इन-मेमोरी डेटा प्रोसेसिंग हाल ही में एक काफी व्यापक रूप से चर्चा का विषय रहा है। कई कंपनियां, जो अतीत में अपनी उच्च लागत के कारण इन-मेमोरी तकनीकों के उपयोग पर विचार नहीं करती थीं, अब इन समाधानों द्वारा पेश किए जाने वाले तेज लेनदेन डेटा प्रसंस्करण का लाभ उठाने के लिए अपनी सूचना प्रणालियों के आर्किटेक्चर का पुनर्निर्माण कर रही हैं। यह यादृच्छिक अभिगम स्मृति (RAM) की लागत में तेजी से गिरावट का परिणाम है, जिसके परिणामस्वरूप स्मृति में परिचालन डेटा के पूरे सेट को स्टोर करना संभव हो जाता है, जिससे उनके प्रसंस्करण की गति 1000 गुना से अधिक हो जाती है।
इन-मेमोरी गणना ग्रिड और
इन-मेमोरी डेटा ग्रिड उत्पाद ऐसे समाधानों के निर्माण के लिए आवश्यक उपकरण प्रदान करते हैं।
इन-मेमरी डेटा ग्रिड (
IMDG ) का कार्य वितरित राज्य में रैंडम एक्सेस मेमोरी में स्टोर करके अल्ट्रा-हाई डेटा उपलब्धता प्रदान करना है। आधुनिक IMDGs बड़ी मात्रा में डेटा के प्रसंस्करण के लिए अधिकांश आवश्यकताओं को पूरा कर सकते हैं।
सीधे शब्दों में
कहें ,
IMDG एक नियमित रूप से बहु-थ्रेडेड हैश तालिका में इंटरफ़ेस के समान एक वितरित वस्तु भंडारण है। आप कुंजियों द्वारा वस्तुओं को संग्रहीत करते हैं। लेकिन, पारंपरिक प्रणालियों के विपरीत, जिसमें कुंजियाँ और मान डेटा प्रकार "बाइट सरणी" और "स्ट्रिंग" द्वारा सीमित होते हैं, आईएमडीजी में आप अपने व्यवसाय मॉडल से किसी भी ऑब्जेक्ट को कुंजी या मान के रूप में उपयोग कर सकते हैं। यह लचीलेपन को बहुत बढ़ाएगा, जिससे आप डेटा ग्रिड में स्टोर कर सकते हैं, जो आपके व्यवसाय तर्क के साथ काम करता है, बिना अतिरिक्त क्रमांकन / डी-क्रमांकन के जो वैकल्पिक तकनीकों की आवश्यकता होती है। यह आपके डेटा ग्रिड के उपयोग को भी सरल करता है, क्योंकि ज्यादातर मामलों में आप वितरित डेटा वेयरहाउस के साथ एक नियमित हैश तालिका के रूप में काम कर सकते हैं। व्यवसाय मॉडल से वस्तुओं के साथ सीधे काम करने की क्षमता
आईएमडीजी और
इन-मेमोरी डेटाबेस (
आईएमडीबी ) के बीच मुख्य अंतर में से एक है। बाद के मामले में, उपयोगकर्ताओं को अभी भी ऑब्जेक्ट-रिलेशनल मैपिंग (ऑब्जेक्ट-टू-रिलेशनल मैपिंग) करने के लिए मजबूर किया जाता है, जो एक नियम के रूप में, प्रदर्शन में महत्वपूर्ण कमी की ओर जाता है।
ऐसे अन्य कार्य हैं जो IMDG को अन्य उत्पादों से अलग करते हैं, जैसे IMDB, NoSql या NewSql डेटाबेस। एक मुख्य एक क्लस्टर में वास्तव में स्केलेबल
डेटा विभाजन है। IMDG अनिवार्य रूप से एक वितरित हैश तालिका है जहां प्रत्येक कुंजी क्लस्टर में एक कड़ाई से परिभाषित सर्वर पर संग्रहीत होती है। क्लस्टर जितना बड़ा होगा, उतना ही अधिक डेटा इसमें स्टोर किया जा सकता है। इस वास्तुकला में मौलिक रूप से महत्वपूर्ण यह है कि डेटा को उसी सर्वर पर संसाधित किया जाए जहां वे स्थित हैं (स्थानीय रूप से), क्लस्टर में उनके आंदोलन को छोड़कर (या कम से कम)। वास्तव में, एक अच्छी तरह से डिज़ाइन किए गए IMDG का उपयोग करते समय, डेटा मूवमेंट पूरी तरह से अनुपस्थित रहेगा जब तक कि क्लस्टर में नए सर्वर नहीं जोड़े जाते हैं या मौजूदा हटा दिए जाते हैं, जिससे क्लस्टर टोपोलॉजी और डेटा वितरण बदल जाता है।
नीचे दिया गया आरेख कुंजी {k1, k2, k3} के सेट के साथ एक क्लासिक IMDG दिखाता है, जिसमें प्रत्येक कुंजी एक अलग सर्वर से संबंधित है। एक बाहरी डेटाबेस वैकल्पिक है। यदि यह मौजूद है, IMDG, एक नियम के रूप में, डेटाबेस से डेटा को स्वचालित रूप से पढ़ेगा या उन्हें लिख देगा।
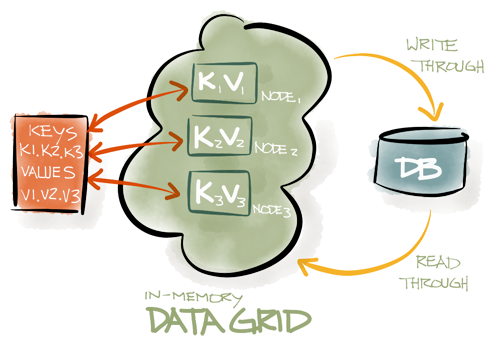
IMDG की एक और विशिष्ट विशेषता है,
ट्रांसेक्शनलिटी का समर्थन जो
ACID (
एटोमिसिटी, कंसिस्टेंसी, आइसोलेशन, ड्यूरेबिलिटी - एटॉमिसिटी, अखंडता, अलगाव, संरक्षण ) की आवश्यकताओं को पूरा करता है। एक नियम के रूप में, क्लस्टर में डेटा अखंडता की गारंटी देने के लिए, दो-चरण प्रतिबद्ध (2-चरण-कमिट या 2PC) का उपयोग किया जाता है। विभिन्न IMDGs में अलग-अलग लॉकिंग तंत्र हो सकते हैं, लेकिन सबसे उन्नत कार्यान्वयन आमतौर पर समानांतर लॉकिंग का उपयोग करते हैं (उदाहरण के लिए,
GridGain MVCC का उपयोग करता है - बहु-संस्करण संगामिति नियंत्रण, बहु-संस्करण समवर्ती अभिगम नियंत्रण), जिससे संचार को कम करता है, और लेन-देन
ACID अखंडता सुनिश्चित करता है उच्च प्रदर्शन को बनाए रखते हुए।
IMDG और
NoSQL डेटाबेस के बीच डेटा अखंडता मुख्य अंतरों में से एक है।
NoSQL डेटाबेस, ज्यादातर मामलों में,
अंतिम दृष्टिकोण
(EC ) नामक एक दृष्टिकोण का उपयोग करके डिज़ाइन किया गया है, जिसमें डेटा कुछ समय के लिए असंगत स्थिति में हो सकता है, लेकिन आवश्यक रूप से *
समय के साथ * सुसंगत हो जाएगा। सामान्य तौर पर, ईसी सिस्टम में लिखने का कार्य धीमी गति से पढ़ने के संचालन की तुलना में काफी तेजी से होता है (अधिक सटीक रूप से, लिखने के संचालन से तेज नहीं)। हाल के IMDGs के साथ *
अनुकूलित * 2PC कम से कम ईसी सिस्टम के अनुरूप है लिखने की गति के संदर्भ में (यदि वे उनसे आगे नहीं हैं), और उन्हें पढ़ने की गति में काफी अधिक है। दिलचस्प बात यह है कि उद्योग ने एक पूर्ण चक्र बना लिया है, जो तब भी धीमी गति से 2PC से EC की ओर बढ़ रहा है, और अब EC से बहुत तेजी से *
अनुकूलित * 2PC तक।
अलग-अलग उत्पाद अलग-अलग 2PC अनुकूलन प्रदान कर सकते हैं, लेकिन सामान्य तौर पर, सभी अनुकूलन के कार्य समरूपता को बढ़ाने, नेटवर्क संचार को कम करने और लेनदेन को पूरा करने के लिए आवश्यक तालों की संख्या को कम करने के लिए हैं। उदाहरण के लिए, Google का वितरित स्पैनर वैश्विक डेटाबेस केवल 2PC दृष्टिकोण पर आधारित है, क्योंकि 2PC ने MapReduce या EC की तुलना में डेटा अखंडता और उच्च थ्रूपुट की गारंटी के लिए एक तेज़ और आसान तरीका प्रदान किया है।
भले ही विभिन्न IMDGs में आम तौर पर सामान्य बुनियादी कार्यक्षमता होती है, लेकिन कई अतिरिक्त विशेषताएं और कार्यान्वयन विवरण हैं जो निर्माता द्वारा भिन्न होते हैं। IMDG उत्पाद का मूल्यांकन करते समय, निष्कासन नीतियों, डेटा लोड करने की तकनीकों पर ध्यान दें, जिसमें सर्वर शुरू करने ((पूर्व) लोड करने की तकनीक), समवर्ती पुनर्संरचना, भंडारण के लिए आवश्यक अतिरिक्त मेमोरी की मात्रा शामिल है। रिकॉर्ड्स (डेटा ओवरहेड), और पसंद इसके अलावा, रन समय में कैश को क्वेरी करने की क्षमता पर ध्यान दें। कुछ IMDGs, जैसे कि
ग्रिडगैन , उपयोगकर्ताओं को
वितरित SQL के लिए समर्थन के साथ नियमित
SQL का उपयोग करके मेमोरी में संग्रहीत डेटा को क्वेरी करने की अनुमति देता है, जो काफी दुर्लभ है।
IMDG में डेटा संग्रहीत करना स्मृति संरचना के लिए आवश्यक आधा कार्यक्षमता है। IMDG में संग्रहीत डेटा को समानांतर और उच्च गति पर भी संसाधित किया जाना चाहिए। IMDG का उपयोग करके क्लस्टर में एक विशिष्ट इन-मेमोरी आर्किटेक्चर विभाजन डेटा, और फिर निष्पादन योग्य कोड उन सर्वरों को भेजा जाता है जहां डेटा की आवश्यकता होती है। चूंकि निष्पादन योग्य कोड (एक कम्प्यूटेशनल कार्य) आमतौर पर
कम्प्यूट ग्रिड का हिस्सा होता है, और इसे सही तरीके से तैनात किया जाना चाहिए, लोड (लोड-बैलेंसिंग) द्वारा संतुलित किया जाता है, इसमें दोष सहिष्णुता (
असफलता ) होती है, और शेड्यूल पर चलने में भी सक्षम होता है (
शेड्यूलिंग ),
कम्प्यूट ग्रिड और IMDG के बीच एकीकरण बहुत महत्वपूर्ण है । अगर
IMDG और
Compute Grid एक ही उत्पाद के हिस्से हैं और समान API का उपयोग करते हैं तो सबसे बड़ा प्रभाव प्राप्त किया जा सकता है। यह डेवलपर से एकीकरण का बोझ हटाता है और आमतौर पर इन-मेमोरी समाधान की सबसे बड़ी प्रदर्शन और विश्वसनीयता प्राप्त करने की अनुमति देता है।
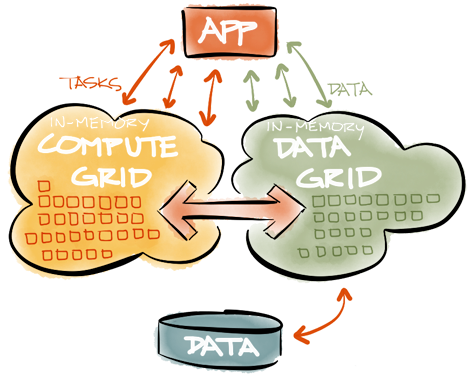
IMDG (एक साथ कंप्यूट ग्रिड) का उपयोग कई क्षेत्रों में किया जाता है, जैसे जोखिम विश्लेषण (रिस्क एनालिटिक्स), ट्रेडिंग सिस्टम (ट्रेडिंग सिस्टम), रीयल-टाइम एंटी-फ्रॉड सिस्टम (धोखाधड़ी का पता लगाना), बायोमेट्रिक्स (बायोमेट्रिक्स), ई-कॉमर्स ( ईकामर्स), ऑनलाइन गेम (ऑनलाइन गेमिंग)।
वास्तव में, स्केलेबिलिटी और प्रदर्शन के मुद्दों का सामना करने वाले किसी भी उत्पाद को इन-मेमोरी प्रोसेसिंग और आईएमडीजी वास्तुकला के उपयोग से लाभ मिल सकता है।