सभी को नमस्कार!
मैं अंग्रेजी का अध्ययन करता हूं और इस प्रक्रिया को हर तरह से सरल बनाता हूं। किसी तरह मुझे एक विशिष्ट पाठ के लिए अनुवाद और प्रतिलेखन के साथ शब्दों की एक सूची प्राप्त करने की आवश्यकता थी। कार्य मुश्किल नहीं था, और मैंने काम करना तय किया। थोड़ी देर बाद, एक
अजगर स्क्रिप्ट लिखी गई, जो यह सब जानता है, और यह भी जानता है कि कैसे थोड़ा और अधिक, क्योंकि मैं अंदर अंग्रेजी पाठ के साथ सभी फाइलों से एक आवृत्ति शब्दकोश प्राप्त करना चाहता था। इसलिए स्क्रिप्ट का एक छोटा सा सेट सामने आया, जिसके बारे में मैं बात करना चाहूंगा।
स्क्रिप्ट फ़ाइलों को पार्स करने, अंग्रेजी शब्दों का चयन करने, उन्हें सामान्य करने, गिनने और अंग्रेजी शब्दों की पूरी परिणामी सूची से पहले काउंटवर्ड शब्द जारी करने से स्क्रिप्ट काम करती है।
अंतिम फ़ाइल में, शब्द इस प्रकार लिखा गया है:
[पुनरावृत्ति की संख्या] [शब्द ही] [शब्द अनुवाद]आगे क्या होगा:
- हम एक फ़ाइल से अंग्रेजी शब्दों की सूची प्राप्त करके शुरू करेंगे ( नियमित अभिव्यक्ति का उपयोग करके);
- इसके बाद, हम शब्दों को सामान्य करना शुरू करेंगे, अर्थात्, उन्हें उनके प्राकृतिक रूप से उस रूप में लाएँ जिसमें वे शब्दकोशों में संग्रहीत हैं (यहाँ हम WordNet प्रारूप का थोड़ा अध्ययन करेंगे);
- फिर हम सभी सामान्यीकृत शब्दों की घटनाओं की संख्या की गणना करते हैं (यह त्वरित और आसान है);
- इसके अलावा, हम StarDict प्रारूप में बदलेंगे , क्योंकि इसकी मदद से हमें अनुवाद और प्रतिलेखन मिलता है।
- ठीक है, बहुत अंत में, हम परिणाम कहीं लिखेंगे (मैंने एक एक्सेल फ़ाइल का चयन किया है)।
मैंने
अजगर 3.3 का उपयोग किया और मुझे एक बार से अधिक पछतावा करना चाहिए कि मैंने अजगर 2.7 में नहीं लिखा, क्योंकि अक्सर आवश्यक मॉड्यूल गायब थे।
आवृत्ति विश्लेषक।
तो, चलो एक साधारण से शुरू करते हैं, फाइलें प्राप्त करते हैं, उन्हें शब्दों में पार्स करते हैं, गिनती करते हैं, सॉर्ट करते हैं, और परिणाम उत्पन्न करते हैं।
आरंभ करने के लिए, हम पाठ में अंग्रेज़ी शब्दों को खोजने के लिए एक नियमित अभिव्यक्ति की रचना करेंगे।
अंग्रेजी शब्दों की खोज के लिए नियमित अभिव्यक्ति
एक साधारण अंग्रेजी शब्द, जैसे कि "ओवर", अभिव्यक्ति का उपयोग करके पाया जा सकता है
"([ए-जेडए-जेड] +)" - अंग्रेजी वर्णमाला के एक या अधिक अक्षर यहां खोजे गए हैं।
एक यौगिक शब्द, उदाहरण के लिए "कमांडर-इन-चीफ", खोजने में कुछ अधिक कठिन है, हमें "प्रमुख" शब्द के बाद "कमांडर-", "इन" फॉर्म के लगातार उप-संदर्भों को देखने की जरूरत है। नियमित अभिव्यक्ति
"" ((a-zA-Z] + -?) * [A-zA-Z] +) का रूप ले लेगी।
यदि कोई मध्यवर्ती उपसर्ग अभिव्यक्ति में मौजूद है, तो यह परिणाम में भी शामिल है। इसलिए, न केवल "कमांडर-इन-चीफ" शब्द हमारे परिणाम में आता है, बल्कि सभी पाए गए सबएक्सप्रेस भी हैं। उन्हें बाहर करने के लिए, हम सबप्रेप्रेशन की शुरुआत में जोड़ते हैं
?: 'शुरुआती कोष्ठक के बाद एक स्फटिक। फिर नियमित अभिव्यक्ति
"(?:? [A-zA-Z] + -?) * [A-zA-Z] +) का रूप ले लेगी।
" हमें अभी भी "नहीं" फ़ॉर्म के एपोस्ट्रोफ के साथ अभिव्यक्ति शब्दों में शामिल करना है। ऐसा करने के लिए,
"-"? "[- ']?" ।
यह, हम नियमित अभिव्यक्ति में सुधारों को पूरा करेंगे, इसे और बेहतर बनाया जा सकता है, लेकिन इस पर ध्यान दें:
"((?: [a-zA-Z] + [- ']?) * [a-zA-ZA-Z +"अंग्रेजी शब्दों के आवृत्ति विश्लेषक का कार्यान्वयन
हम एक छोटा वर्ग लिखेंगे जो अंग्रेजी शब्दों को निकाल सकते हैं, उन्हें गिन सकते हैं और परिणाम उत्पन्न कर सकते हैं। इस पर, संक्षेप में, आवृत्ति शब्दकोश के साथ काम पूरा हो सकता है, लेकिन हमारा काम अभी शुरू हो रहा है। बात यह है कि पाठ में शब्दों को व्याकरण के नियमों को ध्यान में रखते हुए लिखा गया है, जिसका अर्थ है कि पाठ में अंत, एड और आईएनजी के साथ शब्द हो सकते हैं। वास्तव में, यहां तक कि क्रिया के रूप (ए, है, हैं) अलग-अलग शब्दों के लिए गिना जाएगा।
इसलिए शब्द को शब्द काउंटर में जोड़ने से पहले, आपको इसे सही रूप में लाने की आवश्यकता है।
हम दूसरे भाग की ओर मुड़ते हैं -
अंग्रेजी शब्दों का एक
सामान्य लिखने वाला।
अंग्रेजी लेम्मेटाइज़र
दो एल्गोरिदम हैं -
स्टेमिंग और
लेमेटेटाइजेशन । स्टेमिंग का तात्पर्य हेयुरिस्टिक विश्लेषण से है; यह किसी भी आधार का उपयोग नहीं करता है लेमेटेटाइजेशन के दौरान, विभिन्न शब्द आधारों का उपयोग किया जाता है, और व्याकरणिक नियमों के अनुसार परिवर्तन भी लागू होते हैं। हम अपने उद्देश्यों के लिए लेमेटेटाइजेशन का उपयोग करेंगे, क्योंकि परिणाम की त्रुटि स्टैमिंग की तुलना में बहुत कम है।
लेमेट्रीकरण के बारे में पहले से ही एक हाब पर कुछ लेख थे, उदाहरण के लिए
यहां और
यहां । वे
एओटी बेस का उपयोग
करते हैं। मैं खुद को दोहराना नहीं चाहता था, और नींबू पानी के लिए किसी अन्य ठिकानों की तलाश करना भी दिलचस्प था। मैं
वर्डनेट के बारे में बात करना चाहूंगा, और हम इस पर एक लेमेटाइज़र का निर्माण करेंगे। शुरू करने के लिए,
आधिकारिक वर्डनेट वेबसाइट पर आप प्रोग्राम के स्रोत कोड और डेटाबेस को स्वयं डाउनलोड कर सकते हैं। वर्डनेट बहुत कुछ कर सकता है, लेकिन हमें इसकी क्षमताओं का केवल एक छोटा सा हिस्सा चाहिए - शब्दों का सामान्यीकरण।
हमें केवल डेटाबेस चाहिए। वर्डनेट की स्रोत प्रक्रिया (सी में) सामान्यीकरण प्रक्रिया का वर्णन करती है, संक्षेप में मैंने एल्गोरिथ्म को वहां से लिया, इसे अजगर में फिर से लिखा। अरे हाँ, निश्चित रूप से, अजगर के लिए वर्डनेट के लिए एक पुस्तकालय है -
nltk , लेकिन सबसे पहले, यह केवल अजगर 2.7 पर काम करता है, और दूसरी बात, जहाँ तक मैंने देखा, जब सामान्य किया जाता है, तो केवल Wordnet सर्वर के लिए अनुरोध भेजा जाता है।
एक लेम्मेटाइज़र के लिए सामान्य वर्ग आरेख:
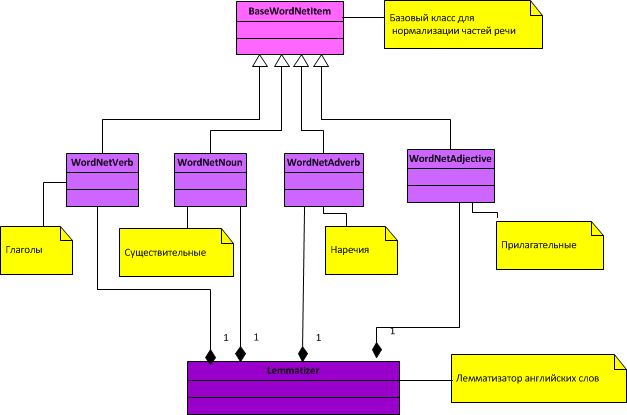
जैसा कि आप आरेख से देख सकते हैं, भाषण के केवल 4 भाग सामान्यीकृत होते हैं (संज्ञा, क्रिया, विशेषण और क्रिया विशेषण)।
यदि हम सामान्यीकरण प्रक्रिया का संक्षेप में वर्णन करते हैं, तो इसमें निम्नलिखित शामिल हैं:
1. भाषण के प्रत्येक भाग के लिए, 2 फाइलें वर्डनेट से डाउनलोड की जाती हैं - एक इंडेक्स डिक्शनरी (जिसमें इंडेक्स डिक्शनरी होती है और भाषण के हिस्से के अनुसार एक एक्सटेंशन होता है, उदाहरण के लिए adverbs.adv के लिए) और एक अपवाद फाइल होती है (भाषण के हिस्से के अनुसार एक्सटेंशन एक्स और एक नाम होता है, उदाहरण के लिए adv.exc क्रिया विशेषण)।
2. सामान्यीकरण के दौरान, अपवादों की सरणी को पहले चेक किया जाता है, यदि शब्द है, तो इसका सामान्यीकृत रूप वापस आ गया है। यदि शब्द अपवाद नहीं है, तो शब्द का भूत व्याकरण के नियमों के अनुसार शुरू होता है, अर्थात् समाप्त होता है, एक नया अंत होता है, चिपकाया जाता है, फिर शब्द को इंडेक्स सरणी में खोजा जाता है, और यदि यह है, तो शब्द को सामान्यीकृत माना जाता है। अन्यथा, निम्नलिखित नियम लागू होते हैं, और इसी तरह, जब तक कि नियम समाप्त नहीं होते हैं या शब्द पहले सामान्यीकृत नहीं होता है।
Lemmalizer के लिए कक्षाएं:
भाषण के हिस्सों के लिए बेस क्लास BaseWordNetItem.py क्रियाओं को सामान्य करने के लिए वर्ग WordNetVerb.py संज्ञा के सामान्यीकरण के लिए वर्ग WordNetNoun.py Adverbs को सामान्य बनाने के लिए वर्ग WordNetAdverb.py विशेषणों को सामान्य करने के लिए वर्ग WordNetAdjective.py Lemmatizer Lemmatizer.py के लिए क्लास खैर, सामान्यीकरण के साथ समाप्त हो गया। अब आवृत्ति विश्लेषक शब्दों को सामान्य कर सकते हैं। हम अपने कार्य के अंतिम भाग की ओर मुड़ते हैं - अंग्रेजी शब्दों के लिए अनुवाद और क्षणिकाएँ प्राप्त करना।
विदेशी अनुवादक StarDict शब्दकोशों का उपयोग करना
आप
StarDict के बारे में लंबे समय तक लिख सकते हैं, लेकिन इस प्रारूप का मुख्य लाभ यह है कि इसके लिए बहुत सारे शब्दकोश डेटाबेस हैं, लगभग सभी भाषाओं में। स्टारडक्ट विषय पर कोई लेख नहीं था और यह अंतराल भरने का समय है। StarDict प्रारूप का वर्णन करने वाली एक फ़ाइल आमतौर पर स्रोत के बगल में स्थित होती है।
यदि हम सभी परिवर्धन को छोड़ देते हैं, तो इस प्रारूप में ज्ञान का सबसे न्यूनतम सेट निम्नानुसार होगा:
प्रत्येक शब्दकोश में 3 आवश्यक फाइलें होनी चाहिए:
1.
ifo एक्सटेंशन
वाली फाइल - इसमें शब्दकोश का सुसंगत वर्णन है;
2.
आईडी एक्सटेंशन के साथ फाइल। Idx फ़ाइल के अंदर प्रत्येक प्रविष्टि में 3 फ़ील्ड होते हैं जो एक के बाद एक जाते हैं:
- word_str - utf-8 प्रारूप में एक स्ट्रिंग जो '\ 0' के साथ समाप्त होती है;
- word_data_offset - .dict फ़ाइल (32 या 64 बिट आकार) पर लिखने से पहले ऑफसेट;
- word_data_size - .dict फ़ाइल में संपूर्ण प्रविष्टि का आकार।
3.
डिक्टेड एक्सटेंशन के साथ फाइल - इसमें अनुवाद खुद होते हैं, जो अनुवाद की ऑफसेट (आईडीएक्स फ़ाइल में ऑफसेट दर्ज होता है) को जानकर पहुंचा जा सकता है।
दो बार यह सोचने के बिना कि कक्षाओं को आखिरकार क्या करना चाहिए, मैंने प्रत्येक फ़ाइलों के लिए एक वर्ग बनाया, और एक सामान्य स्टारडक्ट क्लास जो उन्हें जोड़ती है।
परिणामी वर्ग आरेख:

StarDict के लिए कक्षाएं:
शब्दकोश प्रविष्टियों के लिए बेस क्लास BaseStarDictItem.py , . , . main.py Settings.ini.
Settings.ini ; (, ), PathToBooks = e:\Bienne\Frequency\Books ; WordNet( ) PathToWordNetDict = e:\Bienne\Frequency\WordNet\wn3.1.dict\ ; StarDict( ) PathToStarDict = e:\Bienne\Frequency\Dict\stardict-comn_dictd04_korolew ; , Excel CountWord = 100 ; , ( Excel - , , ) PathToResult = e:\Bienne\Frequency\Books
, ,
xlwt , Excel ( ).
Settings.ini PathToStarDict ";". — , , StarDict.
अंतभाषण
, ,
github .
:
- windows ;
- python 3.3 ;
- xlwt Excel;
- WordNet StarDict ( StarDict dict);
- Settings.ini .
- , StarDict, ( ).