निम्नलिखित विषय
ने मुझे इस लेख को लिखने में
मदद की :
सही पोस्ट की खोज में, या हब्र का रहस्य । तथ्य यह है कि आर भाषा के साथ खुद को परिचित करने के बाद, मैं एक्सेल में कुछ गिनने के किसी भी प्रयास पर बहुत ही ध्यान से देखता हूं। लेकिन मुझे मानना होगा कि मैं आर के साथ एक हफ्ते पहले ही मिला था।
उद्देश्य: आर भाषा और आचरण के माध्यम से प्रिय हैब्राहबर से डेटा एकत्र करना, वास्तव में, सांख्यिकीय विश्लेषण के लिए आर भाषा का निर्माण किया गया था।
इसलिए, इस विषय को पढ़ने के बाद आप जान जाएंगे:
- मैं वेब संसाधनों से डेटा पुनर्प्राप्त करने के लिए R का उपयोग कैसे कर सकता हूं
- बाद के विश्लेषण के लिए डेटा कैसे परिवर्तित करें
- जो संसाधन R को बेहतर जानना चाहते हैं, उन्हें पढ़ने के लिए किन संसाधनों की अत्यधिक अनुशंसा की जाती है
यह अपेक्षित है कि पाठक भाषा के बुनियादी निर्माणों से परिचित होने के लिए स्वतंत्र है। इसके लिए, लेख के अंत में लिंक सबसे उपयुक्त हैं।
ट्रेनिंग
हमें निम्नलिखित संसाधनों की आवश्यकता होगी:
स्थापना के बाद, आपको कुछ इस तरह से देखना चाहिए:
संकुल टैब पर नीचे दायें पैनल में आप संस्थापित संकुल की सूची पा सकते हैं। हमें अतिरिक्त रूप से निम्नलिखित को स्थापित करने की आवश्यकता होगी:
- आरसीआरएल - नेटवर्क के साथ काम करने के लिए। CURL के साथ काम करने वाले सभी लोग खुलने वाले सभी अवसरों को तुरंत समझ जाएंगे।
- XML XML दस्तावेज़ के DOM ट्री के साथ काम करने के लिए एक पैकेज है। हमें xpath पर तत्वों को खोजने की कार्यक्षमता की आवश्यकता है
"संकुल स्थापित करें" पर क्लिक करें, जिन्हें आप की जरूरत है उनका चयन करें, और फिर उन्हें चेकमार्क के साथ चुनें ताकि वे वर्तमान परिवेश में बूट करें।
हमें डेटा मिलता है
इंटरनेट से प्राप्त दस्तावेज़ का DOM ऑब्जेक्ट प्राप्त करने के लिए, बस इन पंक्तियों का पालन करें:
url<-"http://habrahabr.ru/feed/posts/habred/page10/" cookie<-" " html<-getURL(url, cookie=cookie) doc<-htmlParse(html)
प्रेषित कुकीज़ पर ध्यान दें। यदि आप प्रयोग को दोहराना चाहते हैं, तो आपको अपने कुकीज़ स्थानापन्न करने की आवश्यकता होगी, जिसे आपका ब्राउज़र साइट पर प्राधिकरण के बाद प्राप्त करता है। अगला, हमें उस डेटा को प्राप्त करने की आवश्यकता है जिसमें हम रुचि रखते हैं, अर्थात्:
- जब पोस्ट प्रकाशित किया गया था
- कितने विचार
- कितने लोगों ने पसंदीदा में जोड़ा
- +1 और -1 कितने क्लिक थे (कुल)
- कितने +1 क्लिक
- कितना -1
- वर्तमान रेटिंग
- टिप्पणियों की संख्या
बहुत अधिक विस्तार में जाने के बिना, मैं तुरंत कोड दे दूंगा:
published<-xpathSApply(doc, "//div[@class='published']", xmlValue) pageviews<-xpathSApply(doc, "//div[@class='pageviews']", xmlValue) favs<-xpathSApply(doc, "//div[@class='favs_count']", xmlValue) scoredetailes<-xpathSApply(doc, "//span[@class='score']", xmlGetAttr, "title") scores<-xpathSApply(doc, "//span[@class='score']", xmlValue) comments<-xpathSApply(doc, "//span[@class='all']", xmlValue) hrefs<-xpathSApply(doc, "//a[@class='post_title']", xmlGetAttr, "href")
यहां हमने xpath का उपयोग करते हुए तत्वों और विशेषताओं की खोज का उपयोग किया।
इसके अलावा, प्राप्त आंकड़ों से डेटा.फ्रेम बनाने के लिए अत्यधिक अनुशंसा की जाती है - यह डेटाबेस तालिकाओं का एक एनालॉग है। विभिन्न कठिनाई स्तरों के अनुरोध करना संभव होगा। कभी-कभी आपको आश्चर्य होता है कि आर या एलीगेंटली यह कैसे किया जा सकता है
posts<-data.frame(hrefs, published, scoredetailes, scores, pageviews, favs, comments)
डेटा.फ्रेम उत्पन्न करने के बाद, प्राप्त आंकड़ों को सही करना आवश्यक होगा: लाइनों को संख्याओं में परिवर्तित करें, सामान्य प्रारूप में वास्तविक तिथि प्राप्त करें, आदि। हम इसे इस तरह से करते हैं:
posts$comments<-as.numeric(as.character(posts$comments)) posts$scores<-as.numeric(as.character(posts$scores)) posts$favs<-as.numeric(as.character(posts$favs)) posts$pageviews<-as.numeric(as.character(posts$pageviews)) posts$published<-sub(" ","/12/2012 ",as.character(posts$published)) posts$published<-sub(" ","/11/2012 ",posts$published) posts$published<-sub(" ","/10/2012 ",posts$published) posts$published<-sub(" ","/09/2012 ",posts$published) posts$published<-sub("^ ","",posts$published) posts$publishedDate<-as.Date(posts$published, format="%d/%m/%Y %H:%M")
अतिरिक्त फ़ील्ड जोड़ने के लिए भी उपयोगी है जो पहले से प्राप्त लोगों से गणना की जाती है:
scoressplitted<-sapply(strsplit(as.character(posts$scoredetailes), "\\D+", perl=TRUE),unlist) if(class(scoressplitted)=="matrix" && dim(scoressplitted)[1]==4) { scoressplitted<-t(scoressplitted[2:4,]) posts$actions<-as.numeric(as.character(scoressplitted[,1])) posts$plusactions<-as.numeric(as.character(scoressplitted[,2])) posts$minusactions<-as.numeric(as.character(scoressplitted[,3])) } posts$weekDay<-format(posts$publishedDate, "%A")
यहां हमने "कुल 35: ↓ 29 और ↑ 6" फॉर्म के जाने-माने संदेशों को डेटा की एक सरणी में परिवर्तित किया है कि कितने एक्शन किए गए, कितने प्लस और कितने मिन्यूज़ थे।
इस पर, हम कह सकते हैं कि सभी डेटा प्राप्त हुए और विश्लेषण के लिए तैयार प्रारूप में परिवर्तित हो गए। मैंने ऊपर दिए गए कोड को रेडी-टू-यूज़ फंक्शन के रूप में डिज़ाइन किया है। लेख के अंत में आप स्रोत का लिंक पा सकते हैं।
लेकिन चौकस पाठक ने पहले ही ध्यान दिया है कि इस तरह, हमें केवल एक पृष्ठ के लिए डेटा मिला, पूरी श्रृंखला के लिए। पृष्ठों की पूरी सूची के लिए डेटा प्राप्त करने के लिए, निम्न फ़ंक्शन लिखा गया था:
getPostsForPages<-function(pages, cookie, sleep=0) { urls<-paste("http://habrahabr.ru/feed/posts/habred/page", pages, "/", sep="") ret<-data.frame() for(url in urls) { ret<-rbind(ret, getPosts(url, cookie)) Sys.sleep(sleep) } return(ret) }
यहां हम सिस्टम फ़ंक्शन Sys.sleep का उपयोग करते हैं, इसलिए गलती से हबरा प्रभाव को हाबरा के लिए स्वयं व्यवस्थित करने के लिए नहीं :)
इस प्रकार इस समारोह का उपयोग करना प्रस्तावित है:
posts<-getPostsForPages(10:100, cookie,5)
इस प्रकार, हम 5 सेकंड के ठहराव के साथ सभी पृष्ठों को 10 से 100 तक डाउनलोड करते हैं। 10 तक के पृष्ठ हमारे लिए दिलचस्प नहीं हैं, क्योंकि रेटिंग्स अभी तक दिखाई नहीं दे रहे हैं। कुछ मिनट के इंतजार के बाद, हमारा सारा डेटा पोस्ट वेरिएबल में है। मैं आपको तुरंत उन्हें बचाने की सलाह देता हूं, ताकि हर बार जब आप हैबर को परेशान न करें! यह इस तरह से किया जाता है:
write.csv(posts, file="posts.csv")
और निम्नानुसार पढ़ें:
posts<-read.csv("posts.csv")
हुर्रे! हमने सीखा कि कैसे हबर से आंकड़े प्राप्त किए जाते हैं और अगले विश्लेषण के लिए उन्हें स्थानीय रूप से सहेजा जाता है!
डेटा विश्लेषण
यह खंड मैं बिना बताए छोड़ दूंगा। मेरा सुझाव है कि पाठक स्वयं आंकड़ों के साथ खेलें और अपने निष्कर्षों तक पहुँचें। उदाहरण के लिए, सप्ताह के दिन के आधार पर प्लसस और माइनस के मूड की निर्भरता का विश्लेषण करने का प्रयास करें। मैं केवल 2 दिलचस्प निष्कर्ष दूंगा जो मैंने किए हैं।
हैबर उपयोगकर्ता माइनस की तुलना में अधिक होने की संभावना रखते हैं।
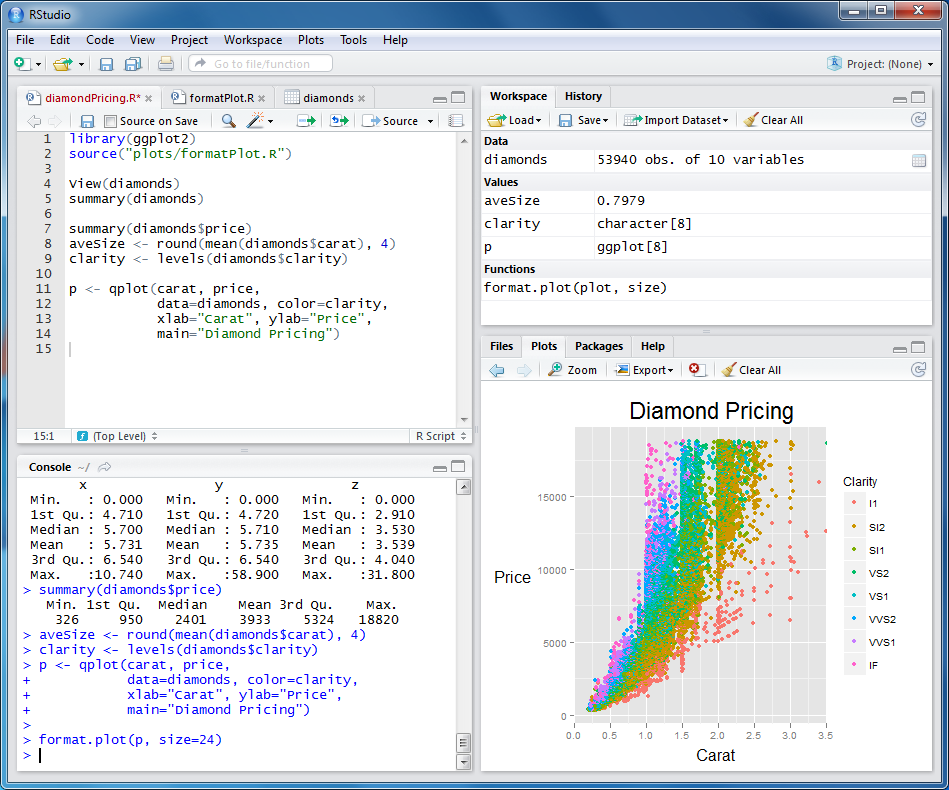
इसे निम्नलिखित ग्राफ में देखा जा सकता है। ध्यान दें कि कितने "क्लाउड" मिन्यूज़ प्लस के प्रसार से अधिक समान और व्यापक हैं। विचारों की संख्या से प्लसस का सहसंबंध minuses के लिए बहुत मजबूत है। दूसरे शब्दों में: बिना सोचे-समझे और कारण को घटाकर!
(मैं रेखांकन पर शिलालेख के लिए माफी माँगता हूँ: जब तक मुझे पता नहीं चला कि रूसी में उन्हें सही तरीके से कैसे प्रदर्शित किया जाए)
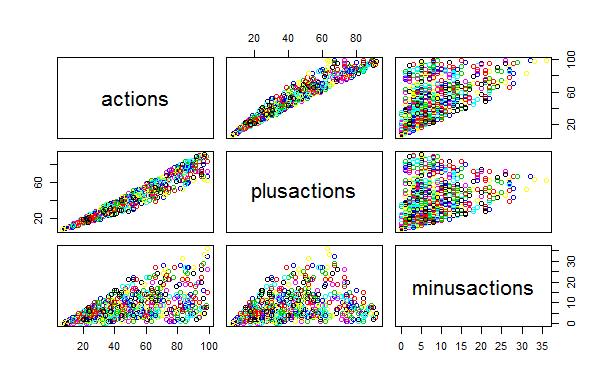
वास्तव में पदों के कई वर्ग हैं
इस कथन का उल्लेख पोस्ट में दिए गए के रूप में किया गया था, लेकिन मैं वास्तविकता में यह सुनिश्चित करना चाहता था। ऐसा करने के लिए, प्लसस की औसत हिस्सेदारी को कुल कार्यों की गणना करने के लिए पर्याप्त है, minuses के लिए समान है और दूसरे को पहले में विभाजित करें। यदि सब कुछ सजातीय था, तो हमें हिस्टोग्राम में कई स्थानीय चोटियों का निरीक्षण नहीं करना चाहिए, लेकिन वे वहां हैं।
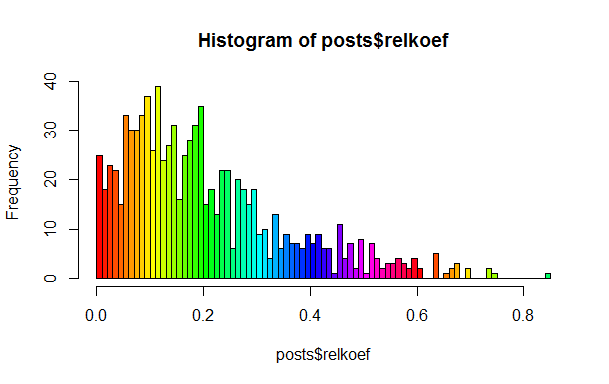
जैसा कि आप देख सकते हैं, वहाँ 0.1, 0.2 और 0.25 के आसपास स्पष्ट चोटियाँ हैं। मेरा सुझाव है कि पाठक स्वयं इन कक्षाओं को खोजें और उनका "नाम" रखें।
मैं यह नोट करना चाहता हूं कि आर क्लस्टरिंग डेटा के लिए एल्गोरिदम में समृद्ध है, सन्निकटन के लिए, परिकल्पना के परीक्षण के लिए आदि।
उपयोगी संसाधन
यदि आप वास्तव में आर की दुनिया में खुद को विसर्जित करना चाहते हैं, तो मैं निम्नलिखित लिंक सुझाता हूं। कृपया अपने दिलचस्प ब्लॉग और आर के विषय पर टिप्पणियों में साझा करें। क्या कोई रूसी में आर के बारे में लिख रहा है?
मेरा मानना है कि आर, हैस्केल, लिस्प, जावास्क्रिप्ट, पाइथन जैसी भाषाओं को हर स्वाभिमानी प्रोग्रामर को जाना जाना चाहिए: यदि काम के लिए नहीं, तो कम से कम अपने क्षितिज को व्यापक बनाने के लिए!
पुनश्च
वादा किया गया स्रोत