
कई C ++ विंडोज प्रोग्रामर अक्सर इन अजीब पहचानकर्ताओं जैसे TCHAR, LPCTSTR से भ्रमित हो जाते हैं। इस लेख में मैं सभी I को डॉट करने के लिए सबसे अच्छे तरीके से कोशिश करूंगा और संदेह के कोहरे को दूर करूंगा।
एक समय, मैंने बहुत समय सोर्स सोर्स में लगाया और समझ में नहीं आया कि इन रहस्यमयी TCHAR, WCHAR, LPSTR, LPWSTR, LPCTSTR का क्या मतलब है।
हाल ही में मैंने एक बहुत ही सक्षम लेख पाया और इसका उच्च गुणवत्ता वाला अनुवाद प्रस्तुत किया।
इस लेख की अनुशंसा उन लोगों के लिए की जाती है जो C ++ स्लीपलेस नाइट्स में सोते हैं।
क्या आप उत्सुक हैं ??
मैं बिल्ली माँगता हूँ !!!
सामान्य तौर पर, एक स्ट्रिंग चरित्र को 1 बाइट और 2 बाइट्स के रूप में दर्शाया जा सकता है।
आमतौर पर, एक एकल-बाइट वर्ण एक ANSI वर्ण एन्कोडिंग है - सभी अंग्रेजी वर्णों को इस एन्कोडिंग में दर्शाया गया है। एक 2-बाइट चरित्र UNICODE एन्कोडिंग है, जिसमें दुनिया की अन्य सभी भाषाओं का प्रतिनिधित्व किया जा सकता है।
विज़ुअल C ++ कंपाइलर ANSI और UNICODE एनकोडिंग के लिए निर्मित डेटा प्रकारों के रूप में char और wchar_t का समर्थन करता है। हालांकि, एक अधिक विशिष्ट यूनिकोड परिभाषा है, समझने के लिए, Windows कई भाषा अनुप्रयोगों के समर्थन के लिए ठीक 2 बाइट एन्कोडिंग का उपयोग करता है।
यूनीकोड Microsoft विंडोज 2-बाइट एन्कोडिंग का प्रतिनिधित्व करने के लिए UTF16 एन्कोडिंग का उपयोग करता है।
Microsoft अपने ऑपरेटिंग सिस्टम (विंडोज NT परिवार) में यूनिकोड समर्थन को लागू करने वाली पहली कंपनियों में से एक थी।
क्या होगा यदि आप चाहते हैं कि आपका C / C ++ कोड एन्कोडिंग से स्वतंत्र हो और विभिन्न एन्कोडिंग मोड का उपयोग कर रहा हो?
टिप। पात्रों और तारों का प्रतिनिधित्व करने के लिए सामान्य डेटा प्रकारों और नामों का उपयोग करें।
उदाहरण के लिए, निम्न कोड बदलने के बजाय:
char cResponse;
इस पर एक !!!
wchar_t cResponse;
बहुभाषी अनुप्रयोगों (जैसे यूनिकोड) का समर्थन करने के लिए, आप अधिक सामान्य तरीके से कोड लिख सकते हैं।
#include<TCHAR.H> // Implicit or explicit include TCHAR cResponse; // 'Y' or 'N' TCHAR sUsername[64]; // _tcs* functions ( TCHAR _tcs*)
प्रोजेक्ट सेटिंग्स में, सामान्य टैब पर, एक CHARACTER SET पैरामीटर है जो इंगित करता है कि किस प्रोग्राम को एन्कोडिंग संकलित किया जाएगा:
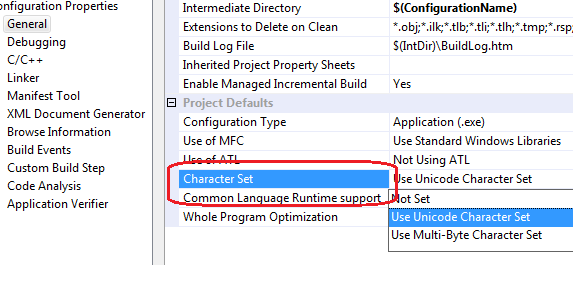
यदि "यूनिकोड कैरेक्टर सेट का उपयोग करें" पैरामीटर निर्दिष्ट किया गया है, तो TCHAR प्रकार का अनुवाद wchar_t प्रकार में किया जाएगा। यदि पैरामीटर "मल्टी-बाइट कैरेक्टर सेट का उपयोग करें" निर्दिष्ट किया जाता है, तो TCHAR का अनुवाद char टाइप करने के लिए किया जाएगा। आप स्वतंत्र रूप से चार और wchar_t प्रकारों का उपयोग कर सकते हैं, और परियोजना सेटिंग्स किसी भी तरह से इन खोजशब्दों के उपयोग को प्रभावित नहीं करेंगी।
TCHAR को इस प्रकार परिभाषित किया गया है:
#ifdef _UNICODE typedef wchar_t TCHAR; #else typedef char TCHAR; #endif
_UNICODE मैक्रो को शामिल किया जाएगा यदि आप "यूनिकोड कैरेक्टर सेट का उपयोग करें" निर्दिष्ट करते हैं और फिर TCHAR प्रकार को wchar_t के रूप में परिभाषित किया जाएगा। जब आप "मल्टी-बाइट कैरेक्टर सेट का उपयोग करें" निर्दिष्ट करते हैं तो TCHAR को चार के रूप में परिभाषित किया जाएगा।
इसके अलावा, एक सामान्य आधार कोड का उपयोग करके कई वर्ण सेट का समर्थन करने के लिए, और संभवतः कई भाषा अनुप्रयोगों का समर्थन करते हैं, विशिष्ट कार्य (अर्थात मैक्रोज़) का उपयोग करते हैं।
Strcpy, strlen, strcat (_s उपसर्ग के साथ फ़ंक्शन के संरक्षित वेरिएंट सहित), या wcscpy, wcslen, wcscat (संरक्षित वेरिएंट सहित) का उपयोग करने के बजाय, आप बेहतर _tccpy, _tcslen, _tcscat फ़ंक्शन का बेहतर उपयोग करते हैं।
जैसा कि आप जानते हैं, स्ट्रलेन फ़ंक्शन इस तरह वर्णित है:
size_t strlen(const char*);
और wcslen फ़ंक्शन इस तरह वर्णित है:
size_t wcslen(const wchar_t* );
आप _tcslen के उपयोग से बेहतर हैं, जो तार्किक रूप से इस तरह वर्णित है:
size_t _tcslen(const TCHAR* );
WC एक वाइड कैरेक्टर है। इसलिए, wcs फ़ंक्शंस वाइड-कैरेक्टर-स्ट्रिंग (यानी, बड़े-वर्ण-स्ट्रिंग के लिए) के लिए होंगे। इस प्रकार _tcs का अर्थ _T वर्ण स्ट्रिंग होगा। और जैसा कि आप जानते हैं, _T उपसर्ग वाली लाइनें टाइप चार या wchar_t की हो सकती हैं।
लेकिन वास्तव में, _tcslen (और _tcs के साथ उपसर्ग किए गए अन्य कार्य) बिल्कुल भी कार्य नहीं हैं, वे मैक्रोज़ हैं। वे बस के रूप में वर्णित हैं:
#ifdef _UNICODE #define _tcslen wcslen #else #define _tcslen strlen #endif
आप हेडर फ़ाइल TCHAR.H को देख सकते हैं और ऊपर के समान मैक्रो विवरण के लिए देख सकते हैं।
इस प्रकार, TCHAR एक प्रकार बिल्कुल नहीं है, लेकिन चार और wchar_t प्रकारों पर एक ऐड-ऑन है। बहु-भाषा अनुप्रयोग चुनने के लिए हमें अनुमति देना, हमारे पास, या सभी एक ही, एक भाषा होगी।
आप पूछ सकते हैं कि उन्हें मैक्रोज़ के रूप में क्यों वर्णित किया गया है, और एक पूर्ण कार्य के रूप में नहीं ??
कारण सरल है: एक पुस्तकालय या DLL एक ही नाम और प्रोटोटाइप के साथ एक साधारण फ़ंक्शन को निर्यात कर सकता है (C ++ में ओवरलोडिंग की अवधारणा को छोड़कर)।
उदाहरण के लिए, यदि आप एक फ़ंक्शन निर्यात करते हैं:
void _TPrintChar(char);
उसके ग्राहक को कैसे कॉल करना चाहिए ?? कैसे करें:
void _TPrintChar(wchar_t);
_TPrintChar को एक तर्क के रूप में दो बाइट चरित्र को स्वीकार करने वाले फ़ंक्शन में जादुई रूप से परिवर्तित किया जा सकता है।
ऐसा करने के लिए, हम दो अलग-अलग कार्य करेंगे:
void PrintCharA(char);
और एक साधारण मैक्रो दोनों के बीच के अंतर को छिपा देगा:
#ifdef _UNICODE void _TPrintChar(wchar_t); #else void _TPrintChar(char); #endif
क्लाइंट केवल फ़ंक्शन को कॉल करेगा
TCHAR cChar; _TPrintChar(cChar);
ध्यान दें कि TCHAR और _TPrintChar अब UNICODE या ANSI से तुलना की जा सकती है, और cChar चर और फ़ंक्शन पैरामीटर चार या wchar_t डेटा प्रकार के लिए तुलनीय होगा।
मैक्रों हमें इन कठिनाइयों के आसपास जाने की अनुमति देते हैं, और हमें अपने पात्रों और तारों के लिए एएनएसआई या यूनिकोड कार्यों का उपयोग करने की अनुमति देते हैं। कई विंडोज फ़ंक्शन इस तरह से वर्णित हैं, और प्रोग्रामर के लिए केवल एक फ़ंक्शन (यानी, एक मैक्रो) है और यह अच्छा है।
मैं SetWindowText के साथ एक उदाहरण दूंगा:
केवल कुछ फ़ंक्शन हैं जिनके पास ऐसे मैक्रोज़ नहीं हैं, और वे केवल प्रत्यय W या A. के साथ हैं। एक उदाहरण ReadDirectoryChangesW फ़ंक्शन है, जिसका ANSI एन्कोडिंग में कोई समतुल्य नहीं है।
जैसा कि आप जानते हैं, हम स्ट्रिंग्स का प्रतिनिधित्व करने के लिए दोहरे उद्धरण चिह्नों का उपयोग करते हैं। इस तरह से प्रस्तुत स्ट्रिंग एक एएनएसआई स्ट्रिंग है, प्रति चरित्र 1 बाइट का उपयोग किया जाता है। मैं एक उदाहरण दूंगा:
“ ANSI . 1 .”
ऊपर दी गई लाइन UNICODE लाइन नहीं है, और कई भाषा समर्थन के लिए उपयुक्त नहीं है। एक UNICODE स्ट्रिंग प्राप्त करने के लिए आपको उपसर्ग L का उपयोग करना होगा।
मैं एक उदाहरण दूंगा:
L” Unicode . 2 , . ”
सामने L रखें और आपको एक UNICODE स्ट्रिंग मिलती है। सभी अक्षर (मैं सभी वर्णों को दोहराता हूं) 2 बाइट पर कब्जा कर लेता हूं, जिसमें अंग्रेजी अक्षर, रिक्त स्थान, संख्या और अशक्त चरित्र शामिल हैं। यूनिकोड स्ट्रिंग का डेटा वॉल्यूम हमेशा 2 बाइट्स का एक से अधिक होगा। 7-चरित्र वाला यूनिकोड स्ट्रिंग 14 बाइट पर कब्जा करेगा। यदि एक यूनिकोड स्ट्रिंग 15 बाइट्स लेता है तो यह एक वैध स्ट्रिंग नहीं है, और यह किसी भी संदर्भ में काम नहीं करेगा।
इसके अलावा, स्ट्रिंग बाइट्स में कई आकार का (TCHAR) होगा।
जब आपको हार्ड-कोडित कोड की आवश्यकता होती है, तो आप इस तरह कोड लिख सकते हैं:
" ANSI";
बिना उपसर्ग के रेखाएँ ANSI रेखाएँ हैं, एक यूनिकोड रेखा के L उपसर्ग के साथ, और _T और TEXT उपसर्ग वाली रेखाएँ संकलन पर निर्भर हैं। और फिर से _T और TEXT फिर से मैक्रोज़ हैं। उन्हें निम्नानुसार परिभाषित किया गया है:
## वर्ण ऑपरेटर सम्मिलन का टोकन है, जो _T ("यूनिकोड") को L "यूनिकोड" में बदल देता है, जहां स्ट्रिंग मैक्रो के लिए एक तर्क है, जब तक कि _UNICODE को परिभाषित नहीं किया जाता है।
यदि _UNICODE परिभाषित नहीं है, तो _T ("यूनिकोड") इसे "यूनिकोड" में बदल देगा। ऑपरेटर इंसर्ट की सी में भी मौजूद है, और यह वीसी ++ में स्ट्रिंग एन्कोडिंग से संबंधित कोई विशिष्ट बात नहीं है।
जानकारी के लिए, मैक्रोज़ को न केवल स्ट्रिंग्स पर बल्कि पात्रों पर भी लागू किया जा सकता है। उदाहरण के लिए, _T ('R') इसे L'R में अच्छी तरह से या सिर्फ 'R' में बदल देगा। यही है, या तो एक यूनिकोड वर्ण या एक ANSI वर्ण।
नहीं और नहीं फिर से, आप किसी मैक्रो का उपयोग किसी वर्ण या स्ट्रिंग को यूनिकोड में परिवर्तित करने के लिए नहीं कर सकते हैं और यूनिकोड पाठ पर नहीं कर सकते।निम्नलिखित कोड गलत होगा:
char c = 'C'; char str[16] = "Habrahabr"; _T( c ); _T(str);
लाइनें _T (c); _T (str); ANSI मोड में संकलित ठीक, _T (x) x में बदल जाएगा, और _T (c) _T (str) के साथ बस c और str में बदल जाएगा।
लेकिन जब आप यूनिकोड मोड में प्रोजेक्ट का निर्माण करते हैं, तो कोड इसके साथ संकलित नहीं होता है:
error C2065: 'Lc' : undeclared identifier error C2065: 'Lstr' : undeclared identifier
मैं आपकी बुद्धि में हाहाकार मचाना नहीं चाहता और समझाऊंगा कि यह काम क्यों नहीं करता।
मल्टीबाइट स्ट्रिंग्स को UNICODE में परिवर्तित करने के लिए कई कार्य हैं, जिनके बारे में मैं जल्द ही बात करूंगा।
एक महत्वपूर्ण नोट है, लगभग सभी कार्य जो एक स्ट्रिंग या चरित्र लेता है, विंडोज एपीआई में प्राथमिकता, MSDN और अन्य जगहों पर एक सामान्य नाम है।
SetWindowTextA / W फ़ंक्शन को निम्न के रूप में वर्गीकृत किया जाएगा:
BOOL SetWindowText(HWND, const TCHAR*);
लेकिन जैसा कि आप जानते हैं, SetWindowText सिर्फ एक मैक्रो है, और प्रोजेक्ट सेटिंग्स के आधार पर इसे निम्न माना जाएगा:
BOOL SetWindowTextA(HWND, const char*); BOOL SetWindowTextW(HWND, const wchar_t*);
तो पहेली मत करो अगर आप इस समारोह का पता नहीं प्राप्त कर सकते हैं:
HMODULE hDLLHandle; FARPROC pFuncPtr; hDLLHandle = LoadLibrary(L"user32.dll"); pFuncPtr = GetProcAddress(hDLLHandle, "SetWindowText");
User32.DLL लायब्रेरी में, 2 फ़ंक्शन SetWindowTextA और SetWindowTextW निर्यात किए जाते हैं, अर्थात्, सामान्य नाम के साथ कोई नाम नहीं हैं।
सभी कार्यों में एएनएसआई और यूनिकोड संस्करण हैं, सामान्य तौर पर, केवल यूनिकोड कार्यान्वयन है। इसका मतलब यह है कि जब आप अपने कोड से SetWindowTextA को कॉल करते हैं, तो ANSI पैरामीटर को स्ट्रिंग में पास करना - यह ANSI को UNICODE कॉल सेटविंडो टेक्स्ट में परिवर्तित करता है।
असली काम (खिड़की के शीर्षक / शीर्षक / लेबल की स्थापना) केवल यूनिकोड संस्करण द्वारा किया जाता है!
एक और उदाहरण लें जो GetWindowText का उपयोग करके विंडो टेक्स्ट प्राप्त करेगा।
आप GetWindowTextA को गंतव्य बफर के रूप में ANSI बफर पास करना कहते हैं।
GetWindowTextA पहले GetWindowTextW को कॉल करेगा, संभवतः यूनिकोड स्ट्रिंग (यानी wchar_t सरणी) के लिए मेमोरी आवंटित करेगा।
यह तब यूनिकोड को आपके लिए ANSI स्ट्रिंग में परिवर्तित करता है।
ये ANSI यूनिकोड रूपांतरणों तक ही सीमित नहीं हैं GUI फ़ंक्शंस, लेकिन Windows API फ़ंक्शंस के पूरे सबसेट, जो स्ट्रिंग्स को स्वीकार करता है और दो विकल्प हैं।
मैं ऐसे कार्यों का एक और उदाहरण दूंगा:
- CreateProcess
- GetUserName
- OpenDesktop
- DeleteFile
- आदि
इसलिए, यह अत्यधिक अनुशंसा की जाती है कि आप यूनिकोड फ़ंक्शन को सीधे कॉल करें।
बदले में, इसका मतलब है कि आपको हमेशा यूनिकोड संस्करण के निर्माण पर ध्यान देना चाहिए, और एएनएसआई संस्करण के निर्माण पर नहीं, इस तथ्य को देखते हुए कि आप कई वर्षों से एएनएसआई के तारों का उपयोग करने के लिए उपयोग किए जाते हैं।
हां, आप एएनएसआई स्ट्रिंग्स को सहेज सकते हैं और प्राप्त कर सकते हैं, उदाहरण के लिए, फ़ाइल पर लिखने के लिए, या अपने चैट प्रोग्राम में एक चैट संदेश भेजना। ऐसी आवश्यकताओं के लिए रूपांतरण कार्य मौजूद हैं।
नोट: एक अन्य प्रकार का विवरण है: इसका नाम WCHAR है - यह wchar_t के बराबर है।
TCHAR एक एकल वर्ण घोषित करने के लिए एक मैक्रो है। आप एक TCHAR सरणी भी घोषित कर सकते हैं। लेकिन क्या होगा, उदाहरण के लिए, आप वर्णों के लिए सूचक का वर्णन करना चाहते हैं या वर्णों के लिए निरंतर सूचक।
मैं एक उदाहरण दूंगा:
TCHAR के साथ चिप्स पढ़ने के बाद, आप शायद इसका उपयोग करना पसंद करते हैं। आपके कोड में तार का प्रतिनिधित्व करने के लिए अभी भी अच्छे विकल्प हैं। ऐसा करने के लिए, प्रोजेक्ट में बस Windows.h को शामिल करें।
नोट: यदि आपके प्रोजेक्ट में विंडोज़ (h) (अप्रत्यक्ष या प्रत्यक्ष रूप से) शामिल है, तो आपको प्रोजेक्ट में TCHAR.H को शामिल नहीं करना चाहिए।
सबसे पहले, पुराने फ़ंक्शन को समझने में आसान बनाने के लिए समीक्षा करें। उदाहरण स्ट्रलेन फ़ंक्शन।
size_t strlen(const char*);
जिसे अलग तरीके से पेश किया जा सकता है।
size_t strlen(LPCSTR);
जहाँ LPCSTR का वर्णन इस प्रकार है:
LPCSTR को इस प्रकार समझा जाता है।
• एलपी - लंबे सूचक (लंबे सूचक)
• सी - लगातार (निरंतर)
• एसटीआर - स्ट्रिंग (स्ट्रिंग)
अनिवार्य रूप से LPCSTR एक स्ट्रिंग के लिए एक (लंबा) सूचक है।
आइए, प्रकार के नाम की नई शैली से मेल करने के लिए strcpy बदलें:
LPSTR strcpy(LPSTR szTarget, LPCSTR szSource);
szTarget, C भाषा के प्रकारों का उपयोग किए बिना, LPSTR प्रकार का है। LPSTR को निम्नानुसार परिभाषित किया गया है:
typedef char* LPSTR;
ध्यान दें कि szSource LPCSTR का है, चूंकि स्ट्रैची फ़ंक्शन स्रोत बफर को संशोधित नहीं करता है, इसलिए कास्ट विशेषता सेट की जाती है। लौटा डेटा प्रकार एक निरंतर स्ट्रिंग नहीं है: LPSTR।
तो, ANSI तार में हेरफेर करने के लिए str उपसर्ग के साथ कार्य करता है। लेकिन हमें एक और दो बाइट यूनिकोड स्ट्रिंग्स की आवश्यकता है। समान बड़े पात्रों के लिए, समान कार्य हैं।
उदाहरण के लिए, बड़े अक्षरों (यूनिकोड स्ट्रिंग्स) की वर्ण लंबाई की गणना करने के लिए, आप wcslen का उपयोग करेंगे:
size_t nLength; nLength = wcslen(L"Unicode");
Wcslen फ़ंक्शन का प्रोटोटाइप है:
size_t wcslen(const wchar_t* szString);
और ऊपर दिए गए कोड को अलग तरह से दर्शाया जा सकता है:
size_t wcslen(LPCWSTR szString);
LPCWSTR को इस तरह वर्णित किया गया है:
typedef const WCHAR* LPCWSTR;
LPCWSTR को इस प्रकार समझा जा सकता है:
एलपी - लंबी सूचक
सी - लगातार
WSTR - वाइड कैरेक्टर स्ट्रिंग
इसी तरह, यूनिकोड स्ट्रिंग्स के लिए strcpy wcscpy के बराबर है:
wchar_t* wcscpy(wchar_t* szTarget, const wchar_t* szSource)
जिसका प्रतिनिधित्व इस प्रकार किया जा सकता है:
LPWSTR wcscpy(LPWSTR szTarget, LPWCSTR szSource);
जहां szTarget एक निरंतर बड़ा स्ट्रिंग (LPWSTR) नहीं है, लेकिन szSource एक निरंतर बड़ा स्ट्रिंग है।
समतुल्य कार्यों के लिए कई समतुल्य wcs फ़ंक्शन हैं। str फ़ंक्शन का उपयोग सरल ANSI स्ट्रिंग्स के लिए किया जाएगा, और यूनिकोड स्ट्रिंग्स के लिए wcs फ़ंक्शन।
हालांकि मैंने पहले ही सलाह दी थी कि आपको केवल एएनएसआई या केवल संश्लेषित TCHAR फ़ंक्शन ही नहीं बल्कि देशी यूनिकोड फ़ंक्शन का उपयोग करना चाहिए। कारण सरल है - आपका आवेदन केवल यूनिकोड होना चाहिए, और आपको इस बारे में चिंता नहीं करनी चाहिए कि वे एएनएसआई के लिए खेल रहे हैं या नहीं। लेकिन पूर्णता के लिए, मैंने इन सामान्य प्रदर्शन (प्रक्षेपण) का उल्लेख किया !!!
एक स्ट्रिंग की लंबाई की गणना करने के लिए, आप _tcslen फ़ंक्शन (मैक्रो) का उपयोग कर सकते हैं।
जो इस प्रकार वर्णित है:
size_t _tcslen(const TCHAR* szString);
या तो:
size_t _tcslen(LPCTSTR szString);
जहाँ एलपीसीटीएसटी प्रकार नाम को इस तरह समझा जा सकता है
एलपी - लंबी सूचक
सी - लगातार
T = TCHAR
एसटीआर = स्ट्रिंग (स्ट्रिंग)
परियोजना सेटिंग्स के आधार पर, एलपीसीटीएसआर को एलपीसीटीएस (एएनएसआई) या एलपीसीडब्ल्यूटीएस (यूनिकोड) में पेश किया जाएगा।
नोट: strlen, wcslen, या _tcslen एक स्ट्रिंग में वर्णों की संख्या लौटाएगा, बाइट्स की संख्या नहीं।
जेनेरिक _tcscpy लाइन कॉपी ऑपरेशन निम्नानुसार वर्णित है:
size_t _tcscpy(TCHAR* pTarget, const TCHAR* pSource);
या इससे भी अधिक सामान्यीकृत तरीके से, जैसे:
size_t _tcscpy(LPTSTR pTarget, LPCTSTR pSource);
आप अनुमान लगा सकते हैं कि LPTSTR का मतलब क्या है))
उपयोग के उदाहरण।
सबसे पहले, मैं गैर-कार्यशील कोड का एक उदाहरण दूंगा:
int main() { TCHAR name[] = "Saturn"; int nLen;
ANSI बिल्ड पर, यह कोड सफलतापूर्वक संकलित करता है क्योंकि TCHAR प्रकार चार का होगा, और चर नाम चार वर्ण का होगा। नाम के लिए strlen कॉलिंग भी ठीक काम करेगा।
So. आइए इसे UNICODE / _UNICODE सक्षम के साथ संकलित करें (परियोजना सेटिंग्स में, "यूनिकोड कैरेक्टर सेट का उपयोग करें" चुनें)।
अब कंपाइलर इस तरह की त्रुटि करेगा:
error C2440: 'initializing' : cannot convert from 'const char [7]' to 'TCHAR []' error C2664: 'strlen' : cannot convert parameter 1 from 'TCHAR []' to 'const char *'
और प्रोग्रामर त्रुटि को सही करने के लिए शुरू करेंगे:
TCHAR name[] = (TCHAR*)"Saturn";
और यह संकलक को शांत नहीं करेगा, क्योंकि TCHAR * से TCHAR [7] में परिवर्तित करना संभव नहीं है। एक ही त्रुटि तब होगी जब एम्बेडेड एएनएसआई तार यूनिकोड फ़ंक्शन को पास किए जाते हैं:
nLen = wcslen("Saturn");
दुर्भाग्य से (या सौभाग्य से), इस त्रुटि को गलत तरीके से केवल सी भाषा प्रकारों को कास्टिंग करके ठीक किया जा सकता है।
nLen = wcslen((const wchar_t*)"Saturn");
और आपको लगता है कि आपने पॉइंटर्स के साथ काम करते समय अपने अनुभव के स्तर को बढ़ा दिया है। आप गलत हैं - यह कोड गलत परिणाम देगा, और बहुमत में आपको एक्सेस उल्लंघन (एक्सेस उल्लंघन) प्राप्त होगा। इस तरह से कास्टिंग करना एक फ्लोट चर को पार करने जैसा है जब 80 बाइट्स की (तार्किक) संरचना की उम्मीद की गई थी।
स्ट्रिंग "शनि" 7 बाइट्स का एक क्रम है:
| 'एस' (83) | 'ए' (97) | 'टी' (116) | 'यू' (117) | 'आर' (114) | 'एन' (110) | '\ _' (0) |
लेकिन जब आप बाइट्स के समान सेट को wcslen में पास करते हैं, तो यह हर 2 बाइट्स को एक वर्ण के रूप में मानता है। इसलिए, पहले 2 बाइट्स [97.83] को 24915 (97 << 8 | 83) के मूल्य वाले एक वर्ण के रूप में माना जाएगा। यह एक यूनिकोड चरित्र है .. .. और अन्य निम्नलिखित पात्रों को [117,116] और इसी तरह माना जाता है।
बेशक आपने इन चीनी पात्रों को पारित नहीं किया, लेकिन टाइप कास्टिंग ने आपके लिए किया !!!
और इसलिए यह जानना बहुत महत्वपूर्ण है कि टाइप रूपांतरण काम नहीं करेगा। तो, पहली पंक्ति को आरंभ करने के लिए, आपको निम्न कार्य करना चाहिए:
TCHAR name[] = _T("Saturn");
जो संकलन के आधार पर 7 या 14 बाइट्स का अनुवाद करेगा।
Wcslen कॉल इस तरह होना चाहिए:
wcslen(L"Saturn");
ऊपर दिए गए प्रोग्राम कोड उदाहरण में, मैंने strlen का उपयोग किया, जो यूनिकोड का निर्माण करते समय त्रुटियों का कारण बनता है।
मैं C भाषा के प्रकार के साथ काम न करने वाले समाधान का एक उदाहरण दूंगा:
lLen = strlen ((const char*)name);
यूनिकोड असेंबलियों पर, नाम चर 14 बाइट्स होगा (7 यूनिकोड वर्ण, शून्य सहित)। स्ट्रिंग के बाद से
"सैटर्न" में केवल अंग्रेजी वर्ण होते हैं जिन्हें ASCII एन्कोडिंग का उपयोग करके दिखाया जा सकता है, एक यूनिकोड वर्ण 'S' को [83, 0] के रूप में दर्शाया जाएगा। निम्न ASCII वर्णों को शून्य के रूप में दर्शाया जाएगा। ध्यान दें कि अब 'S' वर्ण को 83 के 2-बाइट मान के रूप में दर्शाया गया है। पंक्ति के अंत को 0 के मान के साथ 2 बाइट के रूप में दर्शाया जाएगा।
तो, जब आप इस तरह की स्ट्रिंग को स्ट्रेलेन करने के लिए पास करते हैं, तो पहला वर्ण (यानी पहला बाइट) सही होगा ('शनि' के मामले में 'एस')। लेकिन अगले चरित्र / बाइट को रेखा के अंत के रूप में पहचाना जाएगा। इसलिए, strlen गलत मान 1 लौटाएगा।
जैसा कि आप जानते हैं, एक यूनिकोड स्ट्रिंग में अंग्रेजी वर्णों से अधिक हो सकते हैं, और स्ट्रलेन का परिणाम और भी अधिक अपरिभाषित होगा।
संक्षेप में, टाइप कास्टिंग काम नहीं करेगी।
आपको या तो लाइनों को सही रूप में प्रस्तुत करना होगा, या यूनिकोड रूपांतरण कार्यों के लिए एएनएसआई का उपयोग करना होगा, और इसके विपरीत।
अब, मुझे आशा है कि आप निम्नलिखित कोड को समझेंगे:
BOOL SetCurrentDirectory( LPCTSTR lpPathName ); DWORD GetCurrentDirectory(DWORD nBufferLength,LPTSTR lpBuffer);
विषय को जारी रखना। आपने शायद कुछ फ़ंक्शंस / विधियाँ देखीं जिनमें वर्णों की संख्या को संचारित करने की आवश्यकता है, या वर्णों की संख्या को वापस करना। हालाँकि, GetCurrentDirectory है, जिसमें आपको वर्णों की संख्या को स्थानांतरित करने की आवश्यकता है, बाइट्स की संख्या को नहीं।
एक उदाहरण:
TCHAR sCurrentDir[255];
दूसरी ओर, यदि आपको वर्णों की वांछित संख्या के लिए मेमोरी आवंटित करने की आवश्यकता है, तो आपको उचित संख्या में बाइट्स आवंटित करना होगा। C ++ में, आप बस नए ऑपरेटर का उपयोग कर सकते हैं:
LPTSTR pBuffer;
लेकिन अगर आप मेमोरी एलोकेशन फ़ंक्शंस जैसे मॉलॉक, लोकलऑलोक, ग्लोबलऑलोक आदि का उपयोग करते हैं, तो आपको बाइट्स की संख्या निर्दिष्ट करनी होगी!
pBuffer = (TCHAR*) malloc (128 * sizeof(TCHAR) );
जैसा कि आप जानते हैं, रिटर्न वैल्यू की कास्टिंग आवश्यक है। मॉलॉक तर्क में अभिव्यक्ति यह सुनिश्चित करती है कि यह आवश्यक संख्या में बाइट्स आवंटित करता है - और वांछित वर्णों के लिए स्थान आवंटित करता है।
पुनश्च
मूल लेखNG के साथ सभी !!!