पिछले
लेख में, मैंने पहले ही वेब पेजों की सिफारिश प्रणाली में कोल्ड स्टार्ट समस्या को हल करने के लिए मुख्य दिशाओं को रेखांकित किया था। आपको याद दिला दूं कि यूजर्स के लिए एक कोल्ड स्टार्ट (नए यूजर्स को क्या दिखाना है) को कोल्ड स्टार्ट की समस्या को विभाजित किया गया है और साइट्स के लिए एक कोल्ड स्टार्ट (जिसे नए जोड़े गए साइट्स को किससे सिफारिश करनी चाहिए)। आज मैं सिमेंटिक टेक्स्ट एनालिसिस (पाठ खनन) की विधि पर अधिक विस्तार से बताऊँगा जो नई साइटों के लिए कोल्ड स्टार्ट समस्या को हल करने के लिए मुख्य दृष्टिकोण है।
पाठ सामग्री प्रीप्रोसेसिंग
जैसा कि
हमने पहले ही चर्चा की थी , वेब पेज के टेक्स्ट को प्री-प्रोसेसिंग करने में पेज की उपयोगी सामग्री को उजागर करना, स्टॉप शब्द को त्यागना और लेमेटेटाइजिंग शामिल हैं। यह मानक "सज्जनता" एक तरह से या किसी अन्य प्रकार के सभी पाठ खनन कार्यों में सेट होता है, और यह कई
तैयार सॉफ्टवेयर समाधानों में पाया जा सकता है, जो आपके विशिष्ट अनुप्रयोग और विकास पर्यावरण के लिए आवश्यक है।
इसलिए, ग्रंथों के पूर्व-प्रसंस्करण में पहला कदम उन सभी अलग-अलग शब्दों
डब्ल्यू के शब्दकोश का निर्माण करना है जो ग्रंथ
डी के शरीर में पाए जाते हैं, और प्रत्येक दस्तावेज़ में इन शब्दों की घटना पर आंकड़ों की गणना करने के लिए। मैं तुरंत इस तथ्य पर ध्यान आकर्षित करूंगा कि इस लेख में वर्णित सभी विधियां "शब्द बैग" मॉडल पर आधारित होंगी जब पाठ में शब्दों के क्रम को ध्यान में नहीं रखा जाता है। शब्द के संदर्भ को लेमेट्रीकरण के चरण में ध्यान में रखा जा सकता है। उदाहरण के लिए, वाक्य में "हमने स्ट्रॉबेरी खाया और स्प्रिंग्स को किनारे के साथ विकसित किया", पहले मामले में "स्प्रूस" शब्द को "के रूप में" lemmatized किया जाना चाहिए, और दूसरे में - "स्प्रूस" के रूप में। हालांकि, ध्यान रखें कि लेमेटेटाइजेशन में संदर्भ बनाए रखना प्राकृतिक भाषा प्रसंस्करण का एक मुश्किल काम है, सभी लेमेटाइज़र इसके लिए तैयार नहीं हैं। आगे के विश्लेषण में, शब्द क्रम को बिल्कुल भी ध्यान में नहीं रखा जाएगा।
TF-IDF (TF - टर्म फ्रीक्वेंसी, IDF - उलटा डॉक्यूमेंट फ्रीक्वेंसी)
शब्द संसाधन में अगला चरण प्रत्येक दस्तावेज़ में प्रत्येक शब्द
w के लिए
TF-IDF भार की गणना करना है:
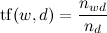
जहाँ
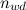
- दस्तावेज़ में शब्द की संख्या,

- दिए गए पाठ में शब्दों की कुल संख्या;

।
कहाँ
| डी | - मामले में ग्रंथों की संख्या, और
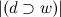
ग्रंथों की संख्या है जिसमें
w होता है। अब

।
या कुछ जटिल विकल्प:
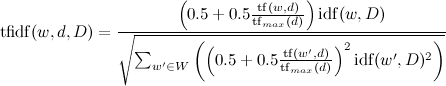
।
जहाँ
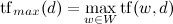
।
दो लक्ष्यों को प्राप्त करने के लिए TF-IDF भार की आवश्यकता होती है। सबसे पहले, ऐसे शब्दों के लिए जो बहुत लंबे हैं, केवल अधिकतम TF-IDF वाले शब्द चुने गए हैं, और बाकी को छोड़ दिया गया है, जो संग्रहीत डेटा की मात्रा को कम करता है। उदाहरण के लिए, प्रासंगिकता प्रतिक्रिया और एलडीए विधियों के लिए, जिसे नीचे वर्णित किया जाएगा, यह हमारे लिए अधिकतम टीएफ-आईडीएफ भार के साथ एन = 200 शब्द लेने के लिए पर्याप्त था। दूसरे, इन वज़न को प्रासंगिकता प्रतिक्रिया एल्गोरिथ्म में सिफारिशों के लिए उपयोग किया जाएगा।
प्रासंगिकता प्रतिक्रिया (RF)
प्रासंगिकता प्रतिक्रिया एल्गोरिथ्म हमें मूल समस्या के समाधान के करीब लाता है और इसका उद्देश्य पृष्ठों की सामग्री और उपयोगकर्ता की पसंद (लेकिन वेब पेज की पसंद को ध्यान में रखे बिना) के आधार पर सिफारिशें बनाना है। मुझे तुरंत यह कहना होगा कि एल्गोरिथ्म नई साइटों की सिफारिशों के लिए उपयुक्त है, लेकिन यह पर्याप्त मात्रा में पसंद (10-20 पसंद और अधिक) होने पर
सहयोगी फ़िल्टरिंग के पारंपरिक तरीकों को खो देता है।
एल्गोरिथ्म का पहला चरण प्रत्येक उपयोगकर्ता के लिए उनकी रेटिंग (पसंद) के इतिहास द्वारा स्वचालित रूप से कीवर्ड (टैग) की खोज करना है। ऐसा करने के लिए, उपयोगकर्ता द्वारा रेट किए गए वेब पेजों से सभी शब्दों के वजन की गणना की जाती है:
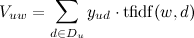
।
जहाँ
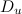
- सभी वेब पेज जिन्हें उपयोगकर्ता पसंद / नापसंद करता है,
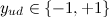
- उपयोगकर्ता द्वारा दी गई रेटिंग। एक उपयोगकर्ता प्रोफ़ाइल के रूप में, अधिकतम वजन वाले शब्दों की एक निर्दिष्ट संख्या (उदाहरण के लिए, 400 शब्द) का चयन किया जाता है।
उपयोगकर्ता से साइट की दूरी की गणना उपयोगकर्ता और साइट के शब्दों के वेट वैक्टर के स्केलर उत्पाद के रूप में की जाती है:
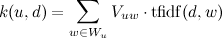
।
जहाँ
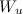
- उपयोगकर्ता प्रोफ़ाइल से शब्द।
नतीजतन, एल्गोरिथ्म हमें किसी भी उपयोगकर्ता की समानता का मूल्यांकन करने की अनुमति देता है जो पसंद करता है और किसी भी वेब पेज पर पाठ सामग्री है। इसके अलावा, एल्गोरिथ्म लागू करने के लिए काफी सरल है और आपको उनके हितों के प्रमुख टैग से मिलकर एक व्याख्या किए गए उपयोगकर्ता प्रोफ़ाइल का निर्माण करने की अनुमति देता है। पंजीकरण करते समय, आप उपयोगकर्ता से उनके प्रमुख हितों को इंगित करने के लिए कह सकते हैं, जिससे नए उपयोगकर्ताओं के लिए सिफारिशें करना संभव हो जाएगा।
अव्यक्त डिरिचलेट आवंटन (LDA)
हमारे ब्लॉग में एलडीए विधि पहले से ही सर्गेई निकोलेंको द्वारा पर्याप्त विस्तार से
वर्णित किया गया है। एल्गोरिथ्म का उद्देश्य अपने विषयों के संदर्भ में ग्रंथों का वर्णन करना है। एलडीए मॉडल की मुख्य धारणा यह है कि प्रत्येक दस्तावेज़ में कई विषय होते हैं, कुछ अनुपात में मिश्रित होते हैं। एलडीए पाठ उत्पन्न करने के लिए एक संभाव्य मॉडल है, जिसके प्रशिक्षण से प्रत्येक दस्तावेज़ के लिए विषयों के एक संभाव्य वितरण की पहचान करने की अनुमति मिलती है, जो बाद में सिफारिशों के कार्य सहित कई लागू समस्याओं को हल करने की अनुमति देता है।
हमारे कार्य की विशिष्टता प्रत्येक वेब पेज के लिए और प्रत्येक उपयोगकर्ता के लिए श्रेणियों की उपलब्धता है (कुल 63 श्रेणियां)। सवाल उठता है: प्रसिद्ध श्रेणियों के साथ प्राप्त एलडीए विषयों को कैसे समेटना है? यदि आप विभाजन में विचार किए बिना एलडीए को प्रशिक्षित करते हैं, तो आपको काफी बड़ी संख्या में विषयों (200 से अधिक) लेने की आवश्यकता है, अन्यथा एलडीए विषय वास्तव में श्रेणियों को दोहराते हैं, और एल्गोरिथ्म का परिणाम समान श्रेणियों (संगीत, विज्ञान, धर्म, आदि) में विभाजन है। जो हम पहले से ही जानते हैं। क्रॉस-कटिंग प्रशिक्षण श्रेणी के आधार पर वर्गीकरण त्रुटियों की पहचान करने और नई साइटों के लिए श्रेणियों की सिफारिश करने के कार्य के लिए उपयोगी हो सकता है। सिफारिशों के लिए, प्रत्येक श्रेणी के लिए अलग से एलडीए विषयों (5-7) के साथ अलग-अलग श्रेणी के लिए एलडीए को प्रशिक्षित करना बेहतर है। इस मामले में, यह स्वचालित रूप से प्रत्येक श्रेणी को उपश्रेणियों में विभाजित करता है, कुछ इस तरह से:

सभी साइटों के लिए एलडीए विषय प्राप्त करने के बाद, आप प्रत्येक उपयोगकर्ता के लिए सिफारिशें तैयार कर सकते हैं। ऐसा करने के लिए, प्रत्येक उपयोगकर्ता के लिए,
लॉजिस्टिक प्रतिगमन को उन साइटों के एलडीए-विषयों पर प्रशिक्षित किया जाता है जिन्हें उन्होंने रेट किया था। यहाँ सकारात्मक घटना पसंद है, नकारात्मक - नापसंद। उपयोगकर्ता के लिए प्रतिगमन मापदंडों के वेक्टर की लंबाई उन श्रेणियों की संख्या के उत्पाद के बराबर होती है, जिन्हें कभी भी उपयोगकर्ता द्वारा प्रोफ़ाइल में चिह्नित किया गया है (यदि उपयोगकर्ता ने अपनी प्रोफ़ाइल में किसी श्रेणी को अक्षम कर दिया है, तो इस श्रेणी में उसकी प्राथमिकताओं की जानकारी नहीं खोई जाएगी)। सिफारिश एक मानक तरीके से प्रशिक्षित उपयोगकर्ता प्रतिगमन मापदंडों और साइटों के एलडीए-विषयों द्वारा एक तरह की संभावना का आकलन करने पर आधारित है।
संक्षेप में कहना
एलडीए विषयों पर सिफारिशों की गुणवत्ता आरएफ विधि से बेहतर है। हालांकि, आरएफ लागू करने के लिए सरल है और आपको एक व्याख्या की गई उपयोगकर्ता प्रोफ़ाइल प्राप्त करने की अनुमति देता है। इसके अलावा, आरएफ पाठ की बहुत कम संख्या (थ्रेसहोल्ड - 10-20 शब्द) के साथ बेहतर काम करता है। दूसरी ओर, एलडीए विधि आपको कई साइड समस्याओं को हल करने की अनुमति देती है, अर्थात्:
- नई साइट जोड़ते समय स्वचालित रूप से श्रेणियों की सिफारिश करें;
- गलत तरीके से वर्गीकृत साइटों की पहचान;
- डुप्लिकेट वेबसाइटों, साहित्यिक चोरी, आदि का पता लगाएं;
- साइट के मुख्य विषयों के प्रदर्शन टैग;
- किसी विशेष श्रेणी में मुख्य टैग प्रदर्शित करें।
इसलिए, इन दो विधियों का एक संयोजन इष्टतम लगता है। दोनों नए पृष्ठों के "पदोन्नति" के चरण में काम करते हैं (जब तक कि साइट को पर्याप्त पसंद नहीं मिली है ताकि सहयोगी फ़िल्टरिंग अपनी पूरी क्षमता पर काम कर सके)। यदि पृष्ठ में सभी सामग्री है - यह 5-10 शब्द है (उदाहरण के लिए, फोटो वाले पृष्ठ में अक्सर सभी पाठ सामग्री होती है - यह चित्र का शीर्षक या शीर्षक है), तो आरएफ, अन्यथा एलडीए का उपयोग करना उचित है। ऊपर सूचीबद्ध अतिरिक्त कार्यों के लिए, आप एलडीए विषयों के बिना नहीं कर सकते।
पाठ खनन विधियों के अपने आगे के अध्ययन के साथ शुभकामनाएँ!