अत्यधिक भरी हुई प्रणालियों और उनके निर्माण के तरीकों की परिभाषा
सर्वर लोड सर्वर हार्डवेयर उपयोग का एक महत्वपूर्ण संकेतक है। एक हिट जानकारी के लिए एक सर्वर के लिए एक ग्राहक अनुरोध है। सर्वर लोड को समय-समय पर हिट्स में व्यक्त क्लाइंट अनुरोधों (हिट्स) की संख्या के अनुपात के रूप में परिभाषित किया जाता है। 2010 में माइक्रोसॉफ्ट के शोध के अनुसार, प्रति सेकंड 100-150 हिट के साथ एक सर्वर को एक उच्च लोड वाला सर्वर माना जा सकता है।
साहित्य में, एचपीसी प्रणाली, एक अत्यधिक भरी हुई प्रणाली, एक अत्यधिक भरी हुई क्लस्टर, एक उच्च भार प्रणाली, एक सुपर कंप्यूटर के रूप में ऐसी अवधारणाएं हैं, जिन्हें कभी-कभी समानार्थक शब्द के रूप में उपयोग किया जाता है। हम प्रति सेकंड कम से कम 150 हिट के भार वाली साइट को समझेंगे।
क्लस्टर कंप्यूटर का एक समूह है जो एकल एकीकृत कंप्यूटिंग संसाधन बनाने के लिए एक साथ काम करता है। प्रत्येक नोड ऑपरेटिंग सिस्टम की अपनी प्रति चला रहा है, जो लिनक्स और बीएसडी का सबसे अधिक उपयोग किया जाता है।
यह समझने के लिए कि क्लस्टर द्वारा किए गए कार्यों को उसके नोड्स के बीच कैसे वितरित किया जाता है, स्केलेबिलिटी को परिभाषित करना आवश्यक है। स्केलेबिलिटी - संसाधनों को जोड़ते समय कार्यभार में वृद्धि (इसकी उत्पादकता में वृद्धि) का सामना करने की प्रणाली की क्षमता। एक प्रणाली को स्केलेबल कहा जाता है यदि यह अतिरिक्त संसाधनों के अनुपात में प्रदर्शन को बढ़ाने में सक्षम है। इस्तेमाल किए गए संसाधनों में वृद्धि के लिए सिस्टम प्रदर्शन में वृद्धि के अनुपात के माध्यम से स्केलेबिलिटी का अनुमान लगाया जा सकता है। यह अनुपात एकता के जितना करीब है, उतना ही अच्छा है। साथ ही, स्केलेबिलिटी सिस्टम के केंद्रीय नोड में संरचनात्मक परिवर्तनों के बिना अतिरिक्त संसाधनों को बढ़ाने की संभावना को संदर्भित करता है। एक भारी भरी हुई प्रणाली की वास्तुकला को स्केल करना क्षैतिज और ऊर्ध्वाधर हो सकता है। वर्टिकल स्केलिंग सर्वर क्षमता को बढ़ाकर सिस्टम के प्रदर्शन को बढ़ाने के लिए है। ऊर्ध्वाधर स्केलिंग का मुख्य नुकसान यह है कि यह एक निश्चित सीमा तक सीमित है। लोहे के मापदंडों को अनिश्चित काल तक नहीं बढ़ाया जा सकता है। हालांकि, वास्तव में, ऊर्ध्वाधर घटक लगभग हमेशा मौजूद होता है, और सार्वभौमिक क्षैतिज स्केलिंग जैसे कि मौजूद नहीं है। क्षैतिज स्केलिंग अतिरिक्त सर्वरों को जोड़कर सिस्टम के प्रदर्शन को बढ़ाने के लिए है। यह क्षैतिज स्केलिंग है जो अब वास्तव में मानक है। यह भी ज्ञात शब्द विकर्ण स्केलिंग है। इसमें दो दृष्टिकोणों का एक साथ उपयोग शामिल है।
और अंत में, किसी भी क्लस्टर वास्तुकला के निर्माण में उपयोग किए जाने वाले मूल सिद्धांत को निर्धारित करना आवश्यक है। यह सिस्टम की तीन-लिंक संरचना है (छवि 1)। तीन लिंक फ्रंटएंड, बैकएंड और डेटा वेयरहाउस हैं। प्रत्येक लिंक अपने कार्य करता है, प्रसंस्करण अनुरोधों में विभिन्न चरणों के लिए जिम्मेदार है, और अलग-अलग पैमाने पर है। प्रारंभ में, अनुरोध सामने के छोर पर आता है। फ़्रंट आमतौर पर स्थिर फ़ाइलों को वापस करने, अनुरोध के प्रारंभिक प्रसंस्करण और इसे आगे स्थानांतरित करने के लिए जिम्मेदार होते हैं। दूसरा लिंक जहां अनुरोध आता है, जो पहले से ही सामने वाले द्वारा पूर्व-संसाधित किया गया है, बैकएंड है। बैकएंड कंप्यूटिंग में लगा हुआ है। बैकेंड की तरफ, एक नियम के रूप में, परियोजना के व्यावसायिक तर्क को लागू किया जाता है। अगली परत जो अनुरोध प्रसंस्करण में जाती है, वह डेटा वेयरहाउस है जिसे बैकएंड द्वारा संसाधित किया जाता है। यह एक डेटाबेस या फाइल सिस्टम हो सकता है।
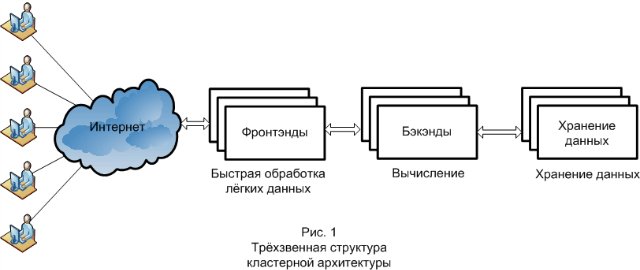
क्लस्टर एचपीसी प्रणाली के निर्माण के लिए हार्डवेयर और सॉफ्टवेयर का अवलोकन
एक क्लस्टर का निर्माण करते समय, कार्य उठता है कि सर्वर के बीच लोड को कैसे वितरित किया जाए। इसके लिए, लोड बैलेंसिंग का उपयोग किया जाता है, जो स्वयं वितरण के अलावा, कई अन्य कार्यों को करता है, उदाहरण के लिए: बढ़ती गलती सहिष्णुता (यदि सर्वर में विफल रहता है, तो सिस्टम काम करना जारी रखेगा) और कुछ प्रकार के हमलों के खिलाफ सुरक्षा (उदाहरण के लिए, SYN- बाढ़)।
फ्रंट-एंड बैलेंसिंग और सुरक्षा
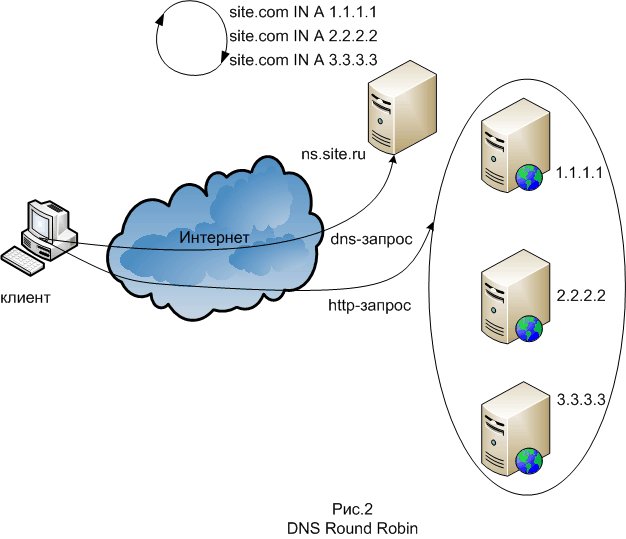
संतुलन तरीकों में से एक डीएनएस राउंड रॉबिन है, जिसका उपयोग फ्रंट स्केल करने के लिए किया जाता है। इसका सार यह है कि सिस्टम के डोमेन को रिकॉर्ड करने के लिए DNS सर्वर पर टाइप A के कई DNS रिकॉर्ड बनाए जाते हैं। DNS सर्वर इन रिकॉर्ड को चक्रीय क्रम में बारी-बारी से जारी करता है। सबसे सरल मामले में, DNS राउंड रॉबिन न केवल एक आईपी पते के साथ, बल्कि एक ही सेवा प्रदान करने वाले सर्वर के कई पतों की एक सूची के साथ प्रश्नों का जवाब देकर काम करता है। प्रत्येक प्रतिक्रिया के साथ, आईपी पते का क्रम बदल जाता है। आमतौर पर, सरल ग्राहक सूची से पहले पते के साथ कनेक्शन स्थापित करने का प्रयास करते हैं, इसलिए विभिन्न ग्राहकों को विभिन्न सर्वरों के पते दिए जाएंगे, जो सर्वरों के बीच कुल लोड वितरित करेंगे। विधि को लागू करने के लिए, किसी भी DNS सर्वर, उदाहरण के लिए बाँध, उपयुक्त है। इस पद्धति का नुकसान यह है कि कुछ प्रदाताओं के लिए DNS सर्वर हैं जो लंबे समय तक रिकॉर्ड के कैशिंग को मजबूर करते हैं।
अगले संतुलन विधि प्रोटोकॉल स्टैक के दूसरे स्तर पर संतुलन है। एक राउटर का उपयोग करके संतुलन किया जाता है ताकि सामने वाले सिस्टम के आईपी पते पर आने वाले कनेक्शनों को स्वीकार करें और उन्हें जवाब दें, लेकिन इस पते से संबंधित एआरपी अनुरोधों का जवाब न दें। इस विधि के सॉफ्टवेयर टूल में से, सबसे सामान्य LVS (लिनक्स वर्चुअल सर्वर) है, जो लिनक्स कर्नेल का एक मॉड्यूल है, इस संतुलन विधि को डायरेक्ट रूटिंग भी कहा जाता है। यहाँ मुख्य शब्दावली इस प्रकार है: निदेशक - वास्तविक नोड जो रूटिंग करता है; Realserver - सर्वर फ़ार्म नोड वीआईपी या वर्चुअल आईपी - बस हमारे वर्चुअल का आईपी (वास्तविक का एक गुच्छा से एकत्र) सर्वर; डीआईपी और आरआईपी - आईपी निदेशक और वास्तविक सर्वर। निदेशक इस आईपीवीएस मॉड्यूल (आईपी वर्चुअल सर्वर) पर स्विच करता है, पैकेट अग्रेषण नियमों को सेट करता है और वीआईपी को उठाता है - आमतौर पर बाहरी इंटरफ़ेस के लिए एक उपनाम के रूप में। यूजर्स वीआईपी होकर जाएंगे। VIP पर पहुंचने वाले पैकेट्स को चयनित विधि द्वारा Realserver के किसी एक को अग्रेषित किया जाता है और वहां पहले से ही सामान्य रूप से संसाधित किया जा रहा है। यह ग्राहक को लगता है कि वह एक मशीन के साथ काम कर रहा है।
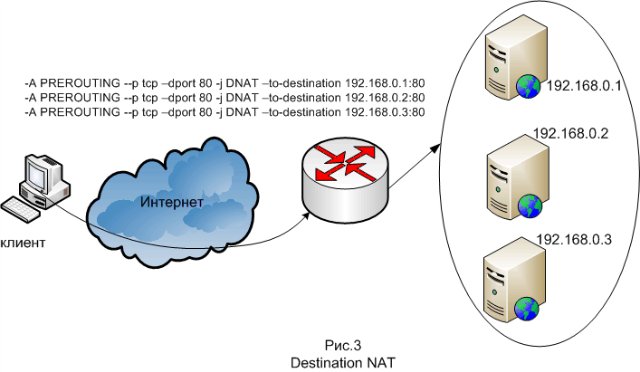
एक अन्य तरीका प्रोटोकॉल स्टैक के तीसरे स्तर पर है, जो कि आईपी स्तर पर है। यह विधि इस तरह से काम करती है कि जब सिस्टम के आईपी पते के साथ एक कनेक्शन किया जाता है, तो गंतव्य एनएटी बैलेंसर पर किया जाता है, यानी पैकेट में गंतव्य आईपी पते को फ्रैंक के आईपी पते से बदल दिया जाता है। प्रतिक्रियाओं के लिए, पैकेट हेडर को वापस संशोधित किया जाता है। यह नेटफिल्टर का उपयोग करके किया जाता है, जो लिनक्स कर्नेल का हिस्सा है।
जहां तक फ्रंट-एंड उपयोगकर्ताओं से अनुरोध स्वीकार करते हैं, क्लस्टर की सुरक्षा का मुख्य कार्य फ्रंट-एंड्स (या फ्रंट-एंड बैलेंसर, आर्किटेक्चर पर निर्भर करता है) के साथ ठीक है। सभी प्रकार के हैकर हमलों (उदाहरण के लिए, जैसे SYN बाढ़ और डीडीओएस) के खिलाफ सुरक्षा प्रदान करना आवश्यक है। अधिकतर, एक फ़ायरवॉल (फ़ायरवॉल - फायर वॉल) का उपयोग सुरक्षा के लिए किया जाता है, इसका दूसरा नाम फ़ायरवॉल (ब्रैंडमॉयर - फायर वॉल) है, दूसरा नाम फ़ायरवॉल है। पैकेट फ़िल्टरिंग नियमों का उपयोग करके एक फ़ायरवॉल दुर्भावनापूर्ण ट्रैफ़िक को रोकता है, और कैशिंग, एड्रेस ट्रांसलेशन और ट्रैफ़िक को अग्रेषित करने जैसी क्रियाओं को भी कर सकता है। जीएनयू / लिनक्स में एक अंतर्निहित नेटफिल्टर फ़ायरवॉल है, जो लिनक्स कर्नेल का हिस्सा है।
बैकेंड स्केलिंग
अत्यधिक भरी हुई वेबसाइटों का निर्माण करते समय, हल्के और भारी http अनुरोधों को प्रतिष्ठित किया जाता है। स्थैतिक वेब पेज और छवियों के लिए लाइट अनुरोध अनुरोध हैं। भारी क्वेरी एक निश्चित कार्यक्रम के लिए एक अपील है जो गतिशील रूप से सामग्री उत्पन्न करती है। डायनामिक वेब पेज एक उच्च-स्तरीय भाषा में लिखे गए प्रोग्राम या स्क्रिप्ट द्वारा तैयार किए जाते हैं: सबसे अधिक बार PHP, ASP.net, पर्ल और जावा। इन कार्यक्रमों के संयोजन को व्यावसायिक तर्क कहा जाता है। व्यावसायिक तर्क नियमों, सिद्धांतों, विषय क्षेत्र की वस्तुओं के व्यवहार की निर्भरता, नियमों के कार्यान्वयन और स्वचालित संचालन के प्रतिबंधों का एक समूह है। व्यापार तर्क बैकएंड पर है। दो योजनाओं का उपयोग किया जाता है: पहला - फ्रंट-एंड वेब सर्वर प्रकाश अनुरोधों को संसाधित करेगा, और भारी बैकएंड के लिए इसे अनुमानित करता है; दूसरा - दृश्यपटल विशुद्ध रूप से एक प्रॉक्सी के रूप में कार्य करता है, लेकिन यह सर्वर के एक समूह के लिए प्रकाश अनुरोधों, और दूसरे के लिए भारी अनुरोधों को समीप करता है।
अपाचे को अक्सर बैकएंड वेब सर्वर के रूप में उपयोग किया जाता है। अपाचे सबसे लोकप्रिय HTTP सर्वर है। अपाचे में एक अंतर्निहित वर्चुअल होस्ट तंत्र है। अपाचे विभिन्न प्रकार के कार्य वातावरण में उपयोग के लिए विभिन्न मल्टीप्रोसेसर मॉडल (एमपीएम) प्रदान करता है। प्रीफ़ॉर्क मॉडल, लिनक्स पर सबसे लोकप्रिय, यह शुरू होने पर एक निश्चित संख्या में अपाचे प्रक्रियाओं को बनाता है और उन्हें पूल में प्रबंधित करता है। एक वैकल्पिक मॉडल कार्यकर्ता है, जो प्रक्रियाओं के बजाय कई थ्रेड्स का उपयोग करता है। यद्यपि थ्रेड्स प्रक्रियाओं की तुलना में हल्के होते हैं, लेकिन उनका उपयोग तब तक नहीं किया जा सकता जब तक कि आपका पूरा सर्वर थ्रेड सुरक्षित न हो। और प्रीफ़ॉर्क मॉडल की अपनी समस्याएं हैं: प्रत्येक प्रक्रिया में बहुत अधिक मेमोरी होती है। अत्यधिक लोड की गई साइटें एक साथ हजारों फाइलों को संसाधित करती हैं, जबकि मेमोरी में सीमित होती है और अधिकतम संख्या में थ्रेड्स या प्रक्रियाएं होती हैं। 2003 में, जर्मन डेवलपर Jan Kneschke को इस समस्या में दिलचस्पी हो गई और उन्होंने फैसला किया कि वह एक वेब सर्वर लिख सकते हैं, जो अपाचे की तुलना में सही तकनीकों पर केंद्रित होगा। उन्होंने लाइटटैप सर्वर को सिंगल थ्रेड और नॉन-ब्लॉकिंग आई / ओ के साथ एक एकल प्रक्रिया के रूप में डिजाइन किया। स्केलिंग कार्य करने के लिए, आप लाइटटैप + अपाचे का उपयोग कर सकते हैं, जिससे कि लाइटटैप क्लाइंट को सभी स्थैतिक दे देगा, और समाप्त होने वाले अनुरोधों, उदाहरण के लिए, .cgi और .php को अपाचे में स्थानांतरित कर दिया जाएगा। स्केलिंग समस्या को हल करने के लिए एक अन्य लोकप्रिय सर्वर Nginx है। Nginx एक HTTP सर्वर और रिवर्स प्रॉक्सी है, साथ ही एक मेल प्रॉक्सी भी है। प्रॉक्सी सर्वर के रूप में, नगनेक्स को सामने की ओर रखा गया है। कई बैकएंड हो सकते हैं, फिर नग्नेक्स एक लोड बैलेंसर के रूप में काम करता है। यह मॉडल आपको इस तथ्य के कारण सिस्टम संसाधनों को बचाने की अनुमति देता है कि निग्नेक्स द्वारा अनुरोध स्वीकार किए जाते हैं, नगनेक्स एक अपाचे अनुरोध भेजता है और जल्दी से एक प्रतिक्रिया प्राप्त करता है, जिसके बाद अपाचे मेमोरी को मुक्त कर देता है, और नग्नेक्स क्लाइंट के साथ बातचीत करता है (सरल अनुरोधों का जवाब देता है), जो स्थैतिक सामग्री वितरित करने के लिए लिखा जाता है। , सिस्टम संसाधनों की कम खपत के साथ बड़ी संख्या में ग्राहक। Microsoft सर्वर के अंतर्गत, ASP का उपयोग बैक-एंड वेब सर्वर के रूप में किया जाता है, जिसमें ASP.net लिखा होता है।
बैकएंड को स्केल करने का एक और तरीका एक स्केलेबल एप्लिकेशन सर्वर है। लागू होता है यदि व्यावसायिक तर्क जावा में लिखा जाता है, अर्थात् इसके सर्वर संस्करण पर। इन एप्लिकेशन को सर्वलेट्स कहा जाता है, और सर्वर को सर्वलेट कंटेनर या एप्लिकेशन सर्वर कहा जाता है। कई खुले स्रोत सर्वलेट कंटेनर हैं: अपाचे टॉम्केट, जेट्टी, जेबॉस एप्लिकेशन सर्वर, ग्लासफिश और मालिकाना: ओरेकल एप्लीकेशन सर्वर, बोरलैंड एप्लीकेशन सर्वर। कई एप्लिकेशन सर्वर क्लस्टरिंग का समर्थन करते हैं, बशर्ते कि एप्लिकेशन अच्छी तरह से परिभाषित स्तरों के अनुसार डिजाइन और विकसित किया गया हो। इसके अलावा, अनुप्रयोगों के साथ महत्वपूर्ण समस्याओं को हल करने के लिए, ओरेकल एप्लीकेशन सर्वर "क्लस्टर आइलैंड्स" का समर्थन करता है - जे 2 ईई स्तर पर सर्वर के सेट जहां सत्र राज्य मापदंडों को अधिक आसानी से पुन: पेश किया जा सकता है, जिससे दूसरे के लिए क्लाइंट अनुरोधों का पारदर्शी पुनर्निर्देशन सुनिश्चित होता है एक घटक जो कुछ J2EE घटक विफल होने पर इस अनुरोध को संभाल सकता है।
DBMS स्केलिंग
और अंत में, क्लस्टर किए गए एचपीसी सिस्टम बनाने के लिए उपयोग किए जाने वाले सॉफ़्टवेयर टूल के विवरण में, डेटा वेयरहाउस को स्केल करने के साधनों का उल्लेख करना आवश्यक है। वेब के लिए डेटा वेयरहाउस के रूप में, सामान्य-प्रयोजन डेटाबेस का उपयोग किया जाता है, जिनमें से सबसे सामान्य MySQL और PostgreSQL हैं।
DBMS स्केलिंग के लिए मुख्य तकनीक पैनापन है, या यों कहें कि, शार्डिंग को स्केलिंग नहीं, बल्कि मशीनों में डेटा को विभाजित करना अधिक सही होगा। विधि का सार यह है कि जैसे-जैसे डेटा की मात्रा बढ़ती है, नए शार्द सर्वर जोड़े जाते हैं, जो तब जोड़े जाते हैं जब मौजूदा शर्ड्स एक निश्चित सीमा तक भरे जाते हैं।
DBMS को स्केल करते समय, प्रतिकृति तकनीक बचाव में आती है। प्रतिकृति डेटाबेस सर्वर के बीच संचार का एक साधन है। प्रतिकृति का उपयोग करके, आप डेटा को एक सर्वर से दूसरे में स्थानांतरित कर सकते हैं या दो सर्वरों पर डेटा को डुप्लिकेट कर सकते हैं। प्रतिकृति का उपयोग "वर्चुअल शार्क" स्केलिंग तकनीक में किया जाता है - प्रतिकृति का उपयोग करते हुए, डेटा वितरित किया जाता है ताकि प्रत्येक बैकेंड सर्वर अपने स्वयं के वर्चुअल शार्क के साथ काम करे, जहां वांछित शार्क शारीरिक रूप से स्थित है, इसकी जानकारी पत्राचार तालिका में संग्रहीत है। साथ ही, डेटाबेस क्वेरी की विशेषताओं के आधार पर स्केलिंग विधि में प्रतिकृति तकनीक: दुर्लभ अद्यतन संचालन और अक्सर पढ़ने के अनुरोध। प्रत्येक बैकेंड सर्वर अपने स्वयं के डेटाबेस सर्वर के साथ काम करता है, उन्हें SLAVE कहा जाता है, इन सर्वरों पर तालिका (SELECT फ़ंक्शन) से संचालन पढ़ें। यदि तालिका में लेखन किया जाता है (INSERT और UPDATE फ़ंक्शन), तो अनुरोध MASTER सर्वर पर आता है और वहाँ से इसे सभी सर्वरों में दोहराया जाता है।
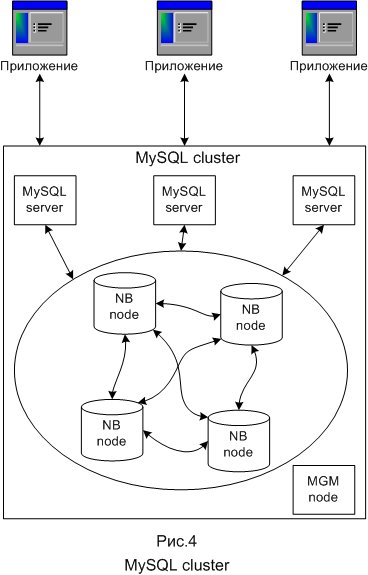
MySQL विभिन्न स्टोरेज सिस्टम का उपयोग करता है। सबसे अधिक बार ये MyISAM और InnoDB हैं। एक NDB स्टोरेज सिस्टम भी है जो MySQL क्लस्टर नामक एक विशेष MySQL स्केलिंग टूल में उपयोग किया जाता है। MySQL क्लस्टर का संकुल भाग वर्तमान में MySQL सर्वर से स्वतंत्र रूप से कॉन्फ़िगर किया गया है। MySQL क्लस्टर में, क्लस्टर के प्रत्येक भाग को नोड कहा जाता है, और नोड्स वास्तव में प्रक्रियाएं हैं। एक कंप्यूटर पर किसी भी संख्या में नोड हो सकते हैं। MySQL क्लस्टर के न्यूनतम कॉन्फ़िगरेशन में, कम से कम तीन नोड होंगे: प्रबंधक (MGM नोड) - इसकी भूमिका: MySQL क्लस्टर के अंदर अन्य नोड्स का प्रबंधन करें, जैसे कॉन्फ़िगरेशन डेटा प्रदान करना, नोड्स शुरू करना और रोकना, बैकअप करना, आदि। डेटाबेस नोड (DB नोड) - सीधे डेटाबेस को प्रबंधित और सहेजता है, उतने ही DB नोड हैं जितने प्रतिकृति के लिए टुकड़े हैं, उदाहरण के लिए, प्रत्येक के दो टुकड़े के दो प्रतिकृति के साथ, आपको चार DB नोड की आवश्यकता है; क्लाइंट नोड (एपीआई) - एक उपयोगकर्ता नोड जो MySQL क्लस्टर के मामले में क्लस्टर तक पहुंच जाएगा, उपयोगकर्ता नोड एक पारंपरिक MySQL सर्वर है जो NDB क्लस्टर स्टोरेज प्रकार का उपयोग करता है, जिससे क्लस्टर टेबल तक पहुंच की अनुमति मिलती है।
एक वैकल्पिक समाधान के रूप में वितरित कम्प्यूटिंग
कभी-कभी, क्लस्टर आर्किटेक्चर के आधार पर अपने स्वयं के अत्यधिक लोड किए गए सिस्टम के निर्माण के बजाय, क्लाइंट के लिए वितरित कंप्यूटिंग इंटरनेट सेवाओं का उपयोग करना आसान और अधिक लाभदायक होता है। वितरित कम्प्यूटिंग कई कंप्यूटरों का उपयोग करके समय लेने वाली कंप्यूटिंग कार्यों को हल करने का एक तरीका है, जिसे अक्सर एक समानांतर कंप्यूटिंग सिस्टम में जोड़ा जाता है। वितरित कंप्यूटिंग का इतिहास 1999 तक का है, जब नॉर्थईस्टर्न यूनाइटेड स्टेट्स यूनिवर्सिटी सीन फेनिंग में नए लोगों ने उपयोगकर्ताओं के बीच एमपी 3 फ़ाइलों के आदान-प्रदान के लिए एक प्रणाली लिखी थी। इस परियोजना को नेपस्टर कहा जाता है। नेपस्टर के उदाहरण के बाद, एक नए, विकेंद्रीकृत प्रकार के पी 2 पी (या पीयर-टू-पीयर) नेटवर्क की एक पूरी श्रेणी विकसित हुई है, पी 2 पी फाइल शेयरिंग यह है कि उपयोगकर्ता सर्वर से फाइल डाउनलोड नहीं करता है, लेकिन फाइल शेयरिंग नेटवर्क के अन्य उपयोगकर्ताओं के कंप्यूटरों से, जिनके आईपी पते वह एक विशेष सर्वर से प्राप्त करता है, जिसे ट्रैकर या हब कहा जाता है। डाउनलोडिंग फाइल सभी साथियों (पीयर-टू-पीयर नेटवर्क के सदस्यों) से एक साथ होती है और एक साथ अपलोड के साथ होती है, इसलिए पीयर-टू-पीयर नेटवर्क एक तरह की वितरित फ़ाइल स्टोरेज है।
वितरित कंप्यूटिंग की तकनीक विकसित हुई, और P2P सिद्धांतों का उपयोग न केवल वितरित फ़ाइल स्टोरेज, वितरित डेटाबेस, स्ट्रीम, प्रोसेसर बनाने के लिए किया जाने लगा।
ग्रिड कंप्यूटिंग (ग्रिड - ग्रिड, नेटवर्क) वितरित कंप्यूटिंग का एक रूप है जिसमें "वर्चुअल सुपरकंप्यूटर" नेटवर्क द्वारा जुड़े क्लस्टर के रूप में प्रस्तुत किया जाता है, एक साथ काम करने के लिए बड़ी संख्या में कार्य करते हैं। ग्रिड एक प्रणाली है जो सेवा के गैर-तुच्छ गुणवत्ता सुनिश्चित करने के लिए मानक, खुले, सार्वभौमिक प्रोटोकॉल और इंटरफेस के माध्यम से वितरित संसाधनों का समन्वय करती है। ग्रिड कंप्यूटिंग की अवधारणा में अंतर्निहित मुख्य विचार विभिन्न प्रकार की कंप्यूटिंग समस्याओं को हल करने के लिए आवश्यक संसाधनों का केंद्रीयकृत दूरस्थ प्रावधान है। उपयोगकर्ता गणना के लिए किसी भी कंप्यूटर से किसी भी कार्य को चला सकता है, इस गणना के लिए संसाधन स्वचालित रूप से दूरस्थ उच्च-प्रदर्शन सर्वरों पर प्रदान किए जाने चाहिए, चाहे कार्य के प्रकार की परवाह किए बिना। ग्रिड डेवलपर्स में रुचि रखने वाले संसाधनों का वितरण फ़ाइल साझाकरण नहीं है, लेकिन कंप्यूटर, सॉफ्टवेयर, डेटा, और अन्य संसाधनों तक सीधी पहुंच है जो संयुक्त रूप से कार्यों और संसाधन प्रबंधन रणनीतियों को हल करने के लिए आवश्यक हैं। ग्रिड वास्तुकला के निम्न स्तर प्रतिष्ठित हैं: बुनियादी (विभिन्न संसाधन, जैसे कंप्यूटर, भंडारण उपकरण, नेटवर्क, सेंसर, आदि); बाइंडिंग (संचार प्रोटोकॉल और प्रमाणीकरण प्रोटोकॉल को परिभाषित करता है); संसाधन (RVS और उनके प्रबंधन के संसाधनों के साथ सहभागिता के लिए प्रोटोकॉल लागू करता है); सामूहिक (संसाधन कैटलॉग प्रबंधन, निदान, निगरानी); लागू (ग्रिड और उपयोगकर्ता अनुप्रयोगों के साथ काम करने के लिए उपकरण)।

वितरित कंप्यूटिंग के विकास में अगला कदम क्लाउड कंप्यूटिंग है।
बर्कले की लैब निम्नलिखित परिभाषा देती है: "क्लाउड कंप्यूटिंग न केवल इंटरनेट पर सेवाओं के रूप में वितरित की जाती है, बल्कि इन सेवाओं को प्रदान करने वाले डेटा केंद्रों में हार्डवेयर और सॉफ्टवेयर सिस्टम भी है।" क्लाउड कंप्यूटिंग एक ऐसी तकनीक है जिसमें वितरित संसाधनों को इंटरनेट सेवा के रूप में उपयोगकर्ता को प्रदान किया जाता है।क्लाउड कंप्यूटिंग के लिए धन्यवाद, कंपनियां अंत उपयोगकर्ताओं को इंटरनेट के माध्यम से सेवाओं, कंप्यूटिंग संसाधनों और अनुप्रयोगों (ऑपरेटिंग सिस्टम और बुनियादी ढांचे सहित) के लिए दूरस्थ गतिशील पहुंच प्रदान कर सकती हैं। कंप्यूटिंग क्लाउड्स में हजारों सर्वर होते हैं जो भौतिक और आभासी डेटा केंद्रों में स्थित होते हैं जो लाखों अनुप्रयोगों को प्रदान करते हैं जो लाखों उपयोगकर्ता एक साथ उपयोग करते हैं।बादलों को वर्गीकृत करने के लिए सभी संभावित तरीकों को क्लाउड सिस्टम की तीन-परत वास्तुकला में घटाया जा सकता है, जिसमें निम्न स्तर शामिल हैं:- एक सेवा के रूप में अवसंरचना: IaaS
- सेवा के रूप में प्लेटफ़ॉर्म (सेवा के रूप में प्लेटफ़ॉर्म: PaaS)
- सेवा के रूप में सॉफ्टवेयर (सेवा के रूप में सॉफ्टवेयर: सास)
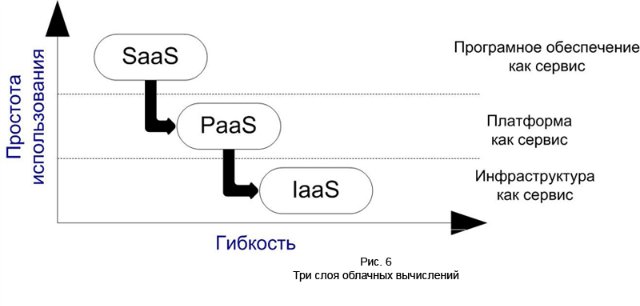 SaaS एक वेब-आधारित सॉफ़्टवेयर परिनियोजन मॉडल है जो वेब ब्राउज़र के माध्यम से सॉफ़्टवेयर को पूरी तरह से सुलभ बनाता है। सास प्रणाली के उपयोगकर्ताओं के लिए, यह कोई फर्क नहीं पड़ता कि सॉफ़्टवेयर कहाँ स्थापित किया गया है, यह किस ऑपरेटिंग सिस्टम का उपयोग करता है, और किस भाषा में इसे लिखा गया है: PHP, जावा या। नेट। और, सबसे महत्वपूर्ण बात, उपयोगकर्ता को कहीं भी कुछ भी स्थापित करने की आवश्यकता नहीं है। उदाहरण के लिए, जीमेल एक ईमेल प्रोग्राम है जो एक ब्राउज़र के माध्यम से सुलभ है। उसी समय, जीमेल खुद को दुनिया भर में स्थित सर्वरों के एक क्लाउड में वितरित किया जाता है, अर्थात यह सास तकनीक का उपयोग करता है।Paa कस्टम वेब अनुप्रयोगों को तैनात करने के लिए एक बुनियादी ढांचे और कार्यात्मक रूप से पूर्ण सेवा और अनुप्रयोग विकास वातावरण के साथ उपयोगकर्ता को प्रस्तुत करता है। उदाहरण के लिए, Google App Engine उपयोगकर्ता Google API का उपयोग करके अपना स्वयं का पायथन एप्लिकेशन लिख सकता है।Iaas सूचना संसाधन, जैसे कम्प्यूटेशनल साइकिल या सूचना भंडारण संसाधन, एक सेवा के रूप में प्रदान करता है। कच्चे कंप्यूटिंग और भंडारण उपकरणों तक पहुंच प्रदान करने के बजाय, IaaS प्रदाता आमतौर पर सेवा के रूप में एक वर्चुअलाइज्ड संरचना प्रदान करते हैं।2012 के अंत में सबसे बड़े क्लाउड प्रदाता हैं: अमेज़ॅन वेब सर्विसेज, विंडोज एज़्योर और Google ऐप इंजन।अमेज़ॅन वेब सर्विसेज (AWS) - अपनी सभी क्लाउड सेवाओं के लिए अमेज़ॅन का एक व्यापक विवरण, यह सेवाओं की एक विस्तृत श्रृंखला को कवर करता है। Amazon Elastic Cloud Compute (Amazon EC2) अमेज़न क्लाउड का दिल है। यह सेवा वर्चुअल सर्वर को अमेजन क्लाउड पर मुक्त संसाधनों की वापसी के साथ अनावश्यक होने के बाद वर्चुअल सर्वर के प्रावधान, प्रबंधन और जारी करने के लिए वेब सेवा प्रदान करती है। EC2 एक उपयोगकर्ता वर्चुअल नेटवर्क है, जिसमें वर्चुअल सर्वर शामिल हैं। अमेज़ॅन ईसी 2 तक पहुंचने का प्राथमिक साधन वेब सेवा एप्लिकेशन प्रोग्रामिंग इंटरफ़ेस (एपीआई) है। अमेज़न एपीआई के साथ काम करने वाले कई इंटरेक्टिव टूल प्रदान करता है, जैसे कि अमेज़ॅन वेब सर्विसेज कंसोल, फ़ायरफ़ॉक्स इलास्टिकफ़ॉक्स प्लगइनअमेज़ॅन कमांड लाइन उपकरणWindows Azure Microsoft द्वारा विकसित एक क्लाउड प्लेटफ़ॉर्म है। Windows Azure Microsoft डेटा सेंटर कंप्यूटर पर डेटा का संग्रहण, उपयोग और संशोधन प्रदान करता है। उपयोगकर्ता के दृष्टिकोण से, अनुप्रयोगों की दो श्रेणियां हैं: उपयोगकर्ता के कंप्यूटर पर आंतरिक, निष्पादन योग्य और डेटा सेंटर कंप्यूटर पर विंडोज एज़्योर वातावरण में वास्तव में निष्पादन योग्य है। क्लाउड में एप्लिकेशन को प्रबंधित करने के लिए विंडोज एज़्योर का मुख्य घटक विंडोज एज़्योर ऐपफाइब्रिक है, जो विंडोज एज़्योर अनुप्रयोगों के विकास, तैनाती और प्रबंधन के लिए एक मध्य स्तरीय क्लाउड-आधारित सॉफ़्टवेयर प्लेटफ़ॉर्म है। विंडोज वर्गीकरण के अनुसार, Azure एक Paa-type क्लाउड प्लेटफ़ॉर्म को संदर्भित करता है, अर्थात।क्लायंट-डेवलपर क्लाउड-आधारित एप्लिकेशन प्रबंधन टूल के साथ प्रदान किया जाता है (यह वही है जो AppFabric घटक प्रदान करता है)।संक्षेप में, एचपीसी-सिस्टम के सभी माने जाने वाले आर्किटेक्चर को इस तरह के ब्लॉक आरेख के रूप में दर्शाया जा सकता है:
SaaS एक वेब-आधारित सॉफ़्टवेयर परिनियोजन मॉडल है जो वेब ब्राउज़र के माध्यम से सॉफ़्टवेयर को पूरी तरह से सुलभ बनाता है। सास प्रणाली के उपयोगकर्ताओं के लिए, यह कोई फर्क नहीं पड़ता कि सॉफ़्टवेयर कहाँ स्थापित किया गया है, यह किस ऑपरेटिंग सिस्टम का उपयोग करता है, और किस भाषा में इसे लिखा गया है: PHP, जावा या। नेट। और, सबसे महत्वपूर्ण बात, उपयोगकर्ता को कहीं भी कुछ भी स्थापित करने की आवश्यकता नहीं है। उदाहरण के लिए, जीमेल एक ईमेल प्रोग्राम है जो एक ब्राउज़र के माध्यम से सुलभ है। उसी समय, जीमेल खुद को दुनिया भर में स्थित सर्वरों के एक क्लाउड में वितरित किया जाता है, अर्थात यह सास तकनीक का उपयोग करता है।Paa कस्टम वेब अनुप्रयोगों को तैनात करने के लिए एक बुनियादी ढांचे और कार्यात्मक रूप से पूर्ण सेवा और अनुप्रयोग विकास वातावरण के साथ उपयोगकर्ता को प्रस्तुत करता है। उदाहरण के लिए, Google App Engine उपयोगकर्ता Google API का उपयोग करके अपना स्वयं का पायथन एप्लिकेशन लिख सकता है।Iaas सूचना संसाधन, जैसे कम्प्यूटेशनल साइकिल या सूचना भंडारण संसाधन, एक सेवा के रूप में प्रदान करता है। कच्चे कंप्यूटिंग और भंडारण उपकरणों तक पहुंच प्रदान करने के बजाय, IaaS प्रदाता आमतौर पर सेवा के रूप में एक वर्चुअलाइज्ड संरचना प्रदान करते हैं।2012 के अंत में सबसे बड़े क्लाउड प्रदाता हैं: अमेज़ॅन वेब सर्विसेज, विंडोज एज़्योर और Google ऐप इंजन।अमेज़ॅन वेब सर्विसेज (AWS) - अपनी सभी क्लाउड सेवाओं के लिए अमेज़ॅन का एक व्यापक विवरण, यह सेवाओं की एक विस्तृत श्रृंखला को कवर करता है। Amazon Elastic Cloud Compute (Amazon EC2) अमेज़न क्लाउड का दिल है। यह सेवा वर्चुअल सर्वर को अमेजन क्लाउड पर मुक्त संसाधनों की वापसी के साथ अनावश्यक होने के बाद वर्चुअल सर्वर के प्रावधान, प्रबंधन और जारी करने के लिए वेब सेवा प्रदान करती है। EC2 एक उपयोगकर्ता वर्चुअल नेटवर्क है, जिसमें वर्चुअल सर्वर शामिल हैं। अमेज़ॅन ईसी 2 तक पहुंचने का प्राथमिक साधन वेब सेवा एप्लिकेशन प्रोग्रामिंग इंटरफ़ेस (एपीआई) है। अमेज़न एपीआई के साथ काम करने वाले कई इंटरेक्टिव टूल प्रदान करता है, जैसे कि अमेज़ॅन वेब सर्विसेज कंसोल, फ़ायरफ़ॉक्स इलास्टिकफ़ॉक्स प्लगइनअमेज़ॅन कमांड लाइन उपकरणWindows Azure Microsoft द्वारा विकसित एक क्लाउड प्लेटफ़ॉर्म है। Windows Azure Microsoft डेटा सेंटर कंप्यूटर पर डेटा का संग्रहण, उपयोग और संशोधन प्रदान करता है। उपयोगकर्ता के दृष्टिकोण से, अनुप्रयोगों की दो श्रेणियां हैं: उपयोगकर्ता के कंप्यूटर पर आंतरिक, निष्पादन योग्य और डेटा सेंटर कंप्यूटर पर विंडोज एज़्योर वातावरण में वास्तव में निष्पादन योग्य है। क्लाउड में एप्लिकेशन को प्रबंधित करने के लिए विंडोज एज़्योर का मुख्य घटक विंडोज एज़्योर ऐपफाइब्रिक है, जो विंडोज एज़्योर अनुप्रयोगों के विकास, तैनाती और प्रबंधन के लिए एक मध्य स्तरीय क्लाउड-आधारित सॉफ़्टवेयर प्लेटफ़ॉर्म है। विंडोज वर्गीकरण के अनुसार, Azure एक Paa-type क्लाउड प्लेटफ़ॉर्म को संदर्भित करता है, अर्थात।क्लायंट-डेवलपर क्लाउड-आधारित एप्लिकेशन प्रबंधन टूल के साथ प्रदान किया जाता है (यह वही है जो AppFabric घटक प्रदान करता है)।संक्षेप में, एचपीसी-सिस्टम के सभी माने जाने वाले आर्किटेक्चर को इस तरह के ब्लॉक आरेख के रूप में दर्शाया जा सकता है: 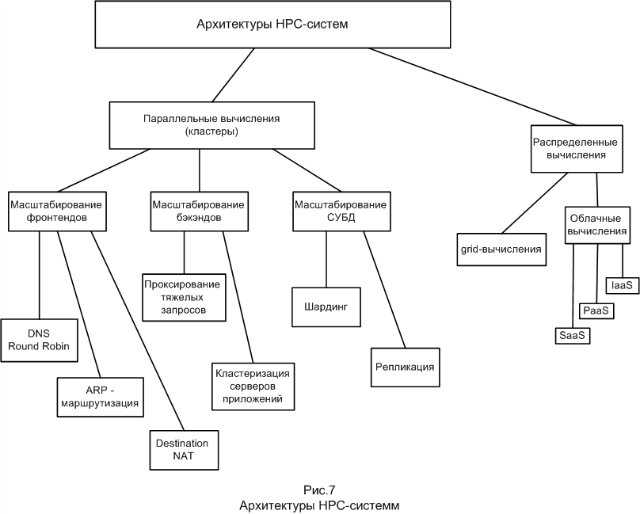
सूत्रों का उपयोग किया- हाई लोड टेक्स्टबुक - जर्नल "हैकर: कंप्यूटर हुलियन्स से एक पत्रिका" - नंबर 7-11 2012
- 2010 और 2011 [इलेक्ट्रॉनिक संसाधन] - मास्को, 2012 के लिए उच्च-लोड सिस्टम हाइलोवाड ++ के डेवलपर्स के सम्मेलन की सर्वश्रेष्ठ सामग्री का संग्रह।
- रेडचेंको जी.आई. वितरित कम्प्यूटिंग सिस्टम - चेल्याबिंस्क: फ़ोटोग्राफ़र, 2012. - 182s।
- . : . — .: -, 2011. -288.: .
- . . Microsoft Windows Azure — .: «», 2013 — 234 ., .