शुभ दोपहर, प्रिय सहयोगियों!
WAS एक क्लाउड स्टोरेज सिस्टम है जो ग्राहकों को किसी भी समय के लिए लगभग असीमित मात्रा में डेटा स्टोर करने की क्षमता प्रदान करता है। WAS को नवंबर 2008 में उत्पादन संस्करण में पेश किया गया था। इससे पहले, इसका उपयोग आंतरिक Microsoft उद्देश्यों के लिए किया गया था, जैसे कि वीडियो, संगीत और गेम को स्टोर करना, मेडिकल रिकॉर्ड को संग्रहीत करना आदि। यह आलेख भंडारण सेवाओं के साथ काम के आधार पर लिखा गया है और सिद्धांतों के लिए समर्पित है। इन सेवाओं का काम।
WAS ग्राहकों के पास किसी भी समय कहीं से भी उनके डेटा तक पहुंच होती है और वे जो भी उपयोग करते हैं और स्टोर करते हैं उसके लिए ही भुगतान करते हैं। डब्ल्यूएएस में संग्रहीत डेटा गंभीर व्यवधानों से वसूली को लागू करने के लिए स्थानीय और भौगोलिक प्रतिकृति दोनों का उपयोग करता है। फिलहाल, WAS रिपॉजिटरी में तीन एब्स्ट्रक्शन - ब्लॉब्स (फाइलें), टेबल (स्ट्रक्चर्ड स्टोरेज) और क्वीज (मैसेज डिलीवरी) होते हैं। ये तीन डेटा सार अधिकांश अनुप्रयोगों के लिए विभिन्न प्रकार के संग्रहीत डेटा की आवश्यकता को कवर करते हैं। एक सामान्य उपयोग परिदृश्य डेटा को blobs में सहेजने के लिए है, लेकिन कतारों की मदद से, डेटा इन blobs में स्थानांतरित कर दिया जाता है, मध्यवर्ती डेटा, स्थिति और इसी तरह के अस्थायी डेटा को तालिकाओं या blobs में संग्रहीत किया जाता है।
डब्ल्यूएएस के विकास के दौरान, ग्राहकों की इच्छाओं को ध्यान में रखा गया था, और स्टील की वास्तुकला की सबसे महत्वपूर्ण विशेषताएं थीं:
- सख्त स्थिरता - कई ग्राहक चाहते हैं कि सख्त स्थिरता हो, खासकर कॉर्पोरेट ग्राहकों के लिए बुनियादी ढांचे को क्लाउड में ले जाना। वे कड़ाई से सुसंगत डेटा पर आशावादी नियंत्रण के लिए कुछ शर्तों के अनुसार ऑपरेशन पढ़ने, लिखने और हटाने में सक्षम होना चाहते हैं - इसके लिए, विंडोज एज़्योर स्टोरेज प्रदान करता है कि कैप प्रमेय (संगति, उपलब्धता, विभाजन-सहिष्णुता) एक बिंदु पर प्राप्त करना कितना मुश्किल है। समय: सख्त संगति, उच्च उपलब्धता, और विभाजन सहिष्णुता।
- वैश्विक और उच्च स्केलेबल नामस्थान - भंडारण के उपयोग को सरल बनाने के लिए, WAS के पास एक वैश्विक नामस्थान है जो आपको डेटा को स्टोर करने और दुनिया में कहीं से भी एक्सेस करने की अनुमति देता है। चूंकि डब्ल्यूएएस का एक मुख्य लक्ष्य बड़ी मात्रा में डेटा स्टोर करने की क्षमता प्रदान करना है, इसलिए यह वैश्विक नाम स्थान डेटा के एक्सबाइट्स को संबोधित करने में सक्षम होना चाहिए।
- आपदा वसूली - WAS कई डेटा केंद्रों में ग्राहक डेटा संग्रहीत करता है जो कई सौ किलोमीटर की दूरी पर स्थित हैं, और यह अतिरेक विभिन्न स्थितियों, जैसे भूकंप, आग, बवंडर, और इसी तरह के कारण डेटा हानि के खिलाफ प्रभावी सुरक्षा प्रदान करता है।
- बहु-किरायेदार और भंडारण की लागत - भंडारण की लागत को कम करने के लिए, कई ग्राहकों को एक साझा भंडारण बुनियादी ढांचे से सेवा दी जाती है, और इस मॉडल के साथ डब्ल्यूएएस, जब विभिन्न स्टोरेज वॉल्यूम के साथ कई अलग-अलग ग्राहकों के भंडारण की आवश्यकता होती है, जिन्हें एक स्थान पर रखा जाता है, कुल आवश्यक भंडारण मात्रा की तुलना में काफी कम होता है यदि WAS प्रत्येक ग्राहक को अलग उपकरण आवंटित करता है।
आइए हम वैश्विक विभाजन नाम स्थान के बारे में अधिक विस्तार से विचार करें। विंडोज एज़्योर स्टोरेज सिस्टम का एक प्रमुख लक्ष्य एक वैश्विक नेमस्पेस प्रदान करना है जो ग्राहकों को क्लाउड में किसी भी डेटा को होस्ट और स्केल करने की अनुमति देता है। एक वैश्विक नाम स्थान प्रदान करने के लिए, WAS नामस्थान के भाग के रूप में DNS का उपयोग करता है, और नाम स्थान में तीन भाग होते हैं: भंडारण खाते का नाम, विभाजन नाम और ऑब्जेक्ट नाम।
एक उदाहरण:
http (s): //AccountName..core.windows.net/PartitionName/ObjectName
खाता नाम - क्लाइंट द्वारा चयनित वॉल्ट खाते का नाम DNS नाम का हिस्सा है। इस भाग का उपयोग भंडारण के मुख्य क्लस्टर को खोजने के लिए किया जाता है और वास्तव में, डेटा सेंटर, जो आवश्यक डेटा संग्रहीत करता है और जहां इस खाते के लिए डेटा के लिए सभी अनुरोध भेजने के लिए आवश्यक है। एक अनुप्रयोग में एक क्लाइंट कई खाता नामों का उपयोग कर सकता है और डेटा को पूरी तरह से अलग-अलग स्थानों में संग्रहीत कर सकता है।
विभाजननाम -
विभाजन नाम जो डेटा के स्थान को निर्धारित करता है जब एक भंडारण क्लस्टर अनुरोध प्राप्त करता है। विभाजननाम का उपयोग ट्रैफ़िक के आधार पर कई स्टोरेज नोड्स में डेटा एक्सेस को स्केल करने के लिए किया जाता है।
ObjectName - यदि पार्टीशन में कई ऑब्जेक्ट हैं, तो ObjectName का उपयोग ऑब्जेक्ट को विशिष्ट रूप से पहचानने के लिए किया जाता है। सिस्टम एक ही पार्टीशननामे के भीतर वस्तुओं के लिए परमाणु लेनदेन का समर्थन करता है। ObjectName वैकल्पिक है। कुछ डेटा प्रकारों के लिए, विभाजननाम किसी खाते के भीतर विशिष्ट रूप से पहचान कर सकता है।
WAS में, आप पूर्ण blob नाम का उपयोग कर सकते हैं के लिए एक विभाजन नाम के रूप में blobs। तालिकाओं के मामले में, यह ध्यान रखना आवश्यक है कि तालिका में प्रत्येक इकाई में एक प्राथमिक कुंजी होती है जिसमें पार्टीशननाम और ऑब्जेक्टनेम होता है, जो आपको परमाणु लेनदेन के लिए एक विभाजन में समूह संस्थाओं की अनुमति देता है। कतारों के लिए, विभाजन नाम कतार नाम का मान है, कतार में रखे गए प्रत्येक संदेश का अपना ऑब्जेक्ट नाम है, जो कतार के भीतर संदेश को विशिष्ट रूप से पहचानता है।
WAS आर्किटेक्चर
फैब्रिक कंट्रोलर , डेटा सेंटर में फॉल्ट टॉलरेंस और कई अन्य कार्यों का प्रबंधन, निगरानी करता है। यह एक तंत्र है जो सिस्टम में होने वाली हर चीज के बारे में जानता है, एक नेटवर्क कनेक्शन से शुरू होता है और वर्चुअल मशीनों पर ऑपरेटिंग सिस्टम की स्थिति के साथ समाप्त होता है। नियंत्रक लगातार ऑपरेटिंग सिस्टम पर स्थापित अपने स्वयं के एजेंटों के साथ संचार करता है और इस ऑपरेटिंग सिस्टम के साथ ओएस संस्करण, सेवा कॉन्फ़िगरेशन, कॉन्फ़िगरेशन पैकेज, और इसी तरह क्या हो रहा है, इस बारे में पूरी जानकारी भेज रहा है। भंडारण के संदर्भ में, फैब्रिक कंट्रोलर संसाधनों का आवंटन करता है और डिस्क भर में डेटा की प्रतिकृति और वितरण के साथ-साथ लोड और ट्रैफ़िक संतुलन का प्रबंधन करता है। विंडोज एज़्योर स्टोरेज आर्किटेक्चर को चित्र 1 में दिखाया गया है।
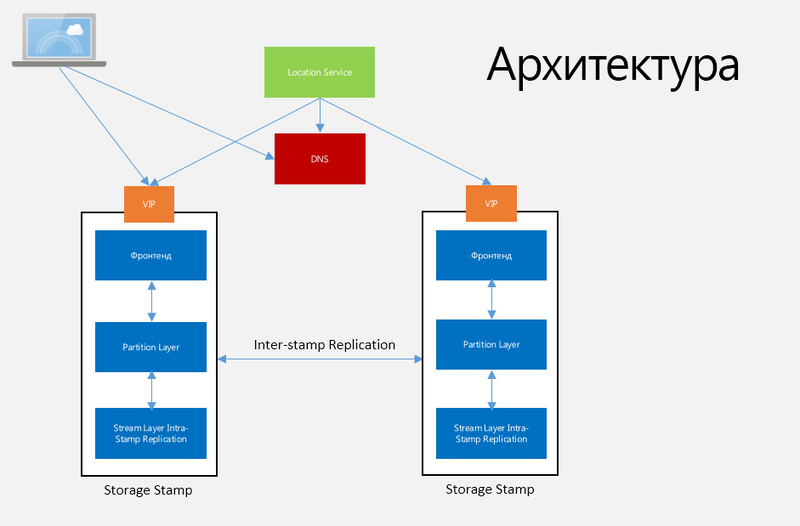
अंजीर। 1. विंडोज एज़्योर स्टोरेज आर्किटेक्चर
भंडारण टिकट (एसएस)। यह शब्द एन नदियों (रैक) भंडारण नोड्स से युक्त क्लस्टर को संदर्भित करता है, जहां प्रत्येक नदी अतिरिक्त नेटवर्क शक्ति और शक्ति के साथ त्रुटियों के अपने स्वयं के डोमेन में है। क्लस्टर में आमतौर पर 10 और 20 नदियों के बीच 18 नोड्स प्रति नदी होती है, जिसमें पहली पीढ़ी का स्टोरेज स्टैम्प होता है जिसमें लगभग 2 पेटाबाइट होते हैं। निम्नलिखित 30 पेटाबाइट्स तक है। वे संग्रहण स्टाम्प को सबसे अधिक उपयोग करने का प्रयास करते हैं, अर्थात, क्षमता के उपयोग, लेनदेन की संख्या और थ्रूपुट के संदर्भ में प्रत्येक एसएस के उपयोग का प्रतिशत लगभग 70 होना चाहिए, लेकिन 80 से अधिक नहीं, क्योंकि अधिक कुशल डिस्क संचालन के लिए आरक्षित होना चाहिए। एक बार जब एसएस उपयोग 70% तक पहुंच जाता है, तो स्थान सेवा अंतर-एसएस प्रतिकृति का उपयोग करके अन्य एसएस के लिए खातों को स्थानांतरित करती है।
स्थान सेवा (एलएस)। यह सेवा सभी SS का प्रबंधन करती है और सभी SS के लिए खाता नामस्थान बनाती है। रास एसएस द्वारा खातों का वितरण करता है और शेष राशि और अन्य प्रबंधन कार्यों को लागू करता है। स्वयं की सुरक्षा के लिए सेवा को भौगोलिक रूप से अलग-अलग दो स्थानों पर वितरित किया जाता है।
स्ट्रीम लेयर (SL)। यह परत डिस्क पर डेटा संग्रहीत करती है और एसएस के अंदर डेटा स्टोर करने के लिए सर्वरों में डेटा के वितरण और प्रतिकृति के लिए जिम्मेदार है। एसएल को प्रत्येक एसएस के भीतर एक वितरित फ़ाइल सिस्टम की एक परत के रूप में देखा जा सकता है जो "धाराओं" को समझता है, इन फ़ाइलों को कैसे स्टोर करें, दोहराएं, और इसी तरह। डेटा SL पर संग्रहीत है, लेकिन विभाजन परत के साथ सुलभ है। SL, वास्तव में, केवल PL द्वारा उपयोग किए जाने वाले कुछ इंटरफ़ेस प्रदान करता है, और एक एपीआई फ़ाइल प्रणाली जो केवल परिशिष्ट-केवल प्रकार के संचालन को लिखने की अनुमति देता है, जो PL को खोलने, बंद करने, हटाने, नाम बदलने, पढ़ने, भागों को जोड़ने और बड़ी फ़ाइलों को मर्ज करने में सक्षम बनाता है ” धाराएँ ”, डेटा की बड़ी मात्रा की सूचियों को“ extents ”(चित्रा 2) कहा जाता है।

अंजीर। 2. एक धारा के दृश्य प्रतिनिधित्व extents से मिलकर
एक स्ट्रीम में कई एक्स्टेंट पॉइंटर्स हो सकते हैं और प्रत्येक सीमा में ब्लॉक का एक सेट होता है। इसके अलावा, extents को "सील" किया जा सकता है, अर्थात, आप उनमें डेटा के नए टुकड़े नहीं जोड़ सकते। यदि स्ट्रीम से डेटा को पढ़ने का प्रयास किया जाता है, तो डेटा को क्रमिक रूप से E1 से सीमा E4 तक प्राप्त किया जाएगा। प्रत्येक धारा को विभाजन परत द्वारा एक बड़ी फ़ाइल के रूप में देखा जाता है, और स्ट्रीम की सामग्री को यादृच्छिक मोड में संशोधित या पढ़ा जा सकता है।
यूनिट। लिखने और पढ़ने के लिए उपलब्ध आंकड़ों की सबसे छोटी इकाई, जो एक विशिष्ट एन बाइट्स तक हो सकती है। सभी रिकॉर्ड किए गए डेटा को एक या अधिक संयुक्त ब्लॉकों के रूप में हद तक लिखा जाता है, और ब्लॉक का आकार एक जैसा नहीं होता है।
विस्तार। एक्सटेंशन स्ट्रीम लेयर पर प्रतिकृति की इकाइयाँ हैं, और डिफ़ॉल्ट रूप से स्टोरेज स्टैम्प एनटीएफएस फ़ाइल में संग्रहीत और ब्लॉक से मिलकर प्रत्येक सीमा के लिए तीन प्रतिकृतियां संग्रहीत करता है। विभाजन परत द्वारा उपयोग की जाने वाली सीमा का आकार 1 जीबी है, जबकि छोटी वस्तुओं को एक सीमा तक विभाजन परत द्वारा पूरक किया जाता है, और कभी-कभी एक ब्लॉक तक। बहुत बड़ी वस्तुओं (जैसे कि बूँदें) को स्टोर करने के लिए, ऑब्जेक्ट को एक विभाजन परत द्वारा कई extents में विभाजित किया जाता है। इस मामले में, निश्चित रूप से, विभाजन परत मॉनिटर करती है कि कौन सी वस्तुएं किस ब्लॉक और ब्लॉक की हैं।
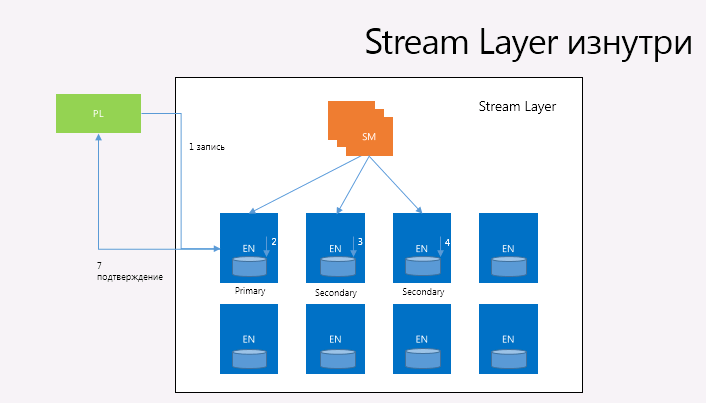 स्ट्रीम प्रबंधक (एसएम)।
स्ट्रीम प्रबंधक (एसएम)। स्ट्रीम प्रबंधक स्ट्रीम के स्ट्रीम नेमस्पेस पर नज़र रखता है, सभी सक्रिय स्ट्रीम और एक्सटेंड की स्थिति का प्रबंधन करता है और एक्सटेंड नोड के बीच उनका स्थान, सभी एक्सटेंड नोड के स्वास्थ्य पर नज़र रखता है, एक्सटेंड बनाता है और वितरित करता है (लेकिन ब्लॉक नहीं - स्ट्रीम मैनेजर उनके बारे में जानता है), और विलुप्त होने की आलसी प्रतिकृति करता है जिसकी प्रतिकृति हार्डवेयर त्रुटियों या बस दुर्गम होने के कारण खो गई थी और "कचरा विस्तार" एकत्र करता है। स्ट्रीम प्रबंधक समय-समय पर सर्वेक्षण करता है और सभी एक्सटेंड नोड की स्थिति को सिंक्रनाइज़ करता है और वे स्टोर करता है। यदि एसएम यह पता लगाता है कि ईएन की अपेक्षित मात्रा से कम की सीमा है, तो एसएम प्रतिकृति देता है। उसी समय, राज्य की मात्रा, यदि कोई इसे कॉल कर सकता है, जो एक स्ट्रीम प्रबंधक की स्मृति में फिट होने के लिए पर्याप्त छोटा हो सकता है। स्ट्रीम लेयर का एकमात्र उपभोक्ता और ग्राहक विभाजन परत है, और वे इतने डिज़ाइन किए गए हैं कि वे 50 मिलियन से अधिक extents का उपयोग नहीं कर सकते हैं और एक भंडारण स्टाम्प के लिए 100,000 से अधिक स्ट्रीम नहीं हैं (ब्लॉक को ध्यान में नहीं रखा गया है, क्योंकि उनमें से बिल्कुल असंख्य संख्याएं हो सकती हैं), जो यह स्ट्रीम मैनेजर मेमोरी के 32 गीगाबाइट में फिट बैठता है।
अत्यधिक नोड्स। प्रत्येक EN SM द्वारा उन्हें सौंपे गए हद तक प्रतिकृतियों के सेट के लिए भंडार का प्रबंधन करता है। एन के पास एन मैप्ड ड्राइव हैं, जो कि विस्तार और उनके ब्लॉकों की प्रतिकृतियां बनाए रखने के लिए पूर्ण नियंत्रण में हैं। उसी समय, EN को स्ट्रीम के बारे में कुछ भी पता नहीं है (स्ट्रीम मैनेजर के विपरीत, जो ब्लॉक के बारे में कुछ भी नहीं जानता है) और केवल extents और ब्लॉक का प्रबंधन करता है, जो (extents) हैं, वास्तव में, डेटा ब्लॉक वाले डिस्क पर फाइलें और उनके चेकसम + संबंधित ब्लॉकों और उनके भौतिक स्थान तक फैली पाली में संघों का एक नक्शा। प्रत्येक EN में इसके विस्तार के कुछ विचार होते हैं और जहां विशिष्ट extents के लिए प्रतिकृतियां स्थित होती हैं। जब कोई धाराएँ विशिष्ट विलुप्त होने का उल्लेख नहीं करती हैं, तो स्ट्रीम प्रबंधक इन कूड़े को हटाता है और अंतरिक्ष को खाली करने की आवश्यकता के बारे में सूचित करता है। उसी समय, स्ट्रीम में डेटा केवल जोड़ा जा सकता है, मौजूदा डेटा को संशोधित नहीं किया जा सकता है। जोड़ें ऑपरेशन परमाणु हैं - या तो पूरे डेटा ब्लॉक को जोड़ा जाता है, या कुछ भी नहीं जोड़ा जाता है। एक समय में, कई ब्लॉकों को एक ही परमाणु ऑपरेशन में जोड़ा जा सकता है "कई ब्लॉकों को जोड़ना"। स्ट्रीम से पढ़ा जा सकने वाला न्यूनतम आकार एक ब्लॉक है। कई ब्लॉकों को जोड़ने का संचालन क्लाइंट को एक ही ऑपरेशन में बड़ी मात्रा में अनुक्रमिक डेटा रिकॉर्ड करने की अनुमति देता है।
प्रत्येक सीमा, जैसा कि पहले ही कहा गया है, आकार के लिए एक निश्चित छत है, और जब यह भरा होता है, तो सीमा को सील कर दिया जाता है और आगे की कार्रवाई नई सीमा पर संचालित होती है। आप डेटा को एक सीलबंद सीमा तक नहीं जोड़ सकते, और यह अपरिवर्तनीय है।
विलुप्त होने के संबंध में कई नियम हैं:
1. एक रिकॉर्ड जोड़ने और क्लाइंट को ऑपरेशन की पुष्टि करने के बाद, किसी भी प्रतिकृति से इस रिकॉर्ड को पढ़ने के सभी आगे के संचालन को एक ही डेटा (डेटा अपरिवर्तनीय) वापस करना चाहिए।
2. हद बंद हो जाने के बाद, किसी भी सील प्रतिकृति से सभी पढ़ने के संचालन को उसी सीमा सामग्री को वापस करना चाहिए।
उदाहरण के लिए, जब एक स्ट्रीम बनाई जाती है, एसएम तीन एक्सटेंशन नोड्स के लिए पहली सीमा (एक प्राथमिक और दो माध्यमिक) को तीन प्रतिकृतियां प्रदान करता है, जो बदले में एसएम द्वारा अलग-अलग अपडेट और त्रुटि डोमेन के बीच यादृच्छिक वितरण के लिए चुने जाते हैं, लोड संतुलन की संभावना को ध्यान में रखते हुए। इसके अलावा, एसएम तय करता है कि प्रतिकृति किस हद तक प्राथमिक होगी और हद तक सभी लेखन कार्य प्राथमिक ईएन पर पहले किए जाते हैं, और उसके बाद ही प्राथमिक एन के साथ रिकॉर्ड दो माध्यमिक ईएस पर बनाया जाता है। प्राथमिक एन और तीन प्रतिकृतियों का स्थान हद तक नहीं बदलता है। जब एसएम सीमा रखता है, तो सीमा की जानकारी ग्राहक को वापस भेज दी जाती है, जो तब जानता है कि कौन से ईएनएस में तीन प्रतिकृतियां हैं और उनमें से कौन सी प्राथमिक है। यह जानकारी स्ट्रीम मेटाडेटा का हिस्सा बन जाती है और क्लाइंट पर कैश की जाती है। जब स्ट्रीम में अंतिम सीमा सील हो जाती है, तो प्रक्रिया दोहराती है। एसएम एक और सीमा रखता है, जो अब स्ट्रीम पर अंतिम सीमा बन जाता है, और सभी नए लेखन ऑपरेशन नए अंतिम सीमा पर किए जाते हैं। हद के लिए, प्रत्येक ऐड ऑपरेशन को तीन बार दोहराया गया है सभी हद तक प्रतिकृतियां, और क्लाइंट प्राथमिक एन के लिए सभी लिखने के अनुरोध भेजता है, लेकिन रीड ऑपरेशन किसी भी प्रतिकृति से, यहां तक कि अनसुना extents के लिए भी किया जा सकता है। ऐड ऑपरेशन को प्राथमिक EN में भेजा जाता है, और प्राथमिक EN हद में शिफ्ट को निर्धारित करने के लिए जिम्मेदार होता है, साथ ही उस घटना में सभी लिखने के संचालन का आदेश देता है जो एक समानांतर रिकॉर्डिंग एक सीमा में होती है, दो सेकंड के EN द्वारा आवश्यक बदलाव के साथ ऐड ऑपरेशन भेजना और क्लाइंट को ऑपरेशन की पुष्टि भेजना। , जो तीनों प्रतिकृतियों पर ऐड ऑपरेशन की पुष्टि होने पर ही भेजा जाता है। यदि प्रतिकृतियों में से कोई प्रतिक्रिया नहीं करता है या कुछ हार्डवेयर त्रुटि उत्पन्न होती है (या हुई है), तो क्लाइंट को एक लिखित त्रुटि दी जाती है। इस स्थिति में, ग्राहक एसएम से संपर्क करता है और जिस हद तक राइट ऑपरेशन होता है, एसएम सील हो जाता है।
एसएम तब अन्य उपलब्ध ईएन पर प्रतिकृतियों के साथ एक नई सीमा रखता है और इस सीमा को अंतिम धारा के रूप में चिह्नित करता है, और यह जानकारी क्लाइंट को वापस कर दी जाती है, जो नई सीमा तक जोड़ने का संचालन करना जारी रखता है। यह उल्लेखनीय है कि सीलिंग और एक नई सीमा रखने के लिए कार्रवाई का पूरा क्रम औसतन केवल 20 मिलीसेकंड पर किया जाता है।
सीलिंग प्रक्रिया के लिए ही। हद को सील करने के लिए, एसएम तीनों EN को उनकी वर्तमान लंबाई के बारे में बताता है। दो परिदृश्यों को सील करने की प्रक्रिया में - या तो एक ही आकार के सभी प्रतिकृतियां, या एक प्रतिकृतियां दूसरों की तुलना में लंबी या छोटी होती हैं। दूसरी स्थिति केवल तब होती है जब ऐड ऑपरेशन विफल हो जाता है जब कुछ ईएस (लेकिन सभी नहीं) उपलब्ध नहीं थे। जब सीलिंग सीमा होती है, एसएम उपलब्ध ईएनएस के आधार पर सबसे छोटी लंबाई का चयन करता है। यह आपको एक्सटेंशन को सील करने की अनुमति देता है ताकि क्लाइंट के लिए पुष्टि किए गए सभी परिवर्तन सील हो जाएं। सील करने के बाद, पुष्टि की गई सीमा की लंबाई अब नहीं बदलती है, और यदि SM सीलिंग के दौरान EN से संपर्क नहीं कर सकता है, लेकिन तब EN उपलब्ध हो जाता है, SM इस EN को पुष्टि की गई लंबाई के साथ सिंक्रनाइज़ करने के लिए बाध्य करता है, जिसके परिणामस्वरूप बिट्स का एक समान सेट होता है।
हालांकि, यहां एक अलग स्थिति उत्पन्न हो सकती है - एसएम एन से संपर्क नहीं कर सकता है, हालांकि, विभाजन सर्वर, जो क्लाइंट है, कर सकता है। विभाजन परत, जिसके बारे में थोड़ी देर बाद, दो रीडिंग मोड हैं - ज्ञात पदों में रिकॉर्ड पढ़ना और स्ट्रीम में सभी रिकॉर्ड पर पुनरावृत्ति का उपयोग करना। पहले के रूप में - विभाजन परत दो प्रकार की स्ट्रीम का उपयोग करती है - रिकॉर्डिंग और बूँद। इन स्ट्रीम रीड ऑपरेशंस के लिए हमेशा कुछ पदों (सीमा + बदलाव, लंबाई) के लिए होता है। विभाजन परत इन दो प्रकारों के लिए रीड ऑपरेशन करती है, स्ट्रीम लेयर पर पिछले सफल ऐड ऑपरेशन के बाद लौटी स्थिति की जानकारी का उपयोग करके, जो केवल तब होता है जब सभी तीन प्रतिकृतियों ने ऐड ऑपरेशन के सफल समापन की सूचना दी है। दूसरे मामले में, जब स्ट्रीम में सभी रिकॉर्ड क्रमिक रूप से क्रमबद्ध हो जाते हैं, तो प्रत्येक विभाजन में दो अलग स्ट्रीम (मेटाडेटा और पुष्टिकरण लॉग) होते हैं, जो कि विभाजन परत शुरुआत से अंत तक क्रमिक रूप से पढ़ेगी।
विंडोज एज़्योर स्टोरेज में, एक तंत्र पेश किया गया है जो आपको डेटा उपलब्धता के स्तर को कम किए बिना उपयोग किए गए डिस्क स्थान और ट्रैफ़िक को बचाने की अनुमति देता है, और इसे इरेज़र कोड कहा जाता है। इस तंत्र का सार यह है कि हद को लगभग समान आकार के एन टुकड़ों में विभाजित किया गया है (व्यवहार में, ये फिर से फाइलें हैं), जिसके बाद रीड-सोलोमन एल्गोरिदम के अनुसार, त्रुटि-सुधार कोड के एम टुकड़े जोड़े जाते हैं। इसका क्या मतलब है? N टुकड़े के किसी भी X का आकार मूल फ़ाइल के आकार के बराबर है; मूल फ़ाइल को पुनर्स्थापित करने के लिए, यह किसी भी टुकड़े के X को इकट्ठा करने और डीकोड करने के लिए पर्याप्त है, शेष NX टुकड़े को हटाया, तोड़ा, और इसी तरह से हटाया जा सकता है। जब तक सिस्टम में त्रुटि सुधार कोड के एम टुकड़े से अधिक संग्रहीत किए जाते हैं, तब तक सिस्टम पूरी तरह से मूल सीमा को बहाल कर सकता है।
क्लाउड स्टोरेज में संग्रहीत डेटा की बड़ी मात्रा के लिए सीलबंद extents का इस तरह का अनुकूलन बहुत महत्वपूर्ण है, क्योंकि यह आपको स्रोत डेटा के तीन पूर्ण प्रतिकृतियों से संग्रहीत डेटा की लागत को कम करने के लिए उपयोग किए गए टुकड़ों की संख्या के आधार पर 1.3-1.5 स्रोत डेटा की अनुमति देता है, और आपको डेटा की "स्थिरता" बढ़ाने की अनुमति भी देता है। एक भंडारण टिकट के अंदर तीन प्रतिकृतियां संग्रहीत करने की तुलना में।जब तीन प्रतिकृतियां होती हैं, तो एक निश्चित समय मान के साथ निष्पादन के लिए सभी ऑपरेशन डाल दिए जाते हैं, और यदि ऑपरेशन इस समय के दौरान पूरा नहीं होता है, तो यह ऑपरेशन नहीं किया जाना चाहिए। यदि एन यह निर्धारित करता है कि रीड ऑपरेशन एक निश्चित समय में पूरी तरह से पूरा नहीं हो सकता है, तो यह तुरंत क्लाइंट को रिपोर्ट करता है। यह तंत्र क्लाइंट को रीड ऑपरेशन के साथ एक अलग EN तक पहुंचने की अनुमति देता है।इसी तरह जिस डेटा के लिए इरेज़िंग कोडिंग का उपयोग किया जाता है - जब रीड ऑपरेशन में भारी लोड के कारण समय अवधि को पूरा करने का समय नहीं होता है, तो इस ऑपरेशन का उपयोग डेटा के पूर्ण टुकड़े को पढ़ने के लिए नहीं किया जा सकता है, लेकिन यह डेटा पुनर्निर्माण विकल्प का लाभ उठा सकता है, जिस स्थिति में रीड ऑपरेशन को संदर्भित करता है इरेज़र कोड के साथ हद के सभी टुकड़े, और आवश्यक टुकड़े को फिर से संगठित करने के लिए पहले एन उत्तरों का उपयोग किया जाएगा।यह देखते हुए कि एक डब्ल्यूएएस प्रणाली बहुत बड़ी धाराओं को संभाल सकती है, निम्न स्थिति उत्पन्न हो सकती है: कुछ शारीरिक डिस्क सेवा और बड़े पढ़ने या लिखने के संचालन के लिए सीमित हैं, अन्य संचालन के लिए बैंडविड्थ में कटौती करना शुरू करते हैं। इस स्थिति को रोकने के लिए, WAS डिस्क पर नए I / O संचालन को असाइन नहीं करता है जब इसे पहले से ही असाइन किए गए ऑपरेशन हैं जो 100 मिलीसेकंड से अधिक के लिए किए जा सकते हैं या जब पहले से ही असाइन किए गए संचालन को असाइन किया गया है, लेकिन 200 मिलीसेकंड में पूरा नहीं हुआ है।जब डेटा को स्ट्रीम लेयर द्वारा रिकॉर्ड किए जाने के लिए निर्धारित किया जाता है, तो एक अतिरिक्त पूरे डिस्क या एसएसडी का उपयोग सभी एन राइट ऑपरेशन के लॉग के लिए भंडार के रूप में किया जाता है। जर्नलिंग डिस्क पूरी तरह से एक जर्नल के लिए आरक्षित है, जिसमें सभी लिखने के संचालन क्रमिक रूप से लॉग होते हैं। जब प्रत्येक EN एक ऐड ऑपरेशन करता है, तो वह सभी डेटा को जर्नलिंग डिस्क पर लिखता है और डिस्क पर डेटा लिखना शुरू करता है। यदि जर्नलिंग डिस्क पहले एक सफल ऑपरेशन कोड देता है, तो डेटा को मेमोरी में बफ़र किया जाएगा और जब तक डेटा डिस्क पर डेटा नहीं लिखा जाता है, तब तक सभी रीड ऑपरेशंस को मेमोरी से सेवा दी जाएगी। जर्नलिंग डिस्क का उपयोग करना महत्वपूर्ण लाभ प्रदान करता है, उदाहरण के लिए, क्लाइंट के लिए ऑपरेशन की पुष्टि करने के लिए डेटा डिस्क से रीड ऑपरेशन के साथ संचालन को "प्रतिस्पर्धा" नहीं करना चाहिए।लॉग विभाजन परत के साथ संचालन को और अधिक सुसंगत बनाने और कम देरी करने की अनुमति देता है।Partition Layer (PL).इस परत में विशेष विभाजन सर्वर (डेमॉन प्रक्रियाएं) शामिल हैं और इसका उद्देश्य वास्तविक भंडारण सार (बूँदें, टेबल, कतारें), नाम स्थान, लेनदेन के आदेश, वस्तुओं की सख्त स्थिरता, SL पर डेटा संग्रहीत करना और I / O संचालन की संख्या को कम करने के लिए डेटा का प्रबंधन करना है। डिस्क के लिए। पीएल भी विभाजननाम के अनुसार एसएस के अंदर डेटा ऑब्जेक्ट को विभाजित करने में शामिल हैं और विभाजन सर्वर के बीच लोड को संतुलित करते हैं। विभाजन परत एक आंतरिक डेटा संरचना प्रदान करता है जिसे ऑब्जेक्ट टेबल (ओटी) कहा जाता है, जो एक बड़ी तालिका है जो कई पेटाबाइट्स तक बढ़ सकती है। ओटी, भार के आधार पर, गतिशील रूप से रेंजपार्टिशन में विभाजित किया जाता है और स्टोरेज स्टैम्प के अंदर सभी विभाजन सर्वर में वितरित किया जाता है। रेंजपार्ट ओटी में रिकॉर्ड की एक श्रृंखला है,प्रदान की गई सबसे छोटी कुंजी से लेकर सबसे बड़ी कुंजी तक।ओटी के कई अलग-अलग प्रकार हैं:• स्टोरेज स्टैम्प से जुड़े प्रत्येक संग्रहण खाते के लिए खाता तालिका मेटाडेटा और कॉन्फ़िगरेशन।• ब्लॉब टेबल स्टोरेज स्टैम्प से जुड़े सभी खातों के लिए सभी ब्लॉब ऑब्जेक्ट्स को स्टोर करता है।• एंटिटी टेबल स्टोरेज स्टैम्प से जुड़े सभी स्टोरेज खातों के लिए सभी इकाई रिकॉर्ड को संग्रहीत करता है और इसका उपयोग विंडोज एज़्योर टेबल स्टोरेज सेवा के लिए किया जाता है।• मैसेज टेबल स्टोरेज स्टैम्प से जुड़े सभी संग्रहण खातों के लिए सभी कतारों के लिए सभी संदेशों को संग्रहीत करता है।• स्कीम टेबल सभी ओटी के लिए स्कीमा का ट्रैक रखता है।• विभाजन मानचित्र तालिका सभी टेबल के लिए सभी वर्तमान रेंजपार्टी का ट्रैक रखती है और कौन सा विभाजन सर्वर किस रेंजपार्टिशन की सेवा दे रहा है। इस तालिका का उपयोग FE सर्वर द्वारा आवश्यक विभाजन सर्वर के अनुरोधों को पुनर्निर्देशित करने के लिए किया जाता है।सभी प्रकार के तालिकाओं में निश्चित स्कीमा हैं, जो स्कीमा टेबल में संग्रहीत हैं।सभी ओटी योजनाओं के लिए, संपत्ति प्रकारों का एक मानक सेट है - बूल, बाइनरी, स्ट्रिंग, डेटटाइम, डबल, GUID, int32 और int64, इसके अलावा, सिस्टम दो विशेष गुणों DictionaryType और BlobType का समर्थन करता है, जिनमें से पहला एक रिकॉर्ड के रूप में एक विशिष्ट योजना के बिना गुणों को जोड़ने की अनुमति देता है। । ये गुण शब्दकोश प्रकार के अंदर संग्रहीत हैं(नाम, प्रकार, मूल्य)। दूसरी विशेष संपत्ति का उपयोग बड़ी मात्रा में डेटा संग्रहीत करने के लिए किया जाता है और वर्तमान में इसका उपयोग केवल बूँद तालिका के लिए किया जाता है, जबकि बूँद डेटा को रिकॉर्ड की सामान्य स्ट्रीम में संग्रहीत नहीं किया जाता है, लेकिन बूँद डेटा के लिए एक अलग स्ट्रीम में, वास्तव में, केवल बूँद डेटा के लिए एक लिंक संग्रहीत किया जाता है (सूची लिंक "हद + पारी, लंबाई")। ओटी मानक संचालन का समर्थन करते हैं - सम्मिलित करें, अपडेट करें, हटाएं और पढ़ें, साथ ही एक एकल विभाजन मान वाले रिकॉर्ड के लिए बैच लेनदेन। एक एकल बैच में संचालन एकल लेनदेन के रूप में पुष्टि की जाती है। ओटी भी स्नैपशॉट अलगाव का समर्थन करते हैं ताकि पढ़ने के संचालन को लिखने के संचालन के साथ समानांतर में चलाने की अनुमति मिल सके।विभाजन परत वास्तुकला
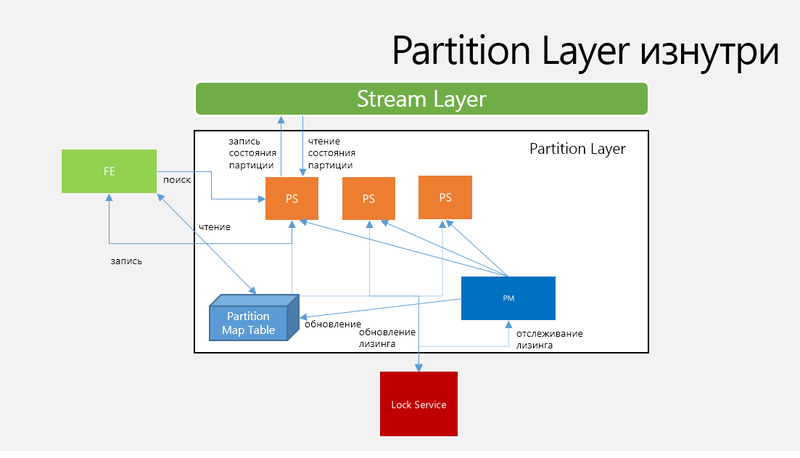
अंजीर।
4. आर्किटेक्चर और वर्कफ़्लो विभाजन परतविभाजन प्रबंधक (पीएम) स्टोरेज स्टैम्प के भीतर एन रेंजपार्टिशन पर बड़े ओटी को मॉनिटर और शेयर करता है और विशिष्ट विभाजन सर्वर को रेंजपार्टिशन प्रदान करता है। यह कहाँ संग्रहीत है के बारे में जानकारी विभाजन मानचित्र तालिका में संग्रहीत है। एक RangePartition एक सक्रिय विभाजन सर्वर को सौंपा गया है, जो यह सुनिश्चित करता है कि दो RangePartitions प्रतिच्छेद नहीं करेंगे।प्रत्येक स्टोरेज स्टैंप में PM के कई उदाहरण हैं और उनमें से सभी लॉक सर्विस में एक लीडर लॉक के लिए "प्रतिस्पर्धा" करते हैं।विभाजन सर्वर (PS)इस पीएम सर्वर को सौंपी गई रेंजपार्टिशन के लिए अनुरोध करता है और धाराओं में सभी विभाजन की स्थिति को संग्रहीत करता है और मेमोरी में कैश का प्रबंधन करता है। PS कई OT से कई रेंजपार्टिशन परोसने में सक्षम है, संभवतः एक दर्जन तक की औसत। PS निम्नलिखित घटकों को मेमोरी में स्टोर करके कार्य करता है:• मेमोरी टेबल , रेंजपार्टिशन के लिए पुष्टिकरण लॉग का एक संस्करण, जिसमें हाल के सभी बदलाव हैं, जो अभी तक एक चेकपॉइंट द्वारा पुष्टि नहीं किए गए हैं।• सूचकांक कैश , एक कैश जिसमें रिकॉर्ड्स के डेटा स्ट्रीम के नियंत्रण बिंदु की स्थिति होती है।• रो डेटा कैश, चेकपॉइंट के लिए रिकॉर्ड डेटा पृष्ठों के लिए मेमोरी में एक कैश। यह कैश केवल-पढ़ने के लिए है। कैश एक्सेस करते समय, रो डाटा कैश और मेमोरी टेबल को दूसरे के लिए वरीयता के साथ जांचा जाता है।• ब्लूम फिल्टर - यदि डेटा रो डेटा कैश और मेमोरी टेबल में नहीं पाया जाता है, तो डेटा स्ट्रीम में स्थितियां और नियंत्रण बिंदुओं की जांच की जाती है, और उनका मोटा गणना अप्रभावी होगा, इसलिए, प्रत्येक नियंत्रण बिंदु पर विशेष ब्लूम फ़िल्टर का उपयोग किया जाता है, जो इंगित करता है कि क्या यह हो सकता है नियंत्रण बिंदु पर रिकॉर्ड तक पहुंच।ताला सेवासेवारत पीएम का चयन करने के लिए उपयोग किया जाता है। प्रत्येक PS विभाजनों की सेवा के लिए एक लॉक सेवा के साथ पट्टे का प्रबंधन करता है। एक PS त्रुटि के साथ, इस PS की सेवा करने वाले सभी N RangePartitions उपलब्ध PS को पुन: असाइन किए जाते हैं। पीएम अपने भार के आधार पर एन पीएस का चयन करते हैं, फिर पीएम रेंजपार्टिशन पीएस को असाइन करता है और उपयुक्त डेटा के साथ पार्टीशन मैप टेबल को अपडेट करता है, जिससे पार्ट-एंड लेयर को पार्टपार्ट मैप टेबल पर पहुंचकर रेंजपार्टिशन का स्थान खोजने की अनुमति मिलती है। रेंजपार्टिशन डेटा को बचाने के लिए लॉग-स्ट्रक्चर्ड मर्ज-ट्री का उपयोग करता है, प्रत्येक रेंजपार्टिशन में स्ट्रीम लेयर पर स्ट्रीम का अपना सेट होता है और स्ट्रीम एक विशेष रेंजपार्टिशन को पूरी तरह से संदर्भित करता है।प्रत्येक रेंजपार्टिशन में निम्न में से एक धारा शामिल हो सकती है :• मेटाडाटा स्ट्रीम- यह स्ट्रीम रेंजपार्टिशन के लिए मुख्य है। पीएम उस पीएस का मेटाडेटा स्ट्रीम नाम प्रदान करके एक PS विभाजन प्रदान करता है।• कमिट लॉग स्ट्रीम - इस स्ट्रीम को रेंजपार्टिशन के लिए जेनरेट किए गए अंतिम बिंदु से रेंजपार्टिशन पर लागू किए गए पुष्टिकरण, अपडेट और डिलीट के लॉग को स्टोर करने के लिए बनाया गया है।• पंक्ति डेटा स्ट्रीम डेटा और स्थिति RangePartitions रिकॉर्डिंग रहता है• ब्लॉब डाटा स्ट्रीम केवल दुकान डेटा धब्बे को ब्लॉब टेबल के लिए प्रयोग किया जाता है।ओटी रेंजपार्टिशन द्वारा प्रबंधित स्ट्रीम लेयर में सभी सूचीबद्ध स्ट्रीम अलग-अलग स्ट्रीम हैं। ओटी में प्रत्येक रेंजपार्टिशन में केवल एक डेटा स्ट्रीम होता है, जिसमें ब्लॉब टेबल को छोड़कर - ब्लॉब टेबल में रेंजपार्टमेंट में रिकॉर्डिंग के लिए अंतिम नियंत्रण बिंदु (ब्लॉब पोजिशन) को बचाने के लिए डेटा रिकॉर्ड और एक विशेष ब्लॉब टाइप प्रकार के डेटा को सेव करने के लिए ब्लॉब के लिए एक अलग डेटा स्ट्रीम होती है।रेंजपार्टिशन लोड संतुलन
विभाजन सर्वर के बीच लोड को संतुलित करने और भंडारण स्टाम्प में विभाजन की कुल संख्या निर्धारित करने के लिए, पीएम तीन ऑपरेशन करता है:
•
भार संतुलन। इस ऑपरेशन का उपयोग करते हुए, यह निर्धारित किया जाता है कि एक विशेष पीएस बहुत अधिक लोड के तहत है, और फिर एक या अधिक रेंजपार्टिशन कम लोड किए गए पीएस को पुन: असाइन किया जाता है।
•
विभाजित। यह ऑपरेशन तब निर्धारित करता है जब एक विशेष रेंजपार्टिशन बहुत अधिक लोड के तहत होता है और इस रेंजपार्टिशन को दो या अधिक छोटे विभाजनों में विभाजित किया जाता है, जिसके बाद इन रेंजपार्टिशन को दो या अधिक पीएस में वितरित किया जाता है। पीएम एक स्प्लिट कमांड भेजता है, लेकिन यह तय करता है कि अकाउंटनाम और विभाजननाम के आधार पर विभाजन को कहाँ विभाजित किया जाएगा, PS। इस मामले में, उदाहरण के लिए, रेंजपार्टिशन बी को दो रेंजपार्टिशन सी और डी में विभाजित करने के लिए, निम्नलिखित ऑपरेशन किए जाते हैं:
o PM C और D में B को अलग करने के लिए PS कमांड भेजता है।
o PS, B के लिए एक ब्रेकपॉइंट बनाता है और ट्रैफ़िक प्राप्त करना बंद कर देता है।
o PS एक विशेष MultiModify कमांड को निष्पादित करता है, B से धाराएँ एकत्र करता है (मेटाडेटा, पुष्टिकरण लॉग और डेटा) और उसी क्रम में C और D के लिए नए स्ट्रीम सेट बनाता है जैसा कि B में होता है (यह जल्दी से होता है, क्योंकि वास्तव में, केवल डेटा के संकेत)। PS फिर मेटाडेटा में C और D के लिए नई विभाजन कुंजी श्रेणियाँ जोड़ता है।
o PS नए विभाजन C और D के लिए यातायात सेवा फिर से शुरू करता है।
o PS विभाजन के PM को सूचित करता है, विभाजन मानचित्र तालिका और मेटाडेटा को अद्यतन करता है, फिर विभाजन विभाजन को विभिन्न PS में स्थानांतरित करता है।
•
मर्ज। इस ऑपरेशन के साथ, दो "ठंडे" या हल्के ढंग से लोड किए गए रेंजपार्टिशन को उनके ओटी में एक महत्वपूर्ण सीमा बनाने के लिए संयुक्त किया जाता है। ऐसा करने के लिए, पीएम आसन्न विभाजन के साथ दो रेंजपार्टिशन का चयन करता है जिनका नाम कम भार होता है, और निम्न क्रियाओं को करता है:
o PM C और D को स्थानांतरित करता है ताकि वे एक PS द्वारा परोसें, और PS को C और D को E में मिलाने की आज्ञा दें।
o PS, C और D के लिए चौकी को बचाता है और C और D को ट्रैफ़िक की सेवा करने से थोड़ी देर रोकता है।
o PS एक नई पुष्टिकरण लॉग और डेटा स्ट्रीम बनाने के लिए MultiModify कमांड को कार्यान्वित करता है। ई। इन धाराओं में से प्रत्येक C और D से संबंधित धाराओं से सभी extents का एक संघ है।
o PS एक E मेटाडेटा स्ट्रीम बनाता है जिसमें पुष्टिकरण लॉग और डेटा स्ट्रीम, E और पॉइंटर्स (सीमा + शिफ्ट) के लिए कुंजियों की एक संयुक्त श्रेणी होती है, जो पुष्टि लॉग (C और D से) के लिए होती है।
o RangePartition E के लिए ट्रैफ़िक सेवा शुरू होती है।
o PM विभाजन मानचित्र और मेटाडेटा अद्यतन करता है।
निम्नलिखित मीट्रिक लोड संतुलन के लिए ट्रैक किए जाते हैं:
• प्रति सेकंड लेनदेन की संख्या।
• लंबित लेनदेन की औसत संख्या।
• सीपीयू लोड।
• नेटवर्क लोड।
• विलंबित अनुरोध।
• रेंजपार्टिशन डेटा का आकार।
उसी समय, पीएम प्रत्येक पीएस के दिल की धड़कन को नियंत्रित करता है, और इस बारे में जानकारी दिल की धड़कन के जवाब में पीएम को वापस प्रेषित होती है। यदि पीएम देखता है कि रेंजपार्टिशन बहुत अधिक लोड (मेट्रिक्स के आधार पर) का अनुभव कर रहा है, तो यह विभाजन को साझा करता है और स्प्लिट ऑपरेशन करने के लिए PS कमांड भेजता है। यदि PS स्वयं ही भारी लोड के अधीन है, लेकिन रेंजपार्टिशन नहीं है, तो पीएम कम रेंज वाले PS को मौजूदा RangePartitions PS को पुन: असाइन करता है। रेंजपार्टिशन पर लोड को संतुलित करने के लिए, पीएम वर्तमान ब्रेकपॉइंट को रिकॉर्ड करने के लिए रेंजपार्टिशन के साथ एक पीएस कमांड भेजता है, जिसके बाद पीएस पीएम की पुष्टि भेजता है और पीएम एक दूसरे पीएस को रेंजपार्टिशन ओवरराइड करता है और पार्टिशन मैप टेबल को अपडेट करता है।
हैश-आधारित इंडेक्सिंग (जब ऑब्जेक्ट को उनके प्रमुख हैश द्वारा सर्वर को सौंपा जाता है) के बजाय एक श्रेणी-आधारित विभाजन तंत्र (जो रेंजपार्टिशन चलता है) का चयन करने का निर्णय इस तथ्य से उचित था कि रेंज-आधारित विभाजन एक विशिष्ट खाते की वस्तुओं के बाद से प्रदर्शन अलगाव को लागू करना आसान बनाता है। रेंजपार्टिशन सेट के भीतर कंधे से कंधा मिलाकर संग्रहीत, हैश-आधारित इंडेक्सिंग सर्वर पर लोड को संतुलित करने के कार्य को भी सरल करता है, लेकिन साथ ही अलगाव उद्देश्यों के लिए वस्तुओं के स्थानीयता के लाभ से वंचित करता है। और कुशल लिस्टिंग। सीमाओं के आधार पर विभाजन आपको एक ग्राहक की वस्तुओं को विभाजन के एक सेट में संग्रहीत करने की अनुमति देता है, जो संभावित असुरक्षित खातों को प्रभावी ढंग से सीमित या अलग करने की क्षमता भी प्रदान करता है। इस दृष्टिकोण की कमियों में से एक अनुक्रमिक पहुंच परिदृश्यों में स्केलिंग है - उदाहरण के लिए, यदि क्लाइंट अपने सभी डेटा को टेबल कुंजी रेंज के बहुत अंत तक लिखता है, तो सभी लेखन ऑपरेशन क्लाइंट टेबल के नवीनतम रेंजपार्टिशन पर रीडायरेक्ट किए जाएंगे। इस मामले में, सिस्टम में विभाजन और लोड संतुलन का उपयोग नहीं किया जाता है। यदि क्लाइंट बड़ी संख्या में PartNNames को लिखने के संचालन को वितरित करता है, तो सिस्टम जल्दी से तालिका को रेंजपार्टिशन के एक सेट में विभाजित करता है और उन्हें कई सर्वरों में वितरित करता है, जो दक्षता को रैखिक रूप से बढ़ाने की अनुमति देता है।
फ्रंट-एंड (FE)। फ्रंटएंड लेयर में स्टेटलेस सर्वर का एक सेट होता है जो आने वाले अनुरोधों को स्वीकार करता है। अनुरोध प्राप्त होने पर, FE खाता नाम को पढ़ता है, अनुरोध को प्रमाणित करता है और प्राधिकृत करता है, और फिर इसे पीएल पर विभाजन सर्वर पर स्थानांतरित करता है (प्राप्त विभाजननाम के आधार पर)। FE के स्वामित्व वाले सर्वर तथाकथित विभाजन मानचित्र को कैश करते हैं, जिसमें सिस्टम PartNName पर्वतमाला के कुछ ट्रैकिंग का प्रबंधन करता है और विभाजन सर्वर जो विभाजन कर रहा है, उसका विभाजन करता है।
इंट्रा-स्टैम्प प्रतिकृति (स्ट्रीम परत)। यह तंत्र समकालिक प्रतिकृति और डेटा सुरक्षा को नियंत्रित करता है। यह किसी भी त्रुटि के मामले में इस डेटा को बचाने के लिए अलग-अलग त्रुटि डोमेन में अलग-अलग नोड्स पर पर्याप्त प्रतिकृतियां बचाता है, और यह पूरी तरह से एसएल पर चलता है। क्लाइंट से प्राप्त लिखित कार्रवाई के मामले में, पूरी तरह से सफल प्रतिकृति के बाद ही इसकी पुष्टि की जाती है।
अंतर-स्टाम्प प्रतिकृति (विभाजन परत)। यह प्रतिकृति तंत्र SSs के बीच अतुल्यकालिक प्रतिकृति करता है, और यह पृष्ठभूमि में इस प्रतिकृति को निष्पादित करता है। ऑब्जेक्ट स्तर पर प्रतिकृति होती है, अर्थात, या तो पूरे ऑब्जेक्ट को दोहराया जाता है, या इसके परिवर्तन (डेल्टा) को दोहराया जाता है।
इन तंत्रों में अंतर है कि इंट्रा-स्टैंप लोहे की त्रुटियों के खिलाफ स्थिरता प्रदान करता है जो समय-समय पर बड़े पैमाने पर सिस्टम में होते हैं, जबकि अंतर-स्टैंप विभिन्न आपदाओं के खिलाफ भौगोलिक अतिरेक प्रदान करता है जो शायद ही कभी होता है। इस प्रकार की प्रतिकृति के लिए एक मुख्य परिदृश्य प्राकृतिक आपदाओं से उबरने के लिए दो डेटा केंद्रों के बीच संग्रहण खाता डेटा की भौगोलिक प्रतिकृति है।
बूँद और तालिका भंडारण सेवाओं में सभी डेटा भौगोलिक रूप से दोहराए जाते हैं (लेकिन कोई कतार नहीं हैं)। भौगोलिक रूप से बेमानी भंडारण के साथ, मंच फिर से तीन प्रतिकृतियां बचाता है, लेकिन दो स्थानों पर। भंडारण खाते का विस्तार करते समय, एलएस भौगोलिक स्थानों में से प्रत्येक में संग्रहण टिकट का चयन करता है और सभी संग्रहण टिकटों में चयनित खातानाम को पंजीकृत करता है, जबकि स्थानों में से एक को लाइव ट्रैफ़िक प्राप्त होगा, जबकि दूसरा, द्वितीयक, केवल अंतर-स्टांप प्रतिकृति का प्रदर्शन करेगा (वास्तव में और भौगोलिक प्रतिकृति है)। रास फिर मुख्य स्थान के वीआईपी के लिए अग्रणी नए AccountName.service.core.windows.net प्रविष्टि के लिए DNS को अद्यतन करता है। इस प्रकार, यदि डेटा सेंटर में कुछ होता है, तो डेटा दूसरे स्थान से उपलब्ध होगा। जब लेखन ऑपरेशन वॉल्ट खाते के लिए मुख्य स्थान पर आता है, तो स्ट्रीम लेयर पर इंट्रा-स्टैम्प प्रतिकृति का उपयोग करके परिवर्तन पूरी तरह से दोहराया जाता है, जिसके बाद ऑपरेशन के सफल समापन पर कोड क्लाइंट को वापस कर दिया जाता है। अतुल्यकालिक मोड में ऑपरेशन की पुष्टि होने पर, एक अन्य भौगोलिक स्थान के लिए प्रतिकृति होती है और वहां लेनदेन परत में पहले से ही लेनदेन लागू होता है।
भौगोलिक दोष सहिष्णुता और गंभीर व्यवधानों की स्थिति में सब कुछ कैसे बहाल किया जाता है। यदि मुख्य भौगोलिक स्थिति में एक गंभीर गड़बड़ हुई है, तो यह स्वाभाविक है कि निगम अधिकतम परिणामों को सुचारू करने की कोशिश करता है। हालांकि, अगर सब कुछ बहुत खराब है और डेटा खो गया है, तो भौगोलिक दोष सहिष्णुता के नियमों को लागू करना आवश्यक हो सकता है - क्लाइंट को मुख्य स्थान पर आपदा के बारे में सूचित किया जाता है, जिसके बाद संबंधित DNS रिकॉर्ड मुख्य स्थान से दूसरे (account.service.core.windows.net) में बाधित होते हैं )। बेशक, डीएनएस रिकॉर्ड का अनुवाद करने की प्रक्रिया में, कुछ काम करने की संभावना नहीं है, लेकिन पूरा होने पर, मौजूदा यूआरएल और टेबल उनके URL पर उपलब्ध हो जाते हैं। अनुवाद प्रक्रिया के पूरा होने के बाद, दूसरी भौगोलिक स्थिति मुख्य एक की स्थिति में बढ़ जाती है (जब तक कि डेटा केंद्र फिर से जमीन से नहीं टूटता)। इसके अलावा, डेटा सेंटर की स्थिति को बढ़ाने की प्रक्रिया के पूरा होने के तुरंत बाद, उसी क्षेत्र में एक नया दूसरा भौगोलिक स्थान बनाने और आगे डेटा प्रतिकृति बनाने की प्रक्रिया शुरू की जाती है। विकास टीम ने घोषणा की कि उपयोगकर्ता यह चुनने में सक्षम होगा कि उसकी दूसरी भौगोलिक स्थिति कहां होगी, यदि एक क्षेत्र में दो से अधिक डेटा केंद्र हैं, लेकिन अभी तक मैंने इस संभावना पर ध्यान नहीं दिया है (संभवतः क्योंकि मैं ऐसे क्षेत्रों को नहीं जानता हूं)।
भौगोलिक प्रतिकृति की प्रक्रिया बहुत अधिक दिलचस्प है यदि केवल इसलिए कि यह हमारे कार्यों को अधिक से अधिक बार प्रभावित करता है जो कि पंचांग डायनासोर की तुलना में अधिक बार होता है, जिसने डेटा केंद्र को खा लिया, जिसके कारण भू-विफलता हुई।
इसलिए, उदाहरण के लिए, हमारे भंडारण खाते में कई ब्लॉब्स (डेवलपर्स के ब्लॉग से एक उदाहरण), फू और बार हैं। ब्लॉब्स के लिए, पूर्ण ब्लॉब नाम PartitionKey मान के बराबर है। हम बूँद फू पर दो लेनदेन ए और बी निष्पादित करते हैं, जिसके बाद हम बूँद बार पर दो लेनदेन एक्स और वाई करते हैं। सिस्टम गारंटी देता है कि लेनदेन A को लेनदेन B से पहले भौगोलिक रूप से दोहराया जाएगा, और तदनुसार, लेनदेन Y को लेनदेन Y से पहले भौगोलिक रूप से दोहराया जाएगा। अन्यथा, कोई गारंटी नहीं है - यह निश्चित रूप से ज्ञात नहीं है कि फू पर लेनदेन और बार पर लेनदेन के बीच भौगोलिक प्रतिकृति पर कितना समय व्यतीत होगा । इसके अलावा, यदि प्रतिकृति के समय डेटा सेंटर किसी कारण से टूट जाता है, जो भौगोलिक रूप से हाल के लेनदेन को दोहराने के लिए असंभव बनाता है, तो ऐसा हो सकता है कि लेनदेन ए और एक्स को दोहराया जाता है, जबकि लेनदेन बी और वाई खो जाएगा। या केवल ए और बी को दोहराया जाता है, और एक्स और वाई गायब हो जाएगा। टेबल सेवाओं के साथ भी ऐसा ही हो सकता है (यह देखते हुए कि तालिकाओं में विभाजन इकाई के विभाजन के आवेदन से निर्धारित होते हैं और खूनी नाम से नहीं)।
सारांश
विंडोज एज़्योर स्टोरेज सेवाएँ प्लेटफ़ॉर्म का एक आवश्यक घटक है, जो क्लाउड स्टोरेज सेवाएँ प्रदान करता है और मजबूत स्थिरता, एक वैश्विक नाम स्थान, और बहु-किरायेदार वातावरणों में उच्च डेटा रिज़िलिएशन जैसी सुविधाओं का संयोजन करता है।