प्रविष्टि
मेरे व्यवहार में, मैं एक केंद्रीकृत संस्करण नियंत्रण प्रणाली (केंद्रीकृत वीसीएस - एसवीएन) से वितरित (वितरित वीसीएस - मर्क्यूरियल) में परियोजना के प्रवास में भाग लेता था (कोडबेस का 5+ वर्ष का इतिहास था)। इस प्रक्रिया में शामिल टीम के बीच FUD (भय, अनिश्चितता और संदेह) की एक निश्चित मात्रा के साथ अक्सर ऐसी गतिविधियां होती हैं। यदि रूपांतरण के तकनीकी पहलुओं (नई रिपॉजिटरी की संरचना, उपकरण का समर्थन, बड़ी द्विआधारी फ़ाइलों के साथ काम करना, एनकोडिंग, आदि) को एक निश्चित समय पर बड़े पैमाने पर हल किया जाएगा, तो टीम के लिए सीखने की अवस्था पर काबू पाने से जुड़े मुद्दों को प्रभावी ढंग से नई प्रणाली का उपयोग करने के लिए, संक्रमण के समय ही शुरू हो सकता है।
ऐसे बदलावों के साथ, नए संस्करण नियंत्रण प्रणाली और इसके उपयोग (मानसिकता बदलाव) के दृष्टिकोण को बदलना महत्वपूर्ण है। जिन सिद्धांतों पर VCS आधारित है, उनकी एक अच्छी समझ बहुत मदद करती है। यदि आप मूल बातें समझते हैं, तो सिस्टम का उपयोग बहुत सरल है। तदनुसार, यह सामग्री केंद्रीयकृत और विकेंद्रीकृत संस्करण नियंत्रण प्रणालियों के बीच मॉडलिंग के इतिहास में अंतर पर ध्यान केंद्रित करेगी।
संरचना में अंतर के बारे में एक छोटा विषयांतर
शुरुआत करने के लिए, मैं संक्षेप में दोनों प्रणालियों की संरचना का संक्षिप्त विवरण दूंगा। आइए
केंद्रीकृत से शुरू करें:
- पारंपरिक VCS को बैकअप, ट्रैक और फ़ाइलों को सिंक्रनाइज़ करने के लिए बनाया गया था।
- सभी परिवर्तन केंद्रीय सर्वर से गुजरते हैं।
 विकेन्द्रीकृत
विकेन्द्रीकृत प्रणाली:
- DVCS में, सभी के पास अपना पूर्ण भंडार है
- डीवीसीएस परिवर्तन साझा करने के लिए बनाए गए थे
- डीवीसीएस का उपयोग करते समय, केंद्रीय सर्वर के साथ कोई हार्ड-कोडित रिपॉजिटरी संरचना नहीं होती है
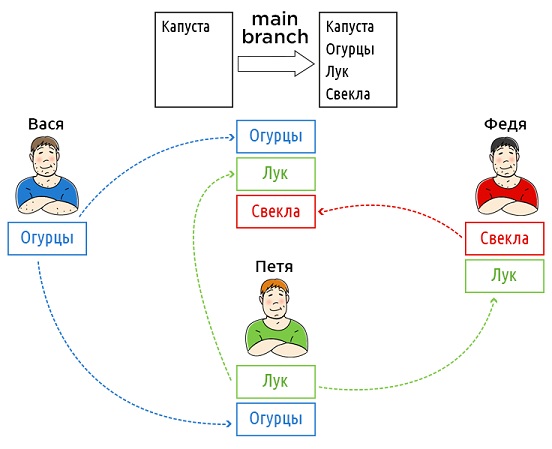
यह बेहतर है कि संरचना में अंतर न करें ताकि सामग्री को बोझ न डालें और मुख्य बात पर अधिक ध्यान केंद्रित करें - दोनों प्रणालियों में इतिहास का मॉडलिंग।
मिथक, तथ्य और प्रतिष्ठा
कोई भी व्यक्ति जो केंद्रीय और विकेंद्रीकृत दोनों प्रणालियों को प्रदान करने वाले अवसरों से परिचित होने का फैसला करता है, वे मिथकों का सामना करेंगे जो उनके उपयोग से जुड़े हैं, और एक निश्चित प्रतिष्ठा जो इन प्रणालियों के पास है। उदाहरण के लिए:
- सक्रिय रूप से ब्रांचिंग और मर्जिंग परिवर्तन (ब्रांचिंग और मर्जिंग) के लिए साधन के रूप में सर्वश्रेष्ठ एसवीएन प्रतिष्ठा नहीं
- "मैजिक" मर्ज टूल के रूप में गिट सिस्टम की प्रतिष्ठा और कमिट को प्रबंधित करने (हटाने, पुन: व्यवस्थित करने, संयोजन, ठंडे बस्ते में डालने) में इसकी बड़ी लचीलापन है।
यदि SVN की खराब प्रतिष्ठा मुख्य रूप से पूर्व संस्करणों में शाखा ट्रैकिंग से जुड़ी मेटाडेटा की कमी के कारण है, तो Git और सभी वितरित प्रणालियों की प्रतिष्ठा, DAG जैसी दिलचस्प चीज से जुड़ी है। मैं यह नोट करना चाहता हूं कि केंद्रीकृत प्रणालियां अभी भी खड़ी नहीं हैं और सक्रिय परिदृश्यों की दिशा में सक्रिय रूप से विकसित हो रही हैं जिनके लिए सक्रिय शाखाओं की आवश्यकता है। लेकिन यह डीएजी के विपरीत, इस सामग्री का विषय नहीं है, जिसे हम बाद में पाठ में अधिक विस्तार से विचार करेंगे।
कैसे केंद्रीकृत प्रणाली उनके इतिहास का मॉडल बनाती है
किसी भी संस्करण नियंत्रण प्रणाली का उपयोग करने में सफलता की कुंजी उस मॉडल को समझने में निहित है जिसका उपयोग इस प्रणाली में परिवर्तनों के इतिहास का प्रतिनिधित्व करने के लिए किया जाता है। आइए केंद्रीकृत प्रणालियों के साथ शुरू करें। यहां कहानी को एक लाइन की तरह बनाया गया है। एक अस्थायी श्रृंखला में हमारा आवागमन शुरू होता है। उपयोग करने और समझने में बहुत आसान है।
सच है, एक बात है लेकिन: हम एक नया संस्करण तभी कर सकते हैं जब यह नवीनतम संस्करण पर आधारित हो। यह वास्तविक परिस्थितियों में कैसा दिखता है:
- डेवलपर्स वास्या और पेट्या सुबह काम करने के लिए आते हैं और नवीनतम संशोधन के लिए अपडेट किए जाते हैं - 2. और वे काम करना शुरू करते हैं, अर्थात कोड लिखते हैं।

- वासा पेटिट से पहले सब कुछ करने का प्रबंधन करता है, इसलिए वह एक नया संशोधन करता है - 3, और एक स्पष्ट विवेक के साथ घर जाता है।
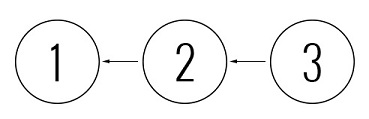
- पेटीए एक नया संशोधन बनाने की कोशिश कर रहा है, वह ऐसा नहीं कर सकता, क्योंकि उसके परिवर्तन संशोधन 2 पर आधारित हैं, और अंतिम संशोधन, वासना के प्रयासों के लिए धन्यवाद, पहले से ही 3 है।

- इसलिए, उसे अपनी कार्यशील प्रति अपडेट करने, परिवर्तनों को मर्ज करने के लिए मजबूर किया जाता है, और उसके बाद ही वह संशोधन 4 को जोड़ सकता है, संशोधन 3 के आधार पर, 2 नहीं।
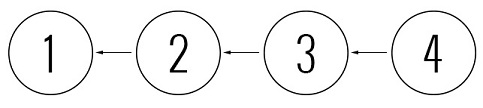
पेट्या को जो लंबे कदम उठाने के लिए मजबूर किया जाता है, वास्तव में, उपयोग किए गए सिस्टम के माध्यम से स्वचालित होते हैं, और डेवलपर के लिए भी ध्यान देने योग्य नहीं हैं। आमतौर पर, इस मामले में, पेट्या एक दुर्जेय सर्वर चेतावनी देखती है, जैसे "आपको पहले से काम करने वाली कॉपी को अपडेट करना होगा", अपडेट किया गया है (वास और पेट्या के बदलावों को यहां विलय कर दिया जाएगा) और एक नया संशोधन करता है।
हास्यास्पद पाठकों को दो बातें नोटिस करेंगी:
- सिस्टम परिवर्तनों के इतिहास के बारे में कुछ जानकारी खो देता है (तथ्य यह है कि शुरू में वासिया और पेटिट के संशोधन संशोधन 2 पर आधारित थे)
- यह मॉडल आपको केवल बाहरी तंत्र का उपयोग करके शाखाकरण का समर्थन करने की अनुमति देता है
आइए इस जानकारी को छोड़ दें और वितरित सिस्टम पर आगे बढ़ें।
कैसे वितरित सिस्टम उनके इतिहास को मॉडल करते हैं
क्या होगा अगर, पिछले उदाहरण में, सिस्टम हमें संशोधन 2 के आधार पर संशोधन 4 करने की अनुमति देगा?
और यह होगा: हमारी कहानी एक पंक्ति (धन्यवाद, कैप) बनना बंद कर देगी और एक ग्राफ में बदल जाएगी। अधिक सटीक रूप से, एक निर्देशित चक्रीय ग्राफ या निर्देशित चक्रीय ग्राफ (DAG) में। विकिपीडिया कृपया हमें इसकी
परिभाषा प्रदान करता है:
"एक निर्देशित ग्राफ का मामला जिसमें कोई निर्देशित चक्र नहीं हैं, अर्थात्, एक ही शीर्ष पर शुरू और समाप्त होने वाले पथ"वितरित सिस्टम इतिहास के मॉडल के लिए DAG का उपयोग करते हैं। जैसा कि आप देख सकते हैं, डीएजी ने कमिट्स के बारे में जानकारी नहीं खोई है, हमारे मामले में, संशोधन 4 संशोधन 2 पर आधारित है।
हालाँकि, सिस्टम में ऐसा कोई संस्करण नहीं है जिसमें एक ही समय में वास्या और पेटिट के परिवर्तन शामिल होंगे। DAG- आधारित उपकरण संशोधन को मर्ज करके इस समस्या को हल करते हैं।

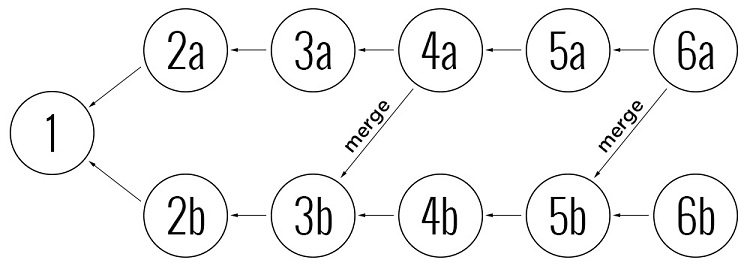
डीएजी का उपयोग करने के एक उदाहरण पर विचार करें, जिसमें हमारे पास एक सामान्य इतिहास वाली दो शाखाएं हैं, और हम संशोधन
5 बी के आधार पर शाखा
बी के साथ शाखा को सिंक्रनाइज़ करना चाहते हैं। परिवर्तनों को स्थानांतरित करते समय, ग्राफ़ में ऐसी जानकारी होती है जो
2 बी और
3 बी में परिवर्तन पहले से ही शाखा
ए के साथ विलय कर दी गई
है , इसलिए आपको केवल शाखा के साथ
4 बी और
5 बी में परिवर्तन करने की आवश्यकता
है । चूंकि DAG पूर्ण मर्ज इतिहास की जानकारी संग्रहीत करता है, इसलिए मर्ज प्रक्रिया अपने आप ही निष्पादित करना बहुत आसान है, यदि हम एक ऐसी प्रणाली का उपयोग करते हैं जो इतिहास को एक पंक्ति के रूप में संग्रहीत करती है और शाखाओं को ट्रैक करने के लिए मेटाडेटा का उपयोग करती है।
जो लोग संस्करण नियंत्रण प्रणालियों के काम में गहराई से खुदाई करना चाहते हैं, मैं
उदाहरण के लिए एरिक सिंक -
संस्करण नियंत्रण पुस्तक की सिफारिश करता हूं।
नवीनतम संस्करण जारी
एक परियोजना पर जहां एक से अधिक डेवलपर काम करते हैं और डीवीसीएस का उपयोग किया जाता है, विकसित किए जा रहे कोड का इतिहास हमेशा एक ग्राफ की तरह दिखेगा, क्योंकि यह वास्तविक तस्वीर को दर्शाता है कि कोड कैसे विकसित किया गया है। यह समझना महत्वपूर्ण है कि इतिहास में किसी भी अतिरिक्त शाखा की एक निश्चित कीमत है जो इसके उपयोग और ट्रैकिंग से जुड़ी है। आप इसके बारे में और अधिक
यहाँ पढ़ सकते हैं।
मैं केवल तथाकथित "नवीनतम संस्करण समस्या" पर ध्यान केंद्रित करना चाहता हूं, जो अक्सर उन लोगों के लिए बहुत सारे सवाल उठाता है जिन्होंने अभी भी डीवीसीएस के साथ शुरुआत की है। मान लीजिए कि हमें सुबह काम करने को मिला और अपनी रिपॉजिटरी को अपडेट किया। इतिहास का चित्र लगभग निम्न चित्र है:

इस स्थिति के कारण काफी तार्किक प्रश्न हो सकते हैं:
- एकीकरण सर्वर को नवीनतम संस्करण संकलित करना चाहिए, लेकिन यह निर्धारित नहीं कर सकता कि कौन से नवीनतम संशोधन हैं
- इसी तरह, क्यूए निर्धारित नहीं कर सकते हैं कि वे किस संस्करण का परीक्षण कर रहे हैं।
- डेवलपर उसी कारण से नवीनतम संस्करण में अपग्रेड नहीं कर सकता है
- यदि कोई डेवलपर रिपॉजिटरी में नया कोड जोड़ना चाहता है, तो उसे किस संशोधन के आधार पर एक नया बनाना चाहिए?
- प्रबंधक को प्रगति का मूल्यांकन करना चाहिए, यह पता लगाना चाहिए कि कितनी कार्यक्षमता पूरी हो गई है। हालाँकि, इसके लिए उसे पता होना चाहिए कि कौन सा संस्करण नवीनतम है।
नवीनतम संस्करण की समस्या एक मुख्य कारण है कि एक लाइन के रूप में इतिहास के साथ आसान केंद्रीकृत सिस्टम के बाद DAG- आधारित टूल का उपयोग लोगों को बहुत अराजक और समझ से बाहर लगता है।
इस समस्या का समाधान परियोजना पर प्रक्रिया के संगठन के विमान में निहित है। उदाहरण के लिए, आप इस तरह की प्रक्रिया का निर्माण कर सकते हैं:
- एकीकरण सर्वर उन सभी संशोधनों या संशोधनों को इकट्ठा करता है जो संकेतित हैं, उदाहरण के लिए, टेस्ट लीड
- क्यूए टीम खुद के लिए या प्रबंधक की मदद से तय करती है कि उन्हें किस संस्करण का परीक्षण करना चाहिए
- डेवलपर को "नवीनतम संस्करण" के लिए अपडेट नहीं किया गया है, लेकिन खुद के लिए निर्णय लेता है कि किस आधार पर संशोधन के लिए एक नई प्रतिबद्धता बनाई जानी चाहिए
यह देखना आसान है कि यहां लागू समाधान के लचीलेपन और जटिलता के बीच संतुलन बनाना आवश्यक है।
सिल्वर बुलेट?
क्या DAG आपके कोड इतिहास के मॉडलिंग के लिए सही समाधान है? आइए इस स्थिति की कल्पना करें: मैं संशोधन 4 बनाना चाहता हूं, जिसमें संशोधन 1 का पूरा इतिहास और केवल संशोधन 3 (संशोधन 2 के रूप में इसके इतिहास के बिना) शामिल है। इस दृष्टिकोण को
चेरी-पिकिंग कहा जाता है और इसे DAG का उपयोग करके मॉडलिंग नहीं किया जा सकता है। हालांकि, कुछ डीवीसीएस एक्सटेंशन के माध्यम से इस तरह के परिदृश्य का अनुकरण कर सकते हैं।

"क्लासिक" DVCS, जैसे Git, Mercurial, और Bazaar, का एक
विकल्प ,
दार्क्स है , एक संस्करण नियंत्रण प्रणाली है जो DAG की तुलना में एक अलग कहानी मॉडलिंग दृष्टिकोण का उपयोग करती है और
केरी स्तर पर चेरी-पिकिंग जैसी स्क्रिप्ट का समर्थन करने में सक्षम है। यह संभव है कि भविष्य में इस तरह के सिस्टम आधुनिक डीवीसीएस को दबाएंगे।