अपनी वैज्ञानिक गतिविधि के हिस्से के रूप में, उन्होंने तथाकथित फेडरेटेड कलमन फ़िल्टर को लागू किया। यह आलेख वर्णन करता है कि "Federated FC" क्या है, यह सामान्यीकृत से कैसे भिन्न होता है, और एक कंसोल एप्लिकेशन का भी वर्णन करता है जो इस गणितीय मॉडल के मापदंडों के चयन के लिए इस फिल्टर और आनुवंशिक एल्गोरिदम को लागू करता है। आवेदन TPL (टास्क पैरेलल लाइब्रेरी) का उपयोग करके लागू किया गया था, इसलिए यह पद न केवल डिजिटल सिग्नल प्रोसेसिंग के विशेषज्ञों के लिए दिलचस्प होगा।
UPD1 :
हाल के दो लेखों को पढ़ने के बाद, मैंने प्रयोग / अनुसंधान / साहसिक कार्य में शामिल होने का फैसला किया (इसे आप क्या चाहते हैं)। लेख के अंत में, मैंने एक और पोल जोड़ दिया - "
क्या आप रूबरू होकर हब्रेब्र पर इस तरह के विशेष रूप से विशेष लेखों को प्रोत्साहित करेंगे? "
परिचय
पहले से ही लिखा है कि कलमन फ़िल्टर (FC), इसके लिए कि यह क्या आवश्यक है और इसकी रचना कैसे की जाती है (वैचारिक रूप से)। नीचे कुछ लेख उपलब्ध हैं।
•
कलमन फ़िल्टर•
कलमन फ़िल्टर - मुश्किल?•
कलमन फ़िल्टर - परिचय•
संवर्धित वास्तविकता की दहलीज पर: डेवलपर्स के लिए क्या तैयार करना है (भाग 2 का 3)•
छोटे यूएवी के लिए गैर-ऑर्थोगोनल SINS•
शास्त्रीय यांत्रिकी: विचलन पर "उंगलियों पर"इसके अलावा, कई चर के गैर-रेखीय कार्यों के अनुकूलन के लिए विभिन्न स्टोचस्टिक एल्गोरिदम के आवेदन के बारे में हैब्रेट पर बहुत सारे लेख हैं। यहाँ मैं विकासवादी एल्गोरिदम, नकली annealing, जनसंख्या एल्गोरिथ्म शामिल हैं। नीचे दिए गए कुछ लेखों के लिंक।
•
एनाउलिंग का तरीका•
आनुवंशिक एल्गोरिथ्म क्या है?•
जेनेटिक एल्गोरिदम। सिद्धांत से अभ्यास तक•
जेनेटिक एल्गोरिदम, छवि पहचान•
आनुवंशिक एल्गोरिथ्म। बस जटिल के बारे में•
समाधान खोजने और उत्पन्न करने के लिए आनुवंशिक एल्गोरिदम•
रोबोकोड बॉट के उदाहरण पर आनुवंशिक एल्गोरिथ्मMATLAB में जेनेटिक एल्गोरिदम•
मछली के एक स्कूल के व्यवहार के आधार पर जनसंख्या एल्गोरिदम•
आनुवंशिक एल्गोरिदम के व्यावहारिक उपयोग के लिए अवधारणा•
तंत्रिका नेटवर्क के विकास के लिए विधियों का अवलोकन•
ताऊ डार्विनवाद•
प्राकृतिक एल्गोरिदम। मधुमक्खी झुंड व्यवहार एल्गोरिथ्म•
प्राकृतिक एल्गोरिदम। मधुमक्खी झुंड एल्गोरिथम का कार्यान्वयनमेरे पिछले लेखों में से एक (
ताऊ-डार्विनवाद: रूबी कार्यान्वयन ), मैंने एक गतिशील प्रणाली के गणितीय मॉडल के मापदंडों का चयन करने के लिए आनुवंशिक एल्गोरिदम (जीए) का उपयोग करने के परिणामों पर आपका ध्यान आकर्षित किया। यह लेख एक और अधिक जटिल समस्या में जीए का उपयोग करने के परिणामों को प्रस्तुत करता है - कलमन फ़िल्टर मॉडल का संश्लेषण। इस कार्य के भाग के रूप में, मैंने एफसी के ट्रांस्फ़ॉर्मेशन मैट्रिक्स (उर्फ ट्रांजिशन मैट्रिक्स) में डायनामिक्स मापदंडों पर आनुवंशिक एल्गोरिदम को "सेट" किया। जीए का उपयोग एफसी में कोवरियस मैट्रिसेस के मूल्यों का चयन करने के लिए भी किया जा सकता है, लेकिन मैंने अभी तक ऐसा नहीं करने का फैसला किया। मैंने स्वयं शोर उत्पन्न किया, क्योंकि मुझे पहले से माप त्रुटियों के सहसंयोजक का मैट्रिक्स पता था। प्रक्रिया शोर सहसंयोजक मैट्रिक्स वास्तव में व्यवहार में कभी नहीं जाना जाता है, इसलिए मैंने पीसी की अधिकतम संवेदनशीलता के आधार पर इसके मूल्य को संक्रमण मैट्रिक्स में मूल्यों में बदलाव के लिए चुना।
जैसा कि हो सकता है, कोवरियस मैट्रिस के मूल्यों के अनुकूलन के मामले में यहां वर्णित समस्या का विस्तार करना मुश्किल नहीं होगा। यह सिर्फ एक अन्य उद्देश्य समारोह को लागू करने के लिए आवश्यक होगा जिसमें व्यक्तिगत जीनों के मूल्यों द्वारा सहसंयोजक मैट्रिक्स उत्पन्न होंगे, और संक्रमण मैट्रिक्स का मूल्य अग्रिम में निर्धारित किया जाएगा। इस प्रकार, एफसी के संश्लेषण की पूरी प्रक्रिया को दो चरणों में विभाजित करना संभव होगा:
1. एफसी के गणितीय मॉडल के मापदंडों का अनुकूलन
2. सहसंयोजक मैट्रिक्स मूल्यों का अनुकूलन
दूसरा चरण, जैसा कि मैंने ऊपर लिखा था, अभी तक लागू नहीं हुआ है। हालांकि, इसका कार्यान्वयन योजनाओं में है।
समस्या का बयान
तो चुनौती। मान लें कि हमारे पास एक निश्चित मापने की प्रणाली है, जिसमें कई सेंसर (मापने वाले चैनल) शामिल हैं। एक उदाहरण के रूप में, मेरे एक अन्य लेख में वर्णित
गैर-ऑर्थोगोनल एसआईएनएस (छोटे यूएवी के लिए गैर-ऑर्थोगोनल एसआईएनएस ) को लें। ऐसी प्रणाली के प्रत्येक सेंसर एक अलग गतिशील प्रणाली है, और समय पर प्रत्येक विशेष क्षण में यह एक स्केलर माप का उत्पादन करता है। कुल आठ मापने वाले चैनल हैं (ब्लॉक में एक्सेलेरोमीटर की संवेदनशीलता अक्षों की संख्या के अनुसार), और तीन मापदंडों के लिए मांग की जाती है (मापने वाले ब्लॉक के रैखिक त्वरण घटक)।
हम सेंसर के बारे में क्या जानते हैं? हमें केवल स्थैतिक मोड में सेंसर से सिग्नल रिकॉर्ड करना है। यानी हमारे लिए, किसी ने तहखाने में कहीं पर एक्सेलेरोमीटर का एक ब्लॉक रखा था और कहते हैं, एक दिन ने एक्सेलेरोमीटर की संवेदनशीलता अक्ष पर गुरुत्वाकर्षण त्वरण के प्रक्षेपण के मूल्यों को लिखा था। इसके अलावा, हमें ब्लॉक में सेंसर के गाइड कोसाइन के मैट्रिक्स का अनुमानित मूल्य दिया जाना चाहिए।
हमारे लिए क्या आवश्यक है? "कलमन फ़िल्टर प्रकार" (FCT) के एल्गोरिथ्म को संकलित करने के लिए, जो मापने की इकाई के रैखिक त्वरण का इष्टतम अनुमान देगा। इष्टतम से मतलब अनुमान त्रुटियों का न्यूनतम विचलन और उनकी अपेक्षा का न्यूनतम ("शून्य" त्रुटियों का न्यूनतम पूर्वाग्रह) है।
नोट: नाम "कलमन टाइप फ़िल्टर" का उपयोग किया जाता है क्योंकि शास्त्रीय एफसी का अर्थ है कि इसका मॉडल एक वास्तविक वस्तु के मॉडल से मेल खाता है, और दूसरे मॉडल के उपयोग को "लेवेनबर्गर आइडेंटिफिकेशन ऑब्जर्विंग डिवाइस" कहा जाता है, जो एफसीटी समूह से संबंधित है।
सेंसर मॉडल के मापदंडों का चयन करने के लिए आनुवंशिक एल्गोरिदम का उपयोग करना प्रस्तावित है। जीन के मूल्यों का उपयोग सेंसर के विभेदक समीकरणों के गुणांक के रूप में किया जाएगा (देखें लेख
ताऊ-डार्विनवाद में "पहचान वस्तु"):
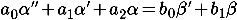
इन गुणांकों के आधार पर, अंतरिक्ष-राज्यों में सेंसर के असतत मॉडल बनाए जाएंगे (देखें।
कलमन फ़िल्टर में "गणितीय मॉडल"
- जटिल! )
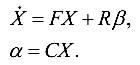
इन मॉडलों के आधार पर, एक "निजी" कलमन प्रकार फिल्टर संकलित किया जाएगा। कई ऐसे "निजी" फिल्टर की एक विधानसभा एक संघीय FCT बनाती है।
किसी व्यक्ति का फिटनेस फ़ंक्शन अनुमान त्रुटियों के वर्गों के औसत मूल्य से विभाजित इकाई का उत्पादन करेगा:

यहाँ n फ़िल्टर मॉडलिंग प्रक्रिया में चरणों की संख्या (रिकॉर्ड किए गए संकेतों में नमूनों की संख्या) है।
फ़ेडरेटेड फ़िल्टर बनाम सामान्यीकृत
मैंने पहले से ही एक सामान्यीकृत एफसी (ओएफके) (
कलमन फ़िल्टर - यह मुश्किल है? ) को संकलित करने की अवधारणा का वर्णन किया है। मैं विस्तार से नहीं बताऊंगा। लब्बोलुआब यह है कि हम सेंसर के अंतर समीकरणों का उपयोग करते हुए राज्य अंतरिक्ष में मॉडल बनाते हैं। अगला, हमें सेंसर मॉडल के विकर्ण मैट्रिक्स को जोड़कर ओएफसी के ब्लॉक-विकर्ण मैट्रिसेस की रचना करने की आवश्यकता है। यानी ऐसे मेट्रिसेस
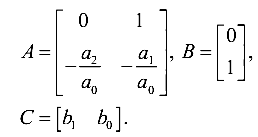
हमें निम्नलिखित की तरह कुछ देना चाहिए (संक्रमण मैट्रिक्स के लिए)

जहां गुणांक का दूसरा सूचकांक सेंसर की संख्या (चैनल को मापने) को इंगित करता है।
अगला महत्वपूर्ण बिंदु एफसी का राज्य वेक्टर है। मोटे तौर पर, इसमें एक्सेलेरोमीटर के पेंडुलम के विस्थापन (विचाराधीन समस्या बयान में) और उनके विस्थापन की गति शामिल है। लेकिन हमें यह गणना करने की आवश्यकता है कि एफसी का उपयोग करके गणना किए गए एक्सीलरोमीटर को राज्य में लाने के लिए हमें ब्लॉक में क्या त्वरण लागू करने की आवश्यकता है। ऐसा करने के लिए, हमें पहले कलमन फ़िल्टर द्वारा निर्मित एक्सीलरोमीटर के संकेतों की गणना करनी चाहिए

जहाँ
 | - सेंसर मॉडल माप मैट्रिक्स से बना ब्लॉक-विकर्ण मैट्रिक्स |
 | - ब्लॉक में सभी सेंसरों के राज्य वेक्टर |
हम सेंसर संकेतों के वेक्टर प्राप्त करने के बाद, यह हमारे लिए किसी भी तरह तीन अज्ञात के साथ आठ समीकरणों के अधिमान्य प्रणाली को हल करने के लिए बनी हुई है

जहाँ
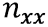 | - एक्सेलेरोमीटर की संवेदनशीलता की कुल्हाड़ियों का मार्गदर्शन करें |
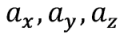 | - मापने की इकाई के वांछित त्वरण |
और फिर अचानक ...

हम केवल गॉसियन-मार्कोव विधि का उपयोग करके छद्म व्युत्क्रम मैट्रिक्स की गणना कर सकते हैं:
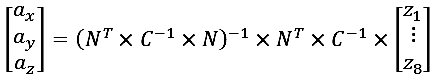
जहां N, गाइड कोसाइन का मैट्रिक्स है (गुणांक n11, n12, ..., n83 के ऊपर देखें);
सी - माप त्रुटियों के सहसंयोजक का मैट्रिक्स (कॉफ़ के साथ भ्रमित नहीं होना)।
OFK एल्गोरिथ्म के बारे में क्या बुरा है? इसके संक्रमण मैट्रिक्स में बहुत सारे शून्य हैं जो आप प्रोसेसर समय को बर्बाद नहीं करना चाहते हैं। यह ठीक है कि इस समस्या को फेडरल कलमन फ़िल्टर टाइप एल्गोरिथ्म हल करता है। बात सरल है। हम एक एकल फिल्टर को संकलित करने से इनकार करते हैं जो एक बार में सभी सेंसर को जोड़ती है और प्रत्येक सेंसर के लिए आठ अलग-अलग फिल्टर लागू करता है। यानी एक 16 वें ऑर्डर फिल्टर के बजाय, हम 8 सेकंड ऑर्डर फिल्टर का उपयोग करते हैं। योजनाबद्ध रूप से, इसे निम्नानुसार दर्शाया जा सकता है।
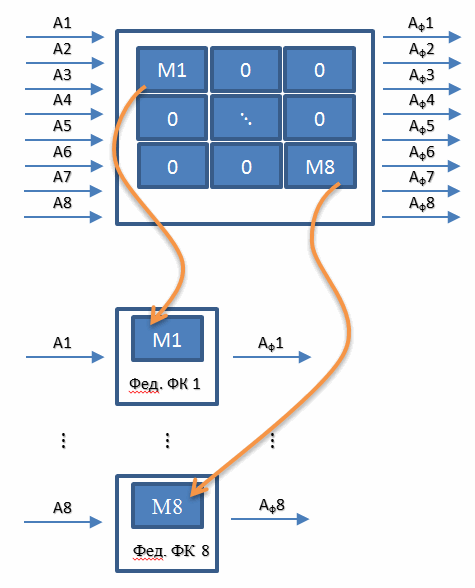
इन आठ "निजी" फिल्टर के आउटपुट सिग्नल, हम, जैसे कि ओएफसी के मामले में, गौसियन-मार्कोव कम से कम वर्गों के समीकरण में प्रतिस्थापित किए जाते हैं और हम मापने की इकाई के त्वरण के तीन घटकों के अनुमान प्राप्त करते हैं।
Federated Kalman फ़िल्टर का नुकसान क्या है? उनमें, मैट्रिक्स [1x1] जिसमें एकल सेंसर की माप त्रुटि का विचरण होता है, माप त्रुटियों के सहसंयोजक के मैट्रिक्स के रूप में उपयोग किया जाता है। यानी कोवरियन मैट्रिक्स के बजाय, एक विशिष्ट सेंसर के शोर संस्करण के बराबर एक स्केलर का उपयोग किया जाता है। इस प्रकार, मापने वाले चैनलों के बीच शोर को ध्यान में नहीं रखा जाता है। इसका मतलब यह है कि इस तरह के फिल्टर को वास्तविक शोर के मामले में कम प्रभावी होना चाहिए जो एक-दूसरे के साथ सहसंबंधित हों। यह सिद्धांत में है। व्यवहार में, समय के साथ शोर का कोविरेंस बदल जाता है, इसलिए यह गारंटी देने का कोई तरीका नहीं है कि ओएफसी संघीय की तुलना में "अधिक" इष्टतम अनुमान देगा। यह अच्छी तरह से पता लगा सकता है कि ओएफसी की दक्षता संघीय फिल्टर की प्रभावशीलता के बराबर या उससे थोड़ी अधिक होगी। यह, संयोग से, मुझे अभी तक पता लगाना है।
संश्लेषण और सिमुलेशन कार्यक्रम
समाधान संरचना
मैं पहले से ही एंग्लिज़्म के लिए माफी माँगता हूँ - मुझे "महान और पराक्रमी" समकक्ष में पेशेवर शब्दजाल से कुछ शब्द नहीं मिले। इसलिए, मैं इस कार्यक्रम के बारे में समाधान की संरचना (खेद) के बढ़े हुए विवरण के साथ शुरू करता हूं। फिर मैं अपनी राय में सबसे दिलचस्प तरीकों के तर्क का वर्णन करूंगा। अंत में मैं इस बारे में बात करूंगा कि मैंने कार्यक्रम के लिए स्रोत डेटा कैसे उत्पन्न किया।
समाधान की संरचना मन-मानचित्र (
दिमाग के साथ फ्लैश ड्राइव ?) पर प्रस्तुत की गई है। धराशायी तीर विधानसभाओं (संदर्भ) के लिंक दिखाते हैं।
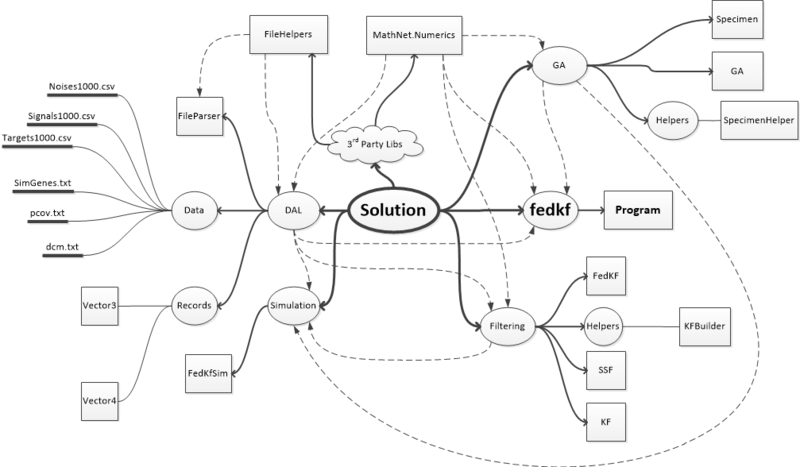
कार्यक्रम में दो तीसरे पक्ष के पुस्तकालयों का उपयोग किया गया था: मैट्रिक्स बीजगणित और यादृच्छिक संख्या पीढ़ी के लिए Math.Net, साथ ही CSV फ़ाइलों से डेटा लोड करने के लिए FileHelpers। इसके अलावा, कार्यान्वित आनुवंशिक एल्गोरिथ्म इंजन "
ए सिंपल सी # जेनेटिक एल्गोरिथम " (बैरी लैपथॉर्न) के तीसरे पक्ष के कार्यान्वयन पर आधारित है। सच है, मूल कार्यान्वयन से थोड़ा बचा है।
समाधान में एक कंसोल एप्लिकेशन प्रोजेक्ट और मुख्य तर्क वाले क्लास लाइब्रेरी प्रकार की चार परियोजनाएं शामिल हैं।
जीए विधानसभा, जैसा कि नाम से पता चलता है, इसमें आनुवंशिक एल्गोरिदम का कार्यान्वयन शामिल है। इसमें Specimen संरचना (एक व्यक्तिगत डेटा संरचना) और GA और SpecimenHelper वर्ग शामिल हैं। SpecimenHelper एक स्थिर वर्ग है और इसमें स्थिर विधियाँ हैं जो व्यक्तिगत जीन के साथ काम करने को सरल बनाती हैं (उदाहरण के लिए, GenerateGenes, क्रॉसओवर, म्यूट, प्रिंट)। इस वर्ग में Math.Net लाइब्रेरी से कॉन्टीन्यूअस यूनीफॉर्म रैंडम नंबर जनरेटर के उदाहरण भी हैं। इस जनरेटर का उपयोग करना पड़ा क्योंकि मुझे पता चला है कि .Net 4.5 असेंबली से मानक रैंडम जनरेटर सामान्य रूप से समान रूप से वितरित लोगों के बजाय यादृच्छिक संख्या वितरित करता है। जीन पीढ़ी के लिए, यह काफी महत्वपूर्ण है।
जीए वर्ग उदाहरण उन्मुख है। विभिन्न मापदंडों और कार्यों के साथ ऑप्टिमाइज़र के कई उदाहरण बनाना संभव है। उदाहरण के लिए, सेंसर के गणितीय मॉडल के मापदंडों का चयन करना एक इंजन में संभव है, और दूसरे में कोवरियस मैट्रिस के मूल्यों का चयन करना है, जबकि बंद होने के माध्यम से, फिटनेस मॉडल में "फिसल" वर्तमान में गणितीय मॉडल के मापदंडों का सबसे अच्छा संयोजन है।
वर्तमान में सिमुलेशन असेंबली में केवल एक स्थिर FedKfSim वर्ग है। बदले में, संघीय फ़िल्टर सिमुलेशन के मापदंडों में शामिल है, नमूना वर्ग के एक उदाहरण के लिए ToFedKf विस्तार विधि, जो इस व्यक्ति के जीन द्वारा एक संघीय फ़िल्टर बनाता है। इस वर्ग में स्टैटिक सिम्यूलेट विधि भी शामिल है, जिसमें व्यक्ति के उत्तीर्ण मापदंडों के लिए एक संघटित फिल्टर बनाया जाता है और इस फिल्टर के संचालन का अनुकरण करने की प्रक्रिया शुरू की जाती है।
फ़िल्टरिंग असेंबली में राज्य स्थान (SSF वर्ग), एक कलमन प्रकार निजी फ़िल्टर (KF वर्ग) और एक फ़ेडरेटेड फ़िल्टर (FedKF वर्ग) में एक डायनामिक मॉडल का कार्यान्वयन होता है। उदाहरण के तरीकों के अलावा, SSF वर्ग में दो स्थिर विधियां शामिल हैं जो आपको एक निरंतर स्थानांतरण फ़ंक्शन (FS) के गुणांकों से राज्य स्थान का असतत मॉडल उत्पन्न करने की अनुमति देती हैं। पीटी पैरामीटर मैटलैब नोटेशन में पारित किए जाते हैं, अर्थात

फ़िल्टरिंग असेंबली में KFBuilder स्टेटिक क्लास में स्टेट स्पेस का एक मॉडल और एक निजी FKT, जो अंश के गुणांक के निरंतर रिकॉर्ड और निरंतर FS के हर के साथ-साथ स्रोत डेटा के साथ-साथ आवश्यक नमूना आवृत्ति (समय की मात्रा का व्युत्क्रम अवधि) का उपयोग करके सहायक विधियाँ शामिल हैं।
DAL असेंबली में FileParser वर्ग होता है, जिसका उपयोग मैट्रिक्स डेटा वाले टेक्स्ट फ़ाइलों को पार्स करने के लिए किया जाता है, साथ ही CSV फ़ाइलों से संकेतों और शोर को लोड करने के लिए किया जाता है।
आनुवंशिक एल्गोरिथम इंजन
इसके संचालन के लिए, फिटनेस फ़ंक्शन (फिटनेसफंक्शन), जनसंख्या का आकार (पॉपुलेशनाइज़), पीढ़ियों की संख्या (जनरेशनकाउंट), किसी व्यक्ति में जीन की संख्या (जीनोमाइज़), क्रॉसिंग की संभावना (क्रॉसओवररेट), म्यूटेशन की संभावना (उत्परिवर्तन) निर्धारित करना आवश्यक है।
दीक्षा विधि व्यक्तियों की प्रारंभिक आबादी उत्पन्न करने के लिए डिज़ाइन की गई है। विधि कोड नीचे प्रस्तुत किया गया है (केवल सबसे महत्वपूर्ण बचा है):
निजी शून्य पहल ()private void Initiation() { //... _currGeneration = new List<Specimen>(); var newSpecies = Enumerable.Range(0, PopulationSize).AsParallel().Select(i => { var newSpec = new Specimen { Length = this.GenomeSize }; SpecimenHelper.GenerateGenes(ref newSpec); var fitness = FitnessFunction(newSpec); newSpec.Fitness = double.IsNaN(fitness) ? 0 : (double.IsInfinity(fitness) ? 1e5 : fitness); //... return newSpec; }).OrderBy(s => s.Fitness); _currGeneration = newSpecies.ToList(); // Huge load starts here :) _fitnessTable = new List<double>(); foreach (var spec in _currGeneration) { if (!_fitnessTable.Any()) { _fitnessTable.Add(spec.Fitness); } else { _fitnessTable.Add(_fitnessTable.Last() + spec.Fitness); } } TotalFitness = _currGeneration.Sum(spec => spec.Fitness); //... }
यहाँ महत्वपूर्ण बिंदु समानांतर LINQ का उपयोग है। सबसे पहले, 0 से जनसंख्या के आकार तक सूचकांकों की एक सरणी बनाई जाती है। इस प्रचलित उदाहरण के लिए, एक समानांतर क्वेरी (.AsParallel ()) बनाई गई है, जिसके लिए पहले से ही एक चुनिंदा क्वेरी जुड़ी हुई है, जिसके शरीर में एक व्यक्तिगत उदाहरण उत्पन्न होगा और इसके फिटनेस मूल्य की गणना की जाएगी। अंत में, एक ऑर्डरिंग क्वेरी (.OrderBy (...) जुड़ी हुई है। ये सभी अनुरोध थे और कोड का यह ब्लॉक जल्दी निष्पादित होगा। मूल्यों को निम्नलिखित पंक्ति में अपडेट किया जाएगा:
_currGeneration = newSpecies.ToList(); // Huge load starts here :)टिप्पणी क्या कहती है। इस स्थिति में, गणना थ्रेड पूल का उपयोग करके समानांतर में की जाएगी, इसलिए चयनित अनुरोध के शरीर में किसी भी साझा चर में मान लिखने के लिए कोड डालना असंभव है (उदाहरण के लिए, एक साझा सरणी में)। ऐसा कोड एक समानांतर अनुरोध के संचालन को बहुत धीमा कर देगा (हम अभी भी इसका सामना करेंगे)।
उत्पन्न व्यक्तियों के आधार पर, व्यक्तियों की फिटनेस तालिका की गणना की जाती है, जिसे पार करने के लिए व्यक्तियों के चयन के रूले व्हील एल्गोरिथ्म की आवश्यकता होगी। जैसा कि आप कोड से देख सकते हैं, तालिका में प्रत्येक वर्तमान (अंतिम) मान पिछले मूल्य और वर्तमान फिटनेस का योग है। इस तरह, तालिका विभिन्न लंबाई के खंडों से भर जाती है - फिटनेस जितनी अधिक होगी, खंड की लंबाई अधिक होगी (नीचे आंकड़ा देखें)।

इसके लिए धन्यवाद, एक समान रूप से वितरित यादृच्छिक चर का उपयोग करके सभी अनुकूलन के योग को "ईमानदारी से चुनें" क्रॉसिंग के लिए व्यक्तियों को चुनें ताकि सबसे अधिक अनुकूलित व्यक्तियों को अधिक बार चुना जाए, लेकिन "हारे हुए" को भी पार करने का मौका मिला। यदि यादृच्छिक संख्या जनरेटर सामान्य रूप से वितरित मूल्यों का उत्पादन करता है (जैसा कि रैंडम इन .net 4.5 के साथ होता है), तो व्यक्तियों को अक्सर फिटनेस टेबल के मध्य से चुना जाएगा। इसलिए मैंने ऊपर लिखा है कि मैथ.नेट पैकेज से कंटीन्यूअस यूनिफॉर्म का उपयोग मेरे मामले में एक महत्वपूर्ण क्षण था।
अगली विधि जिसके बारे में मैं बात करना चाहता हूं वह है चयन विधि।
निजी शून्य चयन () private void Selection() { var tempGenerationContainer = new ConcurrentBag<Specimen>(); //... for (int i = 0; i < this.PopulationSize / 2.5; i++) { int pidx1 = this.PopulationSize - i - 1; int pidx2 = pidx1; while (pidx1 == pidx2 || _currGeneration[pidx1].IsSimilar(_currGeneration[pidx2])) { pidx2 = RouletteSelection(); } //... var children = Rnd.NextDouble() < this.CrossoverRate ? parent1.Crossover(parent2) : new List<Specimen> { _currGeneration[pidx1], _currGeneration[pidx2] }; foreach (var ch in children.AsParallel()) { if (double.IsNaN(ch.Fitness)) { var fitness = FitnessFunction(ch); var newChild = new Specimen { Genes = ch.Genes, Length = ch.Length, Fitness = double.IsNaN(fitness) ? 0 : (double.IsInfinity(fitness) ? 1e5 : fitness) }; tempGenerationContainer.Add(newChild); } else { tempGenerationContainer.Add(ch); } } } _currGeneration = tempGenerationContainer.OrderByDescending(s => s.Fitness).Take(this.PopulationSize).Reverse().ToList(); //... }
इस विधि में, चयन किया जाता है। मैंने रूलेट व्हील की मदद से यहां दोनों माता-पिता को नहीं चुना। माता-पिता में से सबसे पहले योग्य व्यक्तियों में से आधे से थोड़ा कम क्रम में चुना जाता है। दूसरा अभिभावक पहले से ही यादृच्छिक रूप से चयनित है। इसके अलावा, यदि जीन में दूसरा माता-पिता पहले के करीब है, तो यादृच्छिक नमूना दोहराया जाता है जब तक कि एक माता-पिता जीन में पर्याप्त रूप से भिन्न नहीं होते हैं। फिर, एक क्रॉसिंग प्रक्रिया बेतरतीब ढंग से शुरू की जाती है, जो मिश्रित जीन वाले दो व्यक्तियों को बाहर करती है और एक और, जिनके जीन मूल्यों को माता-पिता के जीन के मूल्यों के औसत के रूप में चुना जाता है।
TODO: संभवतः, माता-पिता के जीन के मूल्यों के बीच की सीमा में एक यादृच्छिक संख्या की गणना के साथ औसत की गणना को बदलना आवश्यक है।
नए व्यक्तियों को पार करने के बाद, फिटनेस का मूल्य दोगुना होगा। एनएएनएन। नए व्यक्तियों के फिटनेस मूल्यों का वास्तविककरण फिर से समानांतर में किया जाता है
foreach (var ch in children.AsParallel()) { if (double.IsNaN(ch.Fitness)) { var fitness = FitnessFunction(ch); var newChild = new Specimen {
अंतिम जीए इंजन विधि का उल्लेख करने योग्य है रूलेसेलेक्शन विधि।
private int RouletteSelection() { double randomFitness = Rnd.NextDouble() * TotalFitness; int idx = -1; int first = 0; int last = this.PopulationSize - 1; int mid = (last - first) / 2; while (idx == -1 && first <= last) { if (randomFitness < _fitnessTable[mid]) { last = mid; } else if (randomFitness > _fitnessTable[mid]) { first = mid; } else if (randomFitness == _fitnessTable[mid]) { return mid; } mid = (first + last) / 2; // lies between i and i+1 if ((last - first) == 1) { idx = last; } } return idx; }
इस पद्धति में, अर्ध-विभाजन पद्धति का उपयोग करते हुए, फिटनेस की तालिका में एक सेगमेंट के लिए एक खोज की जाती है जहां एक यादृच्छिक रूप से चयनित मूल्य गिरता है। मैं दोहराता हूं, शून्य से लेकर सभी अनुकूलन के योग में एक यादृच्छिक संख्या का चयन किया जाता है। किसी विशेष व्यक्ति की फिटनेस जितनी अधिक होगी, उतनी ही अधिक संभावना होगी कि एक यादृच्छिक रूप से चयनित फिटनेस मूल्य तालिका के संबंधित खंड में गिर जाएगा। इस तरह, वांछित सूचकांक बहुत तेज है।
Federated FCT सिम्युलेटर
जैसा कि पहले लिखा गया है, फेडरफिम क्लास द्वारा फेड फ़िल्टर सिम्युलेटर लागू किया गया है। इसमें मुख्य विधि अनुकरण विधि है।
सार्वजनिक स्थिर डबल अनुकरण (नमूना कल्पना) public static double Simulate(Specimen spec) { var fkf = spec.ToFedKf(); var meas = new double[4]; ... var err = 0.0; int lng = Math.Min(Signals.RowCount, MaxSimLength); var results = new Vector3[lng]; results[0] = new Vector3 { X = 0.0, Y = 0.0, Z = 0.0 }; for (int i = 0; i < lng; i++) { var sigRow = Signals.Row(i); var noiseRow = Noises.Row(i); var targRow = Targets.Row(i); meas[0] = sigRow[0] + noiseRow[0]; meas[1] = sigRow[1] + noiseRow[1]; meas[2] = sigRow[2] + noiseRow[2]; meas[3] = sigRow[3] + noiseRow[3]; var res = fkf.Step(meas, inps.ToColumnWiseArray()); // inps var errs = new double[] { res[0, 0] - targRow[0], res[1, 0] - targRow[1], res[2, 0] - targRow[2] }; err += (errs[0] * errs[0]) + (errs[1] * errs[1]) + (errs[2] * errs[2])/3.0; results[i] = new Vector3 { X = res[0, 0], Y = res[1, 0], Z = res[2, 0] }; ... } ... return 1/err*lng; }
यह विधि एक पुनरावृत्त प्रक्रिया शुरू करती है। प्रत्येक चरण में, एक चयन सेंसर संकेतों, शोर और संदर्भ मूल्यों (शोर के बिना ब्लॉक त्वरण) के शुद्ध मूल्यों से बना है। शुद्ध संकेतों को शोर के साथ अभिव्यक्त किया जाता है, और इस मिश्रण को संघीय फ़िल्टर की चरण विधि को खिलाया जाता है। पिछले चरण से ब्लॉक त्वरण का आकलन भी वहां प्रस्तुत किया गया है, लेकिन निजी एफसीटी के वर्तमान कार्यान्वयन में इन मूल्यों का उपयोग नहीं किया जाता है। फ़ेडरेटेड फ़िल्टर की चरण विधि मूल्यों की एक सरणी पैदा करती है - ब्लॉक त्वरण का अनुमान। उनके और संदर्भ मूल्यों के बीच का अंतर वर्तमान अनुमान त्रुटि होगी। वर्तमान चरण के अंत में, अनुमान त्रुटियों के औसत वर्ग की गणना की जाती है, और परिणामस्वरूप मूल्य त्रुटियों के योग में जोड़ा जाता है। पुनरावृत्तियों के अंत में, प्रक्रिया के सभी चरणों के लिए औसत त्रुटि मान की गणना की जाती है। आउटपुट औसत त्रुटि का संख्या व्युत्क्रम है।
निष्पादन योग्य अनुप्रयोग
आवेदन का क्रम इस प्रकार है। सबसे पहले, कंसोल तर्क की जाँच की जाती है। यदि तर्क सूची खाली नहीं है, तो मान्य आदेशों में से एक को निष्पादित करने का प्रयास किया जाता है।
switch (cmd) { case "simulate": case "simulation": InitializeSimulator(); FedKfSim.PrintSimResults = true; var spec = new Specimen(); SpecimenHelper.SetGenes(ref spec, ReadSimulationGenes()); FedKfSim.Simulate(spec); break; case "set": var settingName = args[1]; var settingValue = args[2]; var config = ConfigurationManager.OpenExeConfiguration(ConfigurationUserLevel.None); config.AppSettings.Settings[settingName].Value = settingValue; config.Save(ConfigurationSaveMode.Modified); ConfigurationManager.RefreshSection("appSettings"); Console.WriteLine("'{0}' set to {1}", settingName, settingValue); break; case "print": Console.WriteLine("Current settings:"); foreach (var name in ConfigurationManager.AppSettings.AllKeys.AsParallel()) { var value = ConfigurationManager.AppSettings[name]; Console.WriteLine("'{0}' => {1}", name, value); } break; case "help": case "?": case "-h": PrintHelp(); break; default: Console.Error.WriteLine(string.Format("\nARGUMENT ERROR\n'{0}' is unknown command!\n", cmd)); PrintHelp(); break; }
सिमुलेट कमांड का उपयोग करते हुए, जिन जीनों के लिए आप एक फेडरेटेड एफसीटी उत्पन्न करना चाहते हैं, उन्हें कॉन्फ़िगरेशन फ़ाइलों से घटाया जाता है। "सेट" कमांड का उद्देश्य मुख्य एप्लिकेशन कॉन्फ़िगरेशन फ़ाइल के मानों में से एक को बदलना है। "प्रिंट" कमांड के द्वारा, मुख्य कॉन्फ़िगरेशन फ़ाइल से सभी सेटिंग्स का मान कंसोल में प्रदर्शित होता है। मदद कमांड कंसोल को मूल दस्तावेज प्रदर्शित करता है।
जब तर्क के बिना आवेदन शुरू होता है, तो मुख्य इंजन ऑपरेशन मापदंडों को कॉन्फ़िगरेशन फ़ाइल से घटाया जाता है, साथ ही डेटा फ़ाइलों से मैट्रिसेस, सिग्नल, शोर और संदर्भ के मूल्य। सभी आवश्यक डेटा और मापदंडों को लोड करने के बाद, एक ऑप्टिमाइज़र उदाहरण बनाया जाता है और विकासवादी प्रक्रिया शुरू की जाती है।
InitializeSimulator(); var genCount = int.Parse(ConfigurationManager.AppSettings["GenerationsCount"]); var popSize = int.Parse(ConfigurationManager.AppSettings["PopulationSize"]); var crossOver = double.Parse(ConfigurationManager.AppSettings["CrossoverRate"], FileParser.NumberFormat); var mutRate = double.Parse(ConfigurationManager.AppSettings["MutationRate"], FileParser.NumberFormat); var maxGeneVal = double.Parse(ConfigurationManager.AppSettings["MaxGeneValue"], FileParser.NumberFormat); var minGeneVal = double.Parse(ConfigurationManager.AppSettings["MinGeneValue"], FileParser.NumberFormat); var genomeLength = int.Parse(ConfigurationManager.AppSettings["GenomeLength"]); SpecimenHelper.SimilarityThreshold = double.Parse( ConfigurationManager.AppSettings["SimilarityThreshold"], FileParser.NumberFormat); var ga = new Ga(genomeLength) { FitnessFunction = FedKfSim.Simulate, Elitism = true, GenerationsCount = genCount, PopulationSize = popSize, CrossoverRate = crossOver, MutationRate = mutRate }; FedKfSim.PrintSimResults = false; ga.Go(maxGeneVal, minGeneVal);
विशेष रूप से ReadSignalsAndNoises पद्धति पर ध्यान दिया जाना चाहिए।
निजी स्थैतिक शून्य ReadSignalsAndNoises () private static void ReadSignalsAndNoises() { var noisesPath = ConfigurationManager.AppSettings["NoisesFilePath"]; var signalsPath = ConfigurationManager.AppSettings["SignalsFilePath"]; var targetsPath = ConfigurationManager.AppSettings["TargetsFilePath"]; FedKfSim.Noises = new DenseMatrix(FileParser.Read4ColonFile(noisesPath)); FedKfSim.Signals = new DenseMatrix(FileParser.Read4ColonFile(signalsPath)); FedKfSim.Targets = new DenseMatrix(FileParser.Read3ColonFile(targetsPath)); var measCov = new DenseMatrix(4); double c00 = 0, c01 = 0, c02 = 0, c03 = 0, c11 = 0, c12 = 0, c13 = 0, c22 = 0, c23 = 0, c33 = 0; Vector<double> v1 = new DenseVector(1); Vector<double> v2 = new DenseVector(1); Vector<double> v3 = new DenseVector(1); Vector<double> v4 = new DenseVector(1); var s1 = new DescriptiveStatistics(new double[1]); var s2 = new DescriptiveStatistics(new double[1]); var s3 = new DescriptiveStatistics(new double[1]); var s4 = new DescriptiveStatistics(new double[1]); var t00 = Task.Run(() => { v1 = FedKfSim.Noises.Column(0); s1 = new DescriptiveStatistics(v1); c00 = s1.Variance; }); var t11 = Task.Run(() => { v2 = FedKfSim.Noises.Column(1); s2 = new DescriptiveStatistics(v2); c11 = s2.Variance; }); var t22 = Task.Run(() => { v3 = FedKfSim.Noises.Column(2); s3 = new DescriptiveStatistics(v3); c22 = s3.Variance; }); var t33 = Task.Run(() => { v4 = FedKfSim.Noises.Column(3); s4 = new DescriptiveStatistics(v4); c33 = s4.Variance; }); Task.WaitAll(new[] { t00, t11, t22, t33 }); var t01 = Task.Run(() => c01 = CalcVariance(v1, s1.Mean, v2, s2.Mean, FedKfSim.Noises.RowCount)); var t02 = Task.Run(() => c02 = CalcVariance(v1, s1.Mean, v3, s3.Mean, FedKfSim.Noises.RowCount)); var t03 = Task.Run(() => c03 = CalcVariance(v1, s1.Mean, v4, s4.Mean, FedKfSim.Noises.RowCount)); var t12 = Task.Run(() => c12 = CalcVariance(v2, s2.Mean, v3, s3.Mean, FedKfSim.Noises.RowCount)); var t13 = Task.Run(() => c13 = CalcVariance(v2, s2.Mean, v4, s4.Mean, FedKfSim.Noises.RowCount)); var t23 = Task.Run(() => c23 = CalcVariance(v3, s3.Mean, v4, s4.Mean, FedKfSim.Noises.RowCount)); Task.WaitAll(new[] { t01, t02, t03, t12, t13, t23 }); measCov[0, 0] = c00; measCov[0, 1] = c01; measCov[0, 2] = c02; measCov[0, 3] = c03; measCov[1, 0] = c01; measCov[1, 1] = c11; measCov[1, 2] = c12; measCov[1, 3] = c13; measCov[2, 0] = c02; measCov[2, 1] = c12; measCov[2, 2] = c22; measCov[2, 3] = c23; measCov[3, 0] = c03; measCov[3, 1] = c13; measCov[3, 2] = c23; measCov[3, 3] = c33; FedKfSim.SensorsOutputCovariances = measCov; }
सहसंयोजक मूल्यों को संग्रहीत करने के लिए यह कई अलग-अलग दोहरे चर का उपयोग करता है। जैसा कि मैंने ऊपर लिखा है, अगर मैं एक सरणी का उपयोग करता हूं, तो समानांतर कार्य (टास्क) धीरे-धीरे किया जाएगा। दरअसल, यह वही है जो मैं इस पद्धति के प्रारंभिक कार्यान्वयन के साथ आया था। मैं प्रत्येक कार्य के भीतर सूचकांक निर्धारित करता हूं, जिसके अनुसार एक सामान्य सरणी में प्राप्त सह-मूल्य को पंजीकृत करना आवश्यक था। और इस दृष्टिकोण से, कोड काफी सुरक्षित था। लेकिन इसे बेहद धीमी गति से चलाया गया। सरणी को अलग-अलग चर के साथ प्रतिस्थापित करने के बाद, सहसंयोजक मैट्रिक्स की गणना में काफी तेजी आई थी।
तो इस विधि में क्या किया जाता है? शोर की दो पंक्तियों के प्रत्येक अद्वितीय संयोजन के लिए, एक अलग अतुल्यकालिक कार्य बनाया जाता है। इन समस्याओं में, दो यादृच्छिक प्रक्रियाओं की पारस्परिक भिन्नता की गणना की जाती है।
private static double CalcVariance(IEnumerable<double> v1, double mean1, IEnumerable<double> v2, double mean2, int length) { var zipped = v1.Take(length).Zip(v2.Take(length), (i1, i2) => new[] { i1, i2 }); var sum = zipped.AsParallel().Sum(z => (z[0] - mean1) * (z[1] - mean2)); return sum / (length - 1); }
सूत्र फैलाव गणना सूत्र के समान है। केवल एक यादृच्छिक श्रृंखला के औसत से विचलन के वर्ग के बजाय, उपयोग की जाने वाली दो अलग-अलग श्रृंखलाओं के औसत मूल्यों से विचलन का उत्पाद है?
स्रोत डेटा
कार्यक्रम के लिए प्रारंभिक डेटा शोर, सेंसर संकेतों और ब्लॉक त्वरण घटकों के सच्चे मूल्यों के साथ-साथ फिल्टर मापदंडों के साथ संख्यात्मक श्रृंखला हैं: दिशात्मक कोसिन का मैट्रिक्स (मेरी स्नातक परियोजना से लिया गया, मेरे पिछले लेखों में वर्णित पुनर्वितरण ब्लॉक के कॉन्फ़िगरेशन से मेल खाता है), कोविरेन्स मैट्रिक्स प्रक्रिया शोर (अनुभवजन्य रूप से सेट)।
ब्लॉक त्वरण के संदर्भ मूल्यों को दो साइनसोइड्स के संयोजन के रूप में सेट किया गया था। ब्लॉक के गाइड कोसाइन के मैट्रिक्स के माध्यम से इन मूल्यों को सेंसर सिग्नल में परिवर्तित किया गया था। हाइब्रिड तरीके से सेंसर का शोर उत्पन्न हुआ। मैंने एक वास्तविक सेंसर के सिग्नल की रिकॉर्डिंग ली, जो रिकॉर्डिंग के दौरान बाकी था। इस संकेत से निरंतर घटक को हटाने के बाद, मुझे स्टैटिक्स में सेंसर का शोर मिला (यह एल्गोरिदम को डीबग करने के लिए पर्याप्त है)। वैसे, ये शोर सामान्य वितरण के साथ सफेद रंग के बहुत करीब थे। मैंने इन मूल्यों को 1000 मूल्यों के छोटे नमूनों में काट दिया, विभिन्नताओं को श्रेणी [0.05..0.15] तक लाने के लिए उनकी तीव्रता को बढ़ाया। इस प्रकार, हम कह सकते हैं कि मैंने अपने शोध में वास्तविक शोर का इस्तेमाल किया।
परिणाम

उत्पन्न संघीय फ़िल्टर ने औसत शोर फैलाव को लगभग आधे से कम कर दिया (यानी, इसने रूट-मीन-स्क्वायर त्रुटि को लगभग 1.38 गुना कम कर दिया)। जड़ता बढ़ने से त्रुटियों के विचरण में और भी अधिक कमी आ सकती है, लेकिन तब गतिशील विलंब बढ़ जाएगा। मेरी राय में, जीए का उपयोग करके पूरी तरह से परिचालन शोर फिल्टर उत्पन्न किया गया था।
निष्कर्ष
मेरे पास इतना खाली समय नहीं है, इसलिए, मुख्य कार्य को लागू करते समय, पूर्णतावाद के लिए समय नहीं था। कुछ स्थानों में, कोड में सुरक्षा दोष हैं (यह मुख्य रूप से तर्कों की मान्यता की चिंता करता है), कुछ स्थानों पर, "सी # कोड स्टाइल गाइड" की सामान्य सिफारिशों का पालन नहीं किया जाता है। निश्चित रूप से उप-रूपी प्रदर्शन के साथ कोड के ब्लॉक हैं। लेकिन अपनी सभी कमियों के बावजूद, यह काफी अच्छी तरह से काम करता है। मैंने इसे Intel Core i3 CPU पर परीक्षण किया और अनुकूलन प्रक्रिया बहुत तेज़ थी। इसके अलावा, टीपीएल के उपयोग के लिए धन्यवाद, प्रोसेसर संसाधनों का उपयोग काफी कुशलता से किया गया था। कार्यान्वित एल्गोरिदम ने प्रोसेसर के लगभग सभी खाली समय का उपभोग किया, लेकिन अतुल्यकालिक टीपीएल कार्यों की सामान्य प्राथमिकता के कारण, शेष उपयोगकर्ता कार्यक्रमों ने गंभीर ताले के बिना काम किया। मैंने कंसोल में कार्यान्वित प्रोग्राम लॉन्च किया और विज़ुअल स्टूडियो 2012 में काम करने के लिए स्विच किया, बिल्ट-इन रिज़ॉल्वर के साथ, समय-समय पर आउटलुक और एमएस वर्ड पर स्विच किया, आईई और क्रोम ब्राउज़रों में समानांतर में काम करने वाले प्रोजेक्ट को डीबग किया, बिना किसी गंभीर ब्रेक का अवलोकन किए। सामान्य तौर पर, टीपीएल अतुल्यकालिक प्रोग्रामिंग लाइब्रेरी का उपयोग करना एक अच्छा अनुभव था, बिना किसी गंभीर कठिनाइयों के तुरंत एक अच्छा परिणाम प्राप्त हुआ।
आपका ध्यान के लिए धन्यवाद! मुझे उम्मीद है कि लेख और कोड आपके लिए उपयोगी होंगे।
गिथुब स्रोत :
github.com/homoluden/fedkf-ga