इस साल की शुरुआत में MySQL के नए संस्करण की रिलीज़ के बाद, कई ने सोचा कि क्या पुराने संस्करणों से इसे स्थानांतरित करने के लायक है। अपने लिए इस प्रश्न का उत्तर देने के लिए, आपको सबसे पहले यह समझने की आवश्यकता है कि यह परिवर्तन वास्तव में क्या देगा। इस लेख में मैं अपने लिए महत्वपूर्ण नई विशेषताओं को उजागर करने की कोशिश करूंगा जो नए संस्करण के वितरण, उनके प्रदर्शन के विश्लेषण और नए संस्करण की संचालन क्षमता में शामिल थे, साथ ही साथ पुन: लिखित अनुकूलक के कारण कोड में कुछ बदलने की आवश्यकता थी। चूंकि परिवर्तनों की मात्रा वास्तव में बहुत बड़ी है, प्रत्येक आइटम के लिए मैं प्रदर्शन परीक्षण पर मूल लेख का एक लिंक दूंगा और विवरण से पानी को बाहर कर दूंगा।
चलो सबसे दिलचस्प - अनुकूलक एक्सटेंशन के साथ शुरू करते हैं
इंडेक्स कंडीशन पुशडाउन (ICP) - यदि हम किसी कंपोजिट इंडेक्स का उपयोग करते हुए डेटा को टेबल में एक्सेस करते हैं तो यह ऑप्टिमाइज़ेशन किया जाता है। यदि कुंजी के पहले भाग की स्थिति स्पष्ट रूप से लागू की जा सकती है, और कुंजी के शेष भाग पर स्थिति स्पष्ट रूप से लागू नहीं की जा सकती है, उदाहरण के लिए:
keypart1 = 1 - एक्सेस keypart2 like '%value%' , keypart2 like '%value%' - predicate फ़िल्टर करना,- या एक्सेस predicate
keypart1 between a and b कंडीशन keypart1 between a and b को लगाने के लिए, keypart2 between c and d में रेंज की के दोनों तरफ से predicate करें (इस प्रकार की क्वेरी के लिए इंडेक्स का पूरा उपयोग, क्योंकि एक्सेस एक्सेस डेडिकेटेड MySQL में अभी तक लागू नहीं हुआ MySQL )
तब पहले
MySQL सर्वर, एक्सेस predicate लागू करने के बाद, स्टोरेज इंजन पर स्विच हो जाता था और टेबल की पंक्ति को पढ़ने के बाद दूसरी स्थिति लागू करता था। इस विकल्प का उपयोग करते हुए, यह स्विच नहीं होगा, निश्चित रूप से, अगर भंडारण इंजन खुद
ICP का समर्थन करता है, तो फिलहाल यह
MyISAM और
InnoDB , और फ़िल्टर विधेयकों को विशेष रूप से सूचकांक डेटा के आधार पर लागू किया जाएगा। योजना
Using index condition होगी।
परीक्षण के अनुसार
, इनपुट / आउटपुट सबसिस्टम के साथ काम करते समय, कैश से डेटा का अनुरोध करने
का प्रदर्शन लगभग 30-50 प्रतिशत होगा, 100 गुना तक त्वरण संभव है।
मल्टी रेंज रीड (MRR) - जब माध्यमिक कुंजी का उपयोग करके
Range Scan का आयोजन किया जाता है, तो मनमानी डिस्क की संख्या को कम करने के लिए, पहले सूचकांक से सभी आवश्यक डेटा पढ़ें, फिर
ROWID द्वारा सॉर्ट करें, और उसके बाद ही प्राथमिक कुंजी द्वारा डेटा पढ़ें। के संदर्भ में, जो निस्संदेह अद्भुत है,
Using MRR खड़ा होगा। यह ऑपरेशन एक बीम है। यानी द्वितीयक कुंजी द्वारा एक्सेस की भविष्यवाणी करना, हम उपलब्ध बफर में भरते हैं, और उसके बाद ही हम डेटा को सॉर्ट और पढ़ते हैं। यहां, भाग्यशाली और डेटा एक दूसरे के करीब हैं या नहीं। वितरित तालिकाओं के लिए, स्थिति और भी बेहतर है, लेकिन यह इस लेख के दायरे से परे है। अपने शुद्ध रूप में, यह एल्गोरिथ्म एक टेबल पर एक क्वेरी निष्पादित करते समय लागू किया जा सकता है।
बैच कुंजी एक्सेस (BKA) के संयोजन में
, यह भी शामिल होने के संचालन को गति देना संभव बनाता है। डिफ़ॉल्ट रूप से,
BKA ध्वज बंद है; इसके मान, ऑप्टिमाइज़र फ़्लैग के किसी भी मूल्य की तरह,
SELECT @@optimizer_switch अनुरोध निष्पादित करके देखा जा सकता है। जब BKA सक्षम होता है, तो
join_buffer_size पैरामीटर के विभिन्न मूल्यों पर आपके अनुरोधों की जांच करना आवश्यक है
join_buffer_size क्योंकि इस पैरामीटर का उपयोग अधिकतम बफर आकार की गणना के लिए किया जाएगा। क्वेरी के संदर्भ में इस अद्भुत एल्गोरिथ्म को लागू करते समय, हम
Using join buffer (Batched Key Access) देखेंगे। विषय के अधिक विस्तृत कवरेज
यहाँ ।
परीक्षण के परिणामों के अनुसार
, यह अनुकूलन महत्वपूर्ण त्वरण दे सकता है यदि इनपुट आउटपुट है और डिस्क के साथ काम करता है। इस मामले में, आप केवल
MRR साथ 10x त्वरण प्राप्त कर सकते हैं।
MRR और
BKA के संयुक्त उपयोग के साथ 280 से अधिक बार के एक्सेलेरेशन को कई अन्य सिंथेटिक परीक्षणों में प्राप्त किया गया था। विशेष रूप से मेमोरी के साथ काम करते समय, आपको त्वरण नहीं मिलता है, जो काफी तार्किक है, क्योंकि यह ऑपरेशन विशेष रूप से इनपुट और आउटपुट को अनुकूलित करने के लिए डिज़ाइन किया गया है।
फ़ाइल सॉर्ट ऑप्टिमाइज़ेशन - गैर-अनुक्रमित कॉलम द्वारा छंटनी कुछ शर्तों के अधीन बहुत अधिक उत्पादक बन गई है। पहले, जब इस प्रकार की छंटाई करते हैं, तो एकमात्र संभव विकल्प मर्जिंग छँटाई थी। मोटे तौर पर, अनुरोध के परिणामस्वरूप प्राप्त किया गया डेटा एक अस्थायी तालिका में संग्रहीत किया गया था। उसके बाद, इस तालिका के लिए छंटनी की गई और
LIMIT स्थिति को पूरा करने वाले रिकॉर्ड वापस कर दिए गए। जैसा कि आप देख सकते हैं, यह एल्गोरिथ्म बहुत उत्पादक नहीं है, खासकर यदि आपके पास बहुत सारे प्रश्न हैं जो बहुत कम संख्या में पंक्तियों को वापस करते हैं। इनपुट का अनुकूलन करने के लिए, आउटपुट एल्गोरिदम को निम्न में बदल दिया गया था। यदि क्वेरी के परिणामस्वरूप प्राप्त रिकॉर्ड की संख्या पूरी तरह से
sort_buffer_size में
sort_buffer_size , तो तालिका स्कैन किए जाने पर एक कतार बनाई जाती है। यह कतार आदेशित होती है, और क्वेरी परिणाम की अगली पंक्ति प्राप्त होने पर तुरंत भर जाती है। कतार का आकार
N (या
M + N अगर
LIMIT M, N निर्माण का उपयोग किया जाता है)। जब कतार भर जाती है, तो अंत से अतिरिक्त डेटा बाहर फेंक दिया जाता है। इस प्रकार, क्वेरी परिणाम के अंत के साथ छँटाई का अंत एक साथ किया जाता है, और अस्थायी तालिका में कोई कॉल नहीं होती है। ऑप्टिमाइज़र स्वतंत्र रूप से छँटाई के लिए एक रणनीति चुनता है। कतार का उपयोग तब किया जाएगा जब प्रोसेसर को अधिक लोड करना आवश्यक हो, जब इनपुट / आउटपुट सिस्टम उपलब्ध हो तो मर्जिंग सॉर्ट करें।
सिंथेटिक परीक्षण करते समय , 4 बार का त्वरण प्राप्त किया गया था। लेकिन आपको यह भी समझने की आवश्यकता है कि यह अनुकूलन आपको आउटपुट इनपुट सबसिस्टम पर लोड को कम करने की अनुमति देता है, जो पूरे उदाहरण के काम को सकारात्मक रूप से प्रभावित करेगा।
उपकेंद्रों का अनुकूलनpostpone materialization - यह मुख्य रूप से एक क्वेरी योजना के निर्माण से संबंधित है। इससे पहले, जब
EXPLAIN कमांड को निष्पादित किया जाता है, तो
FROM सेक्शन में उपयोग की जाने वाली उपश्रेणियाँ उन पर आंकड़े प्राप्त करने के लिए भौतिक होती हैं। यानी वास्तव में, ये प्रश्न डेटाबेस पर किए गए थे। अब यह ऑपरेशन नहीं किया जाता है, और DB उदाहरण को लोड किए बिना क्वेरी प्लान प्राप्त करना संभव हो गया। हालांकि, क्वेरी निष्पादन समय को भी तेज किया जा सकता है, उदाहरण के लिए, यदि
FROM अनुभाग में 2 भौतिक प्रतिनिधित्व हैं और पहले एक भी रिकॉर्ड वापस नहीं करता है, तो 2 को निष्पादित नहीं किया जाएगा। इसके अलावा, क्वेरी निष्पादन के दौरान, MySQL स्वतंत्र रूप से परिणामी भौतिक तालिका को अनुक्रमित कर सकता है, अगर यह आवश्यक समझता है।
semi-join transformation - एक
semi-join transformation का उपयोग केवल एक तालिका से डेटा प्राप्त करने के लिए किया जा सकता है, अन्य तालिका के डेटा के आधार पर, सभी डेटाबेस में क्लासिक उदाहरण
EXISTS निर्माण है। इस अनुकूलन का उपयोग
IN डिजाइन के लिए संभव हो गया है, जो बहुत बुरी तरह से काम करता था। इस अनुकूलन को संभव बनाने के लिए यह आवश्यक है कि उपशम निम्नलिखित शर्तों को पूरा करे: कोई
UNION , कोई
GROUP BY और
HAVING , कोई
ORDER BY एक
LIMIT अवरोध (अलग से, इन निर्माणों का उपयोग किया जा सकता है)। यह भी आवश्यक है कि सबइनरीज़ की संख्या जोइन के लिए अनुमत अधिकतम तालिकाओं की संख्या से अधिक नहीं है, क्योंकि अन्यथा
MySQL इस क्वेरी को फिर से लिखने में सक्षम नहीं होगा। ऑप्टिमाइज़ेशन
SEMI JOIN में अनुरोध को फिर से लिखकर या उपर्युक्त वर्णित
postpone materialization सामग्रीकरण के लिए ऑप्टिमाइज़ेशन का उपयोग करके निर्माण
FROM में एक
VIEW रूप में प्रस्तुत करने के द्वारा प्राप्त किया जाता है। अंतिम परिणाम से डुप्लिकेट प्रविष्टियों को निम्न तरीकों से हटा दिया जाता है:
- एक अस्थायी तालिका में अंतिम क्वेरी के अनूठे परिणामों को रखकर (
Extra योजना कॉलम में Start temporary और End temporary Start temporary करें) - "पहली बार मिली" कसौटी का उपयोग करके
Extra योजना कॉलम में एक सबक्वेरी ( FirstMatch(tbl_name) से तालिका को स्कैन करने के चरण में) - ऑप्टिमाइज़ेशन लूज़ इंडेक्स स्कैन (
LooseScan(m..n) जहाँ m और n इस अनुकूलन के लिए उपयोग किए जाने वाले प्रमुख भाग हैं)
जब
select_type और फिर
select_type को अनुक्रमणित किया जाता है, तो
MATERIALIZED क्वेरी योजना के
select_type कॉलम में होगी। यह समझने के लिए कि अनुरोध को फिर से कैसे लिखा गया था, आप मानक
EXPLAIN EXTENDED कमांड का उपयोग कर सकते हैं। इस तरह आप हमेशा समझेंगे कि आपका अनुरोध कैसे फिर से लिखा गया था, और क्या अनुकूलन लागू किया गया था।
जैसा कि आप जानते हैं,
टेढ़े-मेढ़े लिखित प्रश्नों को फिर से लिखना (मैंने ऐसे प्रश्नों के लिए अपने हाथ काट लिए होंगे, अब यह बहाना बन गया है) एक पागल प्रदर्शन को बढ़ावा दे सकता है, इसलिए
table pullout पर परीक्षण चलाने के लिए लगभग बेकार है (
WHERE में एक
WHERE हटाकर)। उत्पादकता में 1000 गुना वृद्धि के लिए भी सीमा नहीं होगी, हालांकि, यदि आपके सभी प्रश्नों को सही ढंग से लिखा गया है, तो आप इस प्रकार के अनुकूलन से असाधारण कुछ के लिए इंतजार नहीं कर सकते।
InnoDB लिए स्टेटिक आँकड़ेअंत में, यह हुआ। मुझे नहीं पता कि
Google ,
Percona या
Oracle ही कहां, लेकिन
MySQL में क्वेरी प्लान के निर्माण से डायनेमिक सैंपलिंग को बाहर करना संभव हो गया। अब टेबल और इंडेक्स पर आंकड़े लगातार टेबल में संग्रहीत किए जाते हैं। आँकड़े एकत्र करने की यह विधि डिफ़ॉल्ट रूप से सक्षम है। तालिका में 10% से अधिक डेटा को अपडेट करते समय, उस पर आंकड़े स्वचालित रूप से पुन: प्राप्त होते हैं (बेशक, इसे बदला जा सकता है)। इसके अलावा,
ANALYSE कमांड के साथ बल द्वारा सांख्यिकी संग्रह शुरू किया जा सकता है। जब ऑप्टिमाइज़र अभूतपूर्व रूप से गूंगा हो, तो आँकड़े रीसेट करने के लिए, आप
FLUSH TABLE कमांड को कॉल कर सकते हैं। वास्तव में क्या हो रहा है यह स्पष्ट रूप से नए टेबल
mysql.innodb_index_stats ,
mysql.innodb_table_stats में देखा जा सकता है। यह निश्चित रूप से ओरेकल हिस्टोग्राम नहीं है, लेकिन चेहरे पर प्रगति है। अब योजनाएं एक तरफ अधिक स्थिर हो गई हैं, और दूसरी ओर, डीबीए का एक नया मनोरंजन है: प्रस्तुत करें जब तालिका में आंकड़े अप्रासंगिक हो जाएं, डाउनटाइम ढूंढें, नमूना की मात्रा का अनुमान लगाएं और पुन: गणना करें, खासकर जब यह डेवलपर्स ब्लॉग से अनुसरण करता है, तो आंकड़ों को हैंडल द्वारा बदला जा सकता है। , सीधे अपडेट द्वारा। मैं यह भी ध्यान देना चाहूंगा कि परीक्षण करते समय, आंकड़े संग्राहक, जाहिर तौर पर पृष्ठभूमि थ्रेड में काम कर रहे हैं, उन्होंने डेटा को संसाधित करने का प्रबंधन नहीं किया है। लंबे समय तक आँकड़े तब तक खाली रहे जब तक मैंने मैन्युअल रूप से इसका विश्लेषण शुरू नहीं किया। किसी विशेष विभाजन के लिए सांख्यिकी विश्लेषण चलाना असंभव है, इसलिए, पूरी विभाजन तालिका का विश्लेषण करना आवश्यक था, जो निश्चित रूप से बहुत सुविधाजनक नहीं है। यदि आप सक्रिय डीएमएल का संचालन करते हैं और आधार को नीचे रखते हैं तो भी यही स्थिति उत्पन्न होती है। डेटा होगा - कोई आंकड़े नहीं। लेकिन मुझे लगता है कि ये असाधारण स्थितियां हैं और वे डेटाबेस के नियमित संचालन में हस्तक्षेप नहीं करेंगे।
ऑप्टिमाइज़र पर
निष्कर्ष के रूप में, मुझे लगता है कि यह ध्यान देने योग्य है कि विशेषज्ञों के अनुसार मारिया डीबी 5.5 ऑप्टिमाइज़र, अधिक परिष्कृत है, लेकिन MySQL 5.6 में इसी तरह के कई ऑप्टिमाइज़ेशन उच्च प्रदर्शन की अनुमति देते हैं।
अधिक म्यूटेक्स अच्छे और अलग हैं
जैसा कि हर कोई अच्छी तरह से जानता है, MySQL बड़ी संख्या में प्रोसेसर के लिए अच्छी तरह से पर्याप्त पैमाने पर नहीं होता है जिसमें बड़ी संख्या में एक साथ निष्पादित लेनदेन होते हैं। इसका कारण आंतरिक ताले हैं, विशेष रूप से
kernel mutex , साथ ही मल्टी-कोर आर्किटेक्चर में मेमोरी के साथ काम करते समय मूलभूत समस्याएं।
Kernel mutex , सक्रिय लेनदेन की सूची की प्रतिलिपि बनाने के लिए, गैर-अवरुद्ध और अवरुद्ध लेनदेन, ताले, ताले की प्रतीक्षा, आदि के लिए कई म्यूटेक्स में विभाजित किया गया था।
false sharing की समस्या को भी हल किया गया था, जब एक कोर ने इसके लिए आवश्यक अपरिवर्तनीय डेटा लोड किया था, और इसके लिए आवश्यक दूसरे को एक
cacheline में बदल दिया, और परिणामस्वरूप, पहले कोर के लिए डेटा हमेशा कैश से बाहर धोया गया था। अब, कई महत्वपूर्ण वस्तुओं के लिए 64 बाइट्स का
संरेखण शुरू किया
गया है ।
डेवलपर ब्लॉग के अनुसार,
MySQL ने
read only लेनदेन को
read only लिए 50% तक बेहतर किया है। और सक्रिय सत्रों की संख्या में वृद्धि के साथ प्रदर्शन लाभ पिछले संस्करण की तुलना में 600% तक था। स्वतंत्र लोड परीक्षणों का संचालन करते समय, एक साथ 16 सत्रों तक - गति में बदलाव नहीं हुआ, मिश्रित रीड-राइट लेनदेन के लिए 100% तक और रीड-ओनली लेनदेन के लिए 300% तक।
UNDO रीसेट ऑप्टिमाइज़ेशन
अब समानांतर में UNDO को रीसेट करना संभव है। ऐसा करने के लिए,
innodb_purge_threads पैरामीटर को मान से अधिक पर सेट करें। किसी औद्योगिक डेटाबेस पर इस पैरामीटर के साथ प्रयोग केवल उन लोगों के लिए उचित होगा, जो समानांतर में विभाजित तालिकाओं से बहुत अधिक डेटा हटाते हैं। समानांतर डीएमएल के अलावा अन्य कारणों से विभाजन का उपयोग नहीं करने वाले या विभाजन का उपयोग करने वालों के लिए प्रदर्शन सुधार, उदाहरण के लिए, जिसमें केवल एक विभाजन के साथ डीएमएल संचालन किया जाता है, ऐसा नहीं होगा, क्योंकि डेटा रीसेट करते समय, आप
dict_index_t::lock पर लटका
dict_index_t::lock । उनके लिए, यह सिफारिश की जाती है, पहले की तरह, मुख्य धारा से एक में डेटा डंपिंग को बस आवंटित करने के लिए।
डर्टी ब्लॉक ऑप्टिमाइज़ेशन
जैसा कि आप जानते हैं, मेमोरी से गंदे ब्लॉकों को डंप करना किसी भी संस्करण डेटाबेस के लिए सबसे समस्याग्रस्त स्थानों में से एक है। डिस्क के लिए ब्लॉक के आवश्यक भाग को रीसेट करना या तो मुख्य
InnoDB Master Thread द्वारा किया जा सकता है, और फिर हर कोई इंतजार करेगा, या, जैसा कि मूल रूप से पृष्ठभूमि थ्रेड, एक विशिष्ट सत्र रीसेट कमांड भेज देगा, और फिर यह सत्र अनिश्चित काल तक लटका रहेगा, और बाकी सत्र अवरुद्ध नहीं होंगे। पहले और दूसरे दोनों मामलों में समस्याओं से बचने के लिए,
page_cleaner नामक एक अलग थ्रेड बनाया गया था। यह धारा क्या व्यस्त है, इसकी विस्तृत जानकारी
यहाँ मिल सकती
है। select name, comment from information_schema.innodb_metrics where name like 'buffer_flush_%';
अब ब्लॉक रीसेट वास्तव में एसिंक्रोनस रूप से प्रदर्शन किया जाने लगा। यदि आप ब्लॉकों के रीसेट मापदंडों के साथ खेलने का निर्णय लेते हैं, तो मेरा सुझाव है कि आप नए
LRU flush ऑप्टिमाइज़ेशन मापदंडों पर भी ध्यान दें, क्योंकि इन मापदंडों के अनुसार,
MySQL डेवलपर्स के
निष्कर्ष के अनुसार, अप्रत्यक्ष रूप से एक-दूसरे को प्रभावित कर सकते हैं।
ब्लॉक रीसेट को SSD ड्राइव के लिए अनुकूलित किया गया था। यह अस्पष्ट वाक्यांश निम्नलिखित इंगित करता है। जैसा कि हम जानते हैं, ब्लॉक कैशिंग पृष्ठों में होता है। 64 पेज हद बनाते हैं। समान सीमा के भीतर इन समान पृष्ठों को कॉल करने के लिए पड़ोस। पहले, जब पृष्ठ बदलते हैं, तो आउटपुट को ऑप्टिमाइज़ करने के लिए,
InnoDB ने डिस्क को फ्लश करने के लिए डेटा को फ्लश करने के लिए एक पूरी हद तक इकट्ठा करने की कोशिश की, क्योंकि HDD के लिए, एक मेगाबाइट इष्टतम आकार है, जो आपको डिस्क पर एक कॉल में ऑपरेशन करने की अनुमति देता है। SSDs के लिए, केवल 4 किलोबाइट का एक डंप आकार संभव है, इसलिए कुछ टाइप करने का कोई मतलब नहीं है। इसके अलावा, अपरिवर्तित पृष्ठों को डंप करना भी अर्थहीन है। तो newfangled लोहे के मालिक
पैरामीटर के साथ खेल सकते हैं।
निष्कर्ष के रूप में, यह
इस परीक्षा के परिणामों को नोटिस करने के लिए जगह से बाहर नहीं होगा।


जैसा कि आप ग्राफ़ से देख सकते हैं, जब कैश के साथ काम करते हैं, तो अनुकूलित रीसेट के साथ नया संस्करण
MySQL 4.0.30 खो देता
MySQL 4.0.30 (बहुत सारे प्राचीन संस्करण मेरे लिए अज्ञात हैं) सत्रों की एक छोटी संख्या के साथ, लेकिन यह स्केलिंग करते समय बेहतर परिणाम का क्रम दिखाता है।

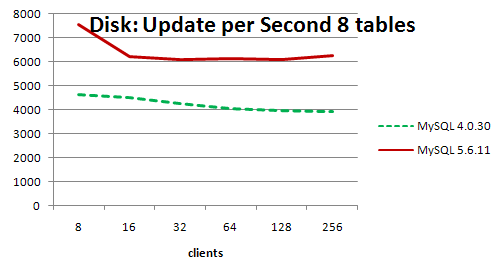
फ़ाइल सिस्टम के साथ काम करते समय, परिणाम इतने प्रभावशाली नहीं होते हैं और दोनों संस्करण सिर से सिर पर जाते हैं और MySQL 5.6 यहां तक कि स्थान भी खो देता है। हालाँकि, लेखक के निष्कर्ष के अनुसार,
5.6.12 रिलीज़ होने पर, इस कमी को समाप्त कर दिया जाएगा, और उत्पादकता 3 गुना
5.6.12 जाएगी। यानी जिन लोगों को बड़े इनपुट आउटपुट के साथ समस्या है और डिस्क के लिए बफ़र्स के सक्रिय फ्लशिंग के साथ, यह अगले संस्करण के रिलीज़ होने की प्रतीक्षा करने के लायक है, आप खुश होंगे।
InnoDB: ऑनलाइन टेबल ... ऑनलाइन
इस तकनीक की सभी प्रशंसा सुरक्षित रूप से दो शब्दों में की जा सकती है -
भोज विज्ञापन । डेवलपर्स के अनुसार, इस टीम
को पूरी तरह से थोड़ा अधिक फिर से लिखा गया था, हालांकि,
InnoDB-engine टीम को इसके लिए कोई महत्वपूर्ण लाभ नहीं मिला।
online , सीमित संख्या में अत्यंत दुर्लभ ऑपरेशन किए जाते हैं, और प्रतिबंधों के साथ भी। यह समझना कि ऑपरेशन
online गया
online बहुत आसान है। अनुरोध के परिणामस्वरूप, आप प्राप्त करेंगे
Query OK, 0 rows affected
और इसलिए क्या हो सकता है:
खैर, बस इतना ही। जैसा कि आप
हमें प्रदान किए गए अवसरों के विवरण से देख सकते हैं
, वे बेहद दुर्लभ हैं , हम आशा करते हैं कि भविष्य में स्थिति में सुधार होगा और टैम्बॉरिन के साथ नृत्य किए बिना बड़ी तालिकाओं में बदलाव किए जा सकते हैं, जो किसी भी समय निष्पादित होने पर तालिका की पूरी प्रतिलिपि के साथ जुड़े होते हैं (
MySQL 5.6 साथ, 5 के अपवाद के साथ कोई भी पढ़ें )
DDL कमांड्स।
विभाजन
विभाजन इंजन को काफी हद तक बदल दिया गया है। अब प्रसंस्करण के लिए विभाजन का चयन तालिकाओं को खोलने और ताले स्थापित करने से पहले किया जाता है। यहाँ एक विभाजन कुंजी पर एक तुच्छ क्वेरी के लिए इनपुट इनपुट का विश्लेषण है।
select count(1) from part_table where partition_key = 190110; +
इनपुट आउटपुट और बफर पूल
select count(distinct file_name) file_name_count, sum(sum_number_of_bytes_read) sum_number_of_bytes_read, min(substring_index(file_name, '/', -1)) min_file_name, max(substring_index(file_name, '/', -1)) max_file_name from performance_schema.file_summary_by_instance where file_name like '%part_table%.ibd' and count_read + count_write > 0 order by 1;
जैसा कि आप देख सकते हैं, संस्करण 5.5 के विपरीत, निर्दिष्ट तालिका के सभी विभाजन के लिए आंकड़ों का विश्लेषण नहीं किया जाता है, लेकिन केवल उन लोगों के लिए जो शर्त के अनुरूप हैं। जो बफर विभाजन में शेष विभाजनों को लोड करने से बाहर रखता है।तालों पर, अभी तक कुछ भी स्पष्ट नहीं है, क्योंकि पार्सिंग के लिए एल्गोरिथ्म और पूरा होने के अनुरोध की प्रतीक्षा में बहुत कुछ बदल गया है, जो आपकी आंख को पकड़ता है, wait/synch/mutex/mysys/THR_LOCK::mutexप्रत्येक विभाजन के लिए पहले से सबसे अवरुद्ध म्यूटेक्स बहुत कम आम हो गया है, अर्थात। जब एक विभाजन के लिए क्वेरी की जाती है, तो यह इतनी बार अवरुद्ध नहीं होता है कि इस तालिका में कुल विभाजन कितने दो से गुणा किए जाते हैं, लेकिन केवल एक, जो निस्संदेह एक बड़ा प्लस है। मैं अभी तक समान आक्रामक व्यवहार के साथ अन्य ताले नहीं खोज पाया हूं। जाहिर तौर पर पोस्ट में इंजन की समस्याएं बताई गई हैंसमाप्त कर दिया गया है (विभाजन की एक सूची प्राप्त करने के लिए, उन्हें स्वतंत्र रूप से बनाए रखने के बिना, आप तालिका का उपयोग कर सकते हैं mysql.innodb_table_stats, एक प्रविष्टि इसमें उस समय जोड़ी जाती है जब विभाजन बनाया जाता है, वास्तविक आंकड़े बाद में दिखाई देते हैं)। इसके अलावा, सुखद से, एक तालिका के लिए विभाजन की अधिकतम संभव संख्या पर सीमा में वृद्धि को नोट किया जा सकता है। चूंकि मुझे व्यक्तिगत रूप से इंजन के बारे में कोई और शिकायत नहीं है, इसलिए यह ध्यान देने योग्य है कि समानांतर प्रसंस्करण के लिए विभाजन बनाए गए हैं, हम hint parallel(n)विभाजित तालिकाओं की प्रतीक्षा कर रहे हैं ।बैकअप और पुनर्स्थापित
नए संस्करण में, एक बार में InnoDB के लिए दो बहुत ही अपेक्षित सुविधाओं को जोड़ा गया था:EXCHANGE PARTITION ALTER TABLE part_table EXCHANGE PARTITION p1 WITH TABLE non_part_table;
सब कुछ मानक है: तालिका में अनुक्रमित सहित पूरी तरह से समान संरचना होनी चाहिए, और storage engineयह भी आवश्यक है कि गैर-विभाजित तालिका में डेटा एक्सचेंज किए गए विभाजन की सीमाओं से परे न जाए।Transportable Tablespacesजैसा कि आप जानते हैं, बस .ibdफ़ाइल को बदलना और यह अपेक्षा करना कि आपके पास डेटा होगा काम नहीं करेगा। चूंकि यह ध्यान में रखना आवश्यक है: REDOलॉग, डेटा शब्दकोश, सिस्टम कॉलम, टेबल स्पेस मेटाडेटा, और शायद बहुत अधिक। इस तरह की जोड़तोड़ के लिए अब कई आदेश दिए गए हैं:निर्यात डेटाबेस पर- FLUSH TABLES table_one, table_two FOR EXPORT;- आयात डेटाबेस पर .ibdडेटाबेस निर्देशिका से प्रतिलिपि और उत्पन्न कॉन्फ़िगरेशन फ़ाइल - एक समान संरचना की एक खाली तालिका बनाएं - - प्रतिलिपिALTER TABLE table_one DISCARD TABLESPACE;.ibdऔर डेटाबेस निर्देशिका में उत्पन्न कॉन्फ़िगरेशन फ़ाइल- ALTER TABLE table_one IMPORT TABLESPACE;संचालन डेटा शब्दकोश के माध्यम से किया जाता है, जिसका अर्थ है जितनी जल्दी हो सके।प्रदर्शन स्कीमा
प्रदर्शन निदान सर्किटरी में उल्लेखनीय रूप से सुधार किया गया है। सबसे पहले, उसका काम तीन गुना तेज हो गया, अर्थात्। जब यह चालू होता है तो प्रदर्शन में गिरावट 10% नहीं बल्कि केवल 3.5% होती है, जिसने इसे डिफ़ॉल्ट रूप से चालू करने की अनुमति दी है। इसके अलावा, अब आरेख में पहले की तरह 17 टेबल नहीं हैं, लेकिन 52 हैं। बहुत सारे बदलाव हैं, जैसा कि आप समझते हैं, और यदि आपको उन सभी का वर्णन करने की आवश्यकता है, तो आपको एक अलग लेख की आवश्यकता है, इसके लिए मैं केवल कुंजी को उजागर करता हूं, मेरी राय में, उपयोगिता सेटअप और परिचय को फेंक रही है।- सीधे अनुरोधों का पता लगाना संभव हो गया
show tables like '%statements%'; +
- (
object_type= 'TEMPORARY TABLE' , - , )
select digest_text, sum_rows_affected, sum_rows_sent, sum_rows_examined from events_statements_summary_by_digest; +
show tables like '%by_thread%'; +
- , , ,
select digest_text, sum_created_tmp_disk_tables, sum_created_tmp_tables from events_statements_summary_by_digest; +
- , ,
show tables like 'table%waits%sum%'; +
उन दिलचस्पी मैं सिफारिश कर सकते हैं के लिए यहाँ है , मुझे लगता है कि वेबिनार बहुत ज्यादा है क्योंकि परिवर्तन के दोनों शुरुआती के लिए और संस्करण 5.5 के साथ इस योजना से परिचित लोगों के लिए उपयोगी हो जाएगा। मैं यह भी जोड़ता हूं कि चूंकि यह योजना अब डिफ़ॉल्ट रूप से सक्षम है, इसलिए इसकी सेटिंग्स बहुत मामूली हैं। उदाहरण के लिए, 5.5 के लिए मुख्य तालिका में events_waits_history_longकेवल 100 प्रविष्टियां हैं, और चूंकि ये सभी पैरामीटर स्थिर हैं और उन्हें बदलने के लिए उदाहरण की पुनरारंभ की आवश्यकता है, इसलिए अग्रिम में अपनी सेटिंग्स निर्धारित करना बेहतर है।निष्कर्ष
एक निष्कर्ष के रूप में, मैं अपने हालिया लेख में पीटर ज़िटसेव की आवाज़ का हवाला देते हुए खुद को अनुमति देता हूं । सिंथेटिक परीक्षणों के परिणामों के अनुसार, यह एक धागे के भार के साथ MySQL 5.6पिछले संस्करण की तुलना में MySQL 5.57.5-11 प्रतिशत धीमा है और 64 धागे के भार के साथ 11-26 प्रतिशत है, जो मूल रूप से आधिकारिक संस्करण से अलग है । यानी
सभी ने आशा के साथ फिर से लिखा, लेकिन एक प्रदर्शन को बढ़ावा नहीं मिला। ऊपर दिए गए सभी ऑप्टिमाइज़ेशन के साथ, निष्कर्ष केवल अभूतपूर्व है, लेकिन निश्चित रूप से आप अपने पर्यावरण की बेहतर जांच करते हैं। उदाहरण के लिए, हमारे लिए एक महत्वपूर्ण स्थान प्रक्रियाओं की कॉल है। इसके लिए, हम एक स्व-लिखित खुली रूपरेखा का उपयोग करते हैं , हब पर डेवलपर्स की , एसाइनव , जेबीडीसी-प्रोक है । तोते का मापन निम्नानुसार है।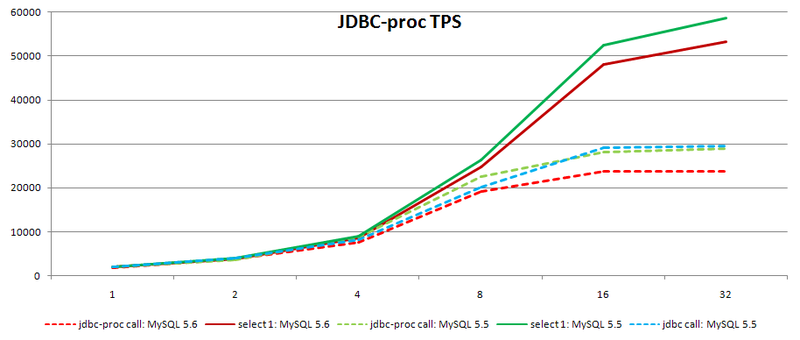 जैसा कि आप देख सकते हैं, हम अपने सर्वर पर प्रदर्शन लाभ प्राप्त नहीं करते हैं, इसके विपरीत, तोते 20% तक गिर जाते हैं, हालांकि, एक नया संस्करण स्थापित करते समय, हम बड़ी संख्या में नैदानिक उपकरण प्राप्त करते हैं जो हमें आसानी से अड़चन खोजने में सक्षम होंगे। इसके अलावा, अब यह स्पष्ट है कि MySQL सही दिशा में जा रहा है, और स्थिरता को सत्यापित करने के लिए कुछ संस्करणों की प्रतीक्षा करने के बाद, हम संस्करण को अपग्रेड करने की योजना बनाते हैं।
जैसा कि आप देख सकते हैं, हम अपने सर्वर पर प्रदर्शन लाभ प्राप्त नहीं करते हैं, इसके विपरीत, तोते 20% तक गिर जाते हैं, हालांकि, एक नया संस्करण स्थापित करते समय, हम बड़ी संख्या में नैदानिक उपकरण प्राप्त करते हैं जो हमें आसानी से अड़चन खोजने में सक्षम होंगे। इसके अलावा, अब यह स्पष्ट है कि MySQL सही दिशा में जा रहा है, और स्थिरता को सत्यापित करने के लिए कुछ संस्करणों की प्रतीक्षा करने के बाद, हम संस्करण को अपग्रेड करने की योजना बनाते हैं।