जब खेल के विकास के बारे में बात की जाती है, तो आमतौर पर यह शेड्स, ग्राफिक्स, एआई आदि के बारे में होता है। बहुत हद तक शायद ही कभी खेल परियोजनाओं के सर्वर पक्ष को प्रभावित करता है, और इससे भी कम - डेटाबेस। हम इस कष्टप्रद गलतफहमी को ठीक करेंगे: आज मैं डेटाबेस के साथ अपने अनुभव के बारे में बात करूंगा जो हमने एलोड्स ऑनलाइन और हमारे नए
स्काईफोर प्रोजेक्ट के विकास के दौरान प्राप्त किया था। ये दोनों खेल क्लाइंट MMORPG हैं। पहले में, कई मिलियन खिलाड़ी पंजीकृत हैं। दूसरे को स्टूडियो द्वारा ऑलोड्स टीम के आंतों में सबसे सख्त गोपनीयता में विकसित किया गया है।
मेरा नाम एंड्री फ्रोलोव है। मैं एलोड्स टीम के लिए मुख्य प्रोग्रामर हूं और सर्वर टीम के रूप में काम करता हूं। मेरा विकास का अनुभव लगभग 10 साल है, लेकिन मैं केवल अक्टूबर 2009 में खेल में शामिल हुआ। मैं मार्च 2010 के बाद से तीन साल से अधिक समय तक टीम में रहा हूं। मैंने ऑलोड्स ऑनलाइन पर काम करना शुरू किया, और अब स्काईफोरज पर। मैं हर उस चीज से निपटता हूं जो किसी तरह स्काईफोर सर्वर और डेटाबेस से जुड़ी है। इस लेख में मैं Allods और Skyforge के उदाहरण का उपयोग करके ऑनलाइन गेम में डेटाबेस के बारे में बात करूंगा।

यदि आप वास्तव में पढ़ना पसंद नहीं करते हैं, तो मैं अंत तक लेख के माध्यम से स्क्रॉल करने और गेम डेवलपर्स कॉन्फ्रेंस से अपनी रिपोर्ट का वीडियो देखने का सुझाव देता हूं। जो लोग पद पर बने रहते हैं उनके पास एक बोनस है - NoSQL-JSON हाइब्रिड और रिलेशनल डेटा मॉडल के बारे में कहानी के रूप में रिपोर्ट के लिए एक महत्वपूर्ण अतिरिक्त।
विकास
गेम बेस एक विशिष्ट ओएलटीपी प्रणाली (कई छोटे और छोटे लेनदेन) है। लेकिन खेलों में डेटाबेस का उपयोग वेब, बैंकों और अन्य उद्यमों पर उनके उपयोग से कुछ अलग है। सबसे पहले, यह इस तथ्य के कारण है कि खेलों में डेटा मॉडल बैंकों की तुलना में बहुत अधिक जटिल है। दूसरे, गेम देव में अधिकांश प्रोग्रामर C ++ की कठोर दुनिया से बाहर आए, उनके साथ दाढ़ी और बाइनरी पैकेजिंग का प्यार था। बिल्कुल उन सभी को, अगर उन्हें चरित्र को डिस्क पर सहेजने की आवश्यकता है, तो पहली चीज वे इसे एक फ़ाइल में क्रमबद्ध करना चाहते हैं। इस तरह यह सब Allods ऑनलाइन में शुरू हुआ। प्रोग्रामर ने फ़ाइल भंडारण किया, लेकिन जल्दी से इसे बेहतर समझा और MySQL के तहत सब कुछ फिर से लिखा। प्रोजेक्ट सफलतापूर्वक लॉन्च किया गया, लोगों ने खेला, अनुभव संचित किया।
एलोड्स में हमारे पास क्या था:
- जावा, MySQL
- शार्ड्स। और उनमें से प्रत्येक को कुछ सीमित खिलाड़ियों की संख्या के लिए डिज़ाइन किया गया था जो ऑनलाइन हैं
- खिलाड़ियों की संख्या ने प्रति सेकंड लगभग 200 लेनदेन उत्पन्न किए
- डेटाबेस के साथ काम करने वाली सेवा नीरस थी, क्योंकि इतने सारे लेन-देन के लिए यह पर्याप्त था
कुछ साल बाद स्काईफॉर्ज शुरू हुआ। Skyforge की पूरी तरह से अलग-अलग आवश्यकताएं थीं, और इसलिए डेटाबेस के साथ काम करने के लिए हमारे दृष्टिकोण पर पुनर्विचार करना पड़ा।
ये आवश्यकताएं हैं:
- अब हमारे पास शार्क नहीं हैं। हमारी एक बड़ी एकजुट दुनिया है
- हम अपने सर्वर को 100,000 खिलाड़ियों पर गिनते हैं, जो ऑनलाइन हैं, और संभवतः अधिक हैं
- हमारे अनुमानों के अनुसार, इन खिलाड़ियों को प्रति सेकंड 7000 से अधिक लेनदेन जारी करना चाहिए
- हम अभी भी जावा में लिखते हैं, लेकिन MySQL के साथ हमने PostgreSQL पर स्विच किया
ठीक है, आइए पर्दे के पीछे देखें और देखें कि हम अपने तकनीकी विचार के विकासवादी विकास के दौरान क्या आए थे।
आर्किटेक्चर
सबसे पहले, हमारे सर्वर वितरित किया जाता है। आधार भी वितरित किया जाता है। दूसरे, हमारे सर्वर का आर्किटेक्चर सेवा-उन्मुख है। इसका मतलब यह है कि सब कुछ सेवाओं के रूप में प्रस्तुत किया जाता है जो संदेशों का आदान-प्रदान करते हैं। खेल में दर्जनों सेवाएं हैं, लेकिन केवल लेनदेन निष्पादन सेवाओं के लिए डेटाबेस तक सीधी पहुंच है। सामान्य शब्दों में और मेरी कलात्मक क्षमताओं के सर्वश्रेष्ठ के लिए, यह कुछ इस तरह दिखता है:

केवल यह ध्यान रखना आवश्यक है कि चित्र में दर्शाए गए सभी तत्व कई प्रतियों में मौजूद हैं।
- गेम मैकेनिक्स सर्वर पर अवतार हैं। एक अवतार हमारे खिलाड़ी का प्रतिनिधित्व करने वाली एक जावा वस्तु है। डेटाबेस सर्वर की तुलना में कई गुना अधिक गेम मैकेनिक्स सर्वर हैं।
- सभी सर्वर एक विशेष इंटरफ़ेस के माध्यम से डेटाबेस के साथ संवाद करते हैं। इस इंटरफ़ेस में सैकड़ों विधियाँ हैं, खेल यांत्रिकी प्रोग्रामर से आधार के वितरित सार को छुपाता है और एक समझने योग्य अनुबंध प्रदान करता है: एक विधि - एक लेनदेन। आपको यह समझने की आवश्यकता है कि यह सैकड़ों विधियों के साथ एक वर्ग नहीं है, बल्कि दस विधियों के साथ एक वर्ग है, जो प्रत्येक दस विधियों के साथ छोटे "उपप्रकार" देते हैं। एक प्रकार का "पैक" संचालन का।
- डेटाबेस सेवा (डेटाबेस) उन कार्यों को करती है जो आ चुके हैं और डेटाबेस पर अपना परिणाम लिखते हैं। डेटाबेस सेवा और डेटाबेस स्वयं एक ही भौतिक सर्वर पर स्थित होते हैं ताकि नेटवर्क पर अतिरिक्त समय बर्बाद न हो।
कैश के रूप में अवतार
इस सरल योजना में एक महत्वपूर्ण बिंदु है। गेम मैकेनिक्स के प्रदर्शन के लिए हमारे अवतार की आवश्यकता है, लेकिन एक साइड इफेक्ट के रूप में, यह वास्तव में डेटाबेस पर कैश है। सभी अनुरोध जैसे "मुझे इस खिलाड़ी के आइटम दिखाएं" या "वसीली का अवतार कहाँ है?" इस अवतार द्वारा परोसा जाता है। जब कोई खिलाड़ी खेल में प्रवेश करता है, तो हम उसका अवतार अपलोड करते हैं, और वह तब तक रहता है जब तक खिलाड़ी ऑनलाइन है। यह सरल ट्रिक आपको डेटाबेस से अधिकांश रीड रिक्वेस्ट और राइट रिक्वेस्ट के हिस्से को हटाने की अनुमति देता है।
हम सभी खिलाड़ियों के डेटा को दो श्रेणियों में विभाजित करते हैं:
- महत्वहीन डेटा, जिसका नुकसान खिलाड़ी बच सकता है। इनमें मानचित्र पर स्थिति, स्वास्थ्य का स्तर आदि शामिल हैं। हम अवतार से इस तरह के डेटा को "समय-समय पर" जमा करते हैं, साथ ही साथ खेल छोड़ने के बाद, हम इसे डेटाबेस में छोड़ देते हैं।
- महत्वपूर्ण डेटा, जिसका नुकसान खिलाड़ी के लिए दर्दनाक होगा। इनमें आइटम, पैसा, quests और इसी तरह की चीजें शामिल हैं। इस डेटा के साथ, सब कुछ बहुत अधिक जटिल है। हम यह सुनिश्चित करने की कोशिश करते हैं कि खिलाड़ी इस डेटा को कभी नहीं खोए, क्योंकि उन्होंने उन पर बहुत समय और प्रयास किया। इसलिए, उन्हें डेटाबेस में समान रूप से सहेजा जाना चाहिए। यह महत्वपूर्ण डेटा का संरक्षण है जो हमारे डेटाबेस पर मुख्य बोझ बनाता है।
तो, हम अपने महत्वपूर्ण डेटा की स्थिति को डेटाबेस और अवतार में दूसरे सर्वर पर कैसे सिंक्रनाइज़ करते हैं? सब कुछ वास्तव में काफी सरल है। विषय लेने की योजना पर विचार करें।
- खेल यांत्रिकी सर्वर डेटाबेस सेवा "आइटम XXX ले" के लिए एक अनुरोध भेजता है।
- डेटाबेस सर्वर आवश्यक जांच करता है (क्या बैग में पर्याप्त जगह है, क्या इस आइटम को "चमकता हुआ", और इसी तरह की आवश्यकता है)। उसके बाद, वह अवतार बैग की अद्यतन स्थिति को आधार पर सहेजता है।
- यदि बचत सफल रही, तभी अवतार को उसके बैग की स्थिति के लिए एक अपडेट भेजा जाता है। अवतार, बदले में, गेम क्लाइंट को अपडेट भेजता है। नतीजतन, खिलाड़ी यह देखेगा कि उसके पास एक आइटम है, केवल जब आइटम सुरक्षित रूप से आधार में संग्रहीत होता है।
PostgreSQL
Skyforge में, हमने नीचे सूचीबद्ध कारणों के संयोजन के लिए MySQL को छोड़ दिया।
- MySQL में, सभी सुविधाएँ विभिन्न स्टोरेज इंजन में फैली हुई हैं। इनोबीडी में कुछ था, माईसैम में कुछ था, मेमोरी इंजन में कुछ था। यह बहुत जटिल जीवन है।
- MySQL में, एक वितरित लेनदेन तंत्र टूट गया है, जिसे हम वास्तव में उपयोग करना चाहते थे। MySQL डेवलपर्स ने इसे केवल छठे संस्करण में ठीक करने का वादा किया, जो अभी तक योजनाओं में भी नहीं है।
- MySQL में, समूह प्रतिबद्ध का तंत्र टूट गया था। संस्करण 5.5 में इसकी मरम्मत की गई थी, और यह आइटम अब प्रासंगिक नहीं है।
- MySQL में वास्तव में काफी कुछ कीड़े हैं, अजीब तरह से काम करने वाले फीचर्स और बहुत सीमित क्वेरी ऑप्टिमाइज़र हैं।
PostgreSQL ने इन सभी समस्याओं को हल किया, बदले में केवल ऑटो-वैक्यूम के साथ एक समस्या दी। हमने NoSQL डेटाबेस नहीं लेने का फैसला किया, क्योंकि हमारे पास डेटा संगति के लिए बहुत अधिक आवश्यकताएं हैं, और दुनिया में एक भी NoSQL डेटाबेस लगातार और किसी वस्तु को एक अवतार से दूसरे में स्थानांतरित नहीं कर सकता है। इस मामले में आखिरकार हमें निरंतरता बहुत पसंद नहीं आई, क्योंकि यह खेल के अनुभव को बहुत बिगाड़ देता है।
हाइब्रिड डेटा स्कीमा
तथ्य यह है कि हम PostgreSQL का उपयोग करते हैं इसका मतलब यह नहीं है कि हमें डेटा को एक संबंधपरक रूप में संग्रहीत करना चाहिए। रिलेशनल डेटाबेस को की-वैल्यू स्टोरेज के रूप में इस्तेमाल किया जा सकता है
एक पूरी तरह से संबंधपरक मॉडल हमें शोभा नहीं देता, क्योंकि कई प्रदर्शन बाधाओं में शामिल हैं। उदाहरण के लिए, हमारे पास एक खिलाड़ी है, और उसके पास quests है। एक खिलाड़ी सैकड़ों quests पूरा कर सकता है, और खेल में प्रवेश करने पर हमें उन सभी को दिखाने की आवश्यकता होगी। यदि आप रिलेशनल मॉडल का उपयोग करते हैं, तो आपको डेटाबेस से सैकड़ों पंक्तियों को वापस करने का अनुरोध करना होगा, और यह धीमा है। दूसरी ओर, गैर-संबंधपरक मॉडल के कई नुकसान हैं: स्थिरांक की कमी, डेटा को आंशिक रूप से अपडेट करने में असमर्थता आदि।
विभिन्न प्रयोगों के बाद, हम सहमत हुए कि हम संबंधपरक मॉडल के एक बंडल से संतुष्ट हैं, जिसमें कुछ क्षेत्रों में गैर-संबंधपरक डेटा शामिल हैं। एलोड्स में और स्काईफोर्ज में हाल तक, हमने डेटा बाइनरी के हिस्से को क्रमबद्ध किया और तालिकाओं में फ़ील्ड के रूप में संग्रहीत किया। लेकिन सिर्फ तीन हफ्ते पहले, हमने आखिरकार सब कुछ समझ लिया और अब हम JSON आवेषण के साथ डेटा को एक रिलेशनल स्कीम में स्टोर करते हैं।
यह कुछ इस तरह दिखता है:
id | 144115188075857124
position |
{"point":{"x":7402.2793,"y":6080.2197,"z":51.42402},"yaw":0.0,"map":"id:132646944","isLocal":false,"isValid":true}
death_descriptor | {"deathTime":-1,"respawnTime":-1,"sparkReturnDelay":-1,"recentDeathTimesArray":[]}
health | 1250
mana_descriptor | {"mana":{"8":300}}
avatar_client_info | \x
character_race_class_res_id | 26209282
character_sex_res_id | 550995
last_online_time | 1371814800726
JSON. , PostgreSQL 9.3 JSON. , — PostgreSQL MongoDB PostgreSQL.
Virtual shards
, . ID , , .
ID : — , — ID .
long id = <shard_id> <account_id>
. . . -, virtual shards . , , 15 . , 5 . 215 310. , .
SSD
SSD. RAID-. , , , fsync.
. , 200 , SSD. , SSD ó . SSD WAL PostgreSQL, , . SSD !
, .
- PostgreSQL — .
- SSD .
- -.
- , . .
, .
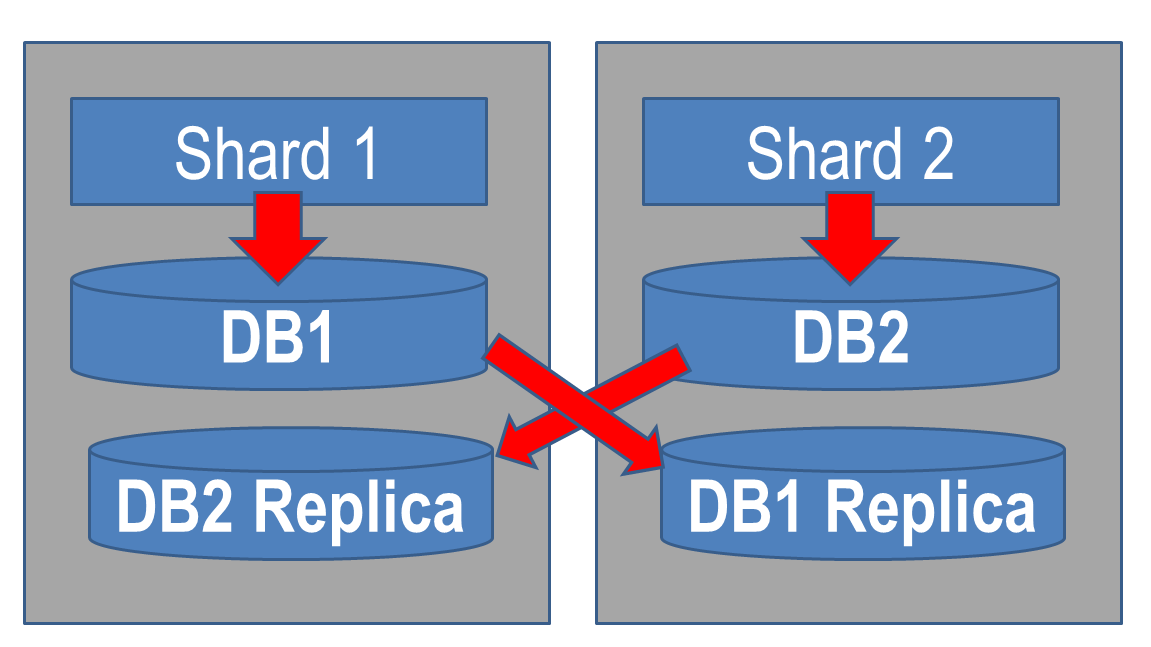
, , . . , master—slave , , .
,
.
C .
- .