यह
__COUNTER__ इनलाइन मैक्रो के लिए एक सुरक्षित विकल्प विकसित करने का प्रस्ताव है। मैक्रो की पहली घटना को
0 से बदल दिया जाता है, दूसरे को
1 , और इसी तरह। मान
__COUNTER__ प्रीप्रोसेसिंग चरण
__COUNTER__ प्रतिस्थापित किया जाता है, इसलिए इसका उपयोग
निरंतर अभिव्यक्ति के संदर्भ में किया जा सकता है।
दुर्भाग्य से, हेडर फ़ाइलों में
__COUNTER__ मैक्रो
__COUNTER__ उपयोग करना खतरनाक है - यदि हेडर फ़ाइलों को अलग-अलग चालू किया जाता है, तो काउंटर मान बदल जाएंगे। इससे ऐसी स्थिति उत्पन्न हो सकती है, उदाहरण के लिए,
foo.cpp में
AWESOME स्थिरांक का मान 42 है, जबकि
AWESOME≡33 । यह एक परिभाषा नियम के सिद्धांत का उल्लंघन है, जो C ++ ब्रह्मांड में एक भयानक अपराध है।
हमें एक ही वैश्विक एक (कम से कम प्रत्येक हेडर फ़ाइल के लिए) के बजाय स्थानीय काउंटरों का उपयोग करने की क्षमता की आवश्यकता है। इसी समय,
निरंतर अभिव्यक्ति में काउंटर मूल्य का उपयोग करने की क्षमता को संरक्षित किया जाना चाहिए।
स्टैक ओवरफ्लो पर
इस सवाल के आधार पर।
प्रेरक उदाहरण
एक संकलन समय काउंटर उपयोगी कब है?मान लीजिए कि हम क्रमबद्ध समर्थन के साथ सरल डेटा संरचनाओं को परिभाषित करने के लिए मैक्रोज़ को लागू करना चाहते हैं। यह कुछ इस तरह दिख सकता है:
STRUCT(Point3D) FIELD(x, float) FIELD(y, float) FIELD(z, float) END_STRUCT
यहां हम केवल
x, y और
z क्षेत्रों की सूची के साथ एक
Point3D संरचना को परिभाषित नहीं कर रहे हैं। हमें
स्वचालित रूप से क्रमबद्धता और डीरिआयलाइज़ेशन फ़ंक्शन भी मिलते हैं। एक नया क्षेत्र जोड़ना असंभव है और इसके लिए क्रमांकन समर्थन के बारे में भूल जाओ। आपको
बढ़ावा देने के लिए बहुत कम लिखना होगा।
दुर्भाग्य से, हमें कम से कम दो बार फ़ील्ड्स की सूची से गुजरने की आवश्यकता है: ताकि क्षेत्र की परिभाषाएँ उत्पन्न हो सकें और क्रमबद्धता उत्पन्न हो सके। अकेले प्रीप्रोसेसर का उपयोग करना संभव नहीं है। लेकिन जैसा कि आप जानते हैं, C ++ में किसी भी समस्या को टेम्प्लेट की मदद से हल किया जा सकता है (टेम्प्लेट की अधिकता की समस्या को छोड़कर)।
हम
FIELD मैक्रो को निम्नानुसार परिभाषित करते हैं (हम स्पष्टता के लिए
__COUNTER__ उपयोग करते हैं):
#define FIELD(name, type) \ type name;
FIELD(x, float) तैनात करते समय
FIELD(x, float) हम प्राप्त करते हैं
float x;
FIELD(y, float) तैनात करते समय
FIELD(y, float) बदल जाता है
float y;
FIELD() की प्रत्येक बाद की घटना
FIELD() मैक्रो का विस्तार क्षेत्र की परिभाषा के साथ होता है,
साथ ही
serialize< की विशेषज्ञता
serialize< i >() फ़ंक्शन जहां
मैं = 0,1,2, ...
एन। serialize<i>() फ़ंक्शन कॉल को
serialize<i+1>() , और इसी तरह। एक काउंटर लिंक कार्यों को एक साथ जोड़ने में मदद करता है।
लिंक एक काम कर रहा नमूना कोड है।
एक-सा संकलन-समय काउंटर
शुरू करने के लिए, हम एक-बिट काउंटर के कार्यान्वयन को दिखाएंगे।
- टेम्पलेट संरचना को परिभाषित करें
cn<n> । ध्यान दें कि sizeof(cn<n>) ≡ n+1 ।
- टेम्पलेट फ़ंक्शन
magic परिभाषित करें।
- एक अभिव्यक्ति पर लागू
sizeof ऑपरेटर उस प्रकार का आकार लौटाता है जो दी गई अभिव्यक्ति है। चूंकि अभिव्यक्ति का मूल्यांकन नहीं किया जाता है, इसलिए magic फ़ंक्शन के शरीर की कोई परिभाषा की आवश्यकता नहीं है।
वर्तमान में परिभाषित एकमात्र magic फ़ंक्शन चरण 2 में टेम्पलेट है। इसलिए, वापसी मान का प्रकार और संपूर्ण अभिव्यक्ति cn<0> ।
- अतिभारित
magic फ़ंक्शन को परिभाषित करें। ध्यान दें कि magic बुलाते समय अस्पष्टता नहीं होती है, क्योंकि अतिभारित कार्य टेम्पलेट कार्यों पर पूर्वता लेते हैं।
- अब, जब कॉलिंग
magic(cn<0>()) , फ़ंक्शन का दूसरा संस्करण उपयोग किया जाएगा; sizeof अंदर अभिव्यक्ति का प्रकार cn< 1 >() ।
सारांशित करें - हमारे पास एक फ़ंक्शन कॉल के साथ एक अभिव्यक्ति है। हम अतिभारित फ़ंक्शन की परिभाषा जोड़ते हैं, परिणामस्वरूप, संकलक एक नया फ़ंक्शन का उपयोग करता है। इस प्रकार, फ़ंक्शन से वापसी मान का प्रकार और संपूर्ण अभिव्यक्ति का प्रकार बदल गया है, हालांकि अभिव्यक्ति समान
रूप से बनी हुई है।
पढ़ने के लिए मैक्रो को परिभाषित करें और एक-बिट काउंटर को "इंक्रीमेंट" करें।
#define counter_read(id) \ (sizeof(magic(cn<0>())) - 1) #define counter_inc(id) \ cn<1> magic(cn<0>)
आईडी पैरामीटर के बारे मेंडिजाइन द्वारा, आईडी पैरामीटर कई प्रकार के स्वतंत्र काउंटरों के उपयोग की अनुमति देता है, अद्वितीय प्रकारों की पहचान करके और आईडी के रूप में उनका उपयोग करके। आईडी का समर्थन करने के लिए, magic को एक अतिरिक्त id पैरामीटर लेना चाहिए। ओवरलोडेड magic फ़ंक्शन एक विशिष्ट आईडी का उल्लेख करेगा, और अन्य सभी आईडी को प्रभावित नहीं करेगा।
एन-बिट संकलन समय काउंटर
एन-बिट काउंटर एकल-बिट काउंटर के समान सिद्धांतों पर बनाया गया है।
sizeof अंदर एक एकल
magic कॉल के बजाय, हमारे पास नेस्टेड कॉल की एक श्रृंखला होगी
a(b(c(d(e( … ))))).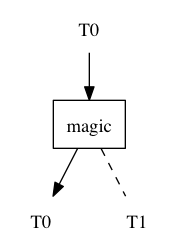
यहाँ यह है, हमारा बुनियादी भवन खंड। यह टाइप
0 के एकल तर्क का एक फ़ंक्शन है। उपलब्ध स्कोप घोषणाओं के आधार पर, रिटर्न प्रकार या तो टी
0 या टी
1 है । यह उपकरण एक रेल के तीर जैसा दिखता है। प्रारंभिक अवस्था में, "तीर" बाईं ओर निर्देशित है। तीर को केवल एक बार स्विच किया जा सकता है।
कई बुनियादी ब्लॉकों का उपयोग करके, हम एक व्यापक नेटवर्क बना सकते हैं:
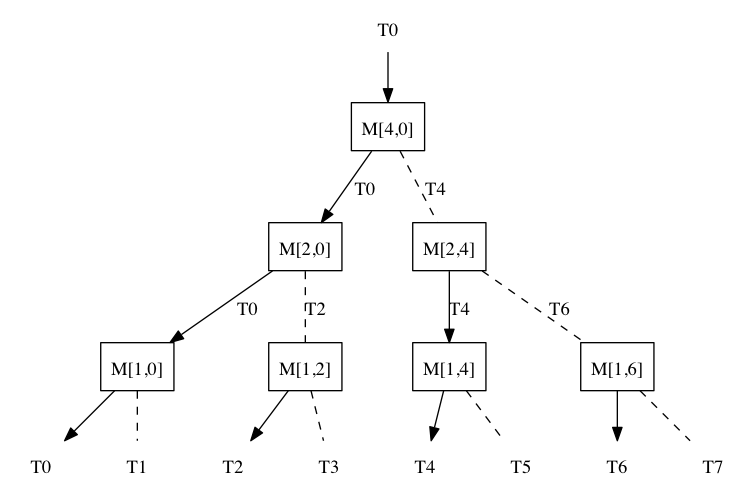
किसी फ़ंक्शन के उपयुक्त संस्करण की खोज करते समय, C ++ कंपाइलर केवल मापदंडों के प्रकारों को ध्यान में रखता है और रिटर्न मान के प्रकार को अनदेखा करता है। यदि अभिव्यक्ति नेस्टेड फ़ंक्शन कॉल है, तो संकलक अंदर से "चलता" है। उदाहरण के लिए, निम्न अभिव्यक्ति में: M
1 (M
2 (M
4 (T
0 ()))), संकलक पहले फ़ंक्शन (
4 ) (M
0 (T
0 ) को कॉल करने की अनुमति देता है। फिर, फ़ंक्शन M
4 के वापसी मूल्य के प्रकार के आधार पर, यह M
2 (T
0 ) या M
2 (T
4 ), और इसी तरह की कॉल की अनुमति देता है।
रेलवे सादृश्य को जारी रखते हुए, हम कह सकते हैं कि कंपाइलर ऊपर से नीचे तक रेलवे नेटवर्क के साथ-साथ, दाएँ या बाएँ तीर पर "मुड़ता" है।
एन नेस्टेड फ़ंक्शन कॉल की अभिव्यक्ति 2
एन आउटपुट के साथ एक नेटवर्क को जन्म देती है। सही क्रम में तीरों को स्विच करना, आप नेटवर्क के आउटपुट पर क्रमिक रूप से सभी 2
एन संभव प्रकार के टी
i प्राप्त कर सकते हैं।
यह दिखाया जा सकता है कि यदि नेटवर्क के आउटपुट में वर्तमान प्रकार T
i है , तो अगले एक को तीर
M [(i + 1) और ~ i, (i + 1) & i] को स्विच करना होगा।
कोड का अंतिम संस्करण
यहां उपलब्ध
है ।
एक निष्कर्ष के बजाय
संकलन-समय काउंटर पूरी तरह से अतिभारित कार्यों के तंत्र पर आधारित है। मैंने स्टैक ओवरफ्लो पर इस तकनीक को
देखा । एक नियम के रूप में, C ++ में
गैर-तुच्छ संकलन समय गणना टेम्प्लेट पर लागू की जाती है, यही कारण है कि प्रस्तुत समाधान विशेष रूप से दिलचस्प है, क्योंकि यह टेम्पलेट्स के बजाय अन्य तंत्र का उपयोग करता है।
ये उपाय कितने व्यावहारिक हैं?
IMHO अगर एक एकल C ++ फ़ाइल को 5 मिनट से अधिक समय के लिए संकलित किया जाता है, और केवल संकलक का नवीनतम संस्करण इसके साथ सामना कर सकता है - यह निश्चित रूप से
अव्यावहारिक है । C ++ में भाषा सुविधाओं का उपयोग करने के लिए कई "रचनात्मक" विकल्प विशुद्ध रूप से शैक्षणिक रुचि के हैं। एक नियम के रूप में, समान कार्यों को अन्य तरीकों से बेहतर तरीके से हल किया जा सकता है, उदाहरण के लिए, बाहरी कोड जनरेटर को शामिल करके। हालाँकि, मुझे कहना होगा, लेखक इस मामले में कुछ हद तक पक्षपाती है, स्पष्ट रूप से
भावना को नहीं पहचान रहा
है , और
बाइसन के प्रति कुछ कमजोरी का अनुभव कर रहा है।
ऐसा लगता है कि संकलन-समय काउंटर भी बहुत व्यावहारिक नहीं है, जैसा कि निम्नलिखित ग्राफ में स्पष्ट रूप से देखा जा सकता है।
X- अक्ष परीक्षण कार्यक्रम में काउंटर की वृद्धि के पूर्ण मूल्य का प्रतिनिधित्व करता है (परीक्षण कार्यक्रम में
counter_inc(int) लाइनें शामिल हैं),
y -axis सेकंड में संकलन समय का
counter_inc(int) करता है। तुलना के लिए, nginx-1.5.2 का संकलन समय भी स्थगित है।
