नमस्कार दोस्तों!
Github एक बेहतरीन साइट है। लेकिन कल्पना कीजिए कि आपने प्रोजेक्ट ए पाया और जानना चाहते हैं कि अन्य समान परियोजनाएं क्या हैं। कैसे हो?
यह इस प्रेरणा के साथ था कि मैं गिटहब एपीआई को अलग करने के लिए बैठ गया। कुछ हफ़्तों के खाली समय के बाद, ऐसा ही हुआ:
अधिकांश परियोजनाओं के लिए, वास्तव में दिलचस्प प्रस्तावों के एक जोड़े हैं। यहां कुछ उदाहरण दिए गए हैं:
कोणीय.जेएस ,
फ्रंट एंड बुकमार्क ,
तीन.जेएससिफारिशों के निर्माण के लिए मुख्य विचार "डेवलपर्स जो इस परियोजना पर एक तारांकन चिह्न डालते हैं, एक तारांकन चिह्न भी डालते हैं ..."। और विचार का विवरण, इसकी कमियों और कोड का लिंक नीचे दिया गया है।
शायद मुझे यह स्वीकार करना चाहिए कि मैं मशीन लर्निंग या सिफारिश प्रणालियों के निर्माण के क्षेत्र में विशेषज्ञ नहीं हूं। नीचे वर्णित सभी एक प्रयोगात्मक प्रहार और महान जिज्ञासा का परिणाम है।
एक शुरुआत के लिए विचारआइए प्रोजेक्ट ए के सभी अनुयायियों का विश्लेषण करें, देखें कि वे किन अन्य परियोजनाओं का अनुसरण करते हैं, और सबसे अक्सर दोहराए जाने वाले प्रोजेक्टों का चयन करते हैं? काश, यह दृष्टिकोण बुरी तरह से विफल हो गया: सिफारिशों की खोज के परिणामों के बीच, सबसे लोकप्रिय परियोजनाएं अक्सर पहले आती हैं, लेकिन जरूरी नहीं कि वर्तमान से संबंधित हो। सभी गिटहब
बूटस्ट्रैप के प्यार में है - आज के लिए सबसे लोकप्रिय परियोजना।
एक आम तारे का वजन कितना होता है?उदाहरण के लिए:
प्रोजेक्ट ए - केवल 100 सितारे
प्रोजेक्ट बी - केवल 200 सितारे
प्रोजेक्ट सी - केवल 1000 सितारे
मान लीजिए कि समान डेवलपर्स में से एक सौ ने A और B को प्रोजेक्ट करने के लिए एक तारांकन चिह्न रखा है, और एक ही डेवलपर्स के सौ ने A और C को प्रोजेक्ट करने के लिए एक तारांकन चिह्न रखा है। B या C कौन सा प्रोजेक्ट B या C प्रोजेक्ट A के करीब होगा? जाहिर है - बी। उनके आधे अनुयायी प्रोजेक्ट ए का अनुसरण करते हैं। सी के केवल 10% अनुयायियों ने प्रोजेक्ट ए को देखा।
हम एक समानता सूत्र में तीन चर कैसे संक्षेप कर सकते हैं? मैंने धीरे से सोचा और दोनों परियोजनाओं के कुल सितारों में से कुल सितारों के प्रतिशत पर विचार करने का विचार तुरंत नहीं आया:
similarity = 2 * shared_stars_count / (project_a_stars + project_b_stars)सूत्र बहुत अच्छी सिफारिशें देता है। जैसा कि मैंने बाद में
कैमरन डेविडसन से सीखा, यह सूत्र 1946 में दो नर्ड द्वारा प्राप्त किया गया था (यह किसी को अपमानित करने का प्रयास नहीं है, वे वास्तव में वनस्पति विज्ञान के विशेषज्ञ थे):
सोरेंसन और डायस ।
एपीआई मुद्देदुर्भाग्य से, GitHub के पास बल्क API नहीं है जो आपको एक ही अनुरोध के साथ सभी प्रोजेक्ट अनुयायियों के बारे में जानकारी प्राप्त करने की अनुमति देता है। सभी असुविधा के लिए, प्रति घंटे 5,000 अनुरोधों की सीमा परियोजना विश्लेषण को असहनीय रूप से लंबा बनाती है।
Addi Osmani ने केवल कुछ सौ अनुयायियों के विश्लेषण के लिए खुद को सीमित करने का सुझाव दिया। प्रायोगिक तौर पर, यदि आप परियोजना के यादृच्छिक 500 अनुयायियों का चयन करते हैं, तो सिफारिशों का परिणाम नहीं होगा।
परियोजना ए के यादृच्छिक एन अनुयायियों के लिए परियोजना समानता मीट्रिक निम्नानुसार फिर से लिखा गया था:
alpha = N/project_a_starssimilarity = 2 * N / (alpha * (N + project_b_stars))यह शब्दांकन लगभग समान सितारों वाली परियोजनाओं को एक दूसरे के करीब बनाता है और लोकप्रिय परियोजनाओं से शोर को समाप्त करता है।
दुर्भाग्य से, एन = 500 के साथ भी, एक परियोजना के विश्लेषण के लिए निर्माण समय में लगभग सात मिनट लगते हैं।
लेकिन क्या होगा अगर हम पहले से ही सभी समान परियोजनाओं की गणना करते हैं?सिफारिश 200+ सितारों वाली परियोजनाओं के लिए अच्छी तरह से काम करती है। लेकिन GitHub'e पर ऐसी कितनी परियोजनाएं हैं? जैसा कि यह निकला,
सात हजार से थोड़ा
अधिक (कोड लिखने के समय लगभग 7,300 था)।
लोकप्रिय रिपॉजिटरी के सभी अनुयायियों के उपनामों की खोज के लिए एक मकड़ी लिखे जाने के बाद, मैंने लगभग 457,115 अद्वितीय उपयोगकर्ताओं को पाया :)। अब प्रत्येक उपयोगकर्ता के लिए आपको उसकी पसंदीदा परियोजनाएँ प्राप्त करने की आवश्यकता है। लेकिन इसमें कितना समय लग सकता है? यहां तक कि प्रति चरण 300 सितारों के एक बहुत निराशावादी अनुमान के साथ, प्रति घंटे 5,000 अनुरोधों की सीमा को देखते हुए, मुझे बिना रुके 11 दिनों के लिए गिटब को "खोदना" पड़ेगा।
11 दिन एक शौक के लिए इतना नहीं है, है ना? कार्य को अच्छी तरह से वितरित किया गया है, क्योंकि यदि आपके पास एक अच्छा दोस्त है जो गितुब पर अपना टोकन साझा करने के लिए तैयार है, तो आप इसे एक सप्ताह में संभाल सकते हैं! उसी शाम, एक मकड़ी अपने पसंदीदा अनुयायी परियोजनाओं को इकट्ठा करने के लिए दिखाई दी।
फन रगड़ते हुए जाल,
समय-समय पर अक्सर कीड़े पर ट्रिपिंग करते हुए, दो मकड़ियों ने 4 दिनों के लिए आवश्यक डेटा एकत्र किया। जैसा कि यह निकला, औसतन गीथूब का एक उपयोगकर्ता 22 सितारे देता है। केवल 0.02% उपयोगकर्ताओं ने 600 से अधिक सितारे दिए। इसलिए, मकड़ियों के निर्दोष ऑपरेशन के साथ, एक दो दिनों में सभी आवश्यक आधार बन सकते हैं।
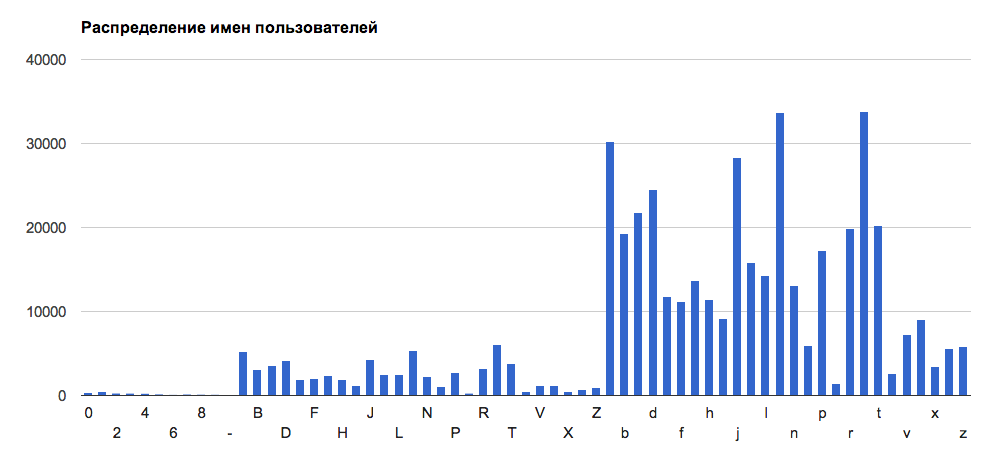
बेकार तथ्यGtHub पर, अधिकांश उपनाम 's' अक्षर से शुरू होते हैं। वे 'एम' और 'ए' पर उपयोगकर्ताओं द्वारा अनुसरण किए जाते हैं। राजधानी 'क्यू' पर निकन्स 2 नंबर पर nicks से कम आम हैं:
 बादल को
बादल कोमैंने मकड़ियों का परिणाम
S3 पर अपलोड किया। सभी आधुनिक ब्राउज़र कॉर्स को पहचानते हैं, इसलिए, नियमित अजाक्स अनुरोध का उपयोग करके, आप सिफारिशों के साथ आवश्यक जेएस फ़ाइल प्राप्त कर सकते हैं। यदि प्रोजेक्ट के लिए परिकलित अनुशंसाएँ क्लाउड में मौजूद नहीं हैं, तो साइट बिल्डिंग अनुशंसाओं के ऑनलाइन मोड में चली जाएगी। बड़ा कोटा प्राप्त करने के लिए गीथूब को प्रमाणित करें। मध्यवर्ती डेटा स्थानीय IndexedDB में सहेजा जाता है, इसलिए आप पृष्ठ बंद होने के बाद भी अनुक्रमण फिर से शुरू कर सकते हैं।
कोडयदि आप, प्रिय हैब्रिटाटेल, जानते हैं कि सिफारिशों को कैसे सुधारना है, तो मुझे बहुत खुशी है! साइट कोड यहाँ उपलब्ध है:
avaka / gazer ।
उन परियोजनाओं पर सितारे लगाएं जो आपको पसंद हैं - यह न केवल रिपॉजिटरी के लेखकों के लिए अच्छा है, बल्कि अन्य डेवलपर्स को सही प्रोजेक्ट खोजने में भी मदद कर सकता है :)।
अंत तक पढ़ने के लिए बहुत बहुत धन्यवाद :)!