
इस लेख में मैं वर्णन करना चाहता हूं कि Proxmox 3.0 होस्ट मशीनों पर ड्रब मिररिंग बनाने पर कैसे। एक प्रॉक्समोक्स क्लस्टर में मशीनों का संयोजन इन ऑपरेशनों से पहले समझ में आता है - हालांकि सामान्य तौर पर कोई अंतर नहीं है।
इस सामग्री और इंटरनेट पर फैले हुए कई के बीच मुख्य अंतर यह है कि हम विभाजन को दूसरे से जुड़े एक नए भौतिक ड्राइव पर नहीं करते हैं, लेकिन केवल उपलब्ध ड्राइव के भीतर lvm विभाजन पर।
इस तरह की कार्रवाइयों की उपयुक्तता का प्रश्न पर्याप्त रूप से बहस योग्य है - चाहे ड्रब "कच्चे" डिस्क पर तेज होगा या नहीं, लेकिन किसी भी मामले में यह 100% परीक्षण का विकल्प है। एक गुल्लक में तो बोलने के लिए। हां, और "कच्ची" डिस्क के साथ काम करना इस निर्देश का सिर्फ एक विशेष मामला है।
दरअसल, स्थापना के दौरान Proxmox 3.0 (साथ ही इसके पूर्ववर्ती 2.0) विभाजन के मुद्दों से परेशान नहीं होता है और स्वयं ही सब कुछ तोड़ देता है, केवल कुल डिस्क आकार और मेमोरी आकार को ध्यान में रखते हुए। हम / pve / डेटा विभाजन प्राप्त करते हैं, जो अधिकांश डिस्क पर कब्जा कर लेता है और स्थानीय भंडारण के रूप में Proxmox में दिखाई देता है। यह उसके कारण है कि कार्रवाई की जाएगी।
1. वर्तमान के लिए संकुल अद्यतन करें
#aptitude update && aptitude full-upgrade2. आवश्यक पैकेज स्थापित करें
#aptitude install drbd8-utils3. एक नए अनुभाग के लिए स्थान खाली करना।
अनमाउंट / देव / pve / डेटा (aka / var / lib / vz)। चरण 3 के सभी निम्नलिखित चरणों को केवल अनमाउंट किए गए संसाधन पर किया जा सकता है - तदनुसार, इससे पहले, हम इस नोड पर स्थानीय भंडारण का उपयोग करने वाले सभी वीएम को बुझाते हैं। यदि आपको वास्तव में ज़रूरत है तो आप बाकी को नहीं छू सकते हैं।
#umount /dev/pve/data3.1। कमी / देव / pve / डेटा।
सिद्धांत रूप में, अगले कुछ चरणों को आदेशों से बदला जा सकता है
#lvresize -L 55G /dev/mapper/pve-data#mkfs.ext3 /dev/pve/dataखैर, या थोड़ा और विस्तृत। और मेरी राय में थोड़ा और सही है।
#lvremove /dev/pve/data#lvcreate -n data -l 55G pve#mkfs.ext3 /dev/pve/dataलेकिन एक ही समय में, हम सब कुछ खो देते हैं जो स्थानीय भंडारण पर है। यदि प्रॉक्समोक्स ताज़ा रूप से स्थापित है (जो आमतौर पर इस तरह के जोड़तोड़ के लिए अनुशंसित है), तो वह सब और चरण 4 पर जाता है। यदि सवाल अभी भी स्थानीय भंडारण में डेटा को बचाने के लिए है, तो हम अलग तरीके से कार्य करेंगे।
3.2। जानकारी खोए बिना / देव / pve / डेटा को कम करना।
मुझे लगता है कि स्थानीय 50G से कम है। यदि आपके पास एक अलग स्थिति है, तो बस टीमों में "नए आकार" को बदल दें।
#umount /dev/pve/dataअनिवार्य जांच, इसके बिना resize2fs काम नहीं करेगा
#e2fsck -f /dev/mapper/pve-datae2fsck 1.42.5 (29-Jul-2012)Pass 1: Checking inodes, blocks, and sizesPass 2: Checking directory structurePass 3: Checking directory connectivityPass 4: Checking reference countsPass 5: Checking group summary information/dev/mapper/pve-data: 20/53223424 files (0.0% non-contiguous), 3390724/212865024 blocksफ़ाइल सिस्टम को 50G पर संपीड़ित करें। यदि आप इस कदम को छोड़ देते हैं, तो 90% की संभावना के साथ lvresize के बाद हमें एक टूटी हुई प्रणाली मिल जाएगी। इसके अलावा, संख्या जानबूझकर परिणामी अनुभाग की तुलना में थोड़ा कम है। एक मार्जिन के साथ।
#resize2fs /dev/mapper/pve-data 50Gresize2fs 1.42.5 (29-Jul-2012)Resizing the filesystem on /dev/mapper/pve-data to 13107200 (4k) blocks.The filesystem on /dev/mapper/pve-data is now 13107200 blocks long.#e2fsck -f /dev/mapper/pve-dataसीधे / 55G करने के लिए / pve / डेटा अनुभाग संपीड़ित करें
#lvresize -L 55G /dev/mapper/pve-dataWARNING: Reducing active logical volume to 55.00 GiBTHIS MAY DESTROY YOUR DATA (filesystem etc.)Do you really want to reduce data? [y/n]: yReducing logical volume data to 55.00 GiBLogical volume data successfully resizedहम सभी उपलब्ध स्थान पर सिस्टम पर कब्जा कर लेते हैं। सिद्धांत रूप में, यदि पिछले चरण में आपका "मार्जिन" बड़ा नहीं है, तो ऐसा नहीं किया जा सकता है। मैचों पर क्यों बचाएं? ;)
#resize2fs /dev/mapper/pve-dataresize2fs 1.42.5 (29-Jul-2012)Resizing the filesystem on /dev/mapper/pve-data to 14417920 (4k) blocks.The filesystem on /dev/mapper/pve-data is now 14417920 blocks long.हम सिस्टम में / dev / pve / data लौटाते हैं।
#mount /dev/pve/data4. शराबी के लिए एक विभाजन बनाना
हम खाली जगह को देखते हैं। हम आश्वस्त हैं कि पिछले सभी चरणों ने जो दिया है वह अपूरणीय है। यानी / देव / sda2 विभाजन पर मुक्त स्थान
#pvdisplay--- Physical volume ---PV Name /dev/sda2VG Name pvePV Size 931.01 GiB / not usable 0Allocatable yesPE Size 4.00 MiBTotal PE 238339Free PE 197891Allocated PE 40448PV UUID 6ukzQc-D8VO-xqEK-X15T-J2Wi-Adth-dCy9LDसभी खाली जगह पर एक नया सेक्शन बनाएं।
#lvcreate -n drbd0 -l 100%FREE pveLogical volume "drbd" created5. हम ड्रब विन्यास फाइल तैयार करते हैं
#nano /etc/drbd.d/r0.resसंसाधन r0 {
स्टार्टअप {
wfc-timeout 120;
degr-wfc-timeout 60;
प्राथमिक-दोनों पर;
}
शुद्ध {
cram-hmac-alg sha1;
साझा-गुप्त "प्रॉक्समोक्स";
अनुमति देते हैं-दो प्राइमरी;
बाद sb-0pri त्याग-शून्य-परिवर्तन;
बाद sb-1pri त्याग-माध्यमिक;
बाद sb-2pri डिस्कनेक्ट;
}
पर्यायवाची {
दर 30M;
}
p1 पर {
डिवाइस / देव / drbd0;
डिस्क / देव / pve / drbd;
पता 10.1.1.1:7788;
मेटा-डिस्क आंतरिक;
}
P2 {पर
डिवाइस / देव / drbd0;
डिस्क / देव / pve / drbd;
पता 10.1.1.2:7788;
मेटा-डिस्क आंतरिक;
}
}
कुछ लोग wfc-timeout पैरामीटर को 0. पर सेट करने की सलाह देते हैं। इसका अर्थ यह है कि अगर शुरुआत में हम drbd पड़ोसी को नहीं देखते हैं, तो wfc-timeout सेकंड के बाद यह दूसरे प्रयास के लिए रीबूट होगा। 0 - इस क्रिया को अक्षम करें।
दर 30M - ड्रब मेजबान के बीच स्थानांतरण सीमा। मान 1G कनेक्शन से मेल खाता है। मेजबानों के बीच वास्तविक चैनल बैंडविड्थ के 30% के रूप में अनुशंसित। नीचे दिए गए उदाहरण में, "परीक्षण खरगोशों" पर, 100M कनेक्शन पर बैंडविड्थ लगभग 11Mb / s है, अर्थात दर 3M तक कम होनी चाहिए। मेजबानों के बीच 10G कनेक्शन के साथ, यह स्पष्ट रूप से वृद्धि करने के लिए समझ में आता है।
6. मेटा डेटा बनाना और ड्रब विभाजन को लॉन्च करना।
#modprobe drbd#drbdadm create-md r0md_offset 830015008768al_offset 830014976000bm_offset 829989642240Found some data==> This might destroy existing data! <==Do you want to proceed?[need to type 'yes' to confirm] yesWriting meta data...initializing activity logNOT initialized bitmapNew drbd meta data block successfully created.Success#drbdadm up r0आप परिणाम इस तरह देख सकते हैं:
#cat /proc/drbdversion: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:WFConnection ro:Secondary/Unknown ds:UpToDate/DUnknown C r----sns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:8105367607. दूसरा मेजबान तैयार करें
हम दूसरी मेजबान मशीन पर 1-6 कदम रखते हैं। एक महत्वपूर्ण बिंदु (!)। ड्रब विभाजन का आकार दोनों मेजबानों पर समान होना चाहिए।
8. तुल्यकालन।
हम मेजबान में से एक लेते हैं (यह कोई फर्क नहीं पड़ता कि कौन सा)। चलो इसे तब तक कहते हैं जब तक प्राथमिक पूरी तरह से सिंक्रनाइज़ नहीं हो जाता। दूसरा, क्रमशः, द्वितीयक है। पूर्ण सिंक्रनाइज़ेशन के बाद, वे समतुल्य हो जाएंगे - यह वह मोड है जिसे हमने सेट किया है।
#drbdadm -- --overwrite-data-of-peer primary r0# cat /proc/drbd
version: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r----sns:0 nr:0 dw:0 dr:664 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:810536760फिर दोनों मेजबानों पर
#drbdadm down r0#service drbd startप्राथमिक पर, परिणाम इस तरह दिखेगा:
Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........***************************************************************DRBD's startup script waits for the peer node(s) to appear.- In case this node was already a degraded cluster before thereboot the timeout is 60 seconds. [degr-wfc-timeout]- If the peer was available before the reboot the timeout willexpire after 120 seconds. [wfc-timeout](These values are for resource 'r0'; 0 sec -> wait forever)To abort waiting enter 'yes' [ 18]:.द्वितीयक पर:
Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........***************************************************************DRBD's startup script waits for the peer node(s) to appear.- In case this node was already a degraded cluster before thereboot the timeout is 60 seconds. [degr-wfc-timeout]- If the peer was available before the reboot the timeout willexpire after 120 seconds. [wfc-timeout](These values are for resource 'r0'; 0 sec -> wait forever)To abort waiting enter 'yes' [ 14]:0: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 110: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 110: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 11.इस तथ्य के कारण त्रुटियों में देरी हुई कि हमने एक ही समय में सब कुछ फिर से शुरू किया। सामान्य स्थिति में, प्रक्षेपण सरल दिखता है:
#service drbd startStarting DRBD resources:[ d(r0) s(r0) n(r0) ].# cat /proc/drbdversion: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:SyncSource ro:Primary/Primary ds:UpToDate/Inconsistent C r-----ns:199172 nr:0 dw:0 dr:207920 al:0 bm:11 lo:1 pe:24 ua:65 ap:0 ep:1 wo:b oos:810340664[>....................] sync'ed: 0.1% (791348/791536)Mfinish: 19:29:01 speed: 11,532 (11,532) K/secयहाँ हम देखते हैं कि डिस्क सिंक्रनाइज़ेशन शुरू हो गया है।
हम इस प्रक्रिया की निगरानी करना शुरू करते हैं और टहलने जाते हैं। मेजबानों के बीच डिस्क के आकार और कनेक्शन की गति के आधार पर, हम कुछ घंटों से एक दिन तक चल सकते हैं ...
#watch –n 1 “cat /proc/drbd”और हम पोषित 100% की प्रतीक्षा कर रहे हैं
cs:SyncSource ro:Primary/Primary ds:UpToDate/ UpToDate9. lvm वॉल्यूम ग्रुप बनाना
प्रक्रिया लंबी है, इसलिए हम प्राथमिक मेजबान पर जारी रहेंगे।
#vgcreate drbd-0 /dev/drbd0No physical volume label read from /dev/drbd0Writing physical volume data to disk "/dev/drbd0"Physical volume "/dev/drbd0" successfully createdVolume group "drbd-0" successfully created10. एक समूह को प्रॉक्समॉक्स से जोड़ना
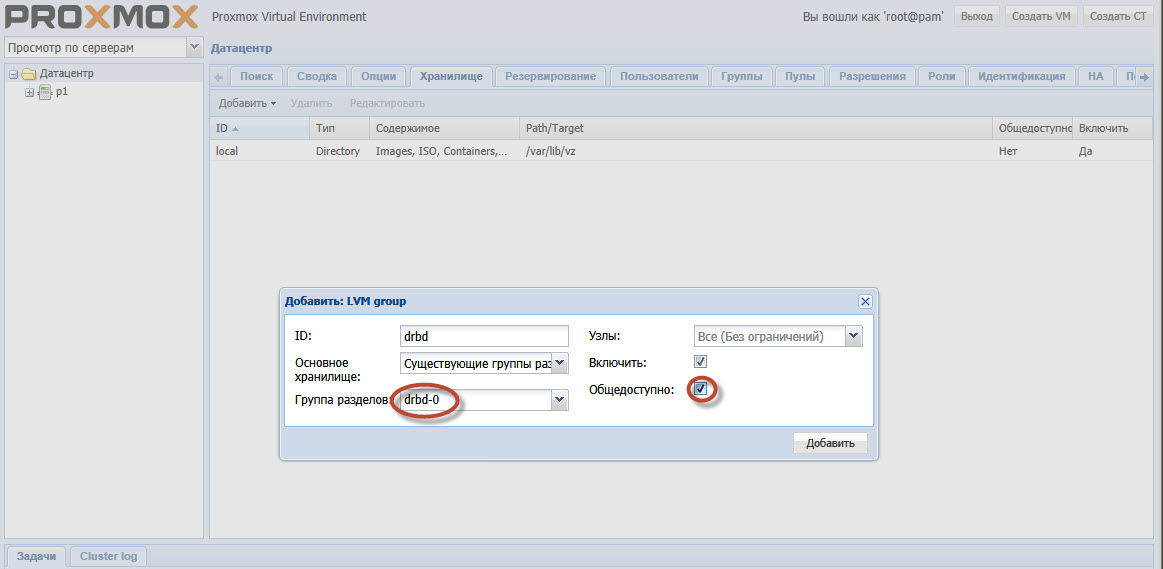
प्रॉक्सॉक्स जीयूआई में डेटा सेंटर-स्टोरेज अनुभाग का चयन करें। जोड़ें। टाइप - LVM, ID मनमाना है - यह सिर्फ एक नाम है। विभाजन समूह drbd-0, + enable, + सार्वजनिक रूप से उपलब्ध।
हाइलाइट किए गए बिंदुओं पर ध्यान दें। drbd-0 चरण 9 में बनाया गया समूह है।
खैर, सार्वजनिक उपलब्धता की स्थापना इसलिए की जाती है ताकि प्रॉक्समोक्स माइग्रेशन प्रक्रिया के दौरान मशीन की होस्ट छवियों को स्वयं कॉपी करने की कोशिश न करे।
11. वह है।
सिंक्रनाइज़ेशन पूरा होने के बाद, आप इमेज-डिस्क स्टोरेज के रूप में drdd चुनकर मशीनें बना सकते हैं, उन्हें होस्ट से होस्ट में स्थानांतरित कर सकते हैं बिना होस्ट मशीन की सेवा के वर्चुअल मशीन से संपर्क खोए। सामान्य तौर पर,
उच्च उपलब्धता क्लस्टर - प्रॉक्समोक्स बनाने के लिए सब कुछ तैयार है