कभी-कभी एक डिजिटल या अल्फ़ान्यूमेरिक अनुक्रम को याद रखना मुश्किल हो सकता है, लेकिन अगर, एक सरल नियम का उपयोग करके, बचपन में सीखी गई कविता की एक पंक्ति को इस संख्या में बदला जा सकता है, तो सब कुछ आसान हो जाएगा। इस लेख में, मोंटे कार्लो विधियाँ कोडिंग संख्याओं के दो अलग-अलग तरीकों का उपयोग करके ऐसे मार्ग का चयन करने के परिणामों की तुलना करती हैं।
मैं आपको एक उदाहरण देता हूं: यदि आप व्यंजन अक्षरों में संख्याओं को अंकित करते हैं, तो प्रत्येक शब्द या वाक्य एक पूर्णांक से मेल खाता है। आमतौर पर, निम्नलिखित एन्कोडिंग विधि को चुना जाता है: 1-पी, 2-डी, 3-टी, 4-एच, 5-पी, 6-एच, 7-एस, 8-सी, 9 वां (क्योंकि 9 "एक बहुत") है। फिर शब्द "मेरे अच्छे दोस्त" 219513 नंबर के अनुरूप हैं। लेकिन यह कुछ हद तक असुविधाजनक है, क्योंकि विशेष तैयारी के बिना अनावश्यक पत्रों को जल्दी से फेंकना संभव नहीं है, हालांकि, "मेरे अच्छे दोस्त" को भूलना काफी मुश्किल है, जो आपको शांत वातावरण में नंबर को याद रखने की अनुमति देगा। 219513. और यह बहुत लुभावना है, क्योंकि संख्या स्वयं बहुत सार है और आसानी से अन्य समान सार संख्याओं के साथ भ्रमित किया जा सकता है।
मानवविज्ञान पर काफी जानकारी है, यहां मैंने पहिया को सुदृढ़ करने की कोशिश नहीं की, लेकिन पाठ चयन की संभावनाओं का उपयोग करने के लिए, जो कि कंप्यूटर सिस्टम की मदद के बिना उपयोग करना मुश्किल है।
बस मामले में, विकिपीडिया से परिभाषा है: Mnemonics (यूनानी, याद रखने की कला), mnemonics - विशेष तकनीकों और विधियों का एक सेट जो आवश्यक जानकारी के memorization की सुविधा प्रदान करता है और संघों (कनेक्शन) का निर्माण करके स्मृति की मात्रा बढ़ाता है। अमूर्त वस्तुओं और तथ्यों को अवधारणाओं और अभ्यावेदन के साथ बदलना जिसमें दृश्य, श्रवण या काइनेस्टेटिक प्रतिनिधित्व होता है, वस्तुओं को स्मृति को सरल बनाने के लिए विभिन्न प्रकार की स्मृति में मौजूदा जानकारी के साथ जोड़ते हैं।
इस मामले में, पाठ के पारित होने के साथ संख्याओं के एक अमूर्त सेट का मिलान उसे छवियों से भर देता है और याद रखना आसान बनाता है। जैसा कि पहले ही उल्लेख किया गया है, विचार इस पाठ को स्वचालित रूप से चुनना है। ये सभी निश्चित रूप से अच्छी तरह से ज्ञात चीजें हैं, मैं उन्हें बिल्कुल भी आविष्कार करने का नाटक नहीं करता हूं, मैं उन लोगों को पाठ्यपुस्तकें पढ़ने की सलाह देता हूं जो स्वयं में रुचि रखते हैं [1]।
पहला अक्षर कोडिंग
प्रारंभिक विचार स्कूल के पाठ्यक्रम के काव्य भाग से एक उद्धरण लेने की कोशिश करने का था जो किसी दिए गए कार नंबर के अनुरूप होगा, अर्थात्, अक्षर-तीन_नुमा पत्र-दो_ अक्षरों के कुछ यादृच्छिक क्रम (एक क्षेत्र कोड के बिना नियमित संख्या)। यह मान लिया गया था कि पहला अक्षर पहले शब्द को जन्म देता है, प्रत्येक तीन अंक एक व्यंजन द्वारा एन्कोड किए जाते हैं, जिनमें से प्रत्येक शब्द को भी जन्म देता है और अंतिम दो अक्षर दो और शब्द हैं। इसके अलावा, रूसी कार नंबर में कोई अक्षर नहीं हो सकते हैं, उनमें से केवल 12 का उपयोग किया जाता है: ए, बी, सी, ई, एन, टी, एम, ओ, के, पी, वाई, एक्स। कई प्रमुख कविताएँ ली गईं: यूजीन वनगिन, पोल्टावा, रुस्लान और ल्यूडमिला, रोमियो और जूलियट + क्रायलोव की दंतकथाएँ। विश्लेषण के दौरान, 1000 यादृच्छिक संख्याएं उत्पन्न होती हैं, जिसके लिए इन कार्यों में से एक उद्धरण चुना जाता है
निम्नलिखित स्क्रिप्ट लिखी गई थी:
यदि आप कोड पर थोड़ी टिप्पणी करते हैं, तो आने वाले सभी शब्दों को कतार में जोड़ा जाता है, जो चयनित अनुक्रम की लंबाई से अधिक नहीं बढ़ता है। अधिकतम मैच की लंबाई को याद किया जाता है। इस प्रकार, कुछ पाठों का उपयोग करके एन्कोड किए जा सकने वाले प्रारंभ से अधिकतम अक्षरों का पता लगाया जाता है।
परिणाम इस प्रकार हैं:
| नाम | औसत | 0 | 1 | 2 | 3 | 4 | 5 | 6 | आयतन |
| क्रायलोव की दंतकथाएँ | 2.434 | 0 | 35 | 530 | 403 | 30 | 2 | 0 | 83kb |
| यूजीन वनगिन | 3.237 | 0 | 0 | 120 | 549 | 306 | 24 | 1 | १.१ एमबी |
| पोल्टावा | 2.507 | 0 | 17 | 510 | 424 | 47 | 2 | 0 | 85kb |
| रोमियो और जूलियट | 2.821 | 0 | 36 | 239 | 598 | 122 | 5 | 0 | 219Kb |
| रुस्लान और ल्यूडमिला | 2,617 | 0 | 68 | 359 | 469 | 97 | 6 | 1 | 138kb |
हम कह सकते हैं कि इन परिणामों ने मुझे खुश नहीं किया, यह पता चला कि 1000 में से केवल दो संख्याओं के लिए यह एक उद्धरण लेने के लिए निकला। आइए इन दो उद्धरणों को देखें: m052rk - "मेरा" वे एक आदी आत्मा ईर्ष्या के साथ हैं; o817vs - "सूजन वाले रुसलान से अचानक के बीच छिप गया।" इन वाक्यांशों में कुछ तर्क निश्चित रूप से मौजूद हैं, लेकिन अपूर्णता और विखंडन उनके संस्मरण को बहुत सरल नहीं बनाता है। फिर भी, परीक्षणों ने हमें यह कहने की अनुमति दी कि यहां तक कि ज्यादातर मामलों में इन ग्रंथों के आधार पर यह तीन अक्षरों के लिए एक अनुक्रम उत्पन्न करता है।
बेशक, मुझे दिलचस्पी हो गई: क्या होता है जब ग्रंथ बड़े होते हैं? शायद बड़ी संख्या में टुकड़े दिखाई देते हैं जिसमें से आप पहले से ही चुन सकते हैं। अगले परीक्षण के लिए, मैंने मोशकोव लाइब्रेरी से चुना: एक पर्यायवाची अनुवाद में दो बाइबिल का वसीयतनामा, सभी प्रमुख बौडेलेयर छंद, सभी दोस्तोवस्की के उपन्यास, "द हॉबिट, या बैक एंड बैक", सभी पुश्किन के उपन्यास छंद में, शेक्सपियर के सभी, सभी टॉल्सटॉय के उपन्यास। निम्नलिखित परिणाम प्राप्त हुए:
| नाम | औसत | 0 | 1 | 2 | 3 | 4 | 5 | 6 | आयतन |
| पुराना नियम | 3.09 | 0 | 0 | 188 | 557 | 235 | 17 | 3 | १.१ एमबी |
| नया वसीयतनामा | 3.126 | 0 | 13 | 180 | 498 | 289 | 17 | 3 | 1.5 एमबी |
| Dostoevsky | 4.053 | 0 | 0 | 10 | 206 | 526 | 237 | 21 | 15 एमबी |
| टोल्किन | 3.12 | 0 | 10 | 148 | 581 | 234 | 27 | 0 | 807Kb |
| पुश्किन | 3.234 | 0 | 0 | 114 | 565 | 295 | 25 | 1 | 1.2 एमबी |
| बौडलेयर | 2.943 | 0 | 4 | 231 | 594 | 160 | 11 | 0 | 461Kb |
| शेक्सपियर | 4.489 | 0 | 0 | 0 | 49 | 474 | 416 | 61 | 64 एमबी |
| गाढ़ा | 3.96 | 0 | 0 | 8 | 236 | 555 | 190 | 11 | 11 एमबी |
उद्धरण अपने आप में काफी हद तक निकले, इसलिए पाठक को बोर करने के लिए नहीं, मैंने उन सभी को नहीं दिया, मैं बस उल्लेख करता हूं कि उनका चरित्र एक जैसा था, कुछ अधूरा और रहस्यमयी: 488 वें में - "यही तो है, वान्या का मानना है कि एक: मास्सुबोव", t380tt - "तीन हज़ारों, वह चिल्लाया, तीन हज़ार, "m081 नहीं -" दासता आपसे मुझे खुशी है। वहाँ है। ” उन सभी को पढ़ने के बाद, कुछ भाग्य-सोच के बारे में सोचा गया जो पुस्तकों के अनुरूप है (जब वे एक यादृच्छिक पृष्ठ खोलते हैं, एक यादृच्छिक रेखा पढ़ते हैं और किसी तरह इसे अपने जीवन के ढांचे के भीतर व्याख्या करने की कोशिश करते हैं) का दौरा किया जाता है। लेकिन मैंने ऐसे लक्ष्य निर्धारित नहीं किए।
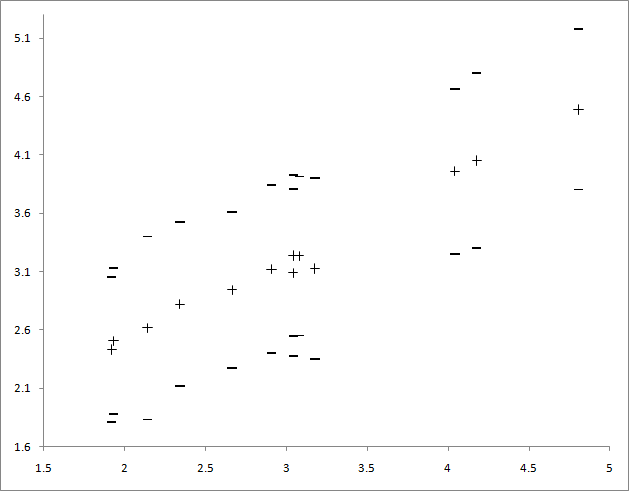
वॉल्यूम बनाम (औसत -, प्लस या माइनस मानक विचलन, और X - उपयोग किए गए पाठ की मात्रा का लघुगणक) के दशमलव लॉगरिदम के औसत का ग्राफ
सिद्धांत रूप में, इस तरह की निर्भरता का अनुमान लगाया जा सकता है, बाइबल के केवल दो खंडों को यहां थोड़ा खटखटाया जाता है, लेकिन अन्यथा औसत मात्रा लघुगणक के अनुपात में बढ़ती है।
लंबाई कोडिंग
पहली बात जो दिमाग में आती है, वह यह है कि बहुत अधिक टेक्स्ट को एन्कोडिंग करने का तरीका प्रश्न से हट जाता है, अर्थात संख्याओं के लिए केवल 10 अक्षर लिए जाते हैं और अक्षरों के 12 के लिए, बाकी के शब्द केवल जंजीरों को तोड़ते हैं। बेशक, आप अन्य कोडिंग विधियों के साथ आ सकते हैं जो सभी अक्षरों का उपयोग करते हैं, या कम से कम केवल व्यंजन। ये विधियां साहित्य में वर्णित हैं, लेकिन मेरा विचार एक आसान उपयोग करने वाला उपकरण बनाना था ताकि उपयोगकर्ता इस बात पर पहेली न लगाए कि वाक्यांश इस संख्या से कैसे मेल खाता है, कौन से अक्षरों को त्यागना है और कौन सा ध्यान में रखना है, अन्यथा यह संभव होगा पहले महत्वपूर्ण पत्र पर कोडिंग लागू करें, यह असंदिग्धता देता है, लेकिन किसी व्यक्ति के लिए सुविधाजनक नहीं है। एक शब्द में अक्षरों की संख्या से संख्याओं को अंकित करने का विचार आया। ऐसे कोडिंग के साथ, शून्य का प्रतिनिधित्व करने की समस्या उत्पन्न होती है, लेकिन अब हम इस पर ध्यान नहीं देंगे। तुलना करने के लिए, मैंने एक ही सेट पर परीक्षणों की एक श्रृंखला आयोजित की और उसी नियमों के अनुसार (कोड लगभग समान है, इस कारण से लिस्टिंग एक पुनरावृत्ति होगी):
| नाम | औसत | 0 | 1 | 2 | 3 | 4 | 5 | 6 | आयतन |
| क्रायलोव की दंतकथाएँ | 2.831 | 0 | 96 | 203 | 490 | 197 | 13 | 1 | 83kb |
| Onegin | 3.497 | 0 | 96 | 85 | 166 | 536 | 113 | 4 | १.१ एमबी |
| पोल्टावा | 2,808 | 0 | 96 | 231 | 459 | 199 | 13 | 2 | 85kb |
| रोमियो और जूलियट | 3.149 | 0 | 96 | 116 | 377 | 371 | 34 | 6 | 219Kb |
| रुस्लान और ल्यूडमिला | 2.94 | 0 | 96 | 178 | 443 | 258 | 23 | 2 | 138kb |
हम कह सकते हैं कि स्थिति बहुत बेहतर है, "1" कॉलम में केवल वही संख्या 96 तुरंत चिंताजनक है, यहां संख्याओं की गणना की जाती है जिसके लिए एक शब्द पहले अक्षर में पाया गया था, लेकिन पहले अंक में नहीं। ये स्वाभाविक रूप से शून्य पर शुरू होने वाली संख्याएँ हैं, इनमें से लगभग 100 संख्याएँ अभी भी कॉलम 2 और 3 में हैं, जैसा कि आप देख सकते हैं, 85 से अधिक नहीं हैं। परिणामी उद्धरण का एक उदाहरण: v325nm - "आपके लिए: मुझे खुशी होगी ... मैं सही नहीं हूँ।" कविताओं के मामले में असंगतता की भरपाई लाइन की शुरुआत से उद्धृत करके की जा सकती है, उपयोगकर्ता को इसके अलावा याद रखना होगा कि कविता में नंबर कहाँ से शुरू होता है, उदाहरण के लिए, उद्धृत उद्धरण को इस तरह प्रदर्शित किया जाना चाहिए: "आपको शपथ: मुझे खुशी होगी ... मैं सही नहीं हूँ।" पिछली पंक्ति: "आह, अनुग्रहपूर्ण शूरवीर, मैं तुम्हारी कसम खाता हूं: मुझे खुशी होगी ... मैं सही नहीं हो सकता।" लेकिन पहले से ही वाक्यांश की शुरुआत स्पष्ट होना बंद हो जाती है। यदि आपको वाक्यांश की शुरुआत याद है, तो आप शून्य की स्थिति को अलग से भी याद रख सकते हैं। शायद किसी को इस तरह के विचार का मज़ाक लगेगा, लेकिन मैं इसे कम से कम लागू मानता हूं।
इस विचार का अनुप्रयोग निम्नलिखित परिणाम देता है:
| नाम | औसत | 0 | 1 | 2 | 3 | 4 | 5 | 6 | आयतन |
| क्रायलोव की दंतकथाएँ | 3.444 | 0 | 0 | 114 | 426 | 367 | 88 | 5 | 83kb |
| Onegin | 4.26 | 0 | 0 | 2 | 93 | 596 | 261 | 48 | १.१ एमबी |
| पोल्टावा | 3.413 | 0 | 0 | 132 | 414 | 367 | 83 | 4 | 85kb |
| रोमियो और जूलियट | 3.791 | 0 | 0 | 39 | 298 | 508 | 143 | 12 | 219Kb |
| रुस्लान और ल्यूडमिला | 3.611 | 0 | 0 | 83 | 356 | 445 | 99 | 17 | 138kb |
| पुराना नियम | 4.189 | 0 | 0 | 5 | 126 | 585 | 243 | 41 | १.१ एमबी |
| नया वसीयतनामा | 4.292 | 0 | 0 | 3 | 83 | 581 | 285 | 48 | 1.5 एमबी |
| Dostoevsky | 5.019 | 0 | 0 | 0 | 0 | 208 | 565 | 227 | 15 एमबी |
| टॉल्किन (द हॉबिट) | 4.123 | 0 | 0 | 2 | 155 | 587 | 230 | 26 | 807Kb |
| पुश्किन | 4.251 | 0 | 0 | 3 | 94 | 593 | 269 | 41 | 1.2 एमबी |
| बौडलेयर | 3.946 | 0 | 0 | 18 | 214 | 591 | 158 | 19 | 461Kb |
इन आंकड़ों के अनुसार, यह माना जा सकता है कि 22% की संभावना वाले यादृच्छिक संख्या के लिए, आप दोस्तोवस्की से उपयुक्त उद्धरण चुन सकते हैं, बुरा नहीं है। उद्धरण, निश्चित रूप से, बहुत महत्वपूर्ण हो जाते हैं, जैसा कि पिछले मामले में है: 725 - "हमारे हंसमुख काम को सहजता से देखता है", m582to - "मेरे शब्द उसे छूने के लिए लग रहे थे,", m385ns - "इस बीच, कुछ चमत्कार से एक असामान्य समानता है", 514nt - "भीड़ के लिए खूनी लड़ाई और दिन आ गया है।"
लेकिन क्या होगा अगर आप कार नंबर के लिए नहीं, बल्कि टेलीफोन नंबर के लिए उत्पन्न करते हैं? जल्द से जल्द नहीं कहा:
| नाम | औसत | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| क्रायलोव की दंतकथाएँ | 4.145 | 0 | 23 | 270 | 387 | 214 | 71 | 35 |
| Onegin | 5.248 | 0 | 0 | 9 | 260 | 347 | 242 | 142 |
| पोल्टावा | 4.131 | 0 | 16 | 293 | 385 | 193 | 76 | 37 |
| रोमियो और जूलियट | 4.608 | 0 | 0 | 138 | 374 | 286 | 146 | 56 |
| रुस्लान और ल्यूडमिला | 4.349 | 0 | 11 | 212 | 381 | 256 | 93 | 47 |
इन परिणामों से पता चलता है कि लगभग 40% की संभावना के साथ छह-अंकीय यादृच्छिक संख्या के लिए "यूजीन वनगिन" से एक समान उद्धरण है, और ये कविताएं हैं जो याद रखने के लिए बहुत अधिक सुखद हैं (सभी के लिए सबसे अधिक संभावना नहीं है, लेकिन बहुमत के लिए, फिर भी, मुझे आशा है कि )।
अन्य तरीके
पर्दे के पीछे क्या अन्य संभावनाएं बनी रहीं: ग्रंथों की पीढ़ी, अर्थात् एक निश्चित संरचना के संबंधित शब्दों या वाक्यों की पीढ़ी (अक्षरों की आवश्यक संख्या या यहां तक कि कैसे) के साथ, सिद्धांत रूप में, यह लंबे समय तक कंप्यूटर के बिना किया गया है। साहित्य में दर्शाई गई पाठ्यपुस्तक प्रत्येक संख्या के लिए 0 से 1000 तक का शब्द प्रदान करती है, जो पहले से ही लेखक द्वारा चुना गया है, लेकिन, दुर्भाग्य से, यह विधि बड़ी संख्या को याद रखना संभव नहीं बनाती है, क्योंकि छवियों को जोड़ा नहीं जा सकता है, यह, लेखक के अनुसार, उनके क्षरण की ओर जाता है। यह समझ में आता है, सब कुछ ओवरलैप करना शुरू हो जाता है, और इसी तरह। यहां एक आसान तरीका है, उदाहरण के लिए: आप सामान्य संघों के साथ संख्याओं को सांकेतिक शब्दों में बदलना कर सकते हैं - 3 (03 से) - एक डॉक्टर, 7 - एक कुल्हाड़ी (फॉर्म के कारण) और उदाहरण के लिए 5 - शुक्रवार। इस मामले में, प्रत्येक अंक (प्रत्येक स्थिति के लिए) के लिए तीन आंकड़ों का चयन करते हुए, सभी तीन अंकों की संख्याओं को "375 - शुक्रवार को डॉक्टरों को काट दिया गया था" जैसी बहुत ही ज्वलंत कहानियों के साथ एन्कोड किया जा सकता है, लेकिन केवल बहुत कम संख्या में याद किया जा सकता है, क्योंकि सब कुछ रास्ते में मिलना शुरू होता है, आपको इसकी आवश्यकता है जब डॉक्टर को इस बार हैक किया गया था, तो यह याद रखने के लिए अतिरिक्त समानताएं बनाएं।
निष्कर्ष
शब्द लंबाई पीढ़ी एल्गोरिथ्म एक एप्लिकेशन में लागू किया गया है जो मोबाइल उपकरणों पर कार संख्या को पहचानता है और केवल मनोरंजन के लिए एक गैर-लाभकारी विकास है। इसके अलावा, इस तरह के चयन को YaZapomnil [2] साइट पर किया जाता है।
यह मुझे काफी दिलचस्प लगा कि इस तरह के अजीब मेट्रिक्स के बारे में विभिन्न प्रकार के अक्षरों की संख्या या शब्दों के पहले अक्षरों के अनुक्रम के क्रम में पाठ की मात्रा में वृद्धि के साथ बढ़ता है। इसके अलावा, परिणाम लाइन पर बहुत अच्छे हैं। जैसे-जैसे पाठ बढ़ता है, टुकड़ों के बीच चयन की संभावना बढ़ जाती है, इससे उनकी गुणवत्ता में सुधार हो सकता है।
फिलहाल, मैं एक ऐसे स्रोत के बारे में सोच रहा हूं जिसमें बड़ी संख्या में सुंदर ग्रंथ होंगे, साथ ही तुलना का एक तरीका जो किसी व्यक्ति के लिए स्पष्ट होगा और जो मुझे बड़ी संख्या में उद्धरणों का चयन करने की अनुमति देगा।
मुझे खुशी होगी अगर विचार दिलचस्प लगे।
संदर्भ
- Kozarenko वी। ए। पाठ्यपुस्तक के Mnemonics, 2002, इलेक्ट्रॉनिक प्रकाशन
- संख्याओं का चयन yazapomnil.ru/n/ द्वारा करें