
आकृति विज्ञान पर लेखों की श्रृंखला की सामग्री पिछले लेख में, हम लेमेटेटेशन समस्या को हल करने के करीब आए और यह पता लगाया कि क्या हम इसे चाहते हैं या नहीं, लेकिन हमें वर्णित भाषा के सभी शब्दों को एक या दूसरे रूप में संग्रहीत करना होगा।
रूसी भाषा के लिए, यह कई लाख शब्द हैं। शायद यह किफायती नहीं है, लेकिन यह हमें बहुत अधिक बोनस देता है।
पहले, हम जांच सकते हैं
कि शब्द शब्दकोश में है या नहीं । नियमित अभिव्यक्तियों के आधार पर नियमों की मदद से, हमें पता नहीं चलता है कि क्या रूसी में "स्वयं को धोएं" एक शब्द है। अंत पूरी तरह से रूसी भाषा के नियमों के अधीन है, सिलेबल्स की पुनरावृत्ति भी एक असाधारण मामला नहीं है। यह शब्द नियमित अभिव्यक्ति को याद करेगा, लेकिन वास्तव में रूसी भाषा में "वॉश" नहीं है।
एक अन्य कार्य जो आकृति विज्ञान में संग्रहीत एक शब्द है
त्रुटि सुधार । जैसे ही हमें शब्दकोश में एक शब्द नहीं मिलता है, लेकिन हम
लेवेन्स्चिन से मांगी गई थोड़ी
दूरी पर एक और शब्द
ढूंढते हैं , हम सुधार पर निर्णय लेते हैं।
इन समस्याओं को हल करने के लिए, हमें न केवल सभी शब्दों, बल्कि उनके सभी रूपों को संग्रहीत करने की आवश्यकता है। एक दूसरे के समान शब्दों के समूह के लिए रूपों के गठन के सभी नियमों
को विभक्ति प्रतिमान कहा जाता
है । क्रिया "बुडलान्ट" लें: बुडानुल, बुडेलनेट, बुडेलनेट, बुडानुल, बुडानूला, बुडलान। आप बहुत सारी क्रियाएं पा सकते हैं जो समान नियमों के अनुसार बदल जाएंगी; दूसरी ओर, बड़ी संख्या में क्रियाएं अन्य नियमों के अनुसार बदल जाएंगी। इसलिए, ये क्रियाएं विभिन्न प्रतिमानों से संबंधित हैं।
वाक्यविन्यास के प्रश्नों का उत्तर देने के लिए, हम इसके
व्याकरणिक अर्थ को प्रत्येक रूप में संग्रहीत करते हैं।
शब्दकोश संग्रहण
इस प्रकार, सिस्टम में संग्रहीत शब्दकोश बहुत सारी समस्याओं को हल करता है, जो आनन्दित नहीं कर सकता है। लेकिन इस डिक्शनरी को कैसे रखा जाए? रूसी भाषा में कई सौ हजार शब्द हैं। औसतन, प्रति शब्द 15 रूप हैं। हमें यह नंबर कहां से मिलेगा? मामलों पर विचार करें: उनमें से 6 एकवचन के लिए और 6 बहुवचन के लिए हैं - पहले से ही 12. और यह उल्लेख नहीं है कि रूसी भाषा में 6 मामले नहीं हैं, जैसा कि वे स्कूल में पढ़ाते हैं, लेकिन 8।
सबसे पहले, पूर्वानुपात मामले में एक केस जिसे एक स्थानिक कहा जाता है। यदि हम "वन" शब्द को प्रस्तावक मामले में रखते हैं, तो हमें दो विकल्प मिलते हैं: "जंगल के बारे में" और "जंगल में"। जंगल में, यह एक स्थानीय मामला है, न कि एक पूर्वसर्ग। कई संज्ञाओं के लिए, इन मामलों के रूप मेल खाते हैं, क्योंकि हम "टेबल पर", "टेबल के बारे में", और "टेबल पर" के बीच अंतर नहीं करते हैं। इसका कारण यह है कि "तालिका में" कोई स्थान नहीं है, लेकिन "जंगल में" एक स्थान है।
आठवें मामले को आंशिक कहा जाता है। यह मामला पूरे हिस्से को दर्शाता है। यदि हम चाय से बाहर निकल गए हैं, तो आलस्य के लिए उठो, और कोई व्यक्ति पास में चलता है, हम उससे कहते हैं: "मुझे चाय डालो, कृपया।" एक नियम के रूप में, आंशिक रूप में शब्दों का रूप जनन या दोषपूर्ण मामले के साथ मेल खाता है। विकिपीडिया हमें एक ऐसे शब्द का एक बेहतरीन उदाहरण देता है जिसमें बहुवचन के अलावा और कोई रूप नहीं है - "गाल" ("गाल नहीं चाहिए?"; "मुझे एक गाल डालो!"

कुल, 8 मामलों को 2 रूपों (एकवचन और बहुवचन) से गुणा किया जाता है - पहले से ही 16। क्रियाओं का समय, संख्या और लिंग होता है। सरल अंकगणितीय गणनाओं का उपयोग करते हुए, हम पाते हैं कि 15 रूप एक मामूली कम अनुमान हैं।
रूसी शब्द में वर्णों की औसत अनुभवजन्य संख्या 9. हम प्राप्त परिणामों को गुणा करते हैं, यह ध्यान रखना नहीं भूलते हैं कि 1 बाइट 2 बाइट्स है, और यह पता चलता है कि रूसी भाषा के सभी रूपों के शब्दकोश के लिए, 50 मेगाबाइट की आवश्यकता है। व्यवहार में, हमारे आदर्श 50 मेगाबाइट में डेढ़ गुना वृद्धि होती है: नतीजतन, रूसी शब्दों के सभी रूपों के साथ एक पाठ फ़ाइल 75 मेगाबाइट से अधिक होती है।
इसके अलावा, यहां तक कि अगर हम इन सभी शब्दों को एक फ़ाइल में लिखते हैं, तो हमें इसे खोजना होगा (अन्यथा हमें इसकी आवश्यकता क्यों है?)। यही है, हमें शब्दों को वर्णानुक्रम में व्यवस्थित करना चाहिए और प्रत्येक शब्द के अलावा शब्द के प्रारंभिक रूप में एक सूचक जोड़ना चाहिए। संकेत, हालांकि एक समय में भारी नहीं है, हमारे शब्दकोश में वजन जोड़ देगा। इस मामले में, खोज की गति होगी

और यह केवल रूसी में है, और अंग्रेजी, फ्रेंच, स्पेनिश, इतालवी और कई अन्य सुंदर और समृद्ध भाषाएँ भी हैं। यदि हम चाहते हैं, उदाहरण के लिए, कई भाषाओं को पहचानने और उनका समर्थन करने के लिए फाइनरडर, हमें केवल गीगाबाइट में रूपात्मक शब्दकोशों को फिट करने की आवश्यकता है। मान्यता और अन्य डीएल के लिए मानकों के बारे में क्या कहना है? ऐसी भारी तकनीक वाला उपयोगकर्ता हमें समझ नहीं पाएगा - और वह सही होगा। हमें अधिक विनम्र होना चाहिए और बेहतर रखना चाहिए।
उपसर्ग वृक्ष
उपसर्ग वृक्ष हमारी सहायता के लिए आता है। इसकी व्यवस्था कैसे की जाती है? यह सब ऊपर से शुरू होता है - एक खाली चरित्र जिसमें वर्णमाला संग्रहीत होती है। पहले अक्षर के लिए, पूरे वर्णमाला को वहां संग्रहीत किया जाता है, अधिक सटीक रूप से, 33 बिंदुओं की एक सरणी। प्रत्येक सूचक अपने प्रतीक से मेल खाता है। पहला पॉइंटर - कैरेक्टर A के लिए, दूसरा - कैरेक्टर B के लिए, कुछ K-th पॉइंटर - कैरेक्टर K और कुछ P-th के लिए - P के अनुसार। पॉइंटर्स के अनुसार, हम इस ट्री के निम्नलिखित नोड्स प्राप्त कर सकते हैं, जो रूसी वर्णमाला के अक्षरों के अनुरूप हैं।
निम्नलिखित नोड फिर से सरणियों को संग्रहीत करते हैं। इसके अलावा, खोज की गति के लिए, हम इस तथ्य की उपेक्षा करते हैं कि जिन अक्षरों को हमें संकेत की आवश्यकता है, वे पहले से ही 33 से कम होंगे (यह संभावना नहीं है कि हमें "एई" के संयोजन की आवश्यकता है, उदाहरण के लिए)। हम अनुपलब्ध अक्षर के आयाम को छोड़ देते हैं ताकि गायब वर्णों के लिए अशक्त बिंदु सम्मिलित हो सकें।
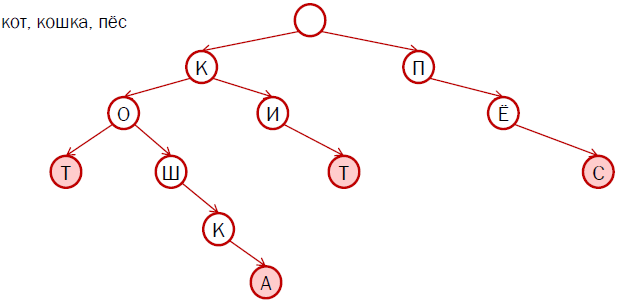
यह आंकड़ा चार शब्दों के लिए एक उपसर्ग वृक्ष का उदाहरण दिखाता है: "बिल्ली", "बिल्ली", "व्हेल" और "कुत्ता"। गुलाबी ने अंतिम चोटियाँ हिलाईं।
इस दृष्टिकोण का लाभ यह है कि हम एक ही शब्द के लिए वर्णों की विशाल श्रृंखलाओं को संग्रहीत नहीं करते हैं, विभिन्न रूपों में खड़े होते हैं। इस प्रकार, हम फ़ाइल का आकार शब्दकोश के साथ कम कर देते हैं। उदाहरण के लिए, रूसी भाषा के लिए, यह पेड़ अतिरिक्त डेटा के साथ लगभग 2 मेगाबाइट लेता है। सबसे पहले, 75 मेगाबाइट की तुलना में, यह निश्चित रूप से एक सफलता है। दूसरे, ऐसे पेड़ पर खोज की गति एक सॉर्ट की गई फ़ाइल की तुलना में बहुत अधिक है। अब यह पूरे शब्दकोश के आकार पर निर्भर नहीं करता है, बल्कि केवल उसी चीज़ पर निर्भर करता है जो हम खोज रहे हैं। यदि हम "ए" की तलाश कर रहे हैं, तो हम इसे एक चरण में पाएंगे, और यदि हम एक लंबे शब्द की तलाश कर रहे हैं, उदाहरण के लिए, "हेलिकॉप्टर", तो इसे खोजने में थोड़ा अधिक समय लगेगा।
बेशक, अगर हम सभी शब्दों के सभी रूपों को व्याकरणिक अर्थों के बिना पेड़ में डालते हैं, तो हम किसी भी कंप्यूटर भाषाविज्ञान के बारे में बात करने में सक्षम नहीं होंगे: हम वाक्यविन्यास के स्तर तक नहीं बढ़ पाएंगे, शब्दार्थ का उल्लेख नहीं कर पाएंगे, और स्वचालित अनुवाद उनके बिना असंभव है। इसलिए, हमें अभी भी डेटा संरचना पर काम करने की आवश्यकता है।
शब्दकोश में क्या संग्रहित करें
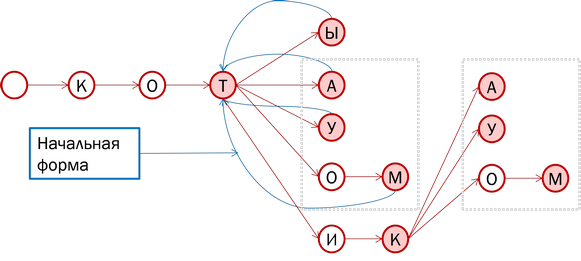
सैद्धांतिक रूप से, हम वास्तव में एक पेड़ में सभी प्रकार के शब्दों को संग्रहीत कर सकते हैं, जबकि प्रारंभिक रूप (आकृति में नीली रेखाएं) को इंगित करते हुए। हालाँकि, ध्यान दें: इस तथ्य के बावजूद कि "बिल्ली" और "बिल्ली" अलग-अलग शब्द-गठन प्रतिमानों को संदर्भित करते हैं, कुछ विभक्तियों (जैसा कि हम अंत कहते हैं) संयोग। क्या होगा अगर शब्दों की इन पूंछों को अलग-अलग संग्रहीत किया जाता है और बिल्लियों के प्रारंभिक रूपों, फर सील और व्हेल को पेड़ में छोड़ दिया जाता है? इसलिए यह अधिक प्रभावी होगा।
पूरी तरह से दृष्टिकोण
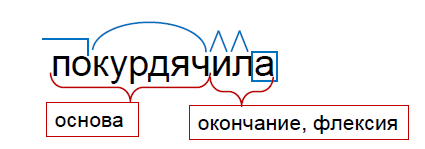
स्कूल में, एक शब्द को इसके घटक भागों में विभाजित किया जाता है: उपसर्ग, जड़, कई प्रत्यय और अंत। हम दूसरे रास्ते से जाएंगे। पहले, हम उपसर्ग को जड़ से अलग नहीं करेंगे। यह इस तथ्य के कारण है कि अक्सर जड़ के साथ उपसर्ग एक पूरी तरह से नया अर्थ बनाते हैं। उदाहरण के लिए शब्द "उपसर्ग" और "दर" लें। "Pri-" शब्द "रेट" के लिए सिर्फ एक उपसर्ग है, लेकिन "उपसर्ग" और "दर" पूरी तरह से अलग चीजें हैं।
इसके अलावा, उपसर्ग किसी भी व्याकरणिक श्रेणी को व्यक्त नहीं करता है। जब हम उपसर्ग "पुनः" ("रीडो" या "स्मोक") जोड़ते हैं, तो हम शब्द के शाब्दिक अर्थ को बदल देते हैं, व्याकरणिक को नहीं। इसलिए, हम उपसर्ग और मूल को एक पूरे के रूप में मानते हैं और इसे शब्द का आधार कहते हैं।
स्कूल से एक और अंतर: हम लगभग कभी भी प्रत्ययों को अलग नहीं करते हैं, क्योंकि ज्यादातर मामलों में वे एक व्याकरणिक श्रेणी व्यक्त करते हैं। हमारे उदाहरण में, "-l-" और "-a-" पिछले काल को व्यक्त करते हैं, स्त्री लिंग, और हम उन्हें विभक्ति में जोड़ते हैं। इस विभाजन के साथ, हमें शब्द का एक परिवर्तनशील हिस्सा मिलता है - विभक्ति और अपरिवर्तनीय - आधार।
सुविधाजनक अनुमान

आप शायद पहले से ही इस तथ्य का उपयोग कर चुके हैं कि कंप्यूटर भाषाविज्ञान में कुछ भी नहीं होता है। यहाँ यह है: शब्द के विभिन्न रूपों में भी जड़ का हिस्सा बदल सकता है। बेशक, हम यह तर्क दे सकते हैं कि यह "मित्र-जी" और "मित्र-मित्र" की जड़ में केवल एक परस्पर सामंजस्य है, लेकिन व्यावहारिक समस्याओं को हल करने के लिए हमारे लिए यह स्वीकार करना अधिक सुविधाजनक है कि इन शब्दों का "मित्र-मित्र," और समान आधार है विभक्ति अलग हैं।
इसलिए, हमने निर्धारित किया है कि टोकन (शब्द उपजी) और विभक्तियों को अलग-अलग संग्रहीत किया जाएगा। अंत में, हम करीब आते हैं कि कैसे नींबू पानी एबीबीवाई में हमारे आकारिकीय मॉड्यूल को हल करता है।
अंतिम नींबू पानी
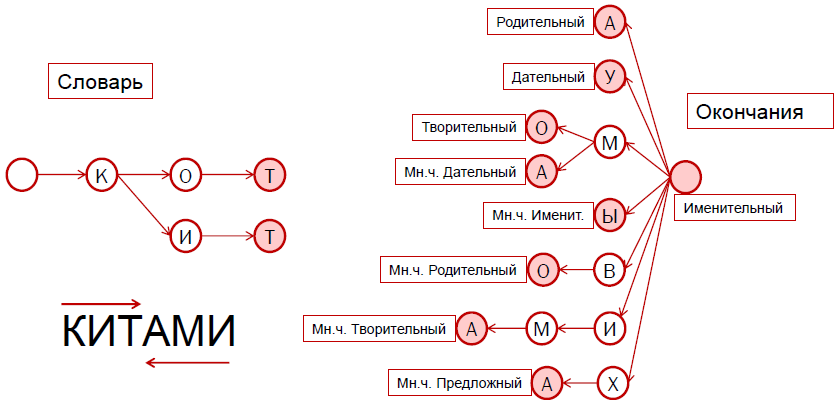
बाईं ओर की आकृति में, पहले से परिचित एक उपसर्ग वृक्ष के रूप में, रूसी भाषा के शब्दकोष का एक लाखवां हिस्सा चित्रित किया गया है। दाईं ओर एंडिंग्स का एक शब्दकोश है, जो उसी तरह संग्रहीत है।
यदि आप एंडिंग्स को करीब से देखते हैं, तो आप देखेंगे कि उन्हें "बिल्ली" और "व्हेल" दोनों के लिए जिम्मेदार ठहराया जा सकता है। यदि हम "a," जोड़ते हैं, तो हमें जनन मिलता है, यदि "y," गोताखोर इत्यादि। ये सभी दो शब्दों के अलग-अलग रूप हैं जो एक ही प्रतिमान से संबंधित हैं, और इसलिए समान रूप से बदलते हैं।
पार्सिंग व्हेल
जब हमें एक शब्द का रूप मिलता है, तो हम इसका विश्लेषण शुरू से नहीं, बल्कि अंत से करते हैं। सबसे पहले, हम मानते हैं कि एक शून्य अंत है, जो गुलाबी में चिह्नित है और इंगित करता है कि हमारे पास नाममात्र का मामला है, एक विलक्षण है। तब हम हमें दिए गए शब्द "व्हेल" का अनुसरण करते हैं और पत्र "और" मिलते हैं। हम उपसर्ग वृक्ष में "और" अक्षर पाते हैं। अगला पत्र "एम" है। ये पत्र अंतिम नहीं हैं, इसलिए हम पेड़ की गहराई में जाना जारी रखते हैं। अगला अक्षर "a", जो गुलाबी रंग में चिह्नित है, पेड़ में अंत नोड है। तो, "-ami" बाएं से दाएं, या "-मा" बाएं से दाएं - यह उन अंतिम विकल्पों में से एक है जिनके साथ शब्द समाप्त हो सकता है।
इसलिए, हमें दो अंत मिले: खाली और "-ami"। अब हमें शब्दकोश के उपसर्ग वृक्ष में आधार खोजने की आवश्यकता है। यह खोज बाएँ से दाएँ की जाती है। हम क्रमिक रूप से अक्षर "के", "और" और "टी" को खोजते हैं, और अक्षर "टी" पर पेड़ समाप्त होता है। यही है, "व्हेल" इस पेड़ में संग्रहीत शब्दों में से एक है। यदि हम और खोज करने का प्रयास करते हैं, तो हम देखेंगे कि अगला अक्षर "a" है, लेकिन अगले शीर्ष पर कोई संकेत नहीं हैं, जिसका अर्थ है कि हम खोज को रोकते हैं।
हम देखते हैं कि बाईं ओर तीन अक्षर और दाईं ओर तीन अक्षर एक शब्द में विलीन हो गए हैं, लेकिन खाली अंत हमारे लिए उपयोगी नहीं था। हम यह निर्णय लेते हैं कि "व्हेल" बहुवचन रूप, वाद्य मामला, प्रारंभिक रूप "व्हेल" के साथ टोकन हैं।
उन समस्याओं के बारे में पढ़ें जो अभी तक अगली पोस्ट में आकृति विज्ञान के उपतंत्र द्वारा कवर नहीं की गई हैं।