हाय हमर! प्रोग्रामर का दिन करीब आ रहा है, और मैं अपने असामान्य घटनाक्रमों को साझा करने की जल्दबाजी करता हूं।
जापानी क्रॉसवर्ड पहेली एक एनपी-पूर्ण कार्य है, जैसे सेल्समैन का काम, बैकपैक पैकिंग, आदि जब कोई व्यक्ति इसे हल करता है, तो उत्तराधिकार में गारंटीकृत भरा और खाली कोशिकाओं को निर्धारित करना आवश्यक है। पूरे पैटर्न के पूरा होने तक एक-एक करके कॉलम और पंक्तियों को पार करें। किसी भाषा में ऐसी समस्या का समाधान कैसे संभव है जो आधिकारिक तौर पर एक प्रोग्रामिंग भाषा भी नहीं है, इसमें लूप और चर शामिल नहीं हैं? SQL एक क्वेरी भाषा है, इसका मुख्य कार्य पंक्तियों का चयन करना है। इसलिए हम सभी संभावित क्रमपरिवर्तन उत्पन्न करेंगे और मूर्तिकार की तरह, सभी अनावश्यक को काट देंगे।
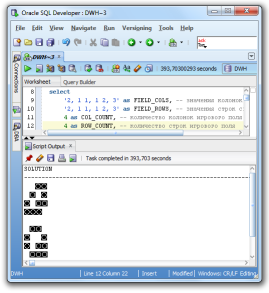
क्वेरी खेलने के लिए, आपको Oracle डेटाबेस 11g या उच्चतर (रास्ते में 12 वें) की आवश्यकता होगी। पहले संस्करण वर्गाट विश्लेषणात्मक फ़ंक्शन के उपयोग के कारण काम नहीं करेंगे। एक्सप्रेस संस्करण (XE) का उपयोग करना संभव है, लेकिन इस बिट का उपयोग 1GB मेमोरी तक किया जाता है, इसलिए फ़ील्ड का अधिकतम आकार जो फावड़ा कर सकता है, वह 5x4 है। पहले से ही 5x5 फ़ील्ड पर, मेमोरी सीमा समाप्त हो जाती है।
क्वेरी किसी भी वास्तविक डेटाबेस तालिकाओं का उपयोग नहीं करती है; आपको इसके लिए कुछ भी तैयार करने की आवश्यकता नहीं है। इनपुट डेटा को उपसमुच्चय में पास किया जाता है। आप प्रस्तावित क्रॉसवर्ड पहेली का उपयोग कर सकते हैं या अपनी रचना कर सकते हैं। ऐसा करने के लिए, कार्य का वर्णन करें - क्रॉसवर्ड पहेली के ऊपर और बाईं ओर संख्याओं की एक सूची, क्षेत्र के आकार को इंगित करें। आप अपनी पसंद के लिए भरे हुए और खाली सेल के लिए प्रतीकों को भी निर्दिष्ट कर सकते हैं।
काम करने की प्रक्रिया में लाइनों को बहुत, अवास्तविक बहुत से गुजरना होगा! क्षेत्र में कोशिकाएँ, पंक्तियों की कुल संख्या * कॉलमों की संख्या होती है। प्रत्येक सेल भरा जा सकता है (1) या खाली (0)। फिर सभी संभावित क्रमपरिवर्तन की संख्या सूत्र 2 ^ (कोशिकाओं की संख्या) के अनुसार गैर-स्पष्ट रूप से बढ़ती है। और चूंकि क्षेत्र का आकार पहले से तय नहीं है, इसलिए प्रत्येक सेल को एक अलग लाइन के रूप में दर्शाया गया है। परिणामस्वरूप, क्रमपरिवर्तन की संख्या को कोशिकाओं की संख्या से गुणा किया जाना चाहिए। उदाहरण के लिए, यहां कुछ वर्ग क्षेत्र दिए गए हैं:
3x3 = 4,608
4x4 = 1,048,576
5x5 = 838,860,800
6x6 = 412,316,860,416
8x8 = 1,180,591,620,717,411,303,424
संपूर्ण खोज का सकारात्मक पक्ष - सभी समाधान हैं। तो, यदि आपके पास निष्क्रिय कंप्यूटिंग शक्ति है, तो अब आप जानते हैं कि इसके साथ क्या करना है! मैं आपको एल्गोरिथ्म के बारे में नहीं बताता - आपको अंत से पढ़ने की जरूरत है, प्रत्येक उपश्रेणी पर टिप्पणी की गई है।