हाल ही में, अधिक से अधिक लोग "NoSQL" के बारे में बात कर रहे हैं - एक सीधे "फैशनेबल" प्रवृत्ति का गठन हुआ है। सहित प्रसिद्ध कंपनियों, प्रसिद्ध डेटा की काफी मात्रा के साथ उच्च लोड परियोजनाओं में - और कोई प्रशंसा करता है, और कोई खुद को गैसोलीन के साथ डुबो देता है और 35 वीं मंजिल से एक मशाल रोता है: "
एसक्यूएल एसीआईडी हमेशा के लिए!"

और कोई फर्क नहीं पड़ता कि वे किस उत्पाद के बारे में बात कर रहे हैं, चाहे वह
मोंगोडीबी या
कैसंड्रा हो , एक व्यक्ति अक्सर धार्मिक उत्साह और विस्मय को देखता है, जैसे कि यह कुछ नया और पवित्र था।
और नेटवर्क में झिलमिलाहट वाले आर्किटेक्चर के मस्तिष्क-फाड़ने वाले स्केच एक विशेष रोमांच का कारण बनते हैं, जैसे कि कई महाद्वीपों पर "मास्टर-प्रतिकृति मास्टर" में काम करने वाले डेटा केंद्रों का एक चक्र:
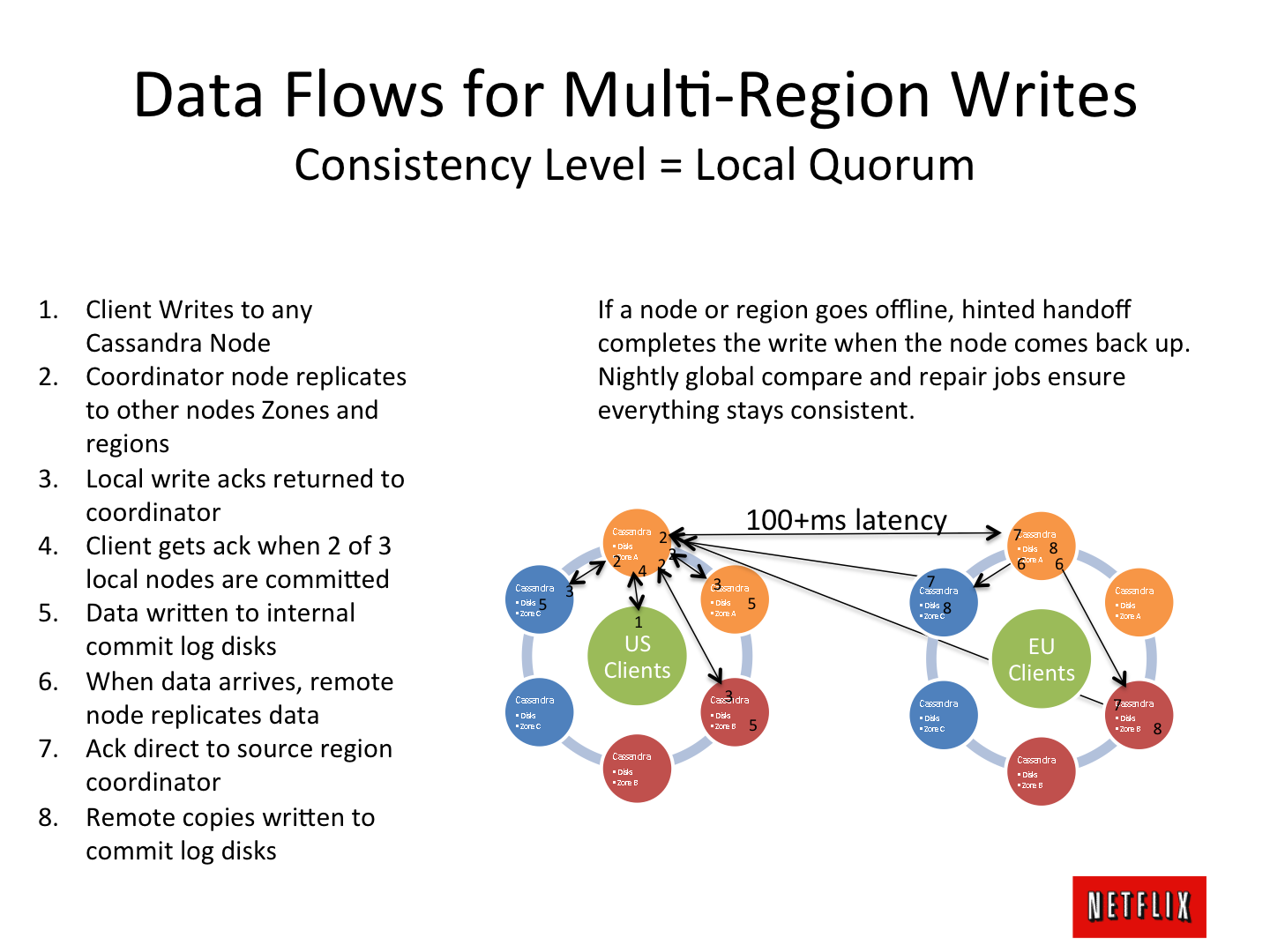
लेकिन ... जब आप मुकाबला परियोजनाओं में "नई" तकनीक का गंभीरता से उपयोग करना शुरू करते हैं, तो आप समझते हैं
कि यह सब कहां से आया है , इस या उस वास्तु निर्णय का क्या कारण है: डेटा सेंटर और अन्य रहस्यवाद के छल्ले - एक व्यावहारिक और सरल, "मर्करी" समझ का निर्माण होता है - जिसे मैं साझा करना चाहता हूं सहकर्मियों, ताकि वास्तु संबंधी गलतियां न हों और समुद्र के उस पार न जाएं। इस बारे में, सिद्धांत रूप में, एक लेख।

क्या अच्छा पुराने ACID के अनुरूप नहीं है?
खैर, सब कुछ प्रदान करने के लिए लगता है - परमाणुता, स्थिरता, लेन-देन अलगाव और प्रतिबद्ध विश्वसनीयता। कोशिश करो, निर्माण करो, शोषण करो। आईएसओ एसक्यूएल ने
लेन-देन अलगाव के स्तर को निर्धारित किया
है - ठीक है, पूरी खुशी के लिए और क्या पर्याप्त नहीं था, जब सब कुछ निर्धारित किया जा सकता है?
"कैप हेरेसी" शैली में किस कारण से, केवल तीन में से 2 का चयन करें? :-)
- डेटा संगति
- उपलब्धता
- जुदाई प्रतिरोध

उत्तर स्पष्ट है - व्यवसाय को नई, "सुपरसोनिक" डेटा वेयरहाउस क्षमताओं की आवश्यकता है:
- आधार हमेशा लिखने और पढ़ने के लिए उपलब्ध होना चाहिए, और सर्वर रिबूट जैसे मामलों में, नेटवर्क गिर गया है - यह बहुत मुश्किल है
- डेटा वॉल्यूम की गहन वृद्धि और उनकी उपलब्धता के लिए सख्त आवश्यकताएं, जिनमें शामिल हैं दुनिया भर में नेटवर्क के तेजी से विकास के कारण - एक डेटाबेस में, ठीक है, उन्होंने बस रखा जाना बंद कर दिया
- दुनिया के अलग-अलग हिस्सों में कई ग्राहक हैं और आपको जल्द से जल्द ऑर्डर बचाने की जरूरत है, आदि।
- वेब सेवाओं का तेजी से विकास, मोबाइल उपकरणों का आगमन
"क्लासिक" डेटाबेस क्लस्टर के अनुरूप क्या नहीं है?
लोकप्रिय से:
- ओरेकल आरएसी - जाहिरा तौर पर महंगा और मुश्किल, भारी, और विभिन्न महाद्वीपों में इसे कैसे बिखेरना है?
- MySQL क्लस्टर एक त्वरित मास्टर है, लेकिन बहुत सारे नुकसान और सीमाएं हैं, जैसे कि डेटा को केवल मेमोरी में स्टोर करना, लेकिन कुछ मामलों के लिए यह ठीक काम करता है
- mysql के लिए गैलेरा क्लस्टर - हां, ईमानदार मास्टर, जहां भी आप चाहते हैं (लेकिन आपको यह जानने की आवश्यकता है कि वास्तव में कहां है), लेकिन "अलग होने का प्रतिरोध" नहीं है, यह कोरम के अभाव में जम सकता है या पागल हो सकता है, जब यह गिरता है और भू-वितरित होने पर धीमा हो जाता है। उपयोग करें क्योंकि सभी प्रतियों में डेटा स्थानांतरित करता है; हाँ और स्वामी के बीच कोई डेटा पैनापन नहीं
और ई-व्यवसाय की आवश्यकता और आवश्यकताएं हैं:
- आधार हमेशा उपलब्ध होना चाहिए, आप ग्राहक के आदेश या उसकी टोकरी को नहीं खो सकते हैं; भले ही डेटाबेस नोड्स के बीच सिंक्रनाइज़ेशन चला गया हो
- डेटाबेस हर जगह (यूरोप और यूएसए) तक पहुंच योग्य होना चाहिए, और निश्चित रूप से, प्रतियों के बीच डेटा को सिंक्रनाइज़ करें
- आधार को डेटा की मात्रा बढ़ाने के साथ अनिश्चित काल के लिए स्केल करना चाहिए
- आधार को लोड करने के लिए पैमाना होना चाहिए: लिखना, पढ़ना
यह स्पष्ट है कि यह धारा धीरे-धीरे मांगती है लेकिन निश्चित रूप से आत्महत्या की ओर ले जाती है ... लेकिन
प्रोग्रामर जवाब - आप कर सकते हैं!
... लेकिन अगर आप प्रोग्रामर को असंभव को करने के लिए लंबे समय से पूछते हैं, तो वे करेंगे!

हर कोई नहीं जानता कि C पूर्ण-विकसित प्रोग्रामिंग के लिए पर्याप्त है, लेकिन सौंदर्य की भावना वाले लोगों के लिए आप C ++ में अपनी आत्मा को बाहर निकाल सकते हैं - नहीं, व्यवसाय के दबाव में: "आप कैसे तेजी से कार्यक्रम कर सकते हैं और ताकि हर कोई कर सकता है?" - प्रौद्योगिकियां जो शक्तिशाली थीं हार्डवेयर अब भी पहले से ही काम करता है: C #, जावा, अजगर, रूबी ...
इसलिए, इस सदी की शुरुआत में “NoSQL”
उत्पादों के रूप में इतना समय नहीं बीता है और यह संभव हो गया है:
- क्लस्टर के किसी भी तत्व को लिखें, हमेशा!
- अलग-अलग महाद्वीपों पर क्लस्टर तत्वों को रखें और स्थानीय लोगों से पढ़ें!
- क्लस्टर के किसी भी नोड को काटें और सिस्टम पागल नहीं होगा!
- अपने दिल की इच्छाओं के रूप में क्लस्टर नोड्स जोड़ें, और यह आपको लिखने और पढ़ने दोनों को स्केल करने की अनुमति देगा!
इसके अलावा, जाहिरा तौर पर,
Amazon ने DynamoDB के साथ दलिया पीना शुरू किया :
डायनेमोडीबी बड़े पैमाने पर गैर-संबंधपरक डेटाबेस और क्लाउड सेवाओं के क्षेत्रों में 15 वर्षों के सीखने का परिणाम है।
और फिर विचारों को फेसबुक
कैसेंड्रा के रूप में क्लोन किया जाने लगा:
अपाचे लक्ष्मण (अमेजन के डायनमो के लेखकों में से एक) और प्रशांत मलिक द्वारा इनबॉक्स सर्च फीचर को पॉवर देने के लिए अपाचे कैसेंड्रा को फेसबुक पर विकसित किया गया था। इसे जुलाई 2008 में Google कोड पर एक ओपन सोर्स प्रोजेक्ट के रूप में रिलीज़ किया गया था।
और निश्चित रूप से,
Google बिगटेबल इसके बिना नहीं कर सकता था।
यह किस तरह की "सिल्वर बुलेट" है?
क्या आप सात टोपी सीना? और सात मैं सीना ...
"NoSQL" उत्पादों के गहन अध्ययन के साथ, और अंतिम उत्पाद जिसके साथ मैंने काम किया था वह Amazon DynamoDB (अपाचे कैसेंड्रा के समान), "छिपा नुकसान और सीमाएं" दिखाई देने लगा, जिसे आप शायद ही "पारगम्यता शुल्क" कह सकते हैं:
आप क्लस्टर के किसी भी नोड को लिख सकते हैं, और पढ़ सकते हैं ...
और पढ़ने के लिए, डिफ़ॉल्ट रूप से,
असंगत जानकारी :-) और जैसा आप चाहते हैं, जानकारी सीमित गति से वितरित की जाती है। ठीक है, बेशक आप बॉक्स की जांच कर सकते हैं और दर्ज की गई जानकारी को पढ़ सकते हैं - लेकिन आपको इंतजार करना होगा, सर।
आप विभिन्न महाद्वीपों पर क्लस्टर नोड्स रख सकते हैं, लेकिन ...
लेकिन फिर, आपको यह जानना होगा कि जानकारी में समय लगता है - इसके लिए महाद्वीपों में फैलने के लिए और आवेदन को इस प्रक्रिया में सक्षम होना चाहिए (हम जिम्मेदारी को स्विच करते हुए देखते हैं, इसे धिक्कार है ... फिर से प्रोग्रामर :-))।
आप क्लस्टर के किसी भी नोड को बंद कर सकते हैं, एक कुल्हाड़ी के साथ नेटवर्क केबल काट सकते हैं, लेकिन ...
क्लस्टर विभाजन के प्रतिरोध को संस्करणकरण के समान तकनीकों के माध्यम से कार्यान्वित किया जाता है - लेकिन समय-समय पर आपको विसंगतियों के लिए एक खोज चलाने की आवश्यकता होगी जैसे कि "मर्कल पेड़ों का उपयोग करके एंटी-एंट्रोपी"।
अपने दिल की इच्छाओं के रूप में क्लस्टर नोड्स जोड़ें
यह संभव है, लेकिन आपको अभी भी शेष नोड्स को कॉन्फ़िगर करना होगा, कभी-कभी एक क्रॉबर और एक सोल्डरिंग लोहे के साथ।
और फिर और दिलचस्प।
Amazon DynamoDB सीमाएँ
हमारी परियोजनाओं में, हम डायनेमोडीबी, अमेज़ॅन के प्रमुख NoSQL समाधान का उपयोग करते हैं। आइए इसे नीचे और अधिक विस्तार से देखें।
डेटा प्रकार - स्पष्ट रूप से कुछ
संख्या, स्ट्रिंग, बाइनरी डेटा। DATETIME के बारे में भूल जाओ (उन्हें टाइमस्टैम्प के साथ अनुकरण किया जा सकता है, लेकिन कभी-कभी यह असहज हो जाता है)।
इंडेक्स जोड़े जा सकते हैं, केवल ... अभी से
सूचकांक को तुरंत निर्दिष्ट किया जाना चाहिए, प्रति तालिका 5 से अधिक नहीं होनी चाहिए। इसके अलावा, आप उन्हें किसी मौजूदा तालिका में नहीं जोड़ सकते, आपको वहां डेटा को हटाने, पुनः बनाने और पुनः लोड करने की आवश्यकता है। वास्तुकार के लिए एक शांत नींद प्रदान की जाती है।
डेटा का आकार
आप किसी भी डेटा को स्टोर कर सकते हैं, लेकिन ... "कॉलम" के नाम और मान के साथ "तालिका की एक पंक्ति" का आकार 64KB से अधिक नहीं होना चाहिए। सच है, "कॉलम" की संख्या सीमित नहीं है।
और अतिरिक्त अनुक्रमित की उपस्थिति में क्लस्टर के एक नोड (मुख्य हैश कुंजी सूचकांक के एक मूल्य के साथ) पर,
आप 10 जीबी से अधिक स्टोर
नहीं कर सकते , फिर।
व्यर्थ में "कॉलम" लिखा। "NoSQL" में अक्सर एक डेटा योजना की कोई अवधारणा नहीं होती है, इसलिए, प्रत्येक "तालिका की पंक्ति" में अलग-अलग "कॉलम" या "विशेषता" हो सकते हैं।
अनुरोध ...
आप केवल एक इंडेक्स के
लिए डेटा का चयन कर सकते हैं (अभी भी एक मुख्य (हैश की) इंडेक्स है, लेकिन श्रेणी चयन केवल इस पर नहीं किया जा सकता है - केवल स्थिर)। केवल एक सूचकांक के आधार पर छाँटें।
जटिल WHERE, GROUP BY के बारे में भूल जाइए, उप-वर्गों का उल्लेख नहीं करने के लिए - NoSQL इंजन बस उन्हें अनुकरण करते हैं और उन्हें बहुत धीरे-धीरे निष्पादित कर सकते हैं।
आप
अधिक जटिल चयन कर सकते हैं, लेकिन पूर्ण तालिका स्कैन विधि (कुख्यात तालिका स्कैन) का उपयोग कर और फिर परिणाम को तत्व द्वारा फ़िल्टर कर रहा है, जो लंबा और महंगा है।
लेन-देन - यह क्या है?
लेन-देन ... कभी-कभी उन्हें आवश्यकता होती है :-), और केवल व्यक्तिगत संस्थाओं के परमाणु अद्यतन की गारंटी है (एक ऑपरेशन में वेतन वृद्धि के साथ वास्तव में अच्छे बन्स हैं)। इसलिए आपको लेन-देन का अनुकरण करना होगा - अन्यथा आप चाहेंगे कि यदि डेटा पूरी दुनिया के 20 सर्वर / डेटा केंद्रों पर "फैल गया" है?
नृत्य प्रस्तुत करें
अक्सर NoSQL पर, सहित डाइनेमोबीडी
रिलेशनल थ्योरी के
संस्थापकों का मजाक उड़ाना शुरू कर देता है और लाइनों में भयावहता पैदा करता है:
user = john blog_post_ $ ts1 = 12 blog_post_ $ ts2 = 33 blog_post_ $ ts3 = 69 ...
जहाँ $ ts1-3 उपयोगकर्ता के ब्लॉग पोस्ट के टाइमस्टैम्प हैं।
हां, एक अनुरोध में प्रकाशनों की सूची प्राप्त करना सुविधाजनक है। लेकिन प्रोग्रामर का काम बढ़ रहा है।
निष्कर्ष
1) NoSQL परियोजना के लिए एक भंडार चुनने से पहले, एक समान श्रेणी के उत्पादों के एक
फ्रेंकस्टीन के उद्भव के कारणों को याद रखें, जो अक्सर अंतर्निहित साधारण सरल तर्क वाले ऐसे सर्वरों के सेट से ज्यादा कुछ नहीं है और, तदनुसार, डेटा भंडारण और सरल चयन होगा। वास्तव में, उड़ान भरने के लिए, लेकिन कुछ अधिक जटिल ... आवेदन पक्ष पर एक जादूगर होना होगा।
2)
ब्रूवर प्रमेय को फिर से पढ़ें और ट्रिक्स खोजें :-)
3) उपयोग किए गए उत्पाद के लिए प्रलेखन पर ध्यान से देखें - विशेष रूप से प्रतिबंध। सबसे अधिक संभावना है कि आप कई आश्चर्य से मिलेंगे - और आपको उनके लिए सावधानीपूर्वक तैयारी करने की आवश्यकता होगी।
4) और अंत में कोडडू की आंखों में देखें

हाँ, आपको लचीली प्रतिकृति योजनाओं का समर्थन करने वाला एक बहुत ही विश्वसनीय, अत्यधिक सुलभ, आधुनिक समाधान मिलेगा - लेकिन, अफसोस, आपको आवेदन तर्क के सबसे गंभीर विकृति और जटिलता के साथ भुगतान करना होगा (लेनदेन का अनुकरण करना, आवेदन के अंदर भारी डेटा के साथ करतब करना, आदि)। चुनाव आपका है!
सभी को शुभकामनाएँ!