जारी रखा जाए।
पिछले भाग:
1-3 ,
4-6 ,
7-910. डेटाबेस का सामान्यीकरण
रिलेशनल डेटा मॉडल में
रिलेशनल डेटाबेस के उचित डिज़ाइन के लिए मार्गदर्शन प्रदान किया जाता है। वे 5 समूहों में एकत्र किए जाते हैं, जिन्हें
सामान्य रूप कहा जाता
है । पहला सामान्य रूप डेटाबेस सामान्यीकरण के निम्नतम स्तर का प्रतिनिधित्व करता है। पांचवां स्तर सामान्यीकरण के उच्चतम स्तर का प्रतिनिधित्व करता है।
सामान्य रूप डेटाबेस डिजाइन करने के लिए
सिफारिशें हैं। डेटाबेस डिजाइन करते समय आपको सभी पांच सामान्य रूपों का पालन करने की आवश्यकता नहीं होती है। हालांकि, यह अनुशंसा की जाती है कि आप डेटाबेस को कुछ हद तक सामान्य कर लें क्योंकि इस प्रक्रिया में आपके डेटाबेस को संभालने की दक्षता और आसानी के मामले में कई महत्वपूर्ण फायदे हैं।
- एक सामान्यीकृत डेटाबेस संरचना में, आप अपेक्षाकृत सरल SQL प्रश्नों के साथ जटिल डेटा नमूनों का उत्पादन कर सकते हैं।
- डेटा अखंडता । एक सामान्यीकृत डेटाबेस आपको डेटा को सुरक्षित रूप से संग्रहीत करने की अनुमति देता है।
- सामान्यीकरण संग्रहीत डेटा के अतिरेक को रोकता है । डेटा हमेशा केवल एक ही स्थान पर संग्रहीत होता है, जो डेटा को सम्मिलित करने, अद्यतन करने और हटाने की प्रक्रिया को आसान बनाता है। इस नियम का अपवाद है। कुंजी स्वयं कई स्थानों पर संग्रहीत की जाती हैं क्योंकि उन्हें अन्य तालिकाओं के लिए विदेशी कुंजी के रूप में कॉपी किया जाता है।
- स्केलेबिलिटी एक प्रणाली की क्षमता है जो भविष्य के विकास का सामना कर सकती है। एक डेटाबेस के लिए, इसका मतलब है कि उपयोगकर्ताओं की संख्या और डेटा की मात्रा में वृद्धि होने पर यह जल्दी से काम करने में सक्षम होना चाहिए। RDBMS के लिए स्केलेबिलिटी किसी भी डेटाबेस मॉडल की एक बहुत महत्वपूर्ण विशेषता है।
यहाँ कुछ मुख्य बिंदु हैं जो
डेटाबेस सामान्यीकरण से संबंधित हैं:
- तार्किक समूहों या सेटों में डेटा व्यवस्थित करें।
- डेटासेट के बीच संबंध खोजना। आपने पहले से ही कई और कई-से-कई रिश्तों के उदाहरण देखे हैं।
- डेटा अतिरेक कम करें।
बहुत कम संख्या में डेटाबेस रिलेशनल डेटा मॉडल में दिए गए सभी पांच सामान्य रूपों का पालन करते हैं। डेटाबेस को आमतौर पर दूसरे या तीसरे सामान्य रूप में सामान्यीकृत किया जाता है। चौथे और पांचवें रूपों का उपयोग शायद ही कभी किया जाता है। इसलिए, मैं आपको केवल पहले तीन के बारे में बताने के लिए सीमित करूंगा।
11. पहला सामान्य रूप (1NF)
पहला सामान्य रूप कहता है कि एक डेटाबेस तालिका आपके सिस्टम के
सार का एक प्रतिनिधित्व है जिसे आप बना रहे हैं। संस्थाओं के उदाहरण: ऑर्डर, ग्राहक, टिकट, होटल, माल आदि ऑर्डर करना। डेटाबेस में प्रत्येक प्रविष्टि एक इकाई उदाहरण का प्रतिनिधित्व करती है। उदाहरण के लिए, ग्राहक तालिका में, प्रत्येक रिकॉर्ड एक ग्राहक का प्रतिनिधित्व करता है।
प्राथमिक कुंजी
नियम: प्रत्येक तालिका में प्राथमिक कुंजी होती है जिसमें छोटी से छोटी संख्या संभव होती है।जैसा कि आप जानते हैं, एक प्राथमिक कुंजी में कई फ़ील्ड शामिल हो सकते हैं। उदाहरण के लिए, आप प्राथमिक कुंजी के रूप में पहला और अंतिम नाम चुन सकते हैं (और आशा है कि यह संयोजन हमेशा अनूठा होगा)। यह एक बेहतर विकल्प सामाजिक कमरा होगा। प्राथमिक कुंजी के रूप में बीमा, के रूप में यह एकमात्र क्षेत्र है जो विशिष्ट रूप से किसी व्यक्ति की पहचान करता है।
इससे भी बेहतर, जब प्राथमिक कुंजी के शीर्षक के लिए कोई स्पष्ट उम्मीदवार नहीं है, तो संख्यात्मक ऑटो-वेतन वृद्धि क्षेत्र के रूप में एक
सरोगेट प्राथमिक कुंजी बनाएं।
Atomicity।
नियम: फ़ील्ड में प्रत्येक रिकॉर्ड में डुप्लिकेट नहीं होते हैं और प्रत्येक फ़ील्ड में केवल एक मान होता है।उदाहरण के लिए, एक कार संग्राहकों की वेबसाइट, जहाँ हर कलेक्टर अपनी कारों को पंजीकृत कर सकता है, ले लो। नीचे दी गई तालिका में पंजीकृत कारों के बारे में जानकारी संग्रहीत है।

क्षैतिज डेटा दोहराव बुरा अभ्यास है।
इस डिजाइन विकल्प के साथ, आप केवल पांच कारों को बचा सकते हैं और यदि आपके पास 5 से कम है, तो आप खाली कोशिकाओं को संग्रहीत करने के लिए डेटाबेस में खाली स्थान बर्बाद कर रहे हैं।
खराब डिजाइन अभ्यास का एक और उदाहरण एक सेल में कई मूल्यों को संग्रहीत करना है।

एक सेल में कई मान।
इस मामले में सही निर्णय एक अलग तालिका में कारों का आवंटन और एक विदेशी कुंजी का उपयोग होगा जो इस तालिका को संदर्भित करता है।
प्रविष्टियों का क्रम मायने नहीं रखना चाहिए।
नियम: तालिका प्रविष्टियों का क्रम मायने नहीं रखना चाहिए।आप ग्राहक तालिका में प्रविष्टियों के क्रम का उपयोग करने के लिए इच्छुक हो सकते हैं यह निर्धारित करने के लिए कि ग्राहक ने पहले पंजीकरण किया है। इन उद्देश्यों के लिए, आप ग्राहकों को पंजीकृत करने के लिए बेहतर दिनांक और समय क्षेत्र बनाते हैं। ग्राहकों के डिलीट, चेंज या ऐड किए जाने पर रिकॉर्ड्स का क्रम अनिवार्य रूप से बदल जाएगा। यही कारण है कि आपको किसी तालिका में प्रविष्टियों के आदेश पर कभी भी भरोसा नहीं करना चाहिए।
अगले भाग में, हम दूसरे सामान्य रूप (2NF) पर विचार करते हैं।
12. दूसरा सामान्य रूप।
डेटाबेस को दूसरे सामान्य रूप के अनुसार सामान्यीकृत करने के लिए, इसे पहले सामान्य रूप के अनुसार सामान्य किया जाना चाहिए। दूसरा सामान्य रूप डेटा अतिरेक के साथ जुड़ा हुआ है।
डेटा अतिरेक।
नियम: एक गैर-प्राथमिक कुंजी वाले फ़ील्ड को प्राथमिक कुंजी पर निर्भर नहीं होना चाहिए।यह थोड़ा अचकचाया हुआ लग सकता है। और इसका मतलब है कि आपको केवल उस तालिका में डेटा संग्रहीत करना चाहिए जो सीधे उससे संबंधित है और किसी अन्य इकाई से संबंधित नहीं है। दूसरे सामान्य रूप के बाद डेटा को खोजने का सवाल है जो अक्सर तालिका प्रविष्टियों में दोहराया जाता है और जो किसी अन्य इकाई से संबंधित हो सकता है।
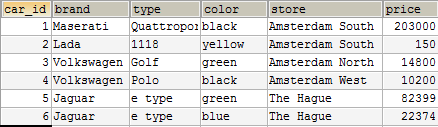
स्टोर फ़ील्ड में रिकॉर्ड के बीच डेटा का दोहराव।
ऊपर दी गई तालिका एक कंपनी की हो सकती है जो कार बेचती है और नीदरलैंड में कई स्टोर हैं।
यदि आप इस तालिका को देखते हैं, तो आपको अभिलेखों के बीच डेटा दोहराव के कई उदाहरण दिखाई देंगे।
ब्रांड फ़ील्ड को एक अलग तालिका में हाइलाइट किया जा सकता है। साथ ही
प्रकार फ़ील्ड (मॉडल), जिसे एक अलग तालिका में भी विभाजित किया जा सकता है, जिसके
ब्रांड तालिका के साथ कई-से-एक संबंध होंगे क्योंकि ब्रांड के अलग-अलग मॉडल हो सकते हैं।
स्टोर कॉलम में उस
स्टोर का नाम होता है जहां मशीन वर्तमान में स्थित है।
स्टोर डेटा अतिरेक और एक अलग इकाई के लिए एक अच्छा उम्मीदवार का एक स्पष्ट उदाहरण है, जिसे
विदेशी प्रमुख संचार द्वारा कार की मेज
से जोड़ा जाना चाहिए।
नीचे एक उदाहरण है कि आप कैसे कारों के लिए एक डेटाबेस मॉडल कर सकते हैं, डेटा अतिरेक से बच सकते हैं।

उपरोक्त उदाहरण में,
कार तालिका में एक विदेशी कुंजी है -
प्रकार और
स्टोर तालिकाओं के लिए एक लिंक। ब्रांड कॉलम गायब हो गया है क्योंकि
प्रकार तालिका के माध्यम से ब्रांड के लिए एक अंतर्निहित लिंक है। जब टाइप करने के लिए एक लिंक होता है, तो ब्रांड के लिए एक लिंक होता है, जैसे प्रकार ब्रांड के अंतर्गत आता है।
हमारे डेटाबेस मॉडल से डेटा अतिरेक को काफी हद तक समाप्त कर दिया गया है। यदि आप पर्याप्त रूप से योग्य हैं, तो आप इस निर्णय से संतुष्ट नहीं हो सकते हैं।
ब्रांड तालिका में
देश_ऑफ_ॉरजिन क्षेत्र के बारे में क्या?
जबकि कोई डुप्लिकेट नहीं है क्योंकि विभिन्न देशों से केवल चार ब्रांड हैं। एक चौकस डेटाबेस डिजाइनर को एक अलग
देश तालिका में देश के नामों को उजागर करना चाहिए।
और अब भी आपको परिणाम से संतुष्ट नहीं होना चाहिए क्योंकि आप एक अलग तालिका में
रंग क्षेत्र का चयन भी कर सकते हैं।
आप अपनी मेजों के निर्माण के लिए कितनी सख्ती से संपर्क करते हैं, यह आपके ऊपर है और विशिष्ट स्थिति पर निर्भर करता है। यदि आप सिस्टम में बड़ी संख्या में कार इकाइयों को संग्रहीत करने की योजना बनाते हैं और आप रंग द्वारा खोज करना चाहते हैं, तो यह अलग तालिका में रंगों का चयन करने के लिए एक बुद्धिमान निर्णय होगा ताकि वे डुप्लिकेट न हों।
एक और मामला है जहां आप एक अलग तालिका में रंगों को उजागर करना चाह सकते हैं। यदि आप कंपनी के कर्मचारियों को नई कारों पर डेटा दर्ज करने की अनुमति देना चाहते हैं, तो आप उन्हें कार
के रंग को पूर्वनिर्धारित सूची में से चुन सकते हैं। इस मामले में, आप अपने डेटाबेस में सभी संभव रंगों को संग्रहीत करना चाहेंगे। यहां तक कि
अगर इस रंग के साथ कोई कारें नहीं हैं , तो आप चाहते हैं कि ये रंग डेटाबेस में मौजूद हों, ताकि कर्मचारी उनका चयन कर सकें। यह निश्चित रूप से मामला है जब आपको एक अलग तालिका में रंगों को उजागर करने की आवश्यकता होती है।
13. तीसरा सामान्य रूप।
तीसरा सामान्य रूप
सकर्मक निर्भरता के साथ जुड़ा हुआ
है । डेटाबेस फ़ील्ड के बीच सकरात्मक निर्भरताएँ तब मौजूद होती हैं जब गैर-कुंजी फ़ील्ड के मान अन्य गैर-कुंजी फ़ील्ड के मानों पर निर्भर करते हैं। डेटाबेस के तीसरे सामान्य रूप में होने के लिए, यह दूसरे सामान्य रूप में होना चाहिए।
सकर्मक निर्भरता।
नियम: तालिका में खेतों के बीच कोई सकर्मक निर्भरता नहीं हो सकती है।
नीचे दी गई ग्राहक तालिका (मेरे ग्राहक जर्मन और फ्रेंच फुटबॉल टीमों के खिलाड़ी हैं) में सकर्मक निर्भरताएं हैं।
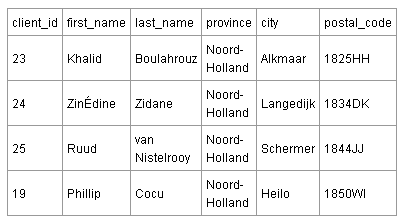
इस तालिका में, सभी फ़ील्ड केवल प्राथमिक कुंजी पर निर्भर नहीं होती हैं। डाक_कोड क्षेत्र और शहर और प्रांत के क्षेत्रों के बीच एक अलग संबंध है। नीदरलैंड में, दोनों अर्थ: शहर और प्रांत - पोस्टल कोड, पोस्टल कोड द्वारा निर्धारित किए जाते हैं। इस प्रकार, ग्राहक तालिका में शहर और प्रांत को संग्रहीत करने की आवश्यकता नहीं है। यदि आप पोस्टल कोड जानते हैं, तो आप पहले से ही शहर और प्रांत को जानते हैं।
यदि आप अपने डेटाबेस मॉडल को तीसरे सामान्य रूप में रखना चाहते हैं तो इस तरह की सकरात्मक निर्भरता से बचा जाना चाहिए।
इस मामले में, तालिका से परिवर्तनशील निर्भरता का उन्मूलन शहर और प्रांत के क्षेत्रों को तालिका से हटाकर और उन्हें एक अलग तालिका में संग्रहीत किया जा सकता है जिसमें पोस्टल कोड (प्राथमिक कुंजी), प्रांत का नाम और शहर का नाम शामिल है। पूरे देश के लिए पोस्टल कोड-शहर-प्रांत संयोजन प्राप्त करना एक बहुत ही गैर-तुच्छ कार्य हो सकता है। यही कारण है कि ऐसी तालिकाओं को अक्सर बेचा जाता है।
तीसरे सामान्य रूप को लागू करने के लिए एक और उदाहरण नीचे एक ऑनलाइन स्टोर ऑर्डर तालिका का बहुत (सरल) सरल उदाहरण है।
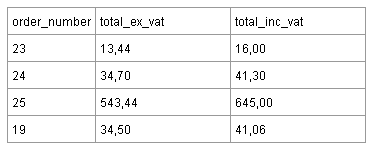
वैट (मूल्य वर्धित कर) वह प्रतिशत है जो उत्पाद की कीमत (इस तालिका में 19%) में जोड़ा जाता है। इसका मतलब यह है कि Total_ex_vat के मूल्य की गणना total_inc_vat और इसके विपरीत के मूल्यों से की जा सकती है। आपको तालिका में इन मूल्यों में से एक को संग्रहीत करना होगा, लेकिन एक बार में दोनों नहीं। आपको डेटाबेस का उपयोग करने वाले प्रोग्राम के लिए Total_ex_vat या इसके विपरीत कुल total_inc_vat की गणना करने का कार्य निर्दिष्ट करना होगा।
तीसरा सामान्य रूप कहता है कि आपको उस तालिका में डेटा संग्रहीत नहीं करना चाहिए जिसे तालिका में अन्य (गैर-कुंजी) फ़ील्ड से प्राप्त किया जा सकता है। विशेष रूप से ग्राहक तालिका के साथ उदाहरण में, तीसरे सामान्य रूप का अनुसरण करने के लिए या तो बड़ी मात्रा में काम की आवश्यकता होती है या ऐसी तालिका के लिए डेटा के वाणिज्यिक संस्करण के अधिग्रहण की आवश्यकता होती है।
तीसरा सामान्य रूप हमेशा डेटाबेस डिज़ाइन में उपयोग नहीं किया जाता है। डेटाबेस डिजाइन करते समय, आपको तीसरे सामान्य रूप को लागू करने और उस स्थिति में डेटा को बनाए रखने के लिए आवश्यक कार्य की मात्रा की तुलना में हमेशा उच्च सामान्य रूप के लाभों की तुलना करनी चाहिए। ग्राहक तालिका के मामले में, व्यक्तिगत रूप से, मैं तालिका को तीसरे सामान्य रूप से सामान्य नहीं करना पसंद करूंगा। वैट के साथ अंतिम उदाहरण में, मैं तीसरे सामान्य रूप का उपयोग करूंगा।
मौजूदा डेटा
से डेटा रखना आमतौर पर एक बुरा विचार है।