परीक्षण के दृष्टिकोण से, यैंडेक्स बड़ी संख्या में सेवाओं की जांच करने के लिए हजारों मानव-घंटे का काम है। बहुत सारी कार्यक्षमता, इंटरैक्शन परिदृश्य हैं - लाखों। हम यह सुनिश्चित करने की कोशिश करते हैं कि लोग केवल जटिल और दिलचस्प कार्यों में लगे हुए हैं, और सभी नियमित काम रोबोट को सौंपे जा सकते हैं।
आदर्श रूप से, यह रोबोट है जो यह सत्यापित करना चाहिए कि इनपुट फॉर्म के साथ एक साधारण पृष्ठ लोड या जटिल इंटरैक्शन के परिणामस्वरूप, लोड किए गए डेटा की जगह पर "NaN", "अपरिभाषित" या खाली लाइनें दिखाई नहीं देती हैं। इस तरह के रोबोट के निर्माण और कार्यान्वयन के लिए प्रायोगिक परियोजना का कोड नाम "रोबोटस्टर" है।

हमने
पहले से ही बताया कि हमने इसे कैसे लागू किया और रूपों के साथ काम करना सिखाया। आज हम इस बारे में बात करेंगे कि हमारा रोबोट सेवा की अधिकतम कार्यक्षमता को कैसे खोजने की कोशिश कर रहा है, और फिर इसे "समझें"।
एक बार, प्रत्येक साइट एक स्थिर पृष्ठ थी, जिसकी सामग्री सर्वर के लिए एक अनुरोध का उपयोग करके बनाई गई थी। अब, कई साइटों को
रिच इंटरनेट एप्लिकेशन (आरआईए) के रूप में वर्गीकृत किया जा सकता है: वे बहुत अधिक संवादात्मक हो गए हैं और पृष्ठ पर उपयोगकर्ता के व्यवहार के आधार पर उनकी सामग्री भिन्न होती है। वेब एप्लिकेशन जावास्क्रिप्ट, और AJAX जैसी तकनीकों का उपयोग करने वाली पारंपरिक साइटों से भिन्न होती हैं, जो आपको ब्राउज़र में पता बदलने के बिना आवेदन की उपस्थिति और सामग्री को महत्वपूर्ण रूप से बदलने की अनुमति देती हैं।
साइट का परीक्षण करने के लिए, परीक्षक को केवल खोज क्रॉलर के कार्य को पूरा करने की आवश्यकता नहीं है और साइट के सभी पृष्ठों के माध्यम से जाना है, बल्कि उनके सभी राज्यों का दौरा करने के लिए, या बल्कि, उन सभी पृष्ठों के सभी राज्यों का दौरा करना है, जिन पर विभिन्न कार्य किए जा सकते हैं।
सबसे सामान्य रूप में, आप राज्य ग्राफ के रूप में एक साइट की कल्पना कर सकते हैं और ग्राफ़ में सभी कोने या कम से कम उनकी अधिकतम संख्या पर जाने के लिए दृष्टिकोण देख सकते हैं। लेकिन इस रूप में, कार्य अनुचित है - यहां तक कि एक साधारण यांडेक्स सेवा में इतने सारे राज्य हैं कि इसे अनंत माना जा सकता है। उदाहरण के लिए, खोज फ़ील्ड में प्रत्येक नई क्वेरी दर्ज करना और "खोज" बटन दबाकर हमें एक नई स्थिति में ले जाता है। यही है, कम से कम उनमें से कई हैं क्योंकि आप विभिन्न खोज क्वेरी दर्ज कर सकते हैं। इसलिए, हम मानक परीक्षण दृष्टिकोण का उपयोग करते हैं जब राज्यों को अपेक्षाकृत कम संख्या में वर्गों में विभाजित किया जाता है। उदाहरण के लिए, खोज परिणामों के साथ कई पृष्ठों को निम्न समूहों में विभाजित करना उचित होगा: परिणामों की कमी, परिणामों की एक छोटी संख्या, परिणामों के कई पृष्ठ। सभी वर्गों को किसी प्रकार का समतुल्य संबंध दिया जाना चाहिए, जिसके बाद हम इस वर्ग के कम से कम एक प्रतिनिधि की जाँच करने का प्रयास करते हैं। लेकिन इस रोबोटस्टर को कैसे पढ़ाया जाए?
हमने निम्नानुसार काम किया है। फिर भी, हमने कार्य को दो भागों में विभाजित किया है: "पृष्ठों के क्रॉलर" द्वारा हम लिंक के द्वारा साइट के चारों ओर जाते हैं, एक निश्चित संख्या में पृष्ठों का चयन करते हैं, और फिर चयनित पृष्ठों में से प्रत्येक पर हम "क्रॉलर ऑफ फॉर्म" लॉन्च करते हैं, जो नीचे दिए गए एल्गोरिदम के अनुसार पृष्ठ को बदलता है और केवल रुकता है एक नए के लिए चल रहा है। हमने ऐसा इसलिए किया क्योंकि इन दोनों क्रॉलरों के कार्य अलग-अलग हैं: यदि लिंक पर क्लिक की अधिकतम "गहराई" शायद ही 5-6 से अधिक है, तो रूपों का उपयोग करके एक नए पृष्ठ पर जाने के लिए, कभी-कभी आपको सौ या दो कार्यों को करने की आवश्यकता होती है। एक उदाहरण के रूप में, आप
Yandex.Direct में एक अभियान बनाने के लिए फ़ॉर्म को देख सकते हैं, जिसे आप प्राधिकरण के बाद देखेंगे। इसलिए, विभिन्न वर्कअराउंड एल्गोरिदम का उपयोग करना उचित है।
बेशक, पुरानी साइटें हैं जहां लगभग कोई उचित तत्व नहीं हैं (केवल पहला क्रॉलर वास्तव में वहां काम करेगा), और, इसके विपरीत, आधुनिक आरआईए जहां पेज यूआरएल बिल्कुल नहीं बदल सकते हैं (तब केवल दूसरा क्रॉलर काम करेगा)। फिर भी, हमें एक अपेक्षाकृत लचीला प्रणाली मिली, जो लगभग किसी भी सेवा के लिए कॉन्फ़िगर करना आसान है।
पेज क्रॉलर कैसे काम करता है
तो, हमारा पहला काम उन पृष्ठों का चयन करना है, जिन पर फॉर्म क्रॉलर लॉन्च किया जाएगा। इन "प्रवेश बिंदुओं" का एक सेट कैसे प्राप्त करें? सबसे पहले हमने आम तौर पर यह तय किया कि यह मैन्युअल रूप से किया जा सकता है। यहाँ पृष्ठों की एक छोटी सूची का एक उदाहरण दिया गया है:
जैसा कि आप देख सकते हैं, पृष्ठ पते में बड़ी संख्या में पैरामीटर हैं। यदि कोई भी पैरामीटर बदलता है, तो लिंक अमान्य हो जाता है। इसके अलावा, नए पृष्ठ कक्षाएं दिखाई देती हैं, और उनमें से कुछ अप्रचलित हो जाते हैं। इसलिए, यह हमारे लिए स्पष्ट हो गया कि हमें गतिशील रूप से संकलन करने और उन पृष्ठों की एक सूची बनाए रखने की आवश्यकता है जिन्हें परीक्षण करने की आवश्यकता है।
मान लीजिए कि हमारी साइट के पेज ग्राफ में आकृति में दिखाया गया रूप है:
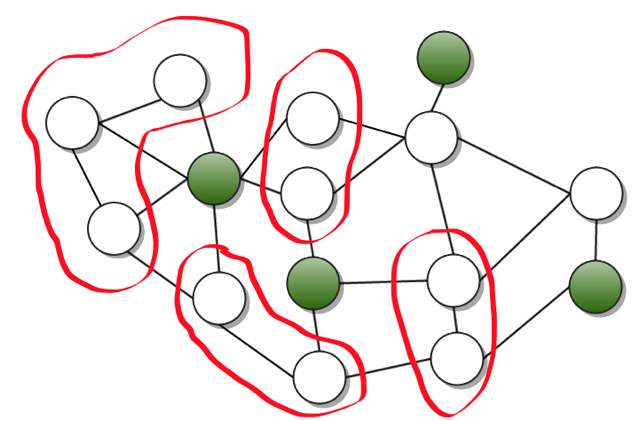
ग्राफ़ के प्रत्येक किनारे को लिंक संक्रमण होने दें।
क्रॉलजैक्स जैसा उपकरण सभी संभावित तरीकों से एक चोटी से जाना शुरू करता है। साइट क्रॉल करने का यह तरीका बहुत लंबा समय ले सकता है। लेकिन हमने फैसला किया कि हम अलग तरीके से कार्य करेंगे: हम ग्राफ में "प्रवेश बिंदु" (आकृति में हरे रंग की कोने) का चयन करते हैं, ताकि आदर्श रूप से, हरे रंग के कोने का सेट
1-नेटवर्क बन जाए । एक नियम के रूप में, इस मामले में, प्रवेश बिंदु रूपों के साथ पृष्ठ हैं, और 1 पृष्ठ की दूरी पर सुलभ खोज का परिणाम है। इस प्रकार, साइट का परीक्षण करने के लिए, यह हमारे लिए प्रवेश बिंदुओं को खोजने, उन पर विभिन्न क्रियाएं करने और उस पृष्ठ पर त्रुटियों की जांच करने के लिए पर्याप्त है जिस पर हमने स्विच किया था। यह ध्यान देने योग्य है कि एक प्रविष्टि बिंदु के 1-पड़ोस के अधिकांश पृष्ठ कार्यक्षमता में समान हैं, इसलिए ऐसे पड़ोस के सभी प्रतिनिधियों का परीक्षण नहीं किया जा सकता है।
इसलिए, साइट का परीक्षण करने के लिए, रोबोट के पास अपने कुछ पृष्ठों की सूची होनी चाहिए।
वेब क्रॉलर - एक काफी मानक और बहुत व्यापक रूप से जलाया जाने वाला कार्य। क्लासिक व्याख्या में, क्रॉलर को अधिक से अधिक पृष्ठों को खोजने की आवश्यकता है। जितने अधिक पृष्ठ, उतना ही बड़ा सूचकांक, बेहतर खोज। हमारे कार्य के संदर्भ में, क्रॉलर की आवश्यकताएं हैं:
- उचित समय में क्रॉल करना संभव होना चाहिए।
- क्रॉलर को संभव पेज संरचना के रूप में अलग-अलग चयन करना चाहिए।
- परीक्षण किए जाने वाले पृष्ठों की संख्या आउटपुट में सीमित होनी चाहिए।
- क्रॉलर को उन पेजों से भी इकट्ठा करना चाहिए, जो गतिशील रूप से लोड किए गए हैं (शुरू में पेज कोड में शामिल नहीं हैं)।
- प्राधिकरण, क्षेत्रीय निर्भरता और यांडेक्स सेवाओं की अन्य सेटिंग्स का समर्थन करना संभव होना चाहिए।
आवश्यकता नंबर १: समयपरीक्षण प्रक्रिया की अवधि को नियंत्रित करना आवश्यक हो सकता है। मान लीजिए कि आपको एक रिलीज जारी करने की आवश्यकता है और जल्दी से बुनियादी कार्यक्षमता की जांच करना चाहते हैं। रेंगने की अवधि की गहराई और विज़िट किए गए पृष्ठों की संख्या को सीमित करके कुछ रूपरेखा में डाला जा सकता है।
आवश्यकता नंबर 2: कवरेजदूसरी आवश्यकता यथासंभव कम समय में अधिक कार्यक्षमता के साथ परीक्षणों को कवर करने की आवश्यकता से उपजी है। जाहिर है, सामग्री सेवा में समकक्ष (कार्यक्षमता में) पृष्ठ हैं। आप पृष्ठ के URL और उसके HTML-कोड के आधार पर ऐसे पृष्ठों को क्लस्टर कर सकते हैं। हमने एक ऐसी विधि विकसित की है जो आपको ऐसे पृष्ठों को क्लस्टर में जल्दी और सटीक रूप से विभाजित करने की अनुमति देती है।
हम दो प्रकार के पृष्ठ रिक्ति का उपयोग करते हैं:
- UrlDistance यूआरएल में अंतर के लिए जिम्मेदार है। यदि दो url की लंबाई समान है, तो url के बीच की दूरी मिलान वाले वर्णों की संख्या के व्युत्क्रमानुपाती होती है। यदि लंबाई अलग है, तो दूरी लंबाई के अंतर के लिए आनुपातिक है।
- TagDistance पृष्ठों के html-code में अंतर के लिए जिम्मेदार है। दो DOM पेड़ों के बीच की दूरी एक ही नाम के टैग की संख्या में अंतर है।
यह ध्यान देने योग्य है कि दूसरी आवश्यकता का कार्यान्वयन पहली आवश्यकता के अनुरूप होना चाहिए। मान लें कि हमें Yandex.Market साइट के परीक्षण के लिए पृष्ठों का चयन करने की आवश्यकता है। मान लीजिए कि प्रत्येक पृष्ठ एन लिंक की ओर जाता है और हम क्रॉल के की गहराई में रुचि रखते हैं। सभी पृष्ठों की तुलना करने के लिए, हमें एचटीएमएल-कोड ओ (एन
के ) पृष्ठों को डाउनलोड करना होगा। इसमें बहुत समय लग सकता है, यह देखते हुए कि सामग्री साइट के प्रत्येक पृष्ठ से 20-30 लिंक हो सकते हैं। यह तरीका हमें शोभा नहीं देता। हम पृष्ठों को बहुत अंत में नहीं, बल्कि हर चरण में फ़िल्टर करेंगे।
तो, हमारे पास हमारे निपटान में वर्तमान पृष्ठ के लिंक की एक सूची है, जिसमें से हमें सबसे अलग चुनने की आवश्यकता है।
- फ़िल्टरिंग का पहला चरण: UrlDistance के अनुसार url की तुलना करना, L को सबसे अलग छोड़ना।
- फ़िल्टर करने का दूसरा चरण: L के उन अधिकांश पृष्ठों के HTML कोड को लोड करें जो UrlDistance मीट्रिक में भिन्न हैं और TagDistance का उपयोग करके उन्हें सहेजते हैं।
इस प्रकार, हमें केवल O (L · K) पृष्ठों के लिए कोड डाउनलोड करना होगा। पृष्ठ फ़िल्टरिंग प्रक्रिया के इन सभी सरलीकरणों के साथ, परिणामी "एंट्री पॉइंट्स" की गुणवत्ता हमें सूट करती है!
आवश्यकता संख्या 3: परीक्षित पृष्ठों की संख्यातीसरी आवश्यकता के कार्यान्वयन से हमें उन पृष्ठों की संख्या को सीमित करने की अनुमति मिलेगी, जिन पर परीक्षण आयोजित किए जाएंगे। मोटे तौर पर, हम रोबोट को बता रहे हैं "एन सबसे कार्यात्मक पृष्ठों का चयन करें और उनका परीक्षण करें।"
आवश्यकता 4: गतिशील रूप से भरी हुई सामग्री को ध्यान में रखेंWebDriver आपको गतिशील रूप से लोड किए गए ब्लॉकों से भी लिंक एकत्र करने की अनुमति देता है, और केवल नेत्रहीन सुलभ लिंक (मानव व्यवहार मॉडलिंग) पर क्लिक करता है।
आवश्यकता नंबर ५: संदर्भएक क्षेत्र या उपयोगकर्ता अधिकार (अलग-अलग जारी करने, अलग कार्यक्षमता) जैसे संदर्भ को ध्यान में रखने के लिए, क्रॉलर को
कुकीज़ के साथ काम करने में सक्षम होना चाहिए। उदाहरण के लिए, क्या आप जानते हैं कि विभिन्न क्षेत्रों में यैंडेक्स का मुख्य पृष्ठ भी अलग हो सकता है?
इसलिए, हमने उपरोक्त सभी आवश्यकताओं को पूरा किया है और साइट की कार्यक्षमता की सबसे बड़ी संभव राशि को जल्दी और कुशलता से खोजने में सक्षम हैं। रोबोट ने "प्रवेश बिंदु" पाया है। अब आपको 1-पड़ोस की यात्रा करने की आवश्यकता है, या, अधिक बस, फॉर्म के साथ बातचीत करें।
क्रॉलर रूपों
साइट की कार्यक्षमता का परीक्षण करने के लिए, आपको इसका उपयोग करने में सक्षम होना चाहिए। यदि आप
सोच-समझकर सब कुछ पर क्लिक करना शुरू
करते हैं और इनपुट टेक्स्ट फ़ील्ड में कोई भी मान दर्ज करते हैं (कोई भी कैसे दर्ज करें), तो आप उचित समय में गुणात्मक रूप से परीक्षण नहीं कर पाएंगे। उदाहरण के लिए, यैंडेक्स पर ऐसे रूपों के साथ बातचीत करना काफी कठिन है।
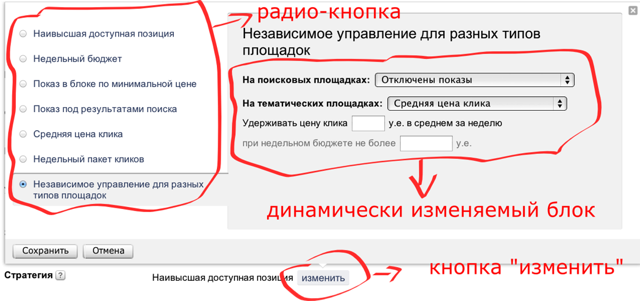
इसलिए जब आप "परिवर्तन" बटन पर क्लिक करते हैं, तो एक नया ब्लॉक दिखाई देता है, जिसमें जब आप रेडियो बटन के अगले मूल्य का चयन करते हैं, तो ग्रे बैकग्राउंड पर आकार बदल जाता है, जो बदले में गतिशील रूप से खेतों में भरने पर बदल जाता है। जाहिर है, इतने इनपुट क्षेत्रों के साथ, जैसा कि इस रूप में, कुछ रणनीति की आवश्यकता है, अन्यथा रोबोट लंबे समय तक स्थिर रहेगा।
आइए कार्य को औपचारिक रूप दें। हम मान सकते हैं कि सभी इनपुट फ़ील्ड ड्रॉप-डाउन सूची हैं। वास्तव में, हमारे लिए पाठ इनपुट फ़ील्ड वास्तव में एक ड्रॉप-डाउन सूची बन जाती है जब हम इसका प्रकार निर्धारित करते हैं और उन मूल्यों की एक सीमित संख्या का चयन करते हैं जिन्हें हम इसमें दर्ज कर सकते हैं। हमारा कार्य एक इष्टतम तरीके से फॉर्म का परीक्षण करना है, जो कि निश्चित मामलों की एक निश्चित संख्या या किसी दिए गए कवरेज के साथ परीक्षण के मामलों की न्यूनतम संख्या के साथ अधिकतम कवरेज का अर्थ है (जो हमारे लिए अधिक महत्वपूर्ण है - परीक्षण की गति, या कवरेज स्तर)।
एक साधारण मामला । इनपुट फ़ील्ड एक निश्चित संख्या है, और वे बदलते नहीं हैं, अर्थात, वे एक दूसरे पर निर्भर नहीं हैं। यह कार्य काफी लोकप्रिय है और व्यापक रूप से कवर किया गया है। उदाहरण के लिए, हम सुंदर नाम
जेनी के साथ एक कार्यक्रम का उपयोग करते हैं।
यह इनपुट की वांछित गहराई और संख्याओं के समूह के रूप में लेता है जो प्रत्येक इनपुट क्षेत्र में विकल्पों की संख्या के लिए जिम्मेदार होते हैं। एक छोटे रूप के उदाहरण पर विचार करें। मान लीजिए कि हम तीन इनपुट फ़ील्ड के एक रूप के लिए डिग्री 2 के कवरेज में रुचि रखते हैं, जिनमें से प्रत्येक के पास दो विकल्प हैं। भरने के निर्देश इस तरह दिखाई देंगे:

नंबर इनपुट फ़ील्ड की संख्या है, अक्षर चुने जाने वाले विकल्प की संख्या है। डिग्री एन के एक कवरेज का मतलब है कि अगर हम किसी एन कॉलम को ठीक करते हैं, तो उनमें सभी संभव संयोजन मिलेंगे।
एक मुश्किल मामला । प्रपत्र गतिशील है और इनपुट फ़ील्ड की संख्या बदलती है। उदाहरण के लिए, पहले तीन क्षेत्रों में भरने के परिणामस्वरूप, एक चौथा और पांचवां इनपुट क्षेत्र दिखाई देता है, या "भेजें" बटन तुरंत दिखाई देता है। इस फॉर्म के मॉडल के रूप में एक "राज्य का ग्राफ" उपयुक्त है। ग्राफ का प्रत्येक शीर्ष रूप की एक स्थिति है। यह फॉर्म से इनपुट फ़ील्ड को हटाकर, इनपुट फ़ील्ड के मूल्य को बदलकर या एक नया जोड़कर बदल सकता है।
हमने कई धारणाएँ बनाई हैं, जो हमारे लिए महत्वपूर्ण नहीं हैं, जिसके तहत एल्गोरिथ्म को काम करना चाहिए:
- इनपुट फ़ील्ड शायद ही कभी हटाए जाते हैं, इसलिए हम इस तरह के मामले पर विचार नहीं करते हैं।
- यदि, फ़ील्ड A को भरने के दौरान, फ़ील्ड B बदल गया, तो आपको इनपुट फ़ील्ड को क्रमबद्ध रूप से सॉर्ट करने की आवश्यकता है, जिसमें हमें वह ऑर्डर मिला है जिसमें हम पहले A को भरेंगे, और फिर B, यदि B A. पर निर्भर करता है, तो हम मानते हैं कि श्रेष्ठ (शारीरिक) पृष्ठ पर स्थान) तत्व अधीनस्थ पर निर्भर नहीं करते हैं।
- यदि इंटरैक्शन के परिणामस्वरूप कोई नया इनपुट फ़ील्ड दिखाई देता है, तो हम मानते हैं कि यह पिछले इनपुट फ़ील्ड में से केवल एक पर निर्भर करता है। वास्तव में, ऐसा नहीं है, लेकिन यह धारणा कार्य को बहुत सरल बनाती है।
एक इनपुट फ़ील्ड की स्थिति को बदलकर किसी अन्य शीर्ष पर संक्रमण किया जाता है।
मान लीजिए, शुरू में, एक रूप में ए
1 तत्व होते हैं ... ए
एन । प्रत्येक ए के लिए
हम प्रदर्शन करते हैं:
- हम सभी संभव तरीकों से ए i के साथ बातचीत करने की कोशिश कर रहे हैं। इन विधियों के k टुकड़े होने दें।
- हम उन तत्वों को बी i1 ठीक करते हैं ... बी ik जो एई के विभिन्न भरावों के दौरान दिखाई दिए।
- बी आईजे के प्रत्येक के लिए पुनरावर्ती प्रक्रिया दोहराएं।
इस दृष्टिकोण के साथ, एल्गोरिथ्म बहुत लंबे समय तक काम कर सकता है, क्योंकि बातचीत के तरीकों की संख्या तत्वों की संख्या से तेजी से बढ़ेगी। निकट भविष्य में समाप्त होने के लिए क्रॉलिंग फॉर्म के लिए, बातचीत के सभी संभावित तरीकों की गणना केवल 2 से अधिक की गहराई पर स्थित तत्वों के लिए की जाती है, और अन्य सभी के लिए हम एक यादृच्छिक मूल्य चुनते हैं। यह दृष्टिकोण परीक्षण रूपों के लिए आवश्यक है जिसमें कुछ निश्चित क्षेत्रों की आवश्यकता होती है।
एल्गोरिथ्म
मान लीजिए, शुरू में, एक रूप में ए
1 तत्व होते हैं ... ए
एन । प्रत्येक ए के लिए
हम प्रदर्शन करते हैं:
1. हम सभी संभव तरीकों से ए के साथ बातचीत करने की कोशिश करते हैं। इन विधियों के k टुकड़े होने दें।
2. हम उन तत्वों को B
i1 ... B
ik को ठीक करते हैं जो A के विभिन्न भरावों के दौरान दिखाई देते हैं।
3. प्रत्येक तत्व B
ij के लिए , जब तक हम फॉर्म भरने के अंत तक नहीं पहुँचते, प्रदर्शन करते हैं:
3.1। हम सभी संभव तरीकों से तत्व बी
आईजे के साथ बातचीत करते हैं।
3.2। बी
आईजे में भरते समय उपलब्ध होने वाले प्रत्येक तत्व के साथ, हम एक अद्वितीय यादृच्छिक तरीके से बातचीत करते हैं।

इष्टतम कवरेज गणना से उत्पन्न होता है कि
मैं एक ड्रॉप-डाउन सूची है जिसमें कई विकल्प हैं जैसे कि स्तर 3 से इसके तरीके हैं।
हम एक ठोस उदाहरण देते हैं।
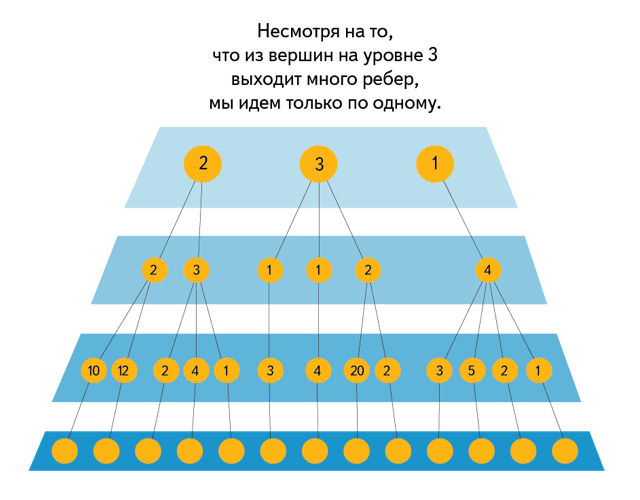
वर्टेक्स ए
1 से लेवल 3 तक के पांच रास्ते हैं, वर्टेक्स ए
2 - चार से, और वर्टेक्स ए
3 से भी चार। तदनुसार, ए
1 को पांच क्षेत्रों के साथ ड्रॉप-डाउन सूची के रूप में और चार के साथ ए
2 और ए
3 का प्रतिनिधित्व किया जा सकता है। इसलिए, रोबोट जेनी को "5 4 4" तर्कों के साथ लॉन्च करेगा।
हमने रोबोट को सेवा की कार्यक्षमता का पता लगाने और इसे उपयोग करने के लिए विचारशील (एक व्यक्ति के बारे में) सिखाया। बेशक, आपको यह उम्मीद नहीं करनी चाहिए कि निकट भविष्य में वह यैंडेक्स के साथ पंजीकरण करेगा। अप्रत्यक्ष रूप से, अपने प्रिय के लिए स्वतंत्र रूप से एक विज्ञापन कंपनी बनाएगा और दुनिया भर में प्रसिद्ध हो जाएगा, हालांकि वह पहले से ही जानता है कि आंतरिक सेवा पर परियोजनाएं कैसे बनाएं (हालांकि, वे अजीब तरह से पर्याप्त हैं, अभी तक गोली नहीं चली है। :))। हालाँकि, हम उससे यह उम्मीद नहीं करते हैं! वह रूपों को सक्षम और अंत तक भरता है। हम उसे वेब इंटरफेस की गुणवत्ता परीक्षण करने की उम्मीद करते हैं, और वह हमारी उम्मीदों पर खरा उतरता है।