सभी को नमस्कार!
मैं जॉन टोरजो की पुस्तक Boost.Asio C ++ नेटवर्क प्रोग्रामिंग का अनुवाद करना जारी रखता हूं।
सामग्री:
Boost.Asio के लेखकों ने एक अद्भुत काम किया, जिससे हमें यह चुनने का अवसर मिला कि हम एक तुल्यकालिक या अतुल्यकालिक पथ का चयन करके हमारे अनुप्रयोगों को सबसे अच्छा क्या मानते हैं।
पिछले अध्याय में, हमने सभी प्रकार के अनुप्रयोगों के लिए चौखटे देखे, जैसे कि एक तुल्यकालिक ग्राहक, एक तुल्यकालिक सर्वर, साथ ही साथ उनके अतुल्यकालिक विकल्प। आप अपने आवेदन के आधार पर उनमें से प्रत्येक का उपयोग कर सकते हैं। यदि प्रत्येक प्रकार के आवेदन के विवरण में तल्लीन करना आवश्यक हो जाता है, तो पर पढ़ें।
मिक्स सिंक्रोनस और एसिंक्रोनस प्रोग्रामिंग
Boost.Asio लाइब्रेरी आपको सिंक्रोनस और एसिंक्रोनस प्रोग्रामिंग को मिलाने की अनुमति देती है। व्यक्तिगत रूप से, मुझे लगता है कि यह एक बुरा विचार है, लेकिन सामान्य तौर पर C ++ की तरह Boost.Asio, यदि आप चाहते हैं तो आप अपने आप को पैर में गोली मार सकते हैं।
आप आसानी से जाल में गिर सकते हैं, खासकर यदि आपका आवेदन अतुल्यकालिक रूप से चलता है। उदाहरण के लिए, आप एक अतुल्यकालिक लिखने के संचालन के जवाब में, कहते हैं, एक अतुल्यकालिक पढ़ने के ऑपरेशन करते हैं:
io_service service; ip::tcp::socket sock(service); ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 8001); void on_write(boost::system::error_code err, size_t bytes) { char read_buff[512]; read(sock, buffer(read_buff)); } async_write(sock, buffer("echo"), on_write);
निश्चित रूप से एक सिंक्रोनस रीड ऑपरेशन वर्तमान थ्रेड को ब्लॉक करेगा, इसलिए कोई भी अन्य अधूरा एसिंक्रोनस ऑपरेशन स्टैंडबाय मोड (इस थ्रेड के लिए) में होगा। यह खराब कोड है और एप्लिकेशन को धीमा या यहां तक कि ब्लॉक करना शुरू कर सकता है (अतुल्यकालिक दृष्टिकोण का उपयोग करने का पूरा बिंदु अवरुद्ध से बचने के लिए है, इसलिए, तुल्यकालिक संचालन का उपयोग करके, आप इसे अस्वीकार करते हैं)। यदि आपके पास एक तुल्यकालिक अनुप्रयोग है, तो यह संभावना नहीं है कि आप अतुल्यकालिक पढ़ने या लिखने के संचालन का उपयोग करेंगे, क्योंकि समकालिक रूप से सोचने का अर्थ है रैखिक रूप से (ए, फिर बी, फिर सी, और इसी तरह)।
एकमात्र मामला, मेरी राय में, जब तुल्यकालिक और अतुल्यकालिक संचालन एक साथ काम कर सकते हैं, जब वे एक दूसरे से पूरी तरह से अलग होते हैं, उदाहरण के लिए, एक तुल्यकालिक नेटवर्क और डेटाबेस से इनपुट और आउटपुट के अतुल्यकालिक संचालन।
क्लाइंट से सर्वर और इसके विपरीत संदेशों की डिलीवरी
एक अच्छे क्लाइंट / सर्वर एप्लिकेशन का एक बहुत ही महत्वपूर्ण हिस्सा संदेशों की डिलीवरी आगे और पीछे (सर्वर से क्लाइंट और क्लाइंट से सर्वर तक) है। आपको यह निर्दिष्ट करना होगा कि क्या संदेश की पहचान करता है। दूसरे शब्दों में, जब एक आने वाले संदेश को पढ़ा जा रहा है, तो हम कैसे जान सकते हैं कि संदेश पूरी तरह से पढ़ा गया है?
आपको संदेश के अंत को निर्धारित करने की आवश्यकता है (शुरुआत निर्धारित करना आसान है, यह अंतिम संदेश के अंत के बाद प्राप्त पहली बाइट है), लेकिन आप देखेंगे कि यह इतना आसान नहीं है।
आप कर सकते हैं:
- एक निश्चित आकार का संदेश बनाना (यह एक अच्छा विचार नहीं है? जब आपको अधिक डेटा भेजने की आवश्यकता हो तो क्या करें?)
- संदेश को समाप्त करने वाला एक विशिष्ट वर्ण बनाएं, जैसे '\ n' या '\ 0'
- संदेश की लंबाई को संदेश उपसर्ग के रूप में निर्दिष्ट करें, और इसी तरह।
पुस्तक के दौरान, मैंने प्रत्येक संदेश के अंत के रूप में "\ n 'वर्ण का उपयोग करने का निर्णय लिया।" इसलिए, संदेश पढ़ना निम्नलिखित कोड टुकड़ा प्रदर्शित करेगा:
char buff_[512];
पाठक के लिए एक अभ्यास के रूप में संदेश उपसर्ग के रूप में लंबाई का संकेत छोड़ना काफी आसान है।
ग्राहक अनुप्रयोगों में सिंक्रोनस I / O
एक नियम के रूप में, तुल्यकालिक ग्राहक दो प्रकार के होते हैं:
- यह सर्वर से कुछ अनुरोध करता है, पढ़ता है और प्रतिक्रिया को संसाधित करता है। फिर यह कुछ और मांगता है। यह अनिवार्य रूप से एक तुल्यकालिक ग्राहक है, जिसकी चर्चा पिछले अध्याय में की गई थी।
- सर्वर से एक आने वाले संदेश को पढ़ता है, इसे संसाधित करता है और एक प्रतिक्रिया लिखता है। फिर यह अगले आने वाले संदेश को पढ़ता है और इसी तरह।
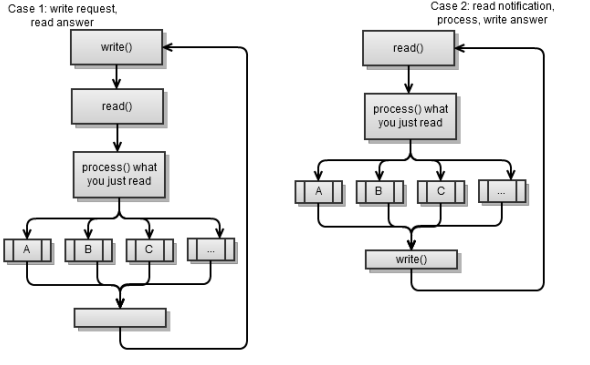
दोनों परिदृश्य निम्नलिखित रणनीति का उपयोग करते हैं: एक अनुरोध करें - प्रतिक्रिया पढ़ें। दूसरे शब्दों में, एक पक्ष एक अनुरोध करता है, जिस पर दूसरा पक्ष प्रतिक्रिया देता है। यह क्लाइंट / सर्वर एप्लिकेशन को लागू करने का एक आसान तरीका है और यही मैं आपको सलाह देता हूं।
आप हमेशा एक Mambo Jambo क्लाइंट / सर्वर बना सकते हैं, जहां प्रत्येक पक्ष आपको जब चाहे लिख सकता है, लेकिन यह बहुत संभावना है कि यह पथ आपदा की ओर ले जाएगा (क्लाइंट या सर्वर अवरुद्ध होने पर आपको कैसे पता चलेगा कि क्या हुआ है?)।
पिछली स्क्रिप्ट समान दिख सकती हैं, लेकिन वे बहुत अलग हैं:
- पहले मामले में, सर्वर अनुरोधों का जवाब देता है (सर्वर ग्राहकों से अनुरोधों की प्रतीक्षा करता है और उनका जवाब देता है)। यह एक पुल-जैसा कनेक्शन है जब क्लाइंट को सर्वर से अनुरोध पर इसकी आवश्यकता होती है।
- बाद के मामले में, सर्वर क्लाइंट घटनाओं को भेजता है जिस पर वह प्रतिक्रिया करता है। यह एक पुश-जैसा कनेक्शन है जब सर्वर क्लाइंट्स को नोटिफिकेशन / इवेंट्स पुश करता है।
मूल रूप से, आप पुल-जैसे क्लाइंट / सर्वर एप्लिकेशनों में आएंगे जो विकास को आसान बनाते हैं, साथ ही साथ आमतौर पर आदर्श भी।
आप इन दोनों दृष्टिकोणों को मिला सकते हैं: मांग (क्लाइंट-सर्वर) पर जाएं और अनुरोध (सर्वर-क्लाइंट) को धक्का दें, हालांकि, यह मुश्किल है और इससे बचना बेहतर है। इन दोनों दृष्टिकोणों को मिलाने की समस्या है; यदि आप अनुरोध करने के लिए रणनीति का उपयोग करते हैं, तो उत्तर पढ़ें; निम्नलिखित हो सकता है:
- ग्राहक लिखता है (एक अनुरोध करता है)
- सर्वर लिखता है (ग्राहक को एक सूचना भेजता है)
- क्लाइंट पढ़ता है कि सर्वर ने क्या लिखा है और इसके अनुरोध की प्रतिक्रिया के रूप में इसकी व्याख्या करता है
- सर्वर क्लाइंट से प्रतिक्रिया की प्रतीक्षा कर रहा है जो क्लाइंट के नए अनुरोध के आने पर आएगा
- ग्राहक लिखता है (एक नया अनुरोध करता है)
- सर्वर इस अनुरोध की व्याख्या करेगा क्योंकि वह प्रतिक्रिया का इंतजार कर रहा था
- क्लाइंट अवरुद्ध है (सर्वर रिटर्न प्रतिसाद नहीं भेजता है क्योंकि उसने ग्राहक के अनुरोध को उसकी अधिसूचना के जवाब के रूप में व्याख्या किया है)।
पुल-जैसे क्लाइंट / सर्वर एप्लिकेशन में, पिछले परिदृश्य को आसानी से टाला जा सकता है। जब ग्राहक हर 5 सेकेंड में सर्वर से कनेक्शन की जांच करता है, तो आप पिंग प्रक्रिया को लागू करके पुश-अप व्यवहार का अनुकरण कर सकते हैं। यदि सूचना के लिए कुछ भी नहीं है, तो सर्वर ping_ok जैसी किसी चीज़ के साथ प्रतिक्रिया कर सकता है, या ping_ [event_name] हो। तब ग्राहक इस घटना को संभालने के लिए एक नया अनुरोध शुरू कर सकता है।
फिर, पिछली स्क्रिप्ट पिछले अध्याय से सिंक्रोनस क्लाइंट का चित्रण करती है। इसका मुख्य लूप:
void loop() {
अंतिम परिदृश्य को फिट करने के लिए मुझे इसे बदलने दें:
void loop() { while ( started_) { read_notification(); write_answer(); } } void read_notification() { already_read_ = 0; read(sock_, buffer(buff_), boost::bind(&talk_to_svr::read_complete, this, _1, _2)); process_notification(); } void process_notification() {
सर्वर एप्लिकेशन में सिंक्रोनस I / O
ग्राहक, जैसे ग्राहक, दो प्रकार के होते हैं, वे पिछले अनुभाग से दो परिदृश्यों के अनुरूप होते हैं। फिर से, दोनों परिदृश्य एक रणनीति का उपयोग करते हैं: एक अनुरोध बनाएं - प्रतिक्रिया पढ़ें।
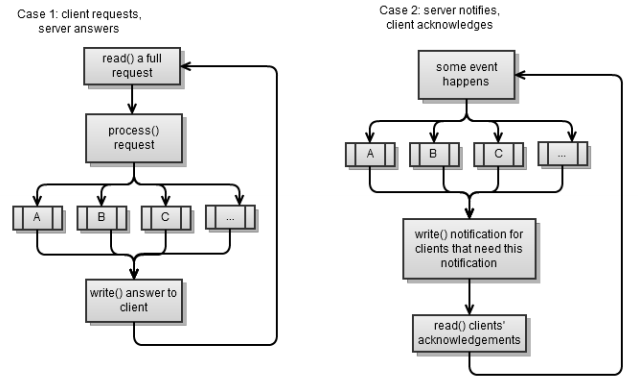
पहला परिदृश्य एक तुल्यकालिक सर्वर है, जिसे हमने पिछले
अध्याय में लागू किया था। अनुरोध को पूरी तरह से पढ़ना आसान नहीं है यदि आप समकालिक रूप से काम कर रहे हैं, क्योंकि आप अवरुद्ध होने से बचना चाहते हैं (आप हमेशा उतना ही पढ़ें जितना आप कर सकते हैं)।
void read_request() { if ( sock_.available()) already_read_ += sock_.read_some(buffer(buff_ + already_read_, max_msg –already_read_)); }
संदेश को पूरी तरह से पढ़ने के बाद, हम बस इसे प्रोसेस करते हैं और क्लाइंट को जवाब देते हैं:
void process_request() { bool found_enter = std::find(buff_, buff_ + already_read_, '\n') < buff_ + already_read_; if ( !found_enter) return;
यदि हम चाहते थे कि हमारा सर्वर एक पुश-जैसा सर्वर बन जाए, तो हम इसे इस प्रकार बदल देंगे:
typedef std::vector<client_ptr> array; array clients; array notify; std::string notify_msg; void on_new_client() {
on_new_client() फ़ंक्शन एक घटना का एक फ़ंक्शन है, जहां हमें सभी ग्राहकों को इसके बारे में सूचित करना चाहिए।
notify_clients एक फ़ंक्शन है जो उन ग्राहकों को सूचित करेगा जो इस ईवेंट के लिए सब्सक्राइब किए गए हैं। सर्वर एक संदेश भेजता है, लेकिन प्रत्येक क्लाइंट से प्रतिक्रिया की प्रतीक्षा नहीं करता है, क्योंकि इससे अवरोध उत्पन्न हो सकता है। जब ग्राहक की प्रतिक्रिया आती है, तो ग्राहक हमें बता सकता है कि यह हमारी अधिसूचना का उत्तर है (और हम इसे सही तरीके से संसाधित कर सकते हैं)।
एक सिंक्रोनस सर्वर में थ्रेड्स
यह एक बहुत ही महत्वपूर्ण कारक है: ग्राहक प्रसंस्करण के लिए हम कितने धागे आवंटित करेंगे?
एक तुल्यकालिक सर्वर के लिए, हमें कम से कम एक थ्रेड की आवश्यकता होती है जो नए कनेक्शनों को संभालेगा:
void accept_thread() { ip::tcp::acceptor acceptor(service, ip::tcp::endpoint(ip::tcp::v4(),8001)); while ( true) { client_ptr new_( new talk_to_client); acceptor.accept(new_->sock()); boost::recursive_mutex::scoped_lock lk(cs); clients.push_back(new_); } }
मौजूदा ग्राहकों के लिए:
- हम एक-तरफ़ा जा सकते हैं। यह सबसे आसान तरीका है और हमने इसे चुना जब हमने अध्याय 4 में सिंक्रोनस सर्वर को लागू किया। यह आसानी से 100-200 एक साथ कनेक्शन का सामना करता है, और कभी-कभी यह अधिक हो सकता है, जो कि अधिकांश मामलों के लिए पर्याप्त है।
- हम प्रत्येक ग्राहक के लिए एक प्रवाह बना सकते हैं। यह बहुत कम ही एक अच्छा विकल्प है, यह बहुत सारे धागे खर्च करेगा, जिससे कभी-कभी डिबगिंग मुश्किल हो जाती है, और हालांकि यह संभवतः 200 से अधिक समवर्ती उपयोगकर्ताओं को संभाल लेगा, यह जल्द ही अपनी सीमा तक पहुंच जाएगा।
- हम मौजूदा ग्राहकों को संभालने के लिए निश्चित संख्या में धागे बना सकते हैं।
तीसरा विकल्प एक तुल्यकालिक सर्वर में लागू करना बहुत मुश्किल है। संपूर्ण
talk_to_client वर्ग थ्रेड सुरक्षित हो गया है। फिर आपको यह जानने के लिए एक विशेष तंत्र की आवश्यकता होगी कि कौन से धागे किस क्लाइंट की प्रक्रिया करते हैं। इसके लिए आपके पास दो विकल्प हैं:
- एक विशिष्ट क्लाइंट को एक विशिष्ट थ्रेड को असाइन करें; उदाहरण के लिए, पहला धागा पहले 20 ग्राहकों को संसाधित करता है, दूसरा धागा ग्राहकों को 21 से 40 तक संसाधित करता है, और इसी तरह। जब कोई ग्राहक उपयोग में होता है, तो हम उसे कई मौजूदा ग्राहकों से निकालते हैं। इस क्लाइंट के साथ काम करने के बाद, हमने उसे सूची में वापस रखा। प्रत्येक थ्रेड सभी मौजूदा क्लाइंट के माध्यम से साइकिल करेगा, और पहले ग्राहक को एक पूर्ण अनुरोध के साथ प्रोसेस करने के लिए ले जाएगा (हम क्लाइंट से आने वाले संदेश को पूरी तरह से पढ़ें) और उस पर प्रतिक्रिया दें।
- सर्वर जवाब देना बंद कर सकता है:
- पहले मामले में, एक थ्रेड में संसाधित कई क्लाइंट एक साथ अनुरोध बनाते हैं, और एक थ्रेड एक समय में केवल एक अनुरोध को संसाधित कर सकता है। हालाँकि, हम इस मामले में कुछ नहीं कर सकते।
- दूसरे मामले में, हम एक साथ अधिक अनुरोध प्राप्त करते हैं कि हमारे पास थ्रेड्स हैं। इस मामले में, हम लोड को संभालने के लिए बस नए थ्रेड बना सकते हैं।
निम्न कोड, जो मूल
answer_to_client फ़ंक्शन के समान है, दिखाता है कि अंतिम स्क्रिप्ट को कैसे लागू किया जा सकता है:
struct talk_to_client : boost::enable_shared_from_this<talk_to_client> { ... void answer_to_client() { try { read_request(); process_request(); } catch ( boost::system::system_error&) { stop(); } } };
हम इसे नीचे दिखाए अनुसार संशोधित करेंगे:
struct talk_to_client : boost::enable_shared_from_this<talk_to_client> { boost::recursive_mutex cs; boost::recursive_mutex cs_ask; bool in_process; void answer_to_client() { { boost::recursive_mutex::scoped_lock lk(cs_ask); if ( in_process) return; in_process = true; } { boost::recursive_mutex::scoped_lock lk(cs); try { read_request(); process_request(); } catch ( boost::system::system_error&) { stop(); } } { boost::recursive_mutex::scoped_lock lk(cs_ask); in_process = false; } } };
जब हम ग्राहक को संसाधित करेंगे, तो इसका
in_process उदाहरण
true सेट हो जाएगा, और अन्य थ्रेड्स इस क्लाइंट को अनदेखा कर देंगे। एक अतिरिक्त बोनस यह है कि
handle_clients_thread() फ़ंक्शन को संशोधित नहीं किया जा सकता है; जैसा आप चाहते हैं, आप केवल कई
handle_clients_thread() फ़ंक्शन बना सकते हैं।
ग्राहक अनुप्रयोगों में एसिंक्रोनस I / O
मुख्य कार्यप्रवाह कुछ हद तक तुल्यकालिक क्लाइंट अनुप्रयोग में समान प्रक्रिया के समान है, जिसमें अंतर यह है कि Boost.Asio प्रत्येक
async_write और
async_write बीच है।
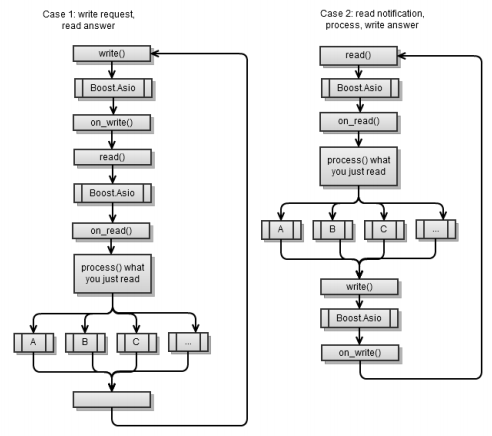
पहला परिदृश्य वैसा ही है जैसा कि
अध्याय 4 में अतुल्यकालिक ग्राहक को लागू किया गया था। याद रखें कि प्रत्येक एसिंक्रोनस ऑपरेशन के अंत में, आपको एक और एसिंक्रोनस ऑपरेशन शुरू करना होगा ताकि
service.run() फ़ंक्शन अपनी गतिविधि को समाप्त न करे।
पहले परिदृश्य को दूसरे पर लाने के लिए, हमें निम्नलिखित कोड के टुकड़े का उपयोग करना होगा:
void on_connect() { do_read(); } void do_read() { async_read(sock_, buffer(read_buffer_), MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2)); } void on_read(const error_code & err, size_t bytes) { if ( err) stop(); if ( !started() ) return; std::string msg(read_buffer_, bytes); if ( msg.find("clients") == 0) on_clients(msg); else ... } void on_clients(const std::string & msg) { std::string clients = msg.substr(8); std::cout << username_ << ", new client list:" << clients ; do_write("clients ok\n"); }
कृपया ध्यान दें कि जैसे ही आप सफलतापूर्वक कनेक्ट होते हैं, आप सर्वर से पढ़ना शुरू कर देते हैं। प्रत्येक
on_[event] फ़ंक्शन इसे पूरा करता है और सर्वर पर प्रतिक्रिया लिखता है।
अतुल्यकालिक दृष्टिकोण की सुंदरता यह है कि आप यह सब व्यवस्थित करने के लिए Boost.Asio का उपयोग करके किसी भी अन्य अतुल्यकालिक संचालन के साथ नेटवर्क I / O को मिला सकते हैं। भले ही स्ट्रीम एक सिंक्रोनस स्ट्रीम के रूप में स्पष्ट नहीं है, आप व्यावहारिक रूप से इसे सिंक्रोनस के रूप में सोच सकते हैं।
कहते हैं कि आप एक वेब सर्वर से एक फ़ाइल पढ़ते हैं और इसे एक डेटाबेस (अतुल्यकालिक) में सहेजते हैं। आप इसके बारे में व्यावहारिक रूप से सोच सकते हैं, जैसा कि निम्नलिखित फ़्लोचार्ट में दिखाया गया है:

सर्वर अनुप्रयोगों में एसिंक्रोनस I / O
फिर से सर्वव्यापी दो मामलों में, पहली स्क्रिप्ट (पुल) और दूसरी स्क्रिप्ट (पुश):

पहला अतुल्यकालिक सर्वर स्क्रिप्ट पिछले
अध्याय में लागू किया गया था। प्रत्येक एसिंक्रोनस ऑपरेशन के अंत में, आपको एक और एसिंक्रोनस ऑपरेशन शुरू करना होगा ताकि
service.run() समाप्त न हो।
यहां कोड फ्रेमवर्क है जिसे ट्रिम कर दिया गया है। निम्नलिखित सभी सदस्य
talk_to_client वर्ग के हैं:
void start() { ... do_read();
संक्षेप में, हम हमेशा एक रीड ऑपरेशन के लिए प्रतीक्षा करते हैं, जैसे ही यह पूरा हो जाता है, हम संदेश को संसाधित करते हैं और क्लाइंट को वापस जवाब देते हैं।
पिछले कोड को पुश सर्वर में बदलें:
void start() { ... on_new_client_event(); } void on_new_client_event() { std::ostringstream msg; msg << "client count " << clients.size(); for ( array::const_iterator b = clients.begin(), e = clients.end();b != e; ++b) (*b)->do_write(msg.str()); } void on_read(const error_code & err, size_t bytes) { std::string msg(read_buffer_, bytes);
जब कोई घटना
on_new_client_event , तो
on_new_client_event कहना है, उन सभी ग्राहकों को संदेश भेजे जाएंगे जिन्हें इस घटना के बारे में सूचित करने की आवश्यकता है। जब वे जवाब देंगे, तो हम समझेंगे कि उन्होंने प्राप्त कार्यक्रम को संसाधित किया। कृपया ध्यान दें कि हम कभी भी अतुल्यकालिक रूप से घटनाओं की प्रतीक्षा नहीं करेंगे (इसलिए
service.run() काम करना समाप्त नहीं करेगा), क्योंकि हम हमेशा नए ग्राहकों की प्रतीक्षा कर रहे हैं।
एक एसिंक्रोनस सर्वर में थ्रेड्स
एसिंक्रोनस सर्वर को अध्याय 4 में दिखाया गया था, यह एकल-थ्रेडेड है, क्योंकि सब कुछ
main() फ़ंक्शन में होता है:
int main() { talk_to_client::ptr client = talk_to_client::new_(); acc.async_accept(client->sock(), boost::bind(handle_accept,client,_1)); service.run(); }
अतुल्यकालिक दृष्टिकोण की सुंदरता एक एकल-थ्रेडेड से बहु-थ्रेडेड संस्करण में संक्रमण की आसानी है। आप हमेशा एक-तरफा जा सकते हैं, कम से कम जब तक आपके ग्राहक एक ही समय में 200 से अधिक नहीं होते हैं। फिर, एक धागे से 100 धागे पर स्विच करने के लिए, आपको निम्नलिखित कोड टुकड़े का उपयोग करना होगा:
boost::thread_group threads; void listen_thread() { service.run(); } void start_listen(int thread_count) { for ( int i = 0; i < thread_count; ++i) threads.create_thread( listen_thread); } int main(int argc, char* argv[]) { talk_to_client::ptr client = talk_to_client::new_(); acc.async_accept(client->sock(), boost::bind(handle_accept,client,_1)); start_listen(100); threads.join_all(); }
बेशक, एक बार जब आप मल्टी-थ्रेडिंग का उपयोग करना शुरू करते हैं, तो आपको थ्रेड-सेफ के बारे में सोचना चाहिए। यहां तक कि अगर आप थ्रेड A पर
async_* कहते हैं, तो इसे पूरा करने की प्रक्रिया को थ्रेड बी (जब तक थ्रेड बी कॉल
service.run() ) कहा जा सकता है। यह अपने आप में कोई समस्या नहीं है। जब तक आप तार्किक अनुक्रम का पालन करते हैं,
on_read() ,
on_read() async_read() से
on_read() ,
on_read() से
process_reques t,
process_request से
async_write() ,
async_write() से
on_write() तक
on_write() से
async_read() और कोई
public फ़ंक्शन नहीं हैं जो आपके
talk_to_client वर्ग को कॉल करेंगे, हालांकि विभिन्न कार्यों को अलग-अलग थ्रेड पर कहा जा सकता है, फिर भी उन्हें क्रमिक रूप से कहा जाएगा। इस प्रकार, म्यूटेक्स की आवश्यकता नहीं है।
हालांकि, इसका मतलब है कि क्लाइंट के लिए केवल एक अतुल्यकालिक ऑपरेशन लंबित हो सकता है। यदि किसी बिंदु पर क्लाइंट के पास दो लंबित असिंक्रोनस फ़ंक्शन हैं, तो आपको म्यूटेक्स की आवश्यकता होगी। क्योंकि दो लंबित ऑपरेशन एक ही समय में पूरा हो सकते हैं, और अंततः हम उनके हैंडलर को एक साथ दो अलग-अलग थ्रेड्स में कॉल कर सकते हैं। इस प्रकार, थ्रेड-सेफ की आवश्यकता है, इस प्रकार म्यूटेक्स।
हमारे अतुल्यकालिक सर्वर में, वास्तव में एक ही समय में दो लंबित संचालन हैं:
void do_read() { async_read(sock_, buffer(read_buffer_), MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2)); post_check_ping(); } void post_check_ping() { timer_.expires_from_now(boost::posix_time::millisec(5000)); timer_.async_wait( MEM_FN(on_check_ping)); }
रीड ऑपरेशन करते समय, हम एक निश्चित अवधि के लिए अतुल्यकालिक रूप से इसके पूरा होने की प्रतीक्षा करेंगे। इस प्रकार, थ्रेड-सेफ की आवश्यकता है। मेरी सलाह है, यदि आप एक बहु-थ्रेडेड विकल्प चुनने की योजना बनाते हैं, तो अपनी कक्षा को शुरू से ही सुरक्षित रखें। यह आमतौर पर प्रदर्शन को चोट नहीं पहुंचाता है (आप निश्चित रूप से इसे देख सकते हैं)। इसके अलावा, यदि आप एक मल्टी-स्ट्रीम पथ पर जाने की योजना बनाते हैं, तो शुरुआत से ही इसका पालन करें। इस प्रकार, आप एक प्रारंभिक चरण में संभावित समस्याओं का सामना करेंगे। जैसे ही आपको कोई समस्या मिलती है, पहली चीज जिसे आपको जांचना चाहिए वह एक चल रहे धागे के साथ हो रहा है? यदि हाँ, तो यह आसान है, बस डिबग करें। अन्यथा, आप शायद किसी फ़ंक्शन को म्यूटेक्स करना भूल गए।
चूँकि हमारे उदाहरण के लिए थ्रेड-सेफ़ की आवश्यकता है, इसलिए हमने
talk_to_client का उपयोग करके talk_to_client को बदल दिया। इसके अलावा, हमारे पास ग्राहकों की एक सरणी है, जिसे हम कोड में कई बार संदर्भित करते हैं, जिसे अपने स्वयं के म्यूटेक्स की भी आवश्यकता होती है।
गतिरोध और स्मृति भ्रष्टाचार से बचना इतना सरल नहीं है। यहां बताया गया है कि
update_clients_changed() फ़ंक्शन को कैसे बदलना है:
void update_clients_changed() { array copy; { boost::recursive_mutex::scoped_lock lk(clients_cs); copy = clients; } for( array::iterator b = copy.begin(), e = copy.end(); b != e; ++b) (*b)->set_clients_changed(); }
हम जो बचना चाहते हैं वह यह है कि दो म्यूटेक्स एक ही समय में बंद हो जाते हैं (जिससे गतिरोध की स्थिति बन सकती है)। हमारे मामले में, हम नहीं चाहते हैं कि एक ही समय में
clients_cs और क्लाइंट
cs_ म्यूटेक्स को लॉक किया जाए।
अतुल्यकालिक संचालन
Boost.Asio आपको अपने किसी भी कार्य को एसिंक्रोनस रूप से करने की अनुमति देता है। बस निम्नलिखित कोड स्निपेट का उपयोग करें:
void my_func() { ... } service.post(my_func);
आप यह सत्यापित कर सकते हैं कि
my_func उन थ्रेड्स में से एक पर कॉल किया जाता है, जो
service.run() । आप एसिंक्रोनस फ़ंक्शन को भी चला सकते हैं और एक अनुगामी हैंडलर बना सकते हैं जो आपको बताता है कि फ़ंक्शन कब पूरा होगा। छद्मकोड इस तरह दिखेगा:
void on_complete() { ... } void my_func() { ... service.post(on_complete); } async_call(my_func);
कोई
async_call फ़ंक्शन नहीं है, आपको अपना खुद का बनाना होगा। सौभाग्य से, यह इतना मुश्किल नहीं है। निम्नलिखित कोड स्निपेट देखें:
struct async_op : boost::enable_shared_from_this<async_op>, ... { typedef boost::function<void(boost::system::error_code)> completion_func; typedef boost::function<boost::system::error_code ()> op_func; struct operation { ... }; void start() { { boost::recursive_mutex::scoped_lock lk(cs_); if ( started_) return; started_ = true; } boost::thread t( boost::bind(&async_op::run,this)); } void add(op_func op, completion_func completion, io_service &service) { self_ = shared_from_this(); boost::recursive_mutex::scoped_lock lk(cs_); ops_.push_back( operation(service, op, completion)); if ( !started_) start(); } void stop() { boost::recursive_mutex::scoped_lock lk(cs_); started_ = false; ops_.clear(); } private: boost::recursive_mutex cs_; std::vector<operation> ops_; bool started_; ptr self_; };
async_op संरचना में, एक बैकग्राउंड थ्रेड बनाया जाता है जो आपके द्वारा जोड़े जाने वाले सभी एसिंक्रोनस फ़ंक्शंस के साथ काम करेगा (
run() )। मेरे लिए, यह कुछ जटिल नहीं लगता है, क्योंकि प्रत्येक ऑपरेशन के लिए निम्न कार्य किया जाता है:
- फ़ंक्शन को अतुल्यकालिक रूप से कहा जाता है।
completion फ़ंक्शन को पहली बार फ़ंक्शन पूरा completion को कहा जाता है- वह उदाहरण
io_serviceजो completionकार्य करेगा । यह वह स्थान है जहाँ आपको पूरा होने की सूचना दी जाएगी। निम्नलिखित कोड स्निपेट देखें:
struct async_op : boost::enable_shared_from_this<async_op> , private boost::noncopyable { struct operation { operation(io_service & service, op_func op, completion_func completion): service(&service), op(op)completion(completion), work(new o_service::work(service)){} operation() : service(0) {} io_service * service; op_func op; completion_func completion; typedef boost::shared_ptr<io_service::work> work_ptr; work_ptr work; }; ... };
कृपया ध्यान दें कि जब ऑपरेशन पूरा नहीं हुआ है, हम उदाहरण का निर्माण कर रहे हैं io_service::work, इसलिए service.run()जब तक हमने अपना अतुल्यकालिक कॉल पूरा नहीं किया है, तब तक इस पर अपना काम समाप्त नहीं होता है (जब तक io_service::work, service.run()कि यह जीवित है, यह मान जाएगा कि यह काम कर चुका है)। निम्नलिखित कोड पर एक नज़र डालें: struct async_op : ... { typedef boost::shared_ptr<async_op> ptr; static ptr new_() { return ptr(new async_op); } ... void run() { while ( true) { { boost::recursive_mutex::scoped_lock lk(cs_); if ( !started_) break; } boost::this_thread::sleep( boost::posix_time::millisec(10)); operation cur; { boost::recursive_mutex::scoped_lock lk(cs_); if ( !ops_.empty()) { cur = ops_[0]; ops_.erase( ops_.begin()); } } if ( cur.service) cur.service->post(boost::bind(cur.completion, cur.op() )); } self_.reset(); } };
run()पृष्ठभूमि थ्रेड में काम करने वाला फ़ंक्शन यह देखने के लिए देखता है कि क्या यह करने के लिए काम है; यदि हां, तो यह बदले में अतुल्यकालिक कार्य करता है। प्रत्येक कॉल के अंत में, यह संबंधित समाप्ति फ़ंक्शन को कॉल करता है।इसे सत्यापित करने के लिए, हम एक फ़ंक्शन बनाएंगे जो compute_file_checksumअतुल्यकालिक रूप से निष्पादित करेगा: size_t checksum = 0; boost::system::error_code compute_file_checksum(std::string file_name) { HANDLE file = ::CreateFile(file_name.c_str(), GENERIC_READ, 0, 0, OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED, 0); windows::random_access_handle h(service, file); long buff[1024]; checksum = 0; size_t bytes = 0, at = 0; boost::system::error_code ec; while ( (bytes = read_at(h, at, buffer(buff), ec)) > 0) { at += bytes; bytes /= sizeof(long); for ( size_t i = 0; i < bytes; ++i) checksum += buff[i]; } return boost::system::error_code(0, boost::system::generic_category()); } void on_checksum(std::string file_name, boost::system::error_code) { std::cout << "checksum for " << file_name << "=" << checksum << std::endl; } int main(int argc, char* argv[]) { std::string fn = "readme.txt"; async_op::new_()->add( service, boost::bind(compute_file_checksum,fn), boost::bind(on_checksum,fn,_1)); service.run(); }
ध्यान दें कि मैंने अभी-अभी आपको असिंक्रोनस रूप से फ़ंक्शन कॉल का संभावित कार्यान्वयन कैसे दिखाया। एक पृष्ठभूमि धागा लागू करने के बजाय, जैसा कि मैंने किया था, आप एक आंतरिक उदाहरण io_serviceका उपयोग कर सकते हैं जिसे आप भेजते हैं ( post()) एक अतुल्यकालिक फ़ंक्शन कॉल। इसे हम पाठक के लिए एक अभ्यास के रूप में छोड़ दें।आप अतुल्यकालिक कार्य की प्रगति दिखाने के लिए वर्ग का विस्तार भी कर सकते हैं (उदाहरण के लिए, प्रतिशत में)। इस मामले में, आप प्रगति बार में प्रगति को मुख्य धारा में दिखा सकते हैं।प्रॉक्सी कार्यान्वयन
एक प्रॉक्सी आमतौर पर क्लाइंट और सर्वर के बीच स्थित होती है। यह क्लाइंट से एक अनुरोध प्राप्त करता है, इसे बदल सकता है, और इसे सर्वर पर भेजता है। फिर वह सर्वर से प्रतिक्रिया लेता है, इसे बदल सकता है, और क्लाइंट को भेजता है।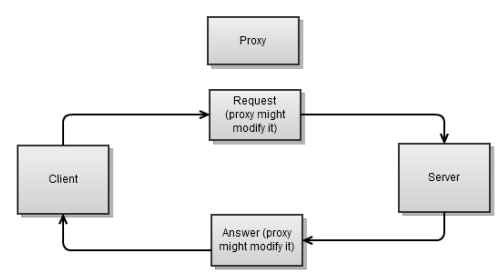 प्रॉक्सी सर्वर की विशेष विशेषता क्या है? हमारे उद्देश्यों के लिए, हमारे पास प्रत्येक कनेक्शन के लिए दो सॉकेट होंगे, एक क्लाइंट के लिए, दूसरा सर्वर के लिए। यह प्रॉक्सी के कार्यान्वयन को थोड़ा जटिल करता है।एक तुल्यकालिक अनुप्रयोग के लिए एक प्रॉक्सी को लागू करना एक अतुल्यकालिक के लिए की तुलना में अधिक जटिल होगा; डेटा दोनों सिरों (क्लाइंट और सर्वर से) से आ सकता है, उसी समय, डेटा उन दोनों (क्लाइंट और सर्वर) को भेजा जा सकता है। इसका अर्थ है कि यदि हम सिंक्रोनस विकल्प चुनते हैं, तो हम एक ओर पढ़ना या लिखना बंद कर सकते हैं, जबकि हमें दूसरी ओर पढ़ना या लिखना होगा, जिसका अर्थ है कि हम एक छोर पर जवाब देना बंद कर देंगे।एक एसिंक्रोनस प्रॉक्सी के सरल उदाहरण में निम्नलिखित बिंदुओं पर विचार करें:
प्रॉक्सी सर्वर की विशेष विशेषता क्या है? हमारे उद्देश्यों के लिए, हमारे पास प्रत्येक कनेक्शन के लिए दो सॉकेट होंगे, एक क्लाइंट के लिए, दूसरा सर्वर के लिए। यह प्रॉक्सी के कार्यान्वयन को थोड़ा जटिल करता है।एक तुल्यकालिक अनुप्रयोग के लिए एक प्रॉक्सी को लागू करना एक अतुल्यकालिक के लिए की तुलना में अधिक जटिल होगा; डेटा दोनों सिरों (क्लाइंट और सर्वर से) से आ सकता है, उसी समय, डेटा उन दोनों (क्लाइंट और सर्वर) को भेजा जा सकता है। इसका अर्थ है कि यदि हम सिंक्रोनस विकल्प चुनते हैं, तो हम एक ओर पढ़ना या लिखना बंद कर सकते हैं, जबकि हमें दूसरी ओर पढ़ना या लिखना होगा, जिसका अर्थ है कि हम एक छोर पर जवाब देना बंद कर देंगे।एक एसिंक्रोनस प्रॉक्सी के सरल उदाहरण में निम्नलिखित बिंदुओं पर विचार करें:- हमारे मामले में, हम जानते हैं कि दोनों कनेक्शन स्थापित हैं। यह हमेशा ऐसा नहीं होता है, उदाहरण के लिए, वेब प्रॉक्सी के लिए, क्लाइंट हमें सर्वर का पता बताता है।
- सादगी के लिए, निम्नलिखित कोड टुकड़े पर विचार करें, यह थ्रेड-सुरक्षित नहीं है:
class proxy : public boost::enable_shared_from_this<proxy> { proxy(ip::tcp::endpoint ep_client, ip::tcp::endpoint ep_server) : ... {} public: static ptr start(ip::tcp::endpoint ep_client, ip::tcp::endpoint ep_svr) { ptr new_(new proxy(ep_client, ep_svr));
यह एक बहुत ही सरल छंद है। दोनों सिरों पर जुड़े होने पर, यह दोनों कनेक्शन (फ़ंक्शन on_start()) पर पढ़ना शुरू कर देता है : class proxy : public boost::enable_shared_from_this<proxy> { ... void on_read(ip::tcp::socket & sock, const error_code& err, size_t bytes) { char * buff = &sock == &client_ ? buff_client_ : buff_server_; do_write(&sock == &client_ ? server_ : client_, buff, bytes); } void on_write(ip::tcp::socket & sock, const error_code &err, size_t bytes) { if ( &sock == &client_) do_read(server_, buff_server_); else do_read(client_, buff_client_); } void do_read(ip::tcp::socket & sock, char* buff) { async_read(sock, buffer(buff, max_msg), MEM_FN3(read_complete,ref(sock),_1,_2), MEM_FN3(on_read,ref(sock),_1,_2)); } void do_write(ip::tcp::socket & sock, char * buff, size_t size) { sock.async_write_some(buffer(buff,size), MEM_FN3(on_write,ref(sock),_1,_2)); } size_t read_complete(ip::tcp::socket & sock, const error_code & err, size_t bytes) { if ( sock.available() > 0) return sock.available(); return bytes > 0 ? 0 : 1; } };
प्रत्येक सफल पढ़ने (on_read) के बाद, यह संदेश को दूसरी तरफ भेजता है। एक बार संदेश सफलतापूर्वक प्रसारित (on_write) हो जाने के बाद, हम फिर से पढ़ना शुरू करते हैं।इसे काम करने के लिए, निम्नलिखित कोड स्निपेट का उपयोग करें: int main(int argc, char* argv[]) { ip::tcp::endpoint ep_c( ip::address::from_string("127.0.0.1"), 8001); ip::tcp::endpoint ep_s( ip::address::from_string("127.0.0.1"), 8002); proxy::start(ep_c, ep_s); service.run(); }
आपने देखा है कि मैं पढ़ने और लिखने के लिए बफ़र्स ( buff_client_और buff_server_) का पुन: उपयोग कर रहा हूं । यह पुन: उपयोग सामान्य है क्योंकि क्लाइंट से पढ़ा गया संदेश सर्वर से लिखा जाता है इससे पहले कि नया संदेश क्लाइंट से पढ़ा जाए और इसके विपरीत। इसका यह भी अर्थ है कि यह विशेष कार्यान्वयन एक लाइव प्रतिक्रिया समस्या से ग्रस्त है। जब हम साइड बी पर रिकॉर्डिंग की प्रक्रिया में हैं, हम साइड ए से नहीं पढ़ रहे हैं (हम साइड बी पर लिखने के ऑपरेशन पूरा होने के बाद साइड ए से पढ़ना शुरू करते हैं)। आप इन चरणों का पालन करके इस समस्या को दूर करने के लिए कार्यान्वयन को बदल सकते हैं:- पढ़ने के लिए आपको कई बफ़र्स का उपयोग करना चाहिए।
- प्रत्येक सफल रीड ऑपरेशन के बाद, दूसरी तरफ एसिंक्रोनस लिखने के अलावा, एक अतिरिक्त एसिंक्रोनस रीड (एक नए बफर में) करें।
- प्रत्येक सफल लेखन ऑपरेशन के बाद, बफर को नष्ट (या पुन: उपयोग) करें।
इसे आप के लिए एक व्यायाम के रूप में छोड़ दें।सारांश
किस दिशा में जाना है, यह तय करते समय कई और बातें हैं: सिंक्रोनस या एसिंक्रोनस।इस अध्याय में हमने जाँच की:- प्रत्येक प्रकार के आवेदन को आसानी से कैसे लागू करें, परीक्षण करें और डिबग करें
- धागे आपके आवेदन को कैसे प्रभावित करते हैं
- एप्लिकेशन व्यवहार (पुल-लाइक या पुश-लाइक) इसके कार्यान्वयन को कैसे प्रभावित करता है
- जब आप एक अतुल्यकालिक अनुप्रयोग को लागू करते हैं तो आप अपने स्वयं के अतुल्यकालिक संचालन को कैसे जोड़ सकते हैं
आगे, हम Boost.Asio की कई जानी-मानी विशेषताओं के साथ-साथ Boost.Asio की मेरी पसंदीदा विशेषता पर विचार करने जा रहे हैं - co-routinesजो आपको अतुल्यकालिक दृष्टिकोण के सभी लाभों का उपयोग करने की अनुमति देगा।इस लेख के लिए संसाधन:
लिंकध्यान देने के लिए आप सभी का धन्यवाद, जल्द ही मिलते हैं!