अपने काम के दौरान, मुझे कई तरह के कार्यों का सामना करना पड़ा। कुछ कार्यों में नीरस काम की आवश्यकता होती है, अन्य शुद्ध रचनात्मकता के लिए आते हैं।
सबसे दिलचस्प कार्य जिन्हें मैं अब याद कर सकता हूं, एक या दूसरे तरीके, क्वेरी ऑप्टिमाइज़ेशन के प्रश्नों पर स्पर्श किया गया।
अनुकूलन, सबसे पहले, इष्टतम क्वेरी योजना की खोज है। हालांकि, ऐसी स्थिति में क्या करना है जहां भाषा का मानक निर्माण एक ऐसी योजना का निर्माण करता है जो इष्टतम से बहुत दूर है?
स्तंभों को पंक्तियों में बदलने के लिए मैंने
UNPIVOT निर्माण का उपयोग करते समय इस तरह की समस्या का सामना किया।
एक छोटे तुलनात्मक विश्लेषण के माध्यम से,
UNPIVOT के लिए एक अधिक प्रभावी विकल्प पाया गया।
ताकि कार्य अमूर्त प्रतीत न हो, मान लें कि हमारे पास एक तालिका है जिसमें उपयोगकर्ताओं के बीच पदकों की संख्या की जानकारी है।
IF OBJECT_ID('dbo.UserBadges', 'U') IS NOT NULL DROP TABLE dbo.UserBadges GO CREATE TABLE dbo.UserBadges ( UserID INT , Gold SMALLINT NOT NULL , Silver SMALLINT NOT NULL , Bronze SMALLINT NOT NULL , CONSTRAINT PK_UserBadges PRIMARY KEY (UserID) ) INSERT INTO dbo.UserBadges (UserID, Gold, Silver, Bronze) VALUES (1, 5, 3, 1), (2, 0, 8, 1), (3, 2, 4, 11)
इस तालिका के आधार पर, हम स्तंभों को पंक्तियों में परिवर्तित करने के लिए विभिन्न तरीकों को प्रस्तुत करते हैं, साथ ही उनके कार्यान्वयन की योजना भी बनाते हैं।
1. यूनिअन सब
एक समय में,
SQL Server 2000 ने स्तंभों को पंक्तियों में बदलने के लिए एक कुशल तरीका प्रदान नहीं किया। नतीजतन, एक ही तालिका से कई नमूने लेने का अभ्यास, लेकिन
यूनिअन ऑल कंस्ट्रक्शन के माध्यम से संयुक्त स्तंभों के एक अलग सेट के साथ, व्यापक रूप से अभ्यास किया गया था:
SELECT UserID, BadgeCount = Gold, BadgeType = 'Gold' FROM dbo.UserBadges UNION ALL SELECT UserID, Silver, 'Silver' FROM dbo.UserBadges UNION ALL SELECT UserID, Bronze, 'Bronze' FROM dbo.UserBadges
इस दृष्टिकोण का एक बड़ा ऋण डेटा का बार-बार पढ़ना है, जिसने इस तरह के अनुरोध की दक्षता को काफी कम कर दिया है।
यदि आप कार्यान्वयन योजना को देखते हैं, तो आप इसे आसानी से देख सकते हैं:
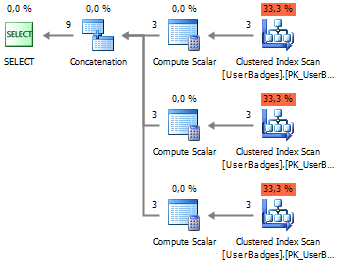
2. UNPIVOT
SQL Server 2005 की रिलीज़ के साथ, यह संभव हो गया कि नई
T-SQL भाषा निर्माण -
UNPIVOT का उपयोग किया जाए ।
UNPIVOT का उपयोग करके
, पिछली क्वेरी को सरल बनाया जा सकता है:
SELECT UserID, BadgeCount, BadgeType FROM dbo.UserBadges UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt
जब निष्पादित किया जाता है, तो हमें निम्नलिखित योजना मिलती है:
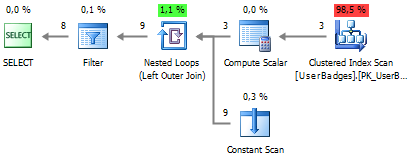
3. मूल्यों
SQL सर्वर 2008 के साथ शुरू करना
, बहु-निर्माण
INSERT प्रश्नों को बनाने के लिए न केवल
VALUES निर्माण का उपयोग करना संभव हो गया, बल्कि
FROM ब्लॉक के अंदर भी।
VALUES निर्माण का उपयोग करते हुए, ऊपर दी गई क्वेरी को इस प्रकार फिर से लिखा जा सकता है:
SELECT p.UserID, t.* FROM dbo.UserBadges p CROSS APPLY ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t(BadgeCount, BadgeType)
उसी समय,
UNPIVOT की तुलना में, कार्यान्वयन योजना थोड़ी सरल हो जाएगी:
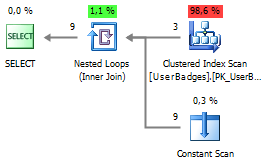
4. गतिशील एसक्यूएल
गतिशील एसक्यूएल का उपयोग करना, किसी भी तालिका के लिए "सार्वभौमिक" क्वेरी बनाना संभव है। इसके लिए मुख्य शर्त यह है कि प्राथमिक कुंजी का हिस्सा नहीं होने वाले कॉलम में संगत डेटा प्रकार होने चाहिए।
ऐसे स्तंभों की सूची जानने के लिए, निम्नलिखित प्रश्न का उपयोग करें:
SELECT c.name FROM sys.columns c WITH(NOLOCK) LEFT JOIN ( SELECT i.[object_id], i.column_id FROM sys.index_columns i WITH(NOLOCK) WHERE i.index_id = 1 ) i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id WHERE c.[object_id] = OBJECT_ID('dbo.UserBadges', 'U') AND i.[object_id] IS NULL
यदि आप क्वेरी योजना को देखते हैं, तो आप देखेंगे कि
sys.index_columns से कनेक्ट करना काफी महंगा है:
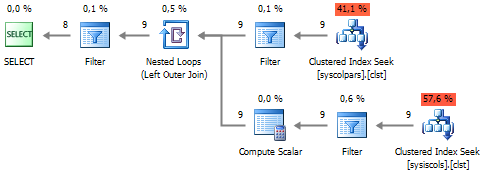
इस कनेक्शन से छुटकारा पाने के लिए, आप
INDEX_COL फ़ंक्शन का उपयोग कर सकते हैं। परिणामस्वरूप, अनुरोध का अंतिम संस्करण निम्नलिखित रूप लेगा:
DECLARE @table_name SYSNAME SELECT @table_name = 'dbo.UserBadges' DECLARE @SQL NVARCHAR(MAX) SELECT @SQL = ' SELECT * FROM ' + @table_name + ' UNPIVOT ( value FOR code IN ( ' + STUFF(( SELECT ', [' + c.name + ']' FROM sys.columns c WITH(NOLOCK) WHERE c.[object_id] = OBJECT_ID(@table_name) AND INDEX_COL(@table_name, 1, c.column_id) IS NULL FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ' ) ) unpiv' PRINT @SQL EXEC sys.sp_executesql @SQL
जब निष्पादित किया जाता है, तो टेम्पलेट के अनुसार एक अनुरोध उत्पन्न होगा:
SELECT * FROM <table_name> UNPIVOT ( value FOR code IN (<unpivot_column>) ) unpiv
यहां तक कि अगर हम अपने द्वारा किए गए अनुकूलन को ध्यान में रखते हैं, तो यह ध्यान देने योग्य है कि यह विधि अभी भी दो तीन लोगों की तुलना में धीमी है:
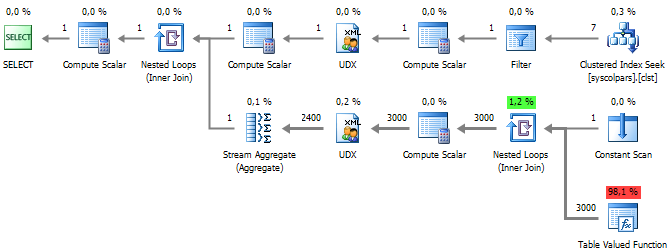
5. एक्सएमएल
गतिशील
UNPIVOT को लागू करने का एक और अधिक सुंदर तरीका निम्नलिखित
XML चाल का उपयोग करना है:
SELECT p.UserID , BadgeCount = tcvalue('.', 'INT') , BadgeType = tcvalue('local-name(.)', 'VARCHAR(10)') FROM ( SELECT UserID , [XML] = ( SELECT Gold, Silver, Bronze FOR XML RAW('t'), TYPE ) FROM dbo.UserBadges ) p CROSS APPLY p.[XML].nodes('t/@*') t(c)
जिसमें फार्म
की प्रत्येक पंक्ति के लिए
XML बनता है:
<t Column1="Value1" Column2="Value2" Column3="Value3" ... />
फिर प्रत्येक विशेषता का नाम और उसका मान पार्स किया जाता है।
ज्यादातर मामलों में,
XML का उपयोग धीमी निष्पादन योजना में किया जाता है - यह बहुमुखी प्रतिभा के लिए भुगतान की गई कीमत है।

अब परिणामों की तुलना करें:
 UNPIVOT
UNPIVOT और
VALUES के बीच निष्पादन की गति में कोई
नाटकीय अंतर नहीं
है । यह कथन सही है जब यह केवल स्तंभों को पंक्तियों में परिवर्तित करने की बात आती है।
हम कार्य को जटिल करते हैं और एक अन्य विकल्प पर विचार करते हैं, जहां प्रत्येक उपयोगकर्ता के लिए पदकों के प्रकार का पता लगाना आवश्यक है, जो उसके पास सबसे अधिक है।
आइए
UNPIVOT निर्माण का उपयोग करके समस्या को हल करने का प्रयास करें:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM dbo.UserBadges b2 UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt WHERE UserID = b.UserID ORDER BY BadgeCount DESC ) FROM dbo.UserBadges b
निष्पादन योजना से पता चलता है कि समस्या डेटा को फिर से पढ़ने और छांटने में है, जो डेटा को व्यवस्थित करने के लिए आवश्यक है:
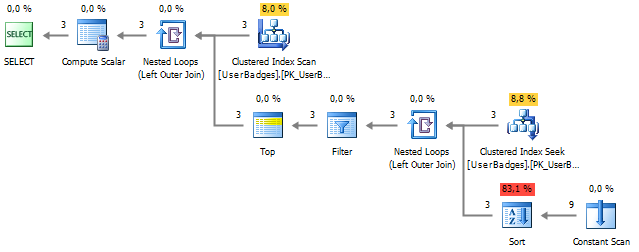
बार-बार पढ़ने से छुटकारा पाना आसान होगा, अगर आपको याद है कि एक उपखंड में बाहरी ब्लॉक से कॉलम का उपयोग करने की अनुमति है:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM (SELECT t = 1) t UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt ORDER BY BadgeCount DESC ) FROM dbo.UserBadges
बार-बार रीडिंग चली गई, लेकिन सॉर्ट ऑपरेशन नहीं चला:
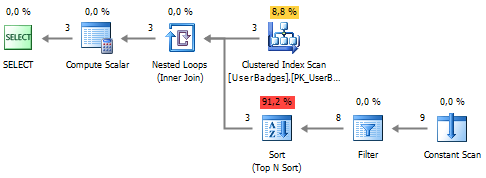
आइए देखें कि इस कार्य में
VALUES निर्माण कैसे व्यवहार करता है:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t (BadgeCount, BadgeType) ORDER BY BadgeCount DESC ) FROM dbo.UserBadges
योजना को सरल बनाया गया था, लेकिन योजना में अभी भी छंटनी मौजूद है:
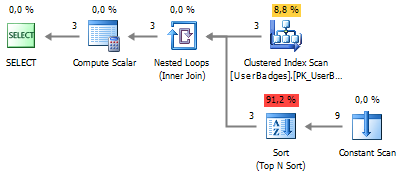
आइए एकत्रीकरण फ़ंक्शन का उपयोग करके सॉर्टिंग को बायपास करने का प्रयास करें:
SELECT UserID , BadgeType = ( SELECT TOP 1 BadgeType FROM ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t (BadgeCount, BadgeType) WHERE BadgeCount = ( SELECT MAX(Value) FROM ( VALUES (Gold), (Silver), (Bronze) ) t(Value) ) ) FROM dbo.UserBadges
हमने छँटाई से छुटकारा पा लिया:
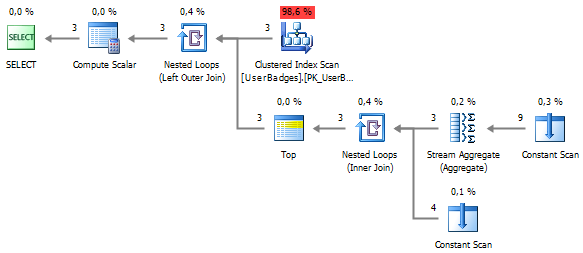 छोटे परिणाम:
छोटे परिणाम:ऐसी स्थिति में जहां पंक्तियों के लिए स्तंभों का एक सरल रूपांतरण करना आवश्यक है,
UNPIVOT या
VALUES निर्माणों का उपयोग करना सबसे बेहतर है।
यदि रूपांतरण के बाद, प्राप्त आंकड़ों को एकत्रीकरण या छंटनी के संचालन में उपयोग करने की योजना है, तो
VALUES निर्माण का उपयोग करना अधिक बेहतर है, जो कि ज्यादातर मामलों में, अधिक कुशल निष्पादन योजना प्राप्त करने की अनुमति देता है।
यदि तालिकाओं में स्तंभों की संख्या परिवर्तनशील है, तो
XML का उपयोग करने की सिफारिश की जाती है, जो गतिशील SQL के विपरीत, तालिका कार्यों के अंदर उपयोग की जा सकती है।
PS अनुकूलित करने के लिए,
SQL Server 2005 की सुविधाओं के लिए उदाहरणों का एक हिस्सा,
VALUES का उपयोग करके एक डिज़ाइन:
SELECT * FROM ( VALUES (1, 'a'), (2, 'b') ) t(id, value)
संयोजन के साथ प्रतिस्थापित होना चाहिए का
चयन करें सभी का चयन करें :
SELECT id = 1, value = 'a' UNION ALL SELECT 2, 'b'
अद्यतन 10/16/2013 : UNPIVOT और VALUES बड़ी मात्रा में डेटा का व्यवहार कैसे करते हैं?
निम्नलिखित संरचना के साथ एक तालिका के आधार पर (कुल 25 कॉलम)।
CREATE TABLE [dbo].[WorkOutFactors] ( WorkOutID BIGINT NOT NULL PRIMARY KEY, NightHours INT NOT NULL, EveningHours INT NOT NULL, HolidayHours INT NOT NULL, ... )
इस तालिका में ~ 186000 पंक्तियाँ हैं। स्थानीय
SQL सर्वर 2012 SP1 पर एक ठंड शुरू होने से, पंक्तियों को पंक्तियों में परिवर्तित करने का संचालन निम्न परिणाम उत्पन्न करता है।
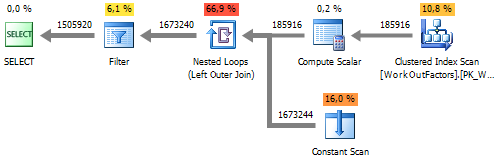
UNPIVOT कार्यान्वयन
योजना :
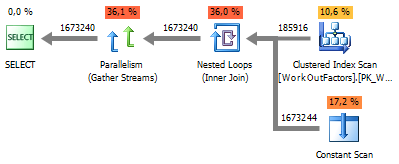
 VALUES
VALUES निष्पादन योजना:
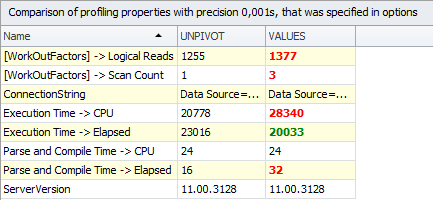
इसकी तुलना में, आप देख सकते हैं कि
VALUES तेज़ है (3 सेकंड से), लेकिन इसके लिए बड़े CPU संसाधनों की आवश्यकता होती है:
मैं अपने आप से जोड़ता हूं कि प्रत्येक विशिष्ट स्थिति में प्रदर्शन का अंतर अलग-अलग होगा।