फोटॉन एक स्केलेबल, लचीला, और भौगोलिक रूप से वितरित
रीयल-टाइम स्ट्रीमिंग प्रोसेसिंग सिस्टम है। सिस्टम Google का आंतरिक उत्पाद है और इसका उपयोग Google विज्ञापन प्रणाली में किया जाता है। फोटॉन के बुनियादी सिद्धांतों और वास्तुकला का वर्णन करने वाले एक शोध पत्र [5] को 2013 के एसीएम सिग्मोड वैज्ञानिक सम्मेलन में प्रस्तुत किया गया था।
पेपर [5] में कहा गया है कि सिस्टम पर
पीक लोड औसतन टू-एंड-एंड देरी के साथ 10 सेकंड तक प्रति मिनट लाखों घटनाएं हो सकती हैं।
* शीर्षक में 'प्रकाश की गति'
एक अतिशयोक्ति
का स्पष्ट झूठ है ।

फोटॉन एक बहुत ही विशिष्ट समस्या को हल करता है:
वास्तविक समय में दो सतत डेटा स्ट्रीम को कनेक्ट करना (ज्वाइन ऑपरेशन करना) करना आवश्यक है। तो पहले से ही उल्लेखित Google विज्ञापन प्रणाली में, इनमें से एक धारा खोज क्वेरी की एक धारा है, दूसरा विज्ञापन पर क्लिक की एक धारा है।
फोटॉन
भौगोलिक रूप से वितरित प्रणाली है और
बुनियादी ढांचे के क्षरण के मामलों को संभालने में
स्वचालित रूप से सक्षम है डेटा सेंटर की विफलता। भू-वितरित प्रणालियों में, संदेश वितरण समय (मुख्य रूप से नेटवर्क देरी के कारण) की गारंटी देना बेहद मुश्किल है, इसलिए फोटॉन मानता है कि संसाधित स्ट्रीमिंग डेटा समय-क्रमित नहीं हो सकता है।
प्रयुक्त सेवाएं: Google फ़ाइल सिस्टम , PaxosDB, TrueTime।
मूल सिद्धांत
[५] में, फोटॉन सिद्धांतों को निम्नलिखित संदर्भ में समझाया गया है: उपयोगकर्ता ने समय t1 पर एक खोज
क्वेरी दर्ज की और समय t2 पर एक विज्ञापन (
क्लिक ) पर
क्लिक किया । उसी संदर्भ में, जब तक कि अन्यथा निर्दिष्ट नहीं किया जाता है, यह आलेख बताएगा कि फोटॉन कैसे काम करता है।
थ्रेड्स (
ज्वाइन ) का सिद्धांत RDBMS की दुनिया से लिया गया है:
क्वेरी स्ट्रीम में एक विशिष्ट पहचानकर्ता
query_id (सशर्त रूप से प्राथमिक कुंजी) है,
क्लिक स्ट्रीम में एक विशिष्ट पहचानकर्ता
click_id होता है और इसमें कुछ query_id (सशर्त विदेशी कुंजी) शामिल होते हैं। थ्रेडिंग ज्वाइन करना query_id द्वारा होता है।
अगला महत्वपूर्ण बिंदु: वह स्थिति जब एक क्लिक की घटना को दो बार गिना जाता है, या, इसके विपरीत, नहीं गिना जाता है, क्रमशः नेतृत्व करेगा, या तो विज्ञापनदाताओं द्वारा मुकदमा करने के लिए या Google से खोए हुए लाभ के लिए। यहां से,
सबसे महत्वपूर्ण घटना प्रसंस्करण शब्दार्थ प्रदान करना महत्वपूर्ण है।
एक अन्य आवश्यकता
निकट-सटीक शब्दार्थ प्रदान करने के लिए है, अर्थात्। ताकि अधिकांश घटनाएं निकट वास्तविक समय मोड में गिनी जाएं। वास्तविक समय में गिने जाने वाली घटनाओं को अभी भी नहीं गिना जाना चाहिए -
बिल्कुल एक बार शब्दार्थ।
इसके अलावा, अलग-अलग डेटा केंद्रों में काम करने वाले फोटॉन इंस्टेंस के लिए, एक
सिंक्रोनाइज़्ड स्टेट की आवश्यकता होती है (अधिक सटीक, केवल क्रिटिकल स्टेट, चूंकि डीसी के बीच पूरे राज्य को "दोहराने के लिए" बहुत महंगा है)। इसलिए सिंक्रोनाइज़्ड
क्रिटिकल स्टेट को event_id (वास्तव में, click_id) चुना
गया था । क्रिटिकल स्टेट को
IdRegistry संरचना में संग्रहीत किया जाता है -
PaxosDB पर आधारित एक इन-मेमोरी की-वैल्यू स्टोरेज।
उत्तरार्द्ध - पैक्सोसबीडी -
दोष सहिष्णुता और डेटा स्थिरता का समर्थन करने के
लिए पैक्सोस
एल्गोरिथ्म को लागू
करता है ।
ग्राहक बातचीत
वर्कर नोड्स
क्लाइंट-सर्वर मॉडल पर IdRegistry के साथ बातचीत करते हैं। वास्तुकला में, IdRegistry के साथ वर्कर नोड्स का
इंटरैक्शन अतुल्यकालिक संदेशों की एक कतार के साथ एक नेटवर्क इंटरैक्शन है ।
इसलिए क्लाइंट्स - वर्कर नोड्स - IdRegistry को केवल 1 भेजें) Event_id की खोज करने के लिए एक अनुरोध (यदि event_id पाया गया था, तो यह पहले ही संसाधित हो चुका है) और 2) Event_id सम्मिलित करने के लिए एक अनुरोध (मामले के लिए यदि इवेंट -id चरण 1 में नहीं मिला था)। सर्वर साइड पर, अनुरोध आरपीसी संचालकों द्वारा प्राप्त किए जाते हैं, जिसका उद्देश्य अनुरोध को कतारबद्ध करना है। अनुरोधों की कतार से, एक विशेष
रजिस्ट्री थ्रेड प्रक्रिया (सिंगलटन) इसे ले जाती है, जो कि पैक्सोसडीबी को लिखेगी और ग्राहक
को कॉलबैक शुरू करेगी।
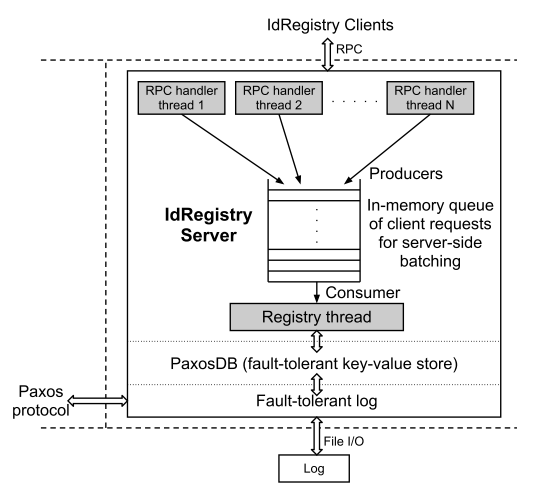
चित्रण का स्रोत [5, चित्र 3]
scalability
क्योंकि भौगोलिक क्षेत्रों के बीच IdRegistry प्रतिकृति होती है,
जिसके बीच नेटवर्क विलंब 100 ms [5]
तक पहुंच सकता है , यह स्वचालित रूप से IdRegistry के थ्रूपुट को लगातार दस लेन-देन (Event_id के अनुसार) प्रति सेकंड तक सीमित करता है, जबकि IdRegistry की आवश्यकता प्रति सेकंड 10K लेनदेन थी । लेकिन कोरम में संघर्ष समाधान के लिए समर्थन के साथ भू-वितरण और / या समकालिक रूप से महत्वपूर्ण राज्य प्रतिकृति को मना करना भी असंभव है।
तब Google इंजीनियरों ने DBMS की दुनिया से परिचित 2 और प्रथाओं की शुरुआत की:
- अनुरोधों की बैचिंग (" बैचिंग )" - Event_id पर "उपयोगी" जानकारी 100 से कम बाइट्स लेती है; IdRegistry क्लाइंट के लिए अनुरोध बैचों में भेजे जाते हैं। वहां वे इन-मेमोरी कतार में आते हैं, जो रजिस्ट्री थ्रेड प्रक्रिया पार्स करता है, जो इस तथ्य से संबंधित संघर्षों को हल करने के लिए जिम्मेदार है कि कतार में एक ही event_id के साथ एक से अधिक तत्व हो सकते हैं।
- टाइमस्टैम्प-आधारित शेडिंग (+ डायनेमिक रीशेयरिंग ) - सभी event_id को श्रेणियों द्वारा विभाजित किया गया है; प्रत्येक श्रेणी के लेन-देन एक विशिष्ट IdRegistry के लिए भेजे जाते हैं।
बैच भेजने के अनुरोधों में एक नकारात्मक पहलू है: शब्दार्थ मिश्रण के अलावा (फोटॉन
वास्तविक समय डेटा को संसाधित करता है, और इसके कुछ हिस्से
बैचिंग मोड में काम करते हैं), बैचिंग स्क्रिप्ट कम संख्या में घटनाओं के लिए सिस्टम के लिए उपयुक्त नहीं है - एक पूर्ण पैकेट का संग्रह समय एक महत्वपूर्ण अंतराल ले सकता है समय।
घटकों
एक डीसी के ढांचे के भीतर, निम्नलिखित घटक प्रतिष्ठित हैं:
- EventStore - प्रश्नों (खोज इंजन में खोज प्रश्नों की धारा) में एक प्रभावी खोज प्रदान करता है;
- डिस्पैचर - विज्ञापनों पर क्लिक के प्रवाह को पढ़ना (क्लिक) और रीड जॉइनर को स्थानांतरित करना (फ़ीड);
- जॉइनर एक स्टेटलेस RPC सर्वर है जो डिस्पैचर के अनुरोधों को स्वीकार करता है, उन्हें प्रोसेस करता है, और क्वेरी और क्लिक्स से जुड़ता है।
रिकॉर्ड जोड़ने के लिए एल्गोरिथ्म नीचे प्रस्तुत किया गया है:
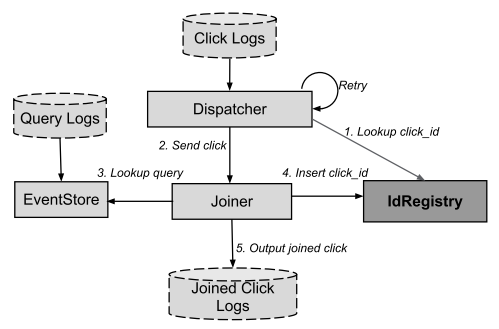
चित्रण का स्रोत [5, चित्र 5]
डीसी के बीच बातचीत:

चित्रण का स्रोत [5, चित्र 6]
हम लॉग लॉग में
शामिल होने के लिए प्रविष्टियों को जोड़ने के लिए एल्गोरिथ्म को छोड़ देते हैं, यह देखते हुए कि सामान्य नेटवर्क एल्गोरिथ्म को जटिल किए बिना, क्रमशः नेटवर्क इंटरैक्शन के साथ सिस्टम के संचालन में
पुन: प्रयास नीतियों और
अतुल्यकालिक कॉल का उपयोग एक अत्यंत प्रभावी तरीका है।
एक ही तकनीक - रिट्री पॉलिसी और एसिंक्रोनस कॉल - का उपयोग फोटॉन के रचनाकारों द्वारा किया गया था।
क्वेरी रिट्री लॉजिकजैसा कि पहले उल्लेख किया गया है, प्रसंस्करण के लिए click_id प्राप्त होने पर स्थिति और इसके साथ संबंधित क्वेरी_आईडी अपवाद नहीं है। इस तथ्य के कारण कि कोड द्वारा प्रासंगिक विज्ञापन पर क्लिकों के प्रवाह को संसाधित करने के लिए खोज प्रश्नों का प्रवाह आवश्यक रूप से संसाधित नहीं होता है।
मज़बूती से सभी click_id के लिए कम से कम-एक बार प्रसंस्करण शब्दार्थ प्रदान करने के लिए, एक तर्क पेश किया गया था जो ऊपर वर्णित मामले के लिए पुनरावृत्ति तर्क का उपयोग करता है। सिस्टम के थ्रॉटलिंग से बचने के लिए, विफल अनुरोधों के बीच का समय तेजी से बढ़ता है - घातीय बैकऑफ़ एल्गोरिथ्म। कई असफल अनुरोधों के बाद या एक निश्चित समय के बाद, क्लिक को "अस्वीकार्य" के रूप में चिह्नित किया जाता है।
डिस्पैचर
डिस्पैचर - क्लिक लॉग पढ़ने के लिए जिम्मेदार प्रक्रिया - क्लिक। ये लॉग जीएफएस में संग्रहीत होते हैं और लगातार समय में बढ़ते हैं।
उन्हें प्रभावी ढंग से पढ़ने के लिए, डिस्पैचर समय-समय पर लॉग के साथ डायरेक्टरी को स्कैन करता है और नई फाइलों और / या बदले हुए लोगों की पहचान करता है, प्रत्येक फाइल की स्थिति को स्थानीय जीएफएस सेल में बचाता है। इस स्थिति में डेटा
के लिए फ़ाइल की एक
सूची और
फ़ाइल की शुरुआत से एक
बदलाव होता है जिसे पहले ही संसाधित किया जा चुका है। इस प्रकार, जब एक फ़ाइल को बदल दिया जाता है, तो बाद को शुरुआत से नहीं घटाया जाता है, लेकिन उस समय से जिस पर अंतिम रीडिंग में प्रसंस्करण समाप्त हो गया था।
नए डेटा के प्रसंस्करण को कई प्रक्रियाओं के समानांतर में किया जाता है, जिनमें से प्रत्येक अपने राज्य को साझा करता है, जो अलग-अलग प्रक्रियाओं
को एक ही फाइल के विभिन्न भागों पर मूल रूप
से काम करने की अनुमति देता है।
योजक
जॉइनर एक स्टेटलेस RPC सर्वर का कार्यान्वयन है जो डिस्पैचर के अनुरोधों को स्वीकार करता है। डिस्पैचर से एक अनुरोध स्वीकार करने के बाद, जॉइनर ने उससे click_id और query_id निकाले। फिर, query_id द्वारा, यह EventStore से जानकारी प्राप्त करने का प्रयास करता है।
सफल होने पर, EventStore एक खोज क्वेरी देता है जो संसाधित होने के लिए क्लिक से मेल खाता है।
अगला, जॉइनर डुप्लिकेट को हटाता है (IdRegistry का उपयोग करके) और एक आउटपुट लॉग उत्पन्न करता है जिसमें शामिल मान होते हैं - ज्वाइन क्लिक लॉग।
यदि डिस्पैचर ने विफलताओं को संभालने के लिए पुन: प्रयास तर्क का उपयोग किया, तो Google इंजीनियरों ने योजक को एक और चाल जोड़ी। रिसेप्शन काम करता है जब जॉइनर ने IdRegistry को एक अनुरोध भेजा; उत्तरार्द्ध सफलतापूर्वक click_id पंजीकृत है, लेकिन नेटवर्क समस्याओं के कारण, या टाइमआउट द्वारा, Joiner को कभी भी IdRegistry से सफलता की प्रतिक्रिया नहीं मिली।
ऐसा करने के लिए, एक विशेष टोकन प्रत्येक प्रतिबद्ध click_id अनुरोध के साथ जुड़ा होता है जो जॉइनर आइड्रेगिस्ट्री को भेजता है। टोकन IdRegistry में संग्रहीत है। यदि IdRegistry से कोई प्रतिक्रिया नहीं मिली है, तो Joiner पिछले अनुरोध के समान टोकन के साथ अनुरोध को दोहराता है, और IdRegistry आसानी से "समझता" है कि आने वाले अनुरोध को पहले ही संसाधित किया जा चुका है।
अनोखा टोकन जनरेशन / Event_Idएक और दिलचस्प ट्रिक जिसे नोट किया जाना चाहिए वह है अद्वितीय ईवेंट_ड जनरेट करने की विधि।
जाहिर है, Event_id के लिए विशिष्ट विशिष्टता की गारंटी फोटॉन के काम करने के लिए एक आवश्यक आवश्यकता है। एक ही समय में, कई डीसी के भीतर अद्वितीय मान उत्पन्न करने के लिए एल्गोरिथ्म सीपीयू संसाधनों का एक अत्यंत महत्वपूर्ण समय और मात्रा ले सकता है।
Google इंजीनियरों को एक सुंदर समाधान मिला: event_id को विशिष्ट रूप से होस्ट IP (ServerIP), प्रोसेस आईडी (ProcessId) और होस्ट के टाइमस्टैम्प (टाइमस्टैम्प) का उपयोग करके पहचाना जा सकता है, जिस पर यह ईवेंट उत्पन्न हुआ था।
स्पैनर के साथ के रूप में, ट्रूटाइम एपीआई का उपयोग विभिन्न नोड्स पर टाइमस्टैम्प की असंगति को कम करने के लिए किया जाता है।
EventStore
EventStore एक सेवा है जो query_id को इनपुट के रूप में प्राप्त करता है और संबंधित क्वेरी (खोज क्वेरी के बारे में जानकारी) देता है।
EventStore के लिए फोटॉन में 2 कार्यान्वयन हैं:
- CacheEventStore - मेमोरी मेमोरी में हैश (क्वेरी_आईडी)] द्वारा वितरित किया गया, जिसमें क्वेरी पर पूरी जानकारी संग्रहीत है। इस प्रकार, एक अनुरोध के जवाब में डिस्क से पढ़ने की आवश्यकता नहीं है।
- LogsEventStore कुंजी-मूल्य का भंडारण है, जहां कुंजी query_id है, और मान उस लॉग फ़ाइल का नाम है जिसमें संबंधित क्वेरी पर जानकारी संग्रहीत है, और इस फ़ाइल में बाइट ऑफसेट है।
चूंकि फोटॉन वास्तविक समय मोड के पास संचालित होता है, हम विश्वासपूर्वक गारंटी दे सकते हैं कि कैशेइवेंटस्टोर में क्वेरी खोजने की संभावना (बशर्ते कि यह न्यूनतम देरी के साथ क्वेरी में मिलती है) बहुत अधिक है, और कैशेइवेंटस्टोर स्वयं अपेक्षाकृत छोटी घटनाओं को स्टोर कर सकता है। समय व्यतीत हो गया।
शोध पत्र [5] आंकड़े प्रदान करता है कि इन-मेमोरी कैश के केवल 10% अनुरोध "पास" होते हैं और तदनुसार, LogsEventStore द्वारा संसाधित किया जाता है।
परिणाम
विन्यास
प्रकाशन के समय [5], अर्थात 2013 में, IdRegistry प्रतिकृतियां
3 भौगोलिक क्षेत्रों (पूर्वी, पश्चिमी तट और उत्तरी अमेरिका के मध्य-पश्चिम)
में 5 डेटा केंद्रों में तैनात की
गई थीं, और क्षेत्रों के बीच नेटवर्क देरी
100 एमएस से अधिक थी । फोटॉन के अन्य घटक डिस्पैचर, जॉइनर आदि हैं। - संयुक्त राज्य अमेरिका के पश्चिमी और पूर्वी तट पर 2 भौगोलिक क्षेत्रों में तैनात।
प्रत्येक DC में, IdRegistry शार्क की संख्या सौ से अधिक होती है, और डिस्पैचर और जॉइनर प्रक्रियाओं के उदाहरणों की संख्या हजारों से अधिक होती है।
उत्पादकता
फोटॉन चोटी की अवधि के दौरान,
प्रति मिनट लाखों घटनाओं सहित, प्रति दिन अरबों में शामिल हो जाता है। 24 घंटों में संसाधित क्लिक-लॉग की मात्रा टेराबाइट्स से अधिक हो जाती है, और दैनिक क्वेरी-लॉग की मात्रा टेराबाइट्स की दसियों में गणना की जाती है।
सभी घटनाओं के 90% होने के बाद
पहले 7 सेकंड में (एक स्ट्रीम में शामिल) संसाधित होते हैं।
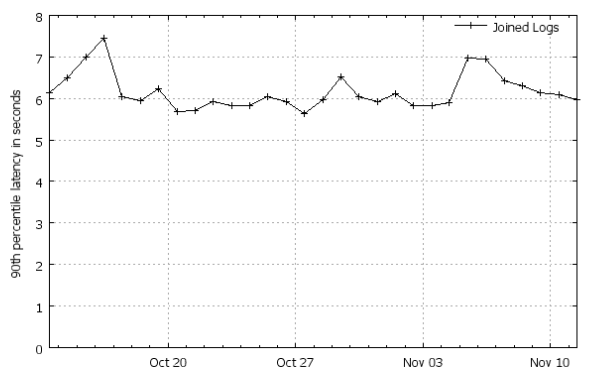
चित्रण का स्रोत [५, चित्र 5]।
आँकड़ों के साथ अधिक रेखांकन (स्लाइड 24-30)।
जटिल प्रणालियों के सरल सिद्धांत
"मूल सिद्धांत" अनुभाग में, मैंने पहले ही उल्लेख किया था कि फोटॉन एक ऐसी प्रणाली है जो बिल्कुल-एक बार (कम से कम-एक बार और सबसे-एक बार) और निकट-सटीक अर्थ विज्ञान का समर्थन करती है, अर्थात यह सुनिश्चित करता है कि लॉग में दर्ज किसी भी घटना को एक बार और केवल एक बार संसाधित किया जाएगा, और वास्तविक समय मोड के करीब उच्च संभावना के साथ।
PaxosDB सबसे अधिक-एक बार शब्दार्थ पर लागू होता है , जबकि
डिस्पैचर रिट्री नीतियां कम से कम-एक बार शब्दार्थ प्रदान करती हैं ।
निकट-वास्तविक समय मोड (निकट-सटीक शब्दार्थ) में प्रसंस्करण की घटनाओं के लिए, निम्नलिखित सिद्धांतों को फोटॉन वास्तुकला में रखा गया है:
- scalability:
- गैर-संबंधपरक भंडारण के लिए अनिवार्य शार्क;
- सभी वर्कर नोड्स स्टेटलेस हैं।
- विलंब (विलंबता):
- जहाँ भी संभव हो आरपीसी संचार;
- जहाँ भी संभव हो, डेटा को रैम में स्थानांतरित करना।
निष्कर्ष में
शोध पत्र [5] के निष्कर्ष में, Google इंजीनियरों ने अपनी अच्छी प्रथाओं और भविष्य के लिए अपनी योजनाओं को साझा किया।
सिद्धांत नए नहीं हैं, लेकिन लेख की पूर्णता और पूर्णता के लिए, मैं उन्हें सूचीबद्ध करूंगा:
- डिस्क पर लिखने के बजाय RPC संचार का उपयोग करें। नोड की भौतिक सीमाओं से परे जाने वाले अनुरोधों को अतुल्यकालिक रूप से निष्पादित किया जाना चाहिए, और ग्राहक को हमेशा यह उम्मीद करनी चाहिए कि उसे टाइमआउट या नेटवर्क समस्याओं के कारण प्रतिक्रिया नहीं मिलेगी।
- सिस्टम की महत्वपूर्ण स्थिति को कम से कम , के रूप में यह आम तौर पर तुल्यकालिक रूप से दोहराया जाना होता है। आदर्श रूप से, किसी सिस्टम की महत्वपूर्ण महत्वपूर्ण स्थिति में केवल सिस्टम मेटाडेटा शामिल होना चाहिए।
- साझाकरण स्केलेबिलिटी का एक दोस्त है :) लेकिन Google के इंजीनियरों ने भी समय-समय पर साझाकरण करके इस विचार में सुधार किया।
फोटॉन के रचनाकारों की योजना
दुनिया को संभालो इस तथ्य के कारण एंड-टू-एंड देरी को कम करें कि सर्वर जो क्लिक और क्वेरी उत्पन्न करते हैं, आरपीसी अनुरोध सीधे जॉइनर्स (अब डिस्पैचर इन घटनाओं के लिए "प्रतीक्षा कर रहे हैं") को भेज देंगे। यह कई डेटा धाराओं को संयोजित करने के लिए फोटॉन को "सिखाने" की भी योजना है (वर्तमान कार्यान्वयन में फोटॉन केवल 2 धाराओं को जोड़ सकता है)।
हम फोटॉन के रचनाकारों को उनकी योजनाओं को लागू करने के लिए शुभकामनाएं देते हैं! और नए शोध पत्र के लिए तत्पर हैं!
स्रोतों की सूची **
[५] राजगोपाल अनंतनारायणन, वेंकटेश बस्कर, सुमित दास, आशीष गुप्ता, हाइफ़ेंग जियांग, तियानहाओ किउ, एट अल।
फोटॉन: फॉल्ट-टॉलरेंट एंड स्केलेबल जॉइनिंग ऑफ कंटीन्यूअस डेटा स्ट्रीम्स , 2013।
** चक्र तैयार करने के लिए उपयोग किए जाने वाले
स्रोतों की एक पूरी सूची ।
पोस्ट इतिहास बदलेंचांस 01 [
12/27/2013 ]।
लेख का चित्रण बदल दिया। नए चित्रण के लिए
TheRaven के लिए धन्यवाद
। Offtopic
Google प्लेटफ़ॉर्म के बारे में लेखों की एक
श्रृंखला में यह अंतिम लेख है।
 सभी को नया साल मुबारक हो! गुड लक और दृढ़ता!दिमित्री पेटुखोव
सभी को नया साल मुबारक हो! गुड लक और दृढ़ता!दिमित्री पेटुखोव ,
एमसीपी,
पीएचडी छात्र , आईटी लाश,
लाल रक्त कोशिकाओं के बजाय कैफीन के साथ एक व्यक्ति।