हेलो, हेब्र!
अंत में, हाथ पहुंच गए। यह बताने का समय है कि हमारी कंपनी
डीएम लैब्स शैक्षणिक गतिविधियों के अलावा डेटा विश्लेषण के क्षेत्र में क्या कर रही है (हमने पहले ही इसके बारे में लिखा था
1 )।
पिछले एक साल में, हमने
म्यूनिख के
तकनीकी विश्वविद्यालय ( टीयूएम) में
फोर्टिस इंस्टीट्यूट ऑफ रोबोटिक्स के साथ मिलकर काम करना शुरू किया (एक साथ हम रोबोट को लोगों को नहीं मारना सिखाते हैं), एक प्रोटोटाइप एंटीफ्राड सिस्टम जारी किया, अंतर्राष्ट्रीय मशीन सीखने के सम्मेलनों में भाग लिया, और सबसे महत्वपूर्ण बात, विश्लेषकों की एक मजबूत टीम बनाने में सक्षम थे। ।
अब डीएम लैब्स पहले से ही तीन क्षेत्रों को जोड़ती है: एक अनुसंधान प्रयोगशाला, तैयार वाणिज्यिक समाधान और प्रशिक्षण का विकास। आज की पोस्ट में, हम उनके बारे में अधिक विस्तार से बात करेंगे, पिछले वर्ष की राशि और भविष्य के लिए अपने लक्ष्यों को साझा करेंगे।
ट्रेनिंग
शैक्षिक दिशा शुरू करते हुए, हम युवा विशेषज्ञों और विशेषज्ञों के बीच ज्ञान के आदान-प्रदान के लिए एक कार्यक्रम बनाना चाहते थे, और जैसा कि पहले ही उल्लेख किया गया है, रूस में डेटा साइंस समुदाय बनाने में मदद करने के लिए।
इस साल हम छात्रों की पहली स्ट्रीम जारी करने में कामयाब रहे और अब हम दूसरे सेट के लिए एक कार्यक्रम आयोजित कर रहे हैं।
| 2013 | 2013/2014 |
|---|
| छात्रों | 18 | 25 |
|---|
| विशेषज्ञ | 19 | 30+ |
|---|
कार्यक्रम  | उद्योग में डेटा खनन | उद्योग में डेटा खनन + आर, मशीन लर्निंग, बिग डेटा में व्यक्तिगत पाठ्यक्रम |
|---|
| व्याख्यान | 60 घंटे | उद्योग में डेटा खनन: 70+ घंटे, पाठ्यक्रम: 80+ घंटे |
|---|
| कंपनी | आईबीएम, ईएमसी, सीमेंस, फोर्टिस, आदि। | सभी समान + डेलोइट, एक्सेंचर, सहपाठियों, आदि। |
|---|
पाठ्यक्रम में बहुत बदलाव आया है, लेकिन हमने महसूस किया कि हमारी शिक्षा के दर्शन को रेखांकित करने वाले तीन तत्वों को नहीं बदला जाएगा:
- विशेषज्ञों के साथ संचार।
- अभ्यास। छात्र विभिन्न प्रतियोगिताओं में भाग लेते हैं और विभिन्न क्षेत्रों ( 1 , 2 और 3 ) के विशेषज्ञों द्वारा प्रस्तुत समस्याओं का समाधान करते हैं।
- Proactivity। हम छात्रों को एक दूसरे के साथ ज्ञान साझा करने और विभिन्न विषयों पर आंतरिक सेमिनार आयोजित करने की कोशिश कर रहे हैं, जिनमें न केवल डेटा विश्लेषण से संबंधित हैं।
पाठ्यक्रम को जारी रखने के अलावा, 2014 में हम और भी विभिन्न शैक्षणिक पहल करेंगे:
- डेटा माइनिंग सौना - क्रिसमस की छुट्टियों के लिए, हमने छात्रों और विशेषज्ञों को सेंट पीटर्सबर्ग के पास एक निजी संपर्क चिड़ियाघर में एक दूसरे के साथ अनौपचारिक रूप से विचार साझा करने और अनुसंधान पर चर्चा करने के लिए आमंत्रित किया (हम जल्द ही इस घटना के बारे में और अधिक लिखेंगे)।
- अब हम सेंट पीटर्सबर्ग में सामाजिक नेटवर्क के विश्लेषण के लिए एक हैकथॉन तैयार कर रहे हैं।
- आने वाले वर्ष में, हम डाटा माइनिंग पर एक सम्मेलन आयोजित करना चाहते हैं।
परियोजनाओं
प्रशिक्षण क्षेत्र की शुरुआत के बाद, परियोजना गतिविधि और डेटा खनन परियोजनाओं की नई दिशा एक तार्किक निरंतरता बन गई, क्योंकि मशीन सीखने की मदद से आप विभिन्न क्षेत्रों में कई दिलचस्प समस्याओं को हल कर सकते हैं:
अब हमारी टीम विभिन्न वाणिज्यिक परियोजनाओं पर काम कर रही है, जिसमें वित्तीय लेन-देन के ट्रैफ़िक का विश्लेषण करने, वेब सेवा लॉग फ़ाइलों के आधार पर विसंगतियों का पता लगाने, उपयोगकर्ता रिटर्न की भविष्यवाणी करने आदि के कार्य शामिल हैं।
TechCrunch मास्को में, हमने बताया कि कैसे हम किसी कंपनी को डेटा-संचालित होने में मदद कर सकते हैं।
हम निम्नलिखित लेखों में परियोजनाओं के विशिष्ट मामलों और हमारे उत्पाद, एंटीफ्राड सिस्टम के बारे में लिखेंगे।
अनुसंधान
डिजाइन का काम अच्छा है, लेकिन एक डेटा वैज्ञानिक की आत्मा हमेशा अधिक के लिए पूछती है: मैं चाहता हूं कि मॉडल अधिक सटीक हों, एल्गोरिदम तेजी से काम करने के लिए, और उनके आवेदन का क्षेत्र बढ़ता है। तो तीसरी दिशा बनाई गई - डेटा माइनिंग आर एंड डी।
अब हम ग्रेड बूस्टिंग मशीनों [
1 ,
2 ,
3 ] से संबंधित विभिन्न कार्यों पर काम कर रहे हैं। ये एल्गोरिदम याहू, यैंडेक्स जैसी कंपनियों द्वारा अपने मैट्रिक्स मैट्रिक्स, माइक्रोसॉफ्ट
और अन्य में सक्रिय रूप से उपयोग किए जाते
हैं । यदि "उंगलियों पर" समझाने के लिए, तो एल्गोरिथ्म का मुख्य विचार निर्णय पेड़ों का एक सेट इस तरह से बनाना है कि प्रत्येक नए पेड़ के साथ एल्गोरिथ्म का कुल उत्पादन अधिक से अधिक सटीक हो। उदाहरण के लिए, जैसा कि इस चित्र में है:
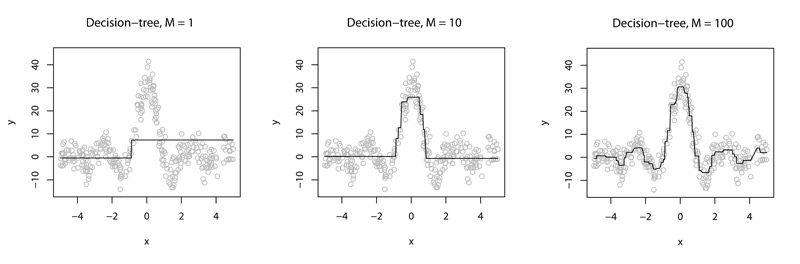
सब कुछ सरल प्रतीत होता है, लेकिन रचनात्मकता के लिए बहुत गुंजाइश है: इसे कैसे बनाया जाए ताकि समान सटीकता प्राप्त करने के लिए कम पेड़ों की आवश्यकता हो (उनकी संख्या कैसे कम करें)? यदि आप "गहरा" पहनावा बनाते हैं तो क्या होगा? या अर्ध - "गहरा" गिज़्मोस का एक पहनावा?
कार्य का दूसरा महत्वपूर्ण क्षेत्र डेटा फ्यूजन विधियां हैं। एक समस्या को हल करने के ढांचे के भीतर विभिन्न क्षेत्रों से डेटा का उपयोग करने का विचार है: पाठ, वीडियो, ऑडियो, ग्राफ़, सेंसर, साथ ही साथ उनके विभिन्न संयोजन। यदि आप सभी डेटा पर एक ही GBM एल्गोरिथ्म "हेड-ऑन" चलाते हैं, तो वितरण बहुत अलग होंगे, और संकेतों की संख्या अनुचित रूप से बड़ी होगी। सामान्य तौर पर, यह काम नहीं करेगा कारणों का वर्णन एक अलग लेख के योग्य विषय है।
एक उदाहरण जो हमें इस क्षेत्र में मिला, वह था वित्तीय जोखिमों का निर्धारण करना। इस कार्य के लिए, वे आमतौर पर एक्सचेंज से उद्धरणों के बारे में मात्रात्मक जानकारी का उपयोग करते हैं - कंपनी के शेयर की कीमतों की अस्थिरता को देखकर, कोई अगले वर्ष के लिए जोखिमों का सटीक अनुमान लगा सकता है। हालांकि, कंपनियों के वार्षिक वित्तीय वक्तव्यों से मिली जानकारी को देखते हुए, इस सटीकता में सुधार किया जा सकता है।
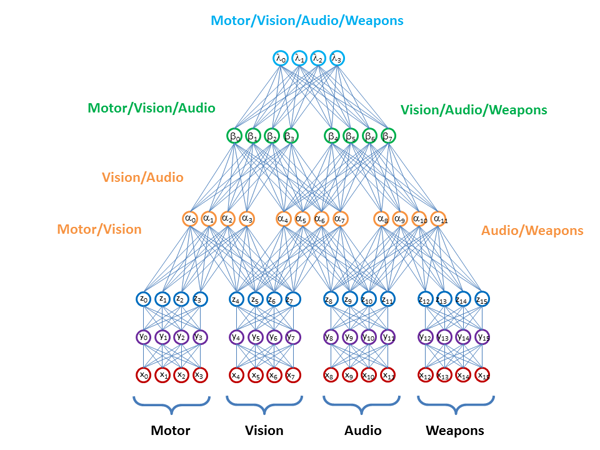
मुख्य प्रश्न यह है कि डेटा में निहित सभी सूचनाओं का उपयोग करने के लिए यह सबसे कुशलता से कैसे किया जाए? विभिन्न डेटा उप-स्थानों पर निर्मित मॉडल कैसे सिलाई करें? केवल
डी-वेव के सुझाव के अनुरूप मॉडल या प्रतिनिधित्व के साथ कुछ मध्यवर्ती परतें सिलाई करें
:
हमारा शोध वहाँ समाप्त नहीं होता है। उदाहरण के लिए, हम प्रश्नों के बारे में बहुत चिंतित हैं:
- जब बहुत सारे हैं तो महत्वपूर्ण संकेतों का चयन कैसे करें: दसियों और सैकड़ों हजारों?
- बड़े आयामों में विसंगतियों की खोज कैसे करें?
- एक अरब बिंदुओं पर GBM एल्गोरिथ्म कैसे चलाएं? और खरब में? यह उन ढाल विधियों के लिए एक सामान्य प्रश्न है जहाँ पर SGD और मिनीबैच लागू नहीं होते हैं ( ICA के साथ एक समान कहानी)
निष्कर्ष में
यह घटनाओं, नए अच्छे लोगों और दिलचस्प कार्यों में समृद्ध एक वर्ष था। हम आशा करते हैं कि 2014 बहुत सारे महान विचारों और उन्हें जीवन में लाने के लिए और भी अधिक ताकत लाएगा और हैबर के प्रत्येक लेख के बारे में लिखेंगे। हां, हम पहले से ही अब इतना बताना चाहते हैं कि हमने एक छोटा सर्वेक्षण करने का फैसला किया है