
पिछले कुछ वर्षों में जारी किए गए लगभग सभी व्यक्तिगत कंप्यूटरों में कम से कम एक दोहरे कोर प्रोसेसर है। यदि आप, पाठक, बहुत पुराना कंप्यूटर या कुछ बजट लैपटॉप नहीं हैं, तो सबसे अधिक संभावना है कि आप मल्टीप्रोसेसर सिस्टम के मालिक हैं। और अगर आप अभी भी गेम खेलना पसंद करते हैं, तो आपके पास लगभग सौ GPU कोर तक पहुंच है। हालांकि, उस समय की शेर की सारी शक्ति धूल बेकार हो जाती है। चलो इसे ठीक करने की कोशिश करते हैं।
परिचय
बहुत कम ही, हम रोजमर्रा के कार्यों को हल करने के लिए कई प्रोसेसर (या कोर) की पूरी शक्ति का उपयोग करते हैं, और एक शक्तिशाली जीपीयू का उपयोग अक्सर कंप्यूटर गेम के लिए नीचे आता है। व्यक्तिगत रूप से, मुझे यह पसंद नहीं है: मैं काम कर रहा हूं - प्रोसेसर को आराम क्यों करना चाहिए? गड़बड़। आपको मल्टीप्रोसेसरों (मल्टी-कोर) की सभी क्षमताओं और लाभों को ध्यान में रखना होगा और जो कुछ भी संभव है उसे अपने आप में समेटना होगा, अपने आप को बहुत समय बचा सकता है। और अगर आप बोर्ड पर सैकड़ों कोर के साथ एक शक्तिशाली वीडियो कार्ड भी कनेक्ट करते हैं ... जो, निश्चित रूप से, केवल एक संकीर्ण श्रेणी के कार्यों के लिए फिट होगा, लेकिन फिर भी गणना में काफी तेजी लाएगा।
इस संबंध में लिनक्स बहुत शक्तिशाली है। सबसे पहले, अधिकांश वितरण में आउट बॉक्स अच्छे उपकरण समानांतर निष्पादन के लिए उपलब्ध हैं, और दूसरी बात यह है कि बहुत सारे सॉफ्टवेयर लिखे गए हैं जो मल्टी-कोर सिस्टम को ध्यान में रखकर बनाए गए हैं। मुझे सेटिंग्स के लचीलेपन के बारे में बात करने की आवश्यकता नहीं है। केवल वही समस्याएं उत्पन्न हो सकती हैं जो वीडियो कार्ड के लिए ड्राइवर हैं, लेकिन कुछ भी नहीं किया जाना है।
पहले, चलो समानांतरीकरण के तरीकों पर निर्णय लेते हैं। उनमें से दो हैं: आवेदन के साधन, जो कार्य को पूरा करने के लिए कई समानांतर धागे (मल्टीथ्रेडिंग) चलाता है। एक अन्य विधि आवेदन की कई प्रतियां चलाने के लिए है, जिनमें से प्रत्येक डेटा के एक निश्चित हिस्से को संसाधित करेगा। इस मामले में ऑपरेटिंग सिस्टम कोर या प्रोसेसर (मल्टीटास्किंग) के बीच प्रक्रियाओं को स्वतंत्र रूप से वितरित करेगा।
हम सीधे टर्मिनल में समानांतर करते हैं
चलो टर्मिनल विंडो से सीधे प्रक्रियाओं के समानांतर लॉन्च के साथ शुरू करते हैं। टर्मिनल पर लंबे समय तक चलने वाली रनिंग प्रॉसेस कोई समस्या पेश नहीं करती है। लेकिन अगर ऐसी दो प्रक्रियाओं की जरूरत हो तो क्या होगा? "यह भी एक समस्या नहीं है," आप कहते हैं, "हम बस एक और टर्मिनल विंडो में दूसरी प्रक्रिया शुरू करते हैं।" और अगर आपको दस या अधिक चलाने की आवश्यकता है? हम्म ... पहली बात जो दिमाग में आती है वह है xargs यूटिलिटी का इस्तेमाल करना। यदि आप उसे विकल्प देते हैं - max-procs = n, तो सॉफ़्टवेयर उसी समय n प्रक्रियाओं को निष्पादित करेगा, जो निश्चित रूप से, हमें सूट करता है। आधिकारिक मैनुअल -मैक्स-प्रॉक्स ऑप्शन (विकल्प -n) के साथ तर्कों द्वारा समूहीकरण का उपयोग करने की सिफारिश करता है: इसके बिना, समानांतर लॉन्चिंग के साथ समस्याएं हो सकती हैं। उदाहरण के लिए, कल्पना करें कि हमें बड़ी (या छोटी) फ़ाइलों का एक गुच्छा संग्रहीत करने की आवश्यकता है:
$ cd folder/with/files $ ls | xargs -n1 --max-procs=4 gzip
हमने कितना समय जीता है? क्या मुझे इससे परेशान होना चाहिए? यहां पर नंबर देना उचित होगा। मेरे क्वाड-कोर प्रोसेसर पर, पाँच फाइलों का सामान्य संग्रह, जिनमें से प्रत्येक का वजन लगभग 400 एमबी था, ने 1 मिनट 40 सेकेंड का समय लिया।
xargs --max-procs=4 का उपयोग करते हुए
xargs --max-procs=4 बीता हुआ समय लगभग चार गुना कम हो गया था: 34 s! मुझे लगता है कि प्रश्न का उत्तर स्पष्ट है।
आइए कुछ और दिलचस्प कोशिश करें। उदाहरण के लिए, एमपी 3 में लंगड़ा का उपयोग करके WAV फ़ाइलों में कनवर्ट करें:
$ ls *.wav | xargs -n1 --max-procs=4 -I {} lame {} -o {}.mp3
क्या यह अजीब लग रहा है? मैं सहमत हूं। लेकिन प्रक्रियाओं का समानांतर निष्पादन xargs का मुख्य कार्य नहीं है, बल्कि इसकी क्षमताओं में से एक है। इसके अलावा, xargs विशेष वर्णों के साथ बहुत अच्छा व्यवहार नहीं करता है, जैसे कि अंतरिक्ष या उद्धरण चिह्न। और यहां जीएनयू समानांतर नामक एक अद्भुत उपयोगिता हमारी सहायता के लिए आती है। सॉफ्टिना मानक रिपॉजिटरी में उपलब्ध है, लेकिन मैं इसे वहां से स्थापित करने की सलाह नहीं देता: उबंटू रिपॉजिटरी में, उदाहरण के लिए, मैं दो साल पहले एक संस्करण में आया था। स्रोत से नए संस्करण को संकलित करना बेहतर है:
$ wget ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2 $ tar xjf parallel-latest.tar.bz2 $ cd parallel-20130822 $ ./configure && make
उपयोगिता का नाम ही इसकी संकीर्ण विशेषज्ञता की बात करता है। दरअसल, समानांतर समानांतरकरण के लिए बहुत अधिक सुविधाजनक है, और इसका उपयोग अधिक तार्किक लगता है। Xargs के बजाय Parallel का उपयोग करने वाला उपरोक्त उदाहरण इस में बदल जाता है:
$ ls *.wav | parallel lame {} -o {}.mp3
वैसे, यदि आप उबंटू या कुबंटु के नीचे बैठे हैं, तो उदाहरण अजीब त्रुटियों को देखते हुए काम नहीं करेगा। यह कुंजी '--gnu' को जोड़कर तय किया गया है (निम्नलिखित उदाहरण पर लागू होता है)। समस्या के बारे में
यहाँ और पढ़ें।
और हम एक साथ निष्पादित प्रक्रियाओं की संख्या निर्धारित क्यों नहीं करते हैं? क्योंकि समानांतर यह हमारे लिए करेगा: यह कोर की संख्या निर्धारित करेगा और कर्नेल पर प्रक्रिया को चलाएगा। बेशक, आप -j विकल्प का उपयोग करके मैन्युअल रूप से इस नंबर को सेट कर सकते हैं। वैसे, यदि आपको विभिन्न मशीनों पर कार्य चलाने की आवश्यकता है, तो पोर्टेबिलिटी में सुधार करने के लिए यह विकल्प को -j +2 प्रारूप में सेट करना सुविधाजनक है, जिसका अर्थ है कि इस विशेष मामले में "सिस्टम में कंप्यूटिंग इकाइयों की तुलना में एक साथ दो और प्रक्रियाएं चलाएं"।
यदि हम पायथन के साथ समानांतर दोस्त बनाते हैं, तो हमें समानांतर कार्यों के लिए एक शक्तिशाली उपकरण मिलता है। उदाहरण के लिए, वेब से वेब पेज डाउनलोड करना और उनकी बाद की प्रोसेसिंग इस तरह दिख सकती है:
$ python makelist.py | parallel -j+2 'wget "{}" -O - | python parse.py'
लेकिन पायथन के बिना भी, इस उपयोगिता में बहुत सारी विशेषताएं हैं। आदमी को पढ़ना सुनिश्चित करें - बहुत सारे दिलचस्प उदाहरण हैं।
समानांतर और xargs के अलावा, निश्चित रूप से, समान कार्यक्षमता वाले कई अन्य उपयोगिताओं हैं, लेकिन वे कुछ भी नहीं जानते हैं कि पहले दो नहीं हो सकते।
हमने इसका पता लगा लिया। हम आगे बढ़ते हैं।
समानांतर संकलन
स्रोत से कुछ एकत्र करना लिनक्स के लिए एक सामान्य बात है। सबसे अधिक बार आपको कुछ तुच्छ इकट्ठा करना पड़ता है, ऐसी परियोजनाओं के लिए कोई भी किसी भी समानांतर संकलन के बारे में नहीं सोचता है। लेकिन कभी-कभी बड़ी परियोजनाएं सामने आती हैं, और बिल्ड के खत्म होने का इंतजार करने में लगभग अनंत काल लगता है: भवन, उदाहरण के लिए, स्रोत से एंड्रॉइड (एओएसपी) (एक धागे में) लगभग पांच घंटे लगते हैं! ऐसी परियोजनाओं के लिए, आपको सभी कोर का उपयोग करने की आवश्यकता है।
सबसे पहले, मुझे लगता है कि यह स्पष्ट है कि संकलन (उदाहरण के लिए जीसीसी) समानांतर नहीं है। लेकिन बड़ी परियोजनाएं अक्सर बड़ी संख्या में स्वतंत्र मॉड्यूल, पुस्तकालयों और अन्य चीजों से बनी होती हैं जिन्हें एक ही समय में संकलित किया जाना चाहिए। बेशक, हमें यह सोचने की ज़रूरत नहीं है कि संकलन को कैसे समानांतर किया जाए - मेक इस बात का ध्यान रखेगा, लेकिन केवल इस शर्त पर कि मेकअप में निर्भरताएं लिखी गई हैं। अन्यथा, पता नहीं होगा कि किस क्रम में इकट्ठा करना है और एक ही समय में क्या एकत्र किया जा सकता है और क्या नहीं। और चूंकि मेकफाइल डेवलपर्स की चिंता है, हमारे लिए यह सब एक कमांड निष्पादित करने के लिए आता है
$ make -jN
जिसके बाद मेक, N कार्यों को एक साथ शुरू करते हुए, परियोजना का निर्माण शुरू करेगा।
वैसे, -j विकल्प के लिए एक मान चुनने के बारे में। वेब पर, अक्सर 1.5 नंबर का उपयोग करने की सिफारिश की जाती है <<कंप्यूटिंग इकाइयों की संख्या>। लेकिन यह हमेशा सच नहीं होता है। उदाहरण के लिए, मेरे क्वाड कोर पर 250 एमबी के कुल वजन के साथ एक परियोजना का निर्माण चार के -जे पैरामीटर मान (स्क्रीन देखें) के साथ सबसे तेज था।
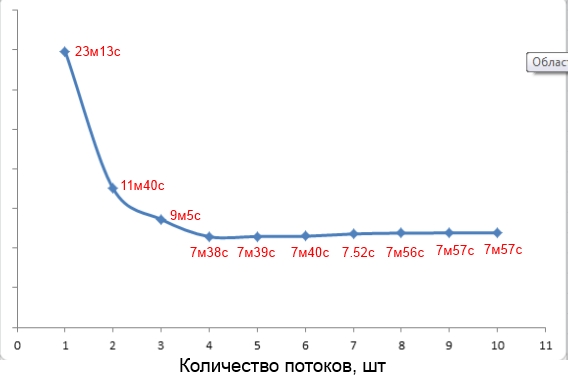
पैरामीटर मान पर संकलन समय की निर्भरता
कुछ और समय हासिल करने के लिए, आप जीसीसी में -पाइप स्विच को जोड़ सकते हैं। इस कुंजी के साथ, संकलन के विभिन्न चरणों के बीच डेटा स्थानांतरण पाइप के माध्यम से होता है, न कि अस्थायी फ़ाइलों के माध्यम से, जो प्रक्रिया को थोड़ा (बहुत कम) गति देता है।
बनाने के अलावा, आप
पायटेक में लिखे गए समानांतर बिल्ड सिस्टम
pmake को भी आज़मा सकते हैं। जूज़वेयर्स के लिए, इसका उपयोग मेक से बहुत अलग नहीं है, लेकिन डेवलपर्स के लिए यह काफी दिलचस्प हो सकता है, क्योंकि इसमें मानक उपकरण की तुलना में अधिक व्यापक क्षमताएं हैं।
समानांतर रु
यदि आपने कभी रिमोट सर्वर के साथ बड़ी संख्या में छोटी फ़ाइलों को सिंक्रनाइज़ करने के लिए रुपीस का उपयोग किया है, तो आपको संभवतः फ़ाइल सूची चरण में एक सभ्य देरी दिखाई दी। क्या इस चरण को समानांतर करके त्वरित किया जा सकता है? बेशक आप कर सकते हैं। नेटवर्क देरी पर बहुत समय बिताया जाता है। इन अस्थायी नुकसानों को कम करने के लिए, हम रुपये की कई प्रतियाँ चलाएँगे, और इसलिए कि एक ही फाइल की नकल नहीं की जाती है, हम प्रत्येक कॉपी को, उदाहरण के लिए, एक अलग निर्देशिका में सेट करेंगे। ऐसा करने के लिए, हम --include और --exclude विकल्पों के संयोजन में शामिल होते हैं, उदाहरण के लिए:
$ rsync -av --include="/a*" --exclude="/*" -P login@server:remote /localdir/ $ rsync -av --include="/b*" --exclude="/*" -P login@server:remote /localdir/
आप विभिन्न टर्मिनलों में मैन्युअल रूप से कई प्रतियां शुरू कर सकते हैं, लेकिन आप समानांतर कनेक्ट कर सकते हैं:
$ cat directory_list.txt | parallel rsync -av --include="/{}*" --exclude="/*" ...
एसएसएच टर्बो जेट फाइल कॉपी
आमतौर पर, दो मेजबानों के बीच निर्देशिकाओं को सिंक्रनाइज़ करने के लिए, रुपये को SSH के शीर्ष पर चलाया जाता है। SSH कनेक्शन को तेज करने के बाद, हम Rsync के काम को गति देंगे। और एसएसएच को ओपनएसएसएच एचपीएन पैच सेट का उपयोग करके त्वरित किया जा सकता है, जो एसएसएच के सर्वर और क्लाइंट भागों को बफर करने के लिए तंत्र में कई बाधाओं को समाप्त करता है। इसके अलावा, एचपीएन एईएस-सीटीआर एल्गोरिथ्म के एक बहु-थ्रेडेड संस्करण का उपयोग करता है, जो फ़ाइलों की एन्क्रिप्शन गति बढ़ाता है (
-oCipher=aes[128|192|256]-ctr द्वारा सक्रिय
-oCipher=aes[128|192|256]-ctr )। यह जाँचने के लिए कि आपके पास ओपनएसएसएच एचपीएन स्थापित है, टर्मिनल में टाइप करें:
$ ssh -V
और HPN सबस्ट्रिंग एंट्री की तलाश करें। यदि आपके पास सामान्य ओपनएसएसएच है, तो आप एचपीएन संस्करण को इस तरह से स्थापित कर सकते हैं:
$ sudo add-apt-repository ppa:w-rouesnel/openssh-hpn $ sudo apt-get update -y $ sudo apt-get install openssh-server
फिर लाइनों को
/etc/ssh/sshd_config :
HPNDisabled no TcpRcvBufPoll yes HPNBufferSize 8192 NoneEnabled yes
फिर SSH सेवा को पुनः आरंभ करें। अब फिर से Rsync / SSH / SCP कनेक्शन बनाएं और लाभ का मूल्यांकन करें।

HPN समर्थन सक्षम करें
फ़ाइल संपीड़न
ऊपर हमने जो भी त्वरण किया, वे एक ही प्रक्रिया की कई प्रतियों के एक साथ लॉन्च पर आधारित हैं। ऑपरेटिंग सिस्टम के प्रक्रिया अनुसूचक ने हमारी मशीन के कोर (प्रोसेसर) के बीच इन प्रक्रियाओं को हल किया, जिसके कारण हमें त्वरण मिला। आइए उस उदाहरण पर वापस जाएं जहां हमने कई फाइलें संपीड़ित की हैं। लेकिन क्या होगा अगर आपको एक बड़ी फ़ाइल को संकुचित करने की आवश्यकता है, और यहां तक कि धीमी bzip2 भी? सौभाग्य से, फ़ाइल संपीड़न अपने आप को समानांतर प्रसंस्करण के लिए बहुत अच्छी तरह से उधार देता है - फ़ाइल ब्लॉकों में विभाजित है और वे स्वतंत्र रूप से संकुचित हैं। हालांकि, gzip और bzip2 जैसी मानक उपयोगिताओं में यह कार्यक्षमता नहीं है। सौभाग्य से, कई तृतीय-पक्ष उत्पाद हैं जो ऐसा कर सकते हैं। उनमें से केवल दो पर विचार करें:
गज़िप का समानांतर एनालॉग -
पिगज़ और
बीज़िप 2 का एनालॉग -
pbzip2 । ये दोनों उपयोगिताओं मानक Ubuntu रिपॉजिटरी में उपलब्ध हैं।
थ्रेड्स और ब्लॉक आकार की संख्या को निर्दिष्ट करने की क्षमता को छोड़कर, पिगज़ का उपयोग गज़िप के साथ काम करने से बिल्कुल अलग नहीं है। ज्यादातर मामलों में, ब्लॉक का आकार डिफ़ॉल्ट रूप से छोड़ा जा सकता है, लेकिन थ्रेड्स की संख्या के रूप में, सिस्टम के प्रोसेसर (कोर) की संख्या (या 1-2 अधिक) के बराबर संख्या को इंगित करना वांछनीय है:
$ pigz -c -p5 backup.tar > pigz-backup.tar.gz
इस कमांड को एक बैकअप.टार पर चलाना। 620 एमबी वजन वाली फाइल ने मुझे 12.8 एस लिया, जिसके परिणामस्वरूप फाइल का वजन 252.2 एमबी था। Gzip के साथ समान फ़ाइल संसाधित करना:
$ gzip -c backup.tar > gzip-backup.tar.gz
43 एस लिया। उसी समय, परिणामी फ़ाइल का वजन पहले के मुकाबले केवल 100 KB कम था: 252.1 एमबी। फिर से, हमें लगभग चार गुना त्वरण मिला, जो अच्छी खबर है।
पिगज़ केवल संपीड़न को समानांतर कर सकता है, लेकिन अपघटन नहीं, जिसे pbzip2 के बारे में नहीं कहा जा सकता है - जो दोनों कर सकते हैं। उपयोगिता का उपयोग करना इसके गैर-समानांतर संस्करण के समान है:
$ pbzip2 -c -p5 backup.tar > pbzip-backup.tar.bz2
उसी बैकअप को संसाधित करना। टार फाइल ने मुझे 38.8 सेकेंड में लिया, परिणामी फाइल का आकार 232.8 एमबी था। नियमित bzip2 का उपयोग करने वाले संपीड़न ने 1 मिनट 53 एस लिया, जिसकी फ़ाइल का आकार 232.7 एमबी है।
जैसा कि मैंने पहले ही कहा, pbzip2 के साथ आप अनपैकिंग को भी तेज कर सकते हैं। लेकिन यहां आपको एक बारीकता को ध्यान में रखने की आवश्यकता है - समानांतर में आप केवल वही पैक कर सकते हैं जो पहले समानांतर में पैक किया गया था, अर्थात, केवल pbzip2 का उपयोग करके बनाए गए अभिलेखागार। सामान्य स्ट्रीम bzip2 संग्रह की कई धाराओं में अनपैकिंग एक स्ट्रीम में की जाएगी। खैर, कुछ और संख्याएँ:
- सामान्य अनपैकिंग - 40.1 एस;
- पांच धाराओं में अनपैकिंग - 16.3 एस।
यह केवल यह जोड़ना है कि पिग और pbzip2 का उपयोग करके बनाए गए अभिलेखागार अपने गैर-समानांतर समकक्षों का उपयोग करके बनाए गए अभिलेखों के साथ पूरी तरह से संगत हैं।
एन्क्रिप्शन
डिफ़ॉल्ट रूप से, eCryptfs का उपयोग Ubuntu और सभी व्युत्पन्न वितरणों में होम डायरेक्टरी को एन्क्रिप्ट करने के लिए किया जाता है। लेखन के समय, eCryptfs ने मल्टीथ्रेडिंग का समर्थन नहीं किया। और यह विशेष रूप से बड़ी संख्या में छोटी फ़ाइलों वाले फ़ोल्डरों में ध्यान देने योग्य है। इसलिए यदि आपके पास मल्टी-कोर है, तो eCryptfs उपयोग करने के लिए व्यावहारिक नहीं है। एक बेहतर प्रतिस्थापन dm-crypt या Truecrypt सिस्टम का उपयोग करना होगा। सच है, वे केवल पूरे विभाजन या कंटेनरों को एन्क्रिप्ट कर सकते हैं, लेकिन वे मल्टी-थ्रेडिंग का समर्थन करते हैं।
जानकारी
नेटबीएसडी 6.0 एनपीएफ पैकेट फ़िल्टर आपको कम से कम तालों के साथ समानांतर बहु थ्रेडेड पैकेट प्रसंस्करण के कारण मल्टी-कोर सिस्टम पर अधिकतम प्रदर्शन प्राप्त करने की अनुमति देता है।
यदि आप केवल एक विशिष्ट डायरेक्टरी को एनक्रिप्ट करना चाहते हैं, न कि पूरी डिस्क को, तो आप
EncFS की कोशिश कर सकते हैं। यह eCryptfs के समान है, लेकिन यह बाद वाले के विपरीत काम करता है, कर्नेल मोड में नहीं, बल्कि FUSE का उपयोग करके, जो इसे eCryptfs की तुलना में धीमा बनाता है। लेकिन यह मल्टी-थ्रेडिंग का समर्थन करता है, इसलिए मल्टी-कोर सिस्टम पर गति में लाभ होगा। इसके अलावा, इसे स्थापित करना (अधिकांश मानक रिपॉजिटरी में उपलब्ध) और उपयोग करना बहुत आसान है। आपको बस इतना करना है
$ encfs ~/.crypt-raw ~/crypt
पासफ़्रेज़ दर्ज करें, और वह यह है: फ़ाइलों के .crypt-raw एन्क्रिप्टेड संस्करण झूठ होंगे, और क्रिप्ट - अनएन्क्रिप्टेड संस्करणों में। EncFS को अनमाउंट करने के लिए, करें:
$ fusermount -u ~/name
बेशक, यह सब स्वचालित हो सकता है। आप
यहां यह करने के बारे में पढ़ सकते हैं।
मुझे यह देखना पसंद है कि गुठली कैसे जुताई होती है
हम प्रोसेसर को पूर्ण रूप से लोड करते हैं, लेकिन कभी-कभी इसके संचालन की निगरानी करना आवश्यक है। सिद्धांत रूप में, लगभग हर वितरण में प्रोसेसर के उपयोग की निगरानी के लिए एक अच्छा स्नैप-इन होता है, जिसमें प्रत्येक व्यक्तिगत कोर या प्रोसेसर के बारे में जानकारी शामिल होती है। कुबंटु में, उदाहरण के लिए, KSysGuard बहुत ही सफलतापूर्वक वर्तमान कर्नेल लोड दिखाता है (स्क्रीन को देखें "केडीसगार्ड को क्वाड-कोर सिस्टम पर")।
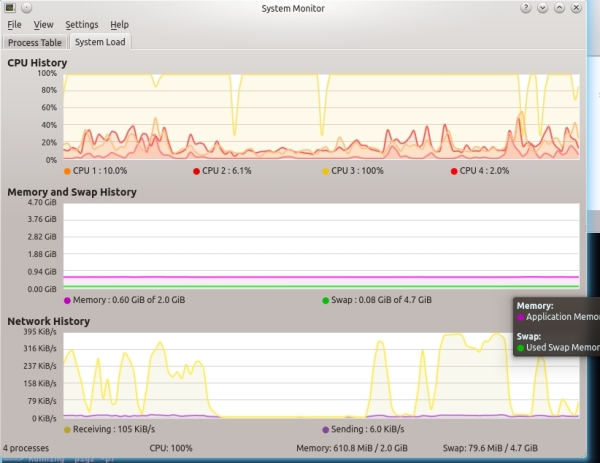
एक ट्रैक्टर प्रणाली पर KSysGuard
लेकिन अन्य दिलचस्प उपयोगिताओं हैं जो आपको प्रोसेसर पर विचार करने की अनुमति देते हैं। कंसोल सॉल्यूशन के प्रशंसक शीर्ष को पसंद करेंगे - शीर्ष का एक अधिक रंगीन और इंटरैक्टिव एनालॉग। मैं आपको सलाह देता हूं कि आप
कोन्की पर ध्यान दें - एक शक्तिशाली और आसानी से अनुकूलन योग्य सिस्टम मॉनिटर। एक पूरे के रूप में प्रत्येक कोर और प्रोसेसर के भार की निगरानी के लिए इसे कॉन्फ़िगर करना बहुत आसान है। प्रत्येक कोर के लिए, आप एक अलग ग्राफ प्रदर्शित कर सकते हैं। स्क्रीनशॉट में आप मेरी उपयोगिता कॉन्फ़िगरेशन विकल्प देख सकते हैं।

ऐसा ही कॉन्की दिखता है
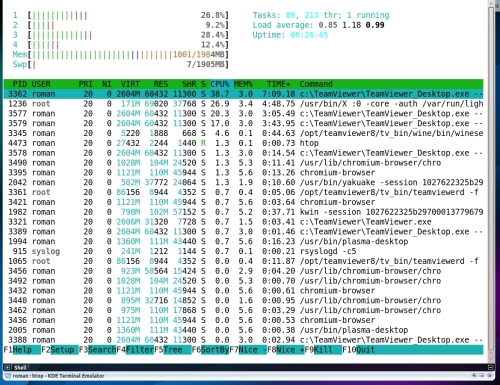
कार्रवाई में खोखला
इसी विन्यास फाइल की सामग्री जो मैंने
यहां पोस्ट की
है । वैसे, नेटवर्क दिलचस्प कॉन्फ़िगरेशन से भरा है जिसे आधार के रूप में लिया जा सकता है और अपने लिए रीमेक किया जा सकता है।
लेकिन ये उपयोगिताओं केवल कार्यभार के बारे में जानकारी प्रदान करती हैं, जो अक्सर पर्याप्त नहीं हो सकती हैं। Sysstat संग्रह से
Mpstat अधिक रोचक जानकारी प्रदान करता है, जैसे कि प्रत्येक कोर का निष्क्रिय समय, I / O के इंतजार में बिताया गया समय, या समय बिताया गया प्रसंस्करण बाधित होता है।

Mpstat उपयोगिता आउटपुट
GPU न केवल खेल के लिए
यह कोई रहस्य नहीं है कि आधुनिक जीपीयू में बहुत बड़ी कंप्यूटिंग शक्ति है। लेकिन इस तथ्य के कारण कि GPU कोर में एक विशेष वास्तुकला और उपलब्ध आदेशों का एक सीमित सेट है, GPU केवल कार्यों की एक संकीर्ण श्रेणी को हल करने के लिए उपयुक्त है। पहले, केवल shader गुरु ही GPU कंप्यूटिंग कर सकते थे। अब, वीडियो कार्ड निर्माता उत्साही और डेवलपर्स के जीवन को सरल बनाने के लिए हर संभव कोशिश कर रहे हैं जो अपनी परियोजनाओं में ग्राफिक्स प्रोसेसर की शक्ति का उपयोग करना चाहते हैं: NVIDIA से CUDA, AMD FireStream, खुले मानक
OpenCL । हर साल, GPU कंप्यूटिंग अधिक से अधिक सुलभ होता जा रहा है।
हैश कैलकुलेशन
आज तक, GPU पर शुरू किए गए कार्यों में, हैश की गणना संभवतः सबसे लोकप्रिय है। और यह सब बिटकॉइन खनन के कारण है, जो वास्तव में, हैश की गणना करना है। अधिकांश बिटकॉइन खनिक लिनक्स के तहत उपलब्ध हैं। यदि आप Bitcoins माइन करना चाहते हैं और यदि आपका GPU OpenCL का समर्थन करता है (यदि यह CUDA का समर्थन करता है, तो OpenCL भी), तो मैं
bfgminer पर ध्यान देने की सलाह देता
हूं : यह तेज़, सुविधाजनक और कार्यात्मक है, हालाँकि इसे सेट करना इतना आसान नहीं है।
GPU Snort त्वरण
यूनानी संस्थान FORTH (फाउंडेशन फॉर रिसर्च एंड टेक्नोलॉजी - हेलस) के शोधकर्ताओं द्वारा ग्नॉर्ट नामक एक बहुत ही दिलचस्प अवधारणा विकसित की गई थी। वे सुझाव देते हैं कि GPU पर नियमित अभिव्यक्ति की जांच के लिए जिम्मेदार कोड को स्थानांतरित करके स्नॉर्ट हमले का पता लगाने की दक्षता बढ़ाई जाए। आधिकारिक अध्ययन पीडीएफ में दिए गए ग्राफ़ के अनुसार, उन्होंने स्नॉर्ट थ्रूपुट में लगभग दो गुना वृद्धि हासिल की।
लेकिन हम एक बिटकॉइन के रूप में नहीं रहते हैं। Brute Force hashes के लिए GPU की शक्ति का उपयोग करने से कुछ भी नहीं रोकता है (ताकि आपके भूल गए पासवर्ड का पता लगा सके, निश्चित रूप से, अब और नहीं)। इस समस्या को हल करने में,
महासंकट-प्लस उपयोगिता ने खुद को साबित कर दिया है - एक असली हैश-हारवेस्टर। नमक, SHA-1, NTLM, कैश्ड डोमेन पासवर्ड, MySQL डेटाबेस पासवर्ड, GRUB पासवर्ड के साथ और बिना MD5 हैश को लेने में सक्षम, और यह आधी सूची में भी नहीं है।
GPU एन्क्रिप्शन
केजीपीयू परियोजना के हिस्से के रूप में यूटा विश्वविद्यालय के
वेइबिन सन और जिंग लिन के छात्रों ने जीपीयू क्षमताओं का
एक बहुत ही दिलचस्प आवेदन
प्रस्तुत किया । परियोजना का सार लिनक्स कर्नेल कोड के कुछ हिस्सों का निष्पादन CUDA- संगत जीपीयू में स्थानांतरित करना है। पहले डेवलपर्स ने एईएस एल्गोरिथ्म को जीपीयू पर पेश करने का फैसला किया। दुर्भाग्य से, परियोजना का विकास रुक गया, हालांकि डेवलपर्स ने काम जारी रखने का वादा किया। लेकिन इसके अलावा, मौजूदा अनुभव का उपयोग ई-क्रिप्टो और डीएम-क्रिप्ट में एईएस एन्क्रिप्शन को तेज करने के लिए किया जा सकता है, यह एक दया है कि कर्नेल संस्करण 3.0 और उच्चतर समर्थित नहीं है।
GPU प्रदर्शन की निगरानी
क्यों नहीं? बेशक, प्रत्येक कोर GPU पर लोड का पता लगाना संभव नहीं होगा, लेकिन आप GPU पर क्या हो रहा है, इसके बारे में कम से कम कुछ जानकारी प्राप्त कर सकते हैं। CUDA-Z प्रोग्राम (लगभग Windows प्रोग्राम GPU-Z का एक एनालॉग), GPU के बारे में विभिन्न स्थिर जानकारी के अलावा, गतिशील जानकारी भी प्राप्त कर सकता है: GPU और मशीन के बीच डेटा विनिमय की वर्तमान गति, साथ ही फ्लॉप में सभी GPU कोर का समग्र प्रदर्शन।
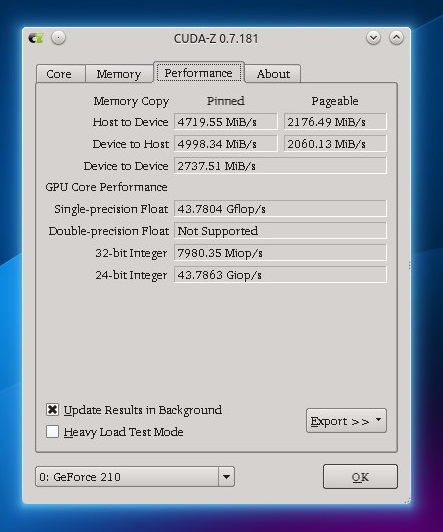
GPU प्रदर्शन जानकारी के साथ CUDA-Z टैब
निष्कर्ष
मल्टी-कोर या मल्टी-प्रोसेसर वर्कस्टेशन लंबे समय से हमारे दैनिक जीवन में शामिल हैं - यह उनके साथ काम करते समय हमारे एकल-थ्रेडेड दृष्टिकोण को बदलने का समय है। वास्तव में, इस तरह के सिस्टम पर कार्यों का समानांतर हमें समय में भारी लाभ देता है, जैसा कि हमने देखा है।
उपयोगी लिंक
- मल्टी-कोर सिस्टम पर जावा ईई अनुप्रयोगों के प्रदर्शन को बढ़ाने के लिए जेवीएम ट्यूनिंग:
bit.ly/JavaTuning - MPI परीक्षणों का उपयोग करके मल्टी-कोर सीपीयू का प्रदर्शन माप: bit.ly/MPIbenchmark
- यदि आपके पास अपने कंप्यूटर पर लेने के लिए कुछ भी नहीं है, तो दवाओं की खोज करने के लिए कंप्यूटिंग शक्ति छोड़ें, ग्लोबल वार्मिंग और अन्य रोचक वैज्ञानिक अनुसंधान का अध्ययन करें: https://boinc.berkeley.edu
 हैकर पत्रिका में पहली बार दिनांक 10/2013 को प्रकाशित किया गया।जारी करने के लिए जारी करें
हैकर पत्रिका में पहली बार दिनांक 10/2013 को प्रकाशित किया गया।जारी करने के लिए जारी करेंहैकर की सदस्यता लें

