उत्पादन
बिजनेस इंटेलिजेंस सॉल्यूशंस (बिजनेस एनालिटिक्स) की समस्या में एक स्वचालित प्रक्रिया या प्रक्रियाओं के एक सेट के परिणामों पर सांख्यिकीय, विश्लेषणात्मक जानकारी के साथ इच्छुक व्यक्तियों को प्रदान करना शामिल है।
उदाहरण के लिए, इलेक्ट्रॉनिक स्टोर में लोगों द्वारा की गई खरीदारी को ठीक करने की एक व्यावसायिक प्रक्रिया है। व्यावसायिक प्रक्रिया के संबंधपरक मॉडल में, स्वाभाविक रूप से विक्रेता, खरीदार, सामान और अन्य संस्थाएं होंगी। इसके अलावा, यदि व्यवसाय प्रक्रिया सफल है, अर्थात्। डेटा का काफी तीव्र प्रवाह है, आर्थिक समस्याओं सहित विभिन्न समस्याओं को हल करने के लिए इस डेटा का विश्लेषण करने की आवश्यकता है। फाइनेंसरों के लिए, यह प्रतिबिंबित करने वाला डेटा का एक संग्रह होगा:
- इस वर्ष की पहली तिमाही के लिए माल की संख्या बेची गई
- विक्रेताओं द्वारा पिछले वर्ष बेची गई वस्तुओं की मात्रा
- मासिक स्लाइस में एक निश्चित प्रकार के उत्पाद की बिक्री की गतिशीलता
- और कई अन्य
इसके अलावा, अगर हम एक होल्डिंग के बारे में बात कर रहे हैं, जिसमें दुकानें, रेस्तरां और अन्य प्रकार की गतिविधियां शामिल हैं, तो डेटा की मात्रा बढ़ जाती है, जो कभी-कभी विश्लेषणात्मक डेटा के प्रकारों में वृद्धि की ओर भी ले जाती है।
इस प्रकार, डेवलपर डेटा विश्लेषण के लिए सबसे व्यापक, सबसे प्रभावी और सुविधाजनक उपकरण प्रदान करने की समस्या का सामना करता है। ओएलएपी समाधान विभिन्न ब्रांडों जैसे कि ओरेकल, एसएपी, माइक्रोसॉफ्ट, माइक्रोस्ट्रैटी, पेंटाहो और कई अन्य लोगों द्वारा पेश किया गया है।
मैं पहले से कुछ आरक्षण करना चाहता हूं:
- लेख में विशेष रिपॉजिटरी (डीबीएमएस) का उपयोग किए बिना रैम में मल्टीपरमीटर डेटा संग्रहीत करने के लिए एक विधि प्रस्तावित है, जो व्यापार खुफिया समाधान (बिजनेस इंटेलिजेंस) के लिए मुख्य हैं
- लेख में OLAP क्यूब्स, MOLAP, ROLAP, HOLAP के शास्त्रीय रूप में उनके निर्माण के सिद्धांतों पर चर्चा नहीं की जाएगी। उनके लिए एक परिचय के लिए, मैं निम्नलिखित लेखों की सिफारिश करता हूं:
habrahabr.ru/post/66356 - बहुआयामी क्यूब्स, OLAP और MDX
habrahabr.ru/post/187782 - चरणों में एक Pentaho- आधारित OLAP सर्वर शुरू करना
habrahabr.ru/post/67272 - एक OLAP घन बनाएँ भाग 1
habrahabr.ru/company/eastbanctech/blog/173711 - सरल बीआई समाधान बनाते समय शुरुआती के लिए 6 व्यावहारिक सुझाव।
मान लीजिए कि ब्रांडों द्वारा पेश किए गए समाधान किसी विशिष्ट कार्य के लिए पूरी तरह से उपयुक्त नहीं हैं (ऐसा होता है कि वे बिल्कुल उपयुक्त नहीं हैं), या कंपनी का बजट किसी विशेष ब्रांड के उपयोग की अनुमति नहीं देता है।
मॉडल डिजाइन
पिछले 3 वर्षों में मेरी गतिविधि को देखते हुए, मैं HTML तकनीक और पुस्तकालयों जैसे DevExpress, HighCharts, ExtJS का उपयोग कर उपयोगकर्ताओं को समाप्त करने के लिए बहु-पैरामीटर डेटा प्रदान करने के लिए व्यावसायिक डैशबोर्ड बना रहा हूं। एग्रीगेट स्टोरेज की एक विशेषता गहन डेटा रीडिंग और ब्लॉक अपडेटिंग है। काम के हिस्से के रूप में, विभिन्न प्रकार के संबंधपरक डेटा मॉडल को स्टोर करने वाले समुच्चय के लिए परीक्षण किया गया था, हालांकि, इनमें से किसी भी प्रकार ने वांछित प्रभाव नहीं दिया - उच्च पढ़ें गति। इस लेख में वर्णित समाधान का नेतृत्व किया गया - रैम में सभी एकत्रित डेटा को संग्रहीत करना, जो निम्न कार्यों को पूरा करता है:
- रैम का किफायती उपयोग
- निर्दिष्ट मानदंडों के अनुसार डेटा निकालने के लिए कुशल एल्गोरिदम
- फ़ाइल भंडारण से डेटा का संग्रहण और पढ़ना
सबसे पहले, उन संस्थाओं को निर्धारित करना आवश्यक है जिनके साथ हम काम करेंगे:
- एक संकेतक मात्रात्मक और गुणात्मक विशेषताओं द्वारा परिभाषित एक नामित इकाई है। उदाहरण के लिए - "आय" या "व्यय"
- माप की एक इकाई एक नामित इकाई है जो उस माप को परिभाषित करती है जिसमें एक माप की गणना की जाती है। उदाहरण के लिए - "डॉलर" या "रूबल"
- निर्देशिका की निर्देशिका और तत्व एक नामित इकाई है जो संकेतक के साथ जुड़े गुणात्मक विशेषताओं को परिभाषित करता है। उदाहरण के लिए, "यौन निर्देशिका", जिसमें "पुरुष" और "महिला" तत्व शामिल हैं
- अवधि - एक नामित संस्था जो उस समय अवधि को परिभाषित करती है जिसके लिए माप लिया गया था। उदाहरण के लिए - "वर्ष", "तिमाही", "महीना", "दिन"
- मूल्य - एक नामित संस्था जो संख्यात्मक रूप में एकत्रित मूल्य को परिभाषित करती है
भंडार में संग्रहीत किए जाने वाले डेटा के निम्नलिखित उदाहरण निम्नानुसार हैं:
- उद्यम की सूचक "आय", "महिला" के संदर्भ में "2011" की अवधि में 300 "डॉलर" का मूल्य था
- सूचक "उपभोग" उद्यम की अवधि में, "2013 की 1 तिमाही" में 100 "रूबल" का मूल्य था।
इस प्रकार परिभाषित इकाइयाँ होने के बाद, कक्षाओं के ऑब्जेक्ट मॉडल को निर्धारित करना आवश्यक है जो उनके रिश्ते को निर्धारित करता है।
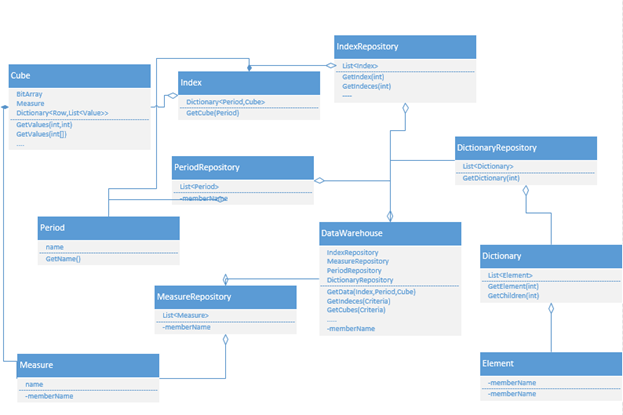
जैसा कि आप आंकड़े से देख सकते हैं, वर्ग आरेख में उपयोगिता वर्ग, जैसे
ऑब्जेक्ट नाम रिपॉजिटरी, डेटावेयर शामिल हैं। डेटा संग्रह के साथ काम करते समय ये कक्षाएं उपयोग करने के लिए सुविधाजनक हैं और मुख्य इंटरफेस को परिभाषित करना आवश्यक है जो किसी दिए गए नियम के अनुसार वस्तुओं को प्रदान करते हैं।
सूचकांक वर्ग - "संकेतक" के सार का वर्णन करता है, जिसमें संकेतक के नाम, संकेतक की दृश्यता विशेषताओं और किसी विशेष अनुप्रयोग के लिए आवश्यक अन्य विशेषताओं जैसे लक्षण शामिल हैं। इंडेक्स क्लास में क्यूब क्लास शामिल है।
क्यूब वर्ग सूचक मूल्यों की गुणात्मक विशेषताओं और स्वयं मूल्यों (उर्फ डेटा क्यूब) का भंडार है। विशेषताओं के प्रत्येक सेट को क्यूब के सभी आयामों के चौराहे पर एक बिंदु है। उदाहरण के लिए - यदि हमारे पास 3 विशेषताओं का घन है, जैसे, उदाहरण के लिए, "वजन", "रंग", "आकार", तो इस 3-आयामी स्थान में प्रत्येक बिंदु इन आयामों में से प्रत्येक के लिए स्थापित मानदंड का गठन करेगा। । किसी भी डेटा क्यूब को दो-आयामी मैट्रिक्स के रूप में दर्शाया जा सकता है - जहां मैट्रिक्स के कॉलम में संदर्भ होंगे, और लाइनें निर्दिष्ट विशेषताओं को देंगी। उदाहरण के लिए, ऐसे मैट्रिक्स में पंक्ति 1 में "वजन - 100 किग्रा", "रंग - लाल", "आकार - छोटा" जैसे मान हो सकते हैं। फिर, डेटा समुच्चय के भंडारण के लिए, मैट्रिक्स को विशेषताओं के सभी संभावित संयोजनों का वर्णन करना आवश्यक है। ऐसी कक्षा बनाते समय, आप रैम में डेटा स्टोरेज को अनुकूलित करने के लिए दो तरीकों का उपयोग कर सकते हैं:
- ऑफसेट का उपयोग कर एक आयामी डेटा सरणी का उपयोग करें
- एक बिटमैप का उपयोग करें। इस मामले में, मैट्रिक्स के प्रत्येक स्तंभ का उसकी विविधता के लिए विश्लेषण करना प्रस्तावित है। उदाहरण के लिए, "लिंगों की निर्देशिका" कॉलम के लिए, आपको केवल तीन मान चाहिए - "कुल", "पुरुष", "महिला"। फिर इस कॉलम में एक मान रखने वाले अधिकतम डेटा केवल 3 बिट्स हो सकते हैं। और इसलिए प्रत्येक निर्देशिका के लिए
क्यूब वर्ग में माप वर्ग शामिल है, जो गुणवत्ता विशेषताओं के पूरे सेट के लिए माप की एक सामान्य इकाई को परिभाषित करता है। यह आपको उपलब्ध विशेषताओं के आधार पर माप की विभिन्न इकाइयों में संकेतकों के मूल्यों को संग्रहीत करने की अनुमति देता है। यानी अलग-अलग क्यूब्स में एक ही संकेतक में क्यूब के अनुरूप माप की एक इकाई हो सकती है। उदाहरण के लिए, यह संकेतक "उत्पादों की बिक्री" हो सकता है, जिसे भौतिक रूप में मापा जाएगा - "बात" और मौद्रिक "खंडहर" में। यह लेख केवल सरल प्रकार के संकेतक प्रदान करता है, जिनमें से माप की इकाई केवल एक घन के लिए एक हो सकती है। व्यवहार में, ऐसे संकेतक हैं, माप की इकाई जिसके लिए घन में गुणवत्ता विशेषताओं के आधार पर भिन्नता है। फिर एक नए स्तर के सार में जाना आवश्यक है, और उन कक्षाओं को पेश करना है जो सरल डेटा सेट और जटिल लोगों की सेवा करते हैं।
क्यूब वर्ग को स्वयं मूल्य शामिल करना चाहिए - मान सेट। यानी विशेषताओं के प्रत्येक सेट - में एक संख्या द्वारा व्यक्त मूल्य होना चाहिए और होना चाहिए। इस स्तर पर, आप रैम में उनके भंडारण का अनुकूलन करने के लिए डेटा वर्गीकरण विधियों को लागू कर सकते हैं। उदाहरण के लिए, डेटाबेस के साथ काम करना और संख्यात्मक मान के लिए भंडारण या फ़ील्ड चुनना - ज्यादातर मामलों में आप अधिकतम संभव फ़्लोटिंग पॉइंट नंबर चुनते हैं। हालांकि, यह बहुत संसाधन गहन है, खासकर जब यह रैम की बात आती है। व्यवहार में, सभी संकेतकों को ऐसी सटीकता की आवश्यकता नहीं होती है। उदाहरण के लिए - संकेतक "योजना का प्रतिशत", 0 से 100 तक केवल पूर्णांक मान की आवश्यकता हो सकती है। जिसके लिए एक बाइट पर्याप्त है। इस प्रकार, BYTE से DECIMAL तक - अधिकतम आवश्यक प्रकार निर्धारित करने के लिए प्रत्येक संकेतक के लिए डेटा का प्रारंभिक विश्लेषण लागू करना संभव है। फिर आप सार के स्तर पर जा सकते हैं - और इस वर्ग से सब कुछ उत्पन्न करते हैं, आवेदन को लागू करने के लिए सभी आवश्यक प्रकार। व्यवहार में, इस विश्लेषिकी से महत्वपूर्ण डेटा संपीड़न प्राप्त हुआ, उदाहरण के लिए, जब डेटाबेस में मूल्य 100 मिलियन था, तो उनमें से केवल 5% को DECIMAL डेटा प्रकार की आवश्यकता थी।
इस मामले में, जब इस तरह के भंडारण को मॉडलिंग करते हैं, तो हार्ड डिस्क के सभी डेटा को बचाने और उन्हें पढ़ने के लिए तरीकों को लागू करना आवश्यक है। मैं दृढ़ता से अनुशंसा करता हूं कि आप मानक क्रमांकन से बचें और बाइनरीविटर और बाइनरीरीडर के आधार पर अपना स्वयं का लिखें। और मैं MemoryStream क्लासेस का गहनता से उपयोग करने की सलाह देता हूं। यानी हार्ड ड्राइव को पढ़ने और लिखने की प्रक्रिया को कई चरणों में विभाजित किया गया है:
- स्मृति में एक धारा को पढ़ना
- मानक एल्गोरिदम के साथ स्ट्रीम संपीड़न
- हार्ड ड्राइव पर स्ट्रीम स्ट्रीम
और इसके विपरीत:
- हार्ड डिस्क से मेमोरी स्ट्रीम तक पढ़ें
- प्रवाह विघटन
- डेटा पढ़ना
यह दृष्टिकोण हार्ड ड्राइव को लोड किए बिना केंद्रीय प्रोसेसर के कई कोर का उपयोग करके डेटा को संपीड़ित करने और पढ़ने की प्रक्रिया को अनुकूलित करना संभव बनाता है। यानी हार्ड ड्राइव से पढ़ना और लिखना क्रमिक रूप से किया जाता है, जबकि मेमोरी में धाराओं से पढ़ना और लिखना समानांतर किया जा सकता है। तो, व्यवहार में, हार्ड डिस्क से 100 मिलियन मान (लगभग 2 जीबी संकुचित डेटा) पढ़ना, और उन्हें मेमोरी में उत्पन्न करना और कक्षाएं उत्पन्न करना (35 जीबी तक) 32-कोर एक्सोन सर्वर का उपयोग करने में लगभग 5 मिनट लगते हैं। संबंधपरक डीबीएमएस से समान डेटा की निकासी में लगभग 5 दिन लगे।
यह लेख इस तरह के भंडार में डेटा को अपडेट करने के विकल्पों पर चर्चा नहीं करता है। लेकिन भंडारण के मुख्य कार्य के साथ, जैसे कि डेटा पढ़ना, यह मॉडल 100% नकल करता है। इस तरह के भंडारण में डेटा को अपडेट करने के लिए, मेमोरी मोड पर अनन्य पहुंच प्रदान करना आवश्यक है। और साथ ही, सिस्टम को विकसित करने के लिए, रैम पर तकनीकी सीमाओं को देखते हुए, वितरित रैम (शार्प) को सिस्टम विकसित करना आवश्यक है।
यह आलेख मानता है कि डेटा एकत्रीकरण प्रक्रिया बाहरी वातावरण में होती है और समुच्चय पहले से ही सिस्टम में प्रवेश करते हैं।
यह लेख विशेष रूप से LINQ तकनीक के उपयोग के मद्देनजर, उनकी तुच्छता को देखते हुए आवेदन कोड प्रदान नहीं करता है, जहां ज्यादातर मामलों में वस्तुओं की समानता या उनके अंतर की विशेषताओं की तुलना करने के संचालन होते हैं।
निष्कर्ष
संबंधपरक डेटाबेस की सभी सुंदरता और बहुमुखी प्रतिभा के लिए, ऐसे कार्य हैं जिन्हें पहले से तैयार किए गए टेम्प्लेट का उपयोग करके हल नहीं किया जा सकता है। समग्र डेटा स्टोरेज के उदाहरण पर - बीआई सिस्टम डिजाइन करने के लिए एक वैकल्पिक दृष्टिकोण दिखाया गया है। और जैसा कि आप देख सकते हैं - यह दृष्टिकोण गहन निष्कर्षण के दौरान हार्ड ड्राइव से डेटा को पढ़ने की प्रक्रिया को समाप्त करने की गारंटी है, जो किसी भी सूचना प्रणाली की अड़चन है। हार्ड ड्राइव से पढ़ने की प्रक्रिया को बाहर करने के बाद, हम हार्ड ड्राइव की तकनीकी क्षमताओं द्वारा दिए गए डेटा तक पहुंच की गति को सीमित करने की मुख्य समस्या को हल करते हैं।
वास्तव में, जब कुल संग्रहण डेटा के साथ काम करते हैं, तो कार्यों का एक सीमित सेट उत्पन्न होता है जिसे लागू किया जाना चाहिए, उदाहरण के लिए, जैसे:
- दिए गए प्रकार "अवधि" के लिए दिए गए "विशेषताओं" में "संकेतक" के लिए मान प्राप्त करें
- जब "विशेषताओं" का एक भाग परिभाषित किया जाता है, तो क्यूब द्वारा "अवशेषों" (जो संकेतक द्वारा सभी शेष उपलब्ध विशेषताओं को प्राप्त करें)
- कई संकेतकों से डेटा को मिलाएं
- दी गई विशेषताओं द्वारा संकेतकों की खोज करें
ज्यादातर मामलों में डेटा आउटपुट दिए गए मापदंड के अनुसार मैट्रिसेस भरे होते हैं, जो एक ही रिकॉर्ड्ससेट और डेटाटेबल रिलेशनल डेटाबेस से प्राप्त होते हैं।