लेखों की इस श्रृंखला में मस्तिष्क के एक लहर मॉडल का वर्णन किया गया है जो पारंपरिक मॉडल से गंभीर रूप से भिन्न है। मैं दृढ़ता से सलाह देता हूं कि जो लोग अभी शामिल हुए हैं वे
पहले भाग से पढ़ना शुरू करते हैं।
मस्तिष्क एक तरफ संचालित होने वाली जानकारी को पूरी तरह से वर्णन करना चाहिए कि क्या हो रहा है, दूसरी तरफ, इसे संग्रहीत किया जाना चाहिए ताकि मस्तिष्क को इसके संचालन की आवश्यकता हो। सिद्धांत रूप में, जानकारी का वर्णन करने के लिए प्रारूप और इसे संसाधित करने के लिए एल्गोरिदम बारीकी से संबंधित चीजें हैं। पहला काफी हद तक दूसरा निर्धारित करता है। इसलिए, यह कहते हुए कि मस्तिष्क द्वारा संग्रहीत डेटा को कैसे व्यवस्थित किया जा सकता है, हम, चाहे हम इसे पसंद करते हैं या नहीं, मोटे तौर पर पूर्ववर्ती प्रक्रियाओं की प्रणाली को पूर्व निर्धारित करते हैं। चूंकि हम बाद में सोचने के सिद्धांतों पर चर्चा करेंगे, अब हम केवल इस बात पर ध्यान देंगे कि वर्तमान विवरण की पूर्णता और जानकारी के बाद के भंडारण को कैसे सुनिश्चित किया जाए। उसी समय, इसका मतलब है कि अगर, सोच के बिंदु पर पहुंच गया है, तो यह पता चला है कि हमने जो डेटा प्रारूप चुना है, वह आवश्यक एल्गोरिदम को फिट करता है, तो हम भाग्यशाली हैं और हम सही तरीके से चले गए हैं।
यह समझने के लिए कि मस्तिष्क किस प्रकार के विवरण का उपयोग करता है, आइए हम दृश्य धारणा के अनुक्रम का पता लगाएं। छवि को देखते हुए, हम इसे त्वरित आंख आंदोलनों के साथ "स्कैन" करते हैं, जिसे सैकेड्स (केडीपीवी पर ड्राइंग) कहा जाता है। उनमें से प्रत्येक समग्र चित्र के टुकड़ों में से एक को देखने के केंद्र में रखता है। दृश्य कॉर्टेक्स के क्षेत्र पर विवरण दिखाई देते हैं, जो कि हम उस क्षण को केंद्र में देखते हैं, परिधि क्या देखता है और सिर्फ किए गए संस्कार के परिणामस्वरूप विस्थापन क्या है। प्रत्येक बाद का संस्कार एक नई तस्वीर बनाता है। ये विवरण एक के बाद एक दूसरे को प्रतिस्थापित करते हैं।
इसलिए, चेहरे को देखते हुए, हम सबसे पहले, उदाहरण के लिए, एक आंख को स्पष्ट रूप से देखते हैं और पहचानते हैं, जिस पर टकटकी लगाई जाती है। चेहरे के शेष तत्व जो दृष्टि की सापेक्ष परिधि पर आते हैं - नाक, मुंह, और इसी तरह, हम कम के साथ सीखते हैं, लेकिन एक ही उच्च संभावना है। प्रत्येक संस्कार के बाद, केंद्रीय टुकड़ा बदल जाता है, लेकिन मान्यता प्राप्त तत्वों का सामान्य सेट अपरिवर्तित रहता है।
सिद्धांत रूप में, इनमें से प्रत्येक अलग-अलग विवरण जो कि saccades के बीच उत्पन्न होते हैं, यह कहने के लिए पर्याप्त है कि हमारे पास एक चेहरा है और यहां तक कि यह पता लगाता है कि वे किसके हैं। लेकिन प्रत्येक व्यक्तिगत विवरण मज़बूती से केवल उस वस्तु का बोलता है, जो उसके लिए टकटकी की दिशा में स्थित है। शेष वस्तुओं को काफी हद तक निर्धारित किया जाता है।
यदि हम चेहरे की अधिक संपूर्ण और विस्तृत तस्वीर प्राप्त करना चाहते हैं, तो स्कैन के दौरान उत्पन्न होने वाले सभी विवरणों का संयोजन इसके लिए उपयुक्त है। इस मामले में, न केवल यह वर्णन करना महत्वपूर्ण होगा कि किस तरह की वस्तुओं को मान्यता दी जाती है, बल्कि साथ-साथ आंखों की शिफ्ट के बारे में भी जानकारी है। और यहाँ हम एक महत्वपूर्ण बिंदु पर आते हैं। अंतिम विवरण क्या है जो दृश्य विश्लेषक का उत्पादन करना चाहिए? कई अवधारणाओं की गतिविधि का सिर्फ एक चित्र? यह केवल उस विवरण के उस भाग से मेल खाता है जिसे हम अभी देख रहे हैं। लेकिन बाकी का क्या? यह पता चला है कि एक सही विवरण जो जानकारी नहीं खोता है, एक के बाद एक सरल विवरणों का एक पैकेज है। जहां इस तरह के एक अस्थायी पैकेज की सभी परतें सूचना के केवल एक निश्चित हिस्से का वर्णन करती हैं, और उनके संयोजन के रूप में एक पूर्ण विवरण प्राप्त किया जाता है। यह सच है बशर्ते कि पैकेज में सभी विवरण एक घटना के अनुरूप हों, अर्थात वे हमारे ध्यान की वैश्विक बदलाव से पहले प्राप्त किए गए थे।
अगर हम सेरेब्रल कॉर्टेक्स की गतिविधि का एक स्नैपशॉट लेते हैं, तो जो कुछ हो रहा है उसका विवरण इसकी प्रत्येक क्षेत्र में सक्रिय अवधारणाओं की एक सूची के साथ तुलना की जा सकती है। लेकिन इस तरह के विवरण में एक महत्वपूर्ण कमी है। मान लीजिए कि हम नीचे दी गई आकृति में चित्रित अभी भी जीवन का वर्णन करना चाहते हैं।
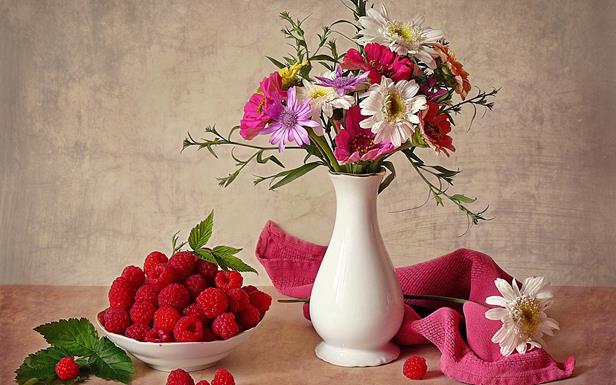
हम यह कर सकते हैं, उदाहरण के लिए, इस तरह:
- एक फूलदान केंद्र के दाईं ओर थोड़ा सा है;
- फूलदान में गुलदस्ता;
- फूलदान के दाईं ओर तौलिया;
- एक तौलिया पर सफेद फूल;
- बाईं ओर रास्पबेरी का एक कटोरा;
- कटोरे के बाईं ओर एक शीट पर रास्पबेरी;
- एक कटोरे के सामने तीन रसभरी;
- फूलदान के दाईं ओर रास्पबेरी।
सामान्य विवरण में ऐसे संक्षिप्त विवरणों का एक समूह होता है। प्रत्येक संक्षिप्त विवरण, कुछ आरक्षणों के साथ, इसमें शामिल अवधारणाओं की एक सूची द्वारा प्रतिस्थापित किया जा सकता है। लेकिन अगर हम छोटे ट्रांसफर में शामिल सभी अवधारणाओं को जोड़कर अंतिम विवरण एकत्र करना चाहते हैं, तो हम असफल होंगे। इसके अलावा, कुछ जानकारी गायब हो जाएगी, क्योंकि यह स्पष्ट नहीं हो जाएगा कि क्या संबंधित है। लेकिन, इसके अलावा, यह पता चला है कि कई बार कुछ अवधारणाओं का उपयोग करना आवश्यक है। उदाहरण के लिए, यह बाईं तरफ, और दाईं ओर, और एक कटोरे के सामने रसभरी है। और अगर हम इस "बस असेंबल किए गए" विवरण को एक सादृश्य के रूप में उपयोग करना चाहते हैं कि कॉर्टेक्स के क्षेत्रों में इस तरह के एक स्थिर जीवन का वर्णन कैसे किया जाता है, तो यह पता चलता है कि हमारे पास "रास्पबेरी" का सामान्यीकरण है और यह एक ही समय में "सक्रिय समय" नहीं हो सकता है। इस स्थिति से बाहर निकलने का रास्ता, जो मुझे तर्कसंगत लगता है, एक बैच विवरण का उपयोग करना है। प्रत्येक सरल विवरण में सक्रिय अवधारणाओं की एक विशिष्ट गणना शामिल हो सकती है। पूर्ण विवरण सरल विवरणों के एक सेट के रूप में प्राप्त किया जाता है। चूंकि सरल विवरण समय में अलग हो जाते हैं, एक तरफ यह स्पष्ट है कि यह क्या संदर्भित करता है, और दूसरी तरफ, एक ही अवधारणा विभिन्न संदर्भों में पैकेज की विभिन्न परतों में कई बार हो सकती है।
इस तरह की एक पैकेज प्रस्तुति एक व्यक्ति के ध्यान की मात्रा के बारे में तर्क के साथ बहुत अच्छी तरह से संबंधित है। मनोवैज्ञानिक, ध्यान के गुणों का अध्ययन करते हुए, स्थापित किया है कि वस्तुओं की संख्या की सीमा है जिस पर एक व्यक्ति एक साथ ध्यान केंद्रित कर सकता है। आमतौर पर यह सीमा सात वस्तुओं से अधिक नहीं होती है। मैकेनिकल टैकिस्टोस्कोप का उपयोग करके ध्यान की मात्रा को मापने वाला पहला प्रयोग प्रायोगिक मनोविज्ञान के संस्थापक विल्हेम वुंड्ट द्वारा किया गया था।
 टैचीटोस्कोप - एक उपकरण जिसके साथ आप लगातार दृश्य उत्तेजनाओं को पेश कर सकते हैं
टैचीटोस्कोप - एक उपकरण जिसके साथ आप लगातार दृश्य उत्तेजनाओं को पेश कर सकते हैंध्यान की मात्रा का आकलन करना बहुत सरल है। पिछले अभी भी जीवन को देखें और यह गणना करने की कोशिश करें कि आप कितने अलग-अलग तत्वों में सक्षम हैं, नहीं, याद रखने के लिए नहीं, यह अलग है, लेकिन एक ही समय में इसे अपने सिर में रखने के लिए। या उदाहरण के लिए, सात-अंकीय फ़ोन नंबर लें, 1145618 और इसे अपने सिर में रखने की कोशिश करें। सबसे अधिक संभावना है, ताकि यह गायब न हो, आपको इसे अपने आप को दोहराने में लूप करना होगा। यदि संख्या में सात से अधिक अंक हैं, तो एक महान संभावना है कि उन सभी को स्मृति में रखना संभव नहीं होगा। स्थिर जीवन की अधिकतम संख्या या संख्याएँ जिन्हें एक साथ माना जाता है, आपके ध्यान की मात्रा का अनुमान देती हैं।
सेरेब्रल कॉर्टेक्स में जानकारी के बैच प्रतिनिधित्व के बारे में हमारी धारणा हमें सूचना पैकेट की एक परत के साथ ध्यान में रखी गई प्रत्येक वस्तुओं की तुलना करने की अनुमति देती है।
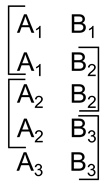
यदि हम एक कॉर्टेक्स की कल्पना करते हैं, जिसमें कम संख्या में अवधारणाएं होती हैं, जो दो वस्तुओं "ए" और "बी" के संबंध में बहुत ही सरल विचारों को तैयार करने में सक्षम है, तो विचार के अनुरूप पैकेज: "लाल वस्तु ए ब्लू ऑब्जेक्ट बी पर झूठ" जैसा चित्र में दिखाया गया है। नीचे दिए गए।
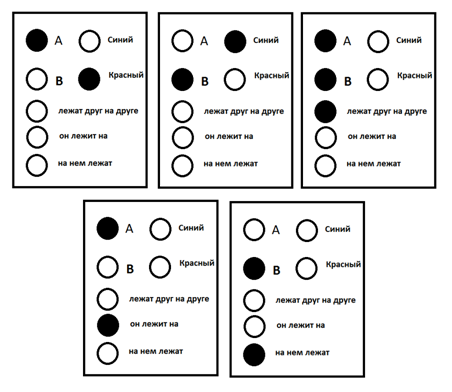 सूचना पैकेज उदाहरण
सूचना पैकेज उदाहरणजटिल विवरण एन्कोडिंग
आइए हम स्मृति में लौटें और किस प्रकार की जानकारी के साथ व्यवस्थित करने का प्रयास करें, और तदनुसार, विवरणों के प्रकार, हमारा मस्तिष्क संचालित कर सकता है।
पहला प्रकार एक सरल विवरण है जो प्रांतस्था की तात्कालिक गतिविधि की एक तस्वीर से मेल खाता है। यह उन अवधारणाओं का एक संयोजन है जो मस्तिष्क द्वारा अभी पता लगाया गया है।
दूसरा प्रकार एक घटना, एक विचार के अनुरूप सरल विवरणों का एक पैकेज है। पैकेज में, विवरण का क्रम महत्वपूर्ण नहीं है। पैकेज की परतों की पुनर्स्थापना बयान के सामान्य अर्थ को नहीं बदलती है। एक पैकेज को याद रखना लगातार सरल विवरणों की एक श्रृंखला की बहाली है।
तीसरा प्रकार एक स्थितिगत विवरण है। इस विवरण में, कुछ वस्तुओं का संबंध दूसरों के साथ है जो संबंधों की एक निश्चित प्रणाली में उनके साथ हैं। उदाहरण के लिए, इस तरह के विवरण की भिन्नता एक स्थानिक विवरण है। जब हम केवल अंतरिक्ष में अपनी स्थिति को ठीक नहीं करते हैं, लेकिन इसे अन्य वस्तुओं के स्थान के साथ कुछ विवरणों के साथ जोड़ते हैं।
चौथा प्रकार एक प्रक्रियात्मक विवरण है। ऐसा विवरण, जिसमें पैटर्न का क्रम बदलता है और इसमें शामिल अंतराल महत्वपूर्ण होते हैं। उदाहरण के लिए, भाषण की धारणा ध्वनियों के अनुक्रम द्वारा निर्धारित की जाती है, जबकि अंतराल का अनुपात अंतरंगता का निर्माण करता है, जिस पर सुना गया वाक्यांश का सामान्य अर्थ निर्भर करता है। एक प्रक्रिया को याद करते हुए छवियों के एक उपयुक्त अनुक्रम का प्रजनन है।
और पांचवां प्रकार एक कालानुक्रमिक विवरण है। लंबे समय तक फिक्सिंग किस क्रम में और किस समय अंतराल पर ये या अन्य घटनाएं हुईं। कालानुक्रमिक स्मृति के लिए याद करने की क्षमता सिर्फ एक कालक्रम से संबंधित हर चीज का पुनरुत्पादन नहीं है, बल्कि एक सामान्य समय अनुक्रम द्वारा इसके साथ एक विवरण से दूसरे में स्थानांतरित करने की क्षमता है।
यह नोटिस करना आसान है कि कई विवरण किसी भी तरह समय से बंधे हैं। एक बैच विवरण क्रमिक छवियों की एक श्रृंखला है। प्रक्रियात्मक विवरण घटनाओं के अनुक्रम को ध्यान में रखता है। कालानुक्रमिक विवरण को समय के साथ घटनाओं की स्थिति पर विचार करने की आवश्यकता होती है।
इस तरह के विवरणों की समय पर निर्भरता ने संबंधित मॉडलों की उपस्थिति को जन्म दिया। इनमें से सबसे प्रसिद्ध जेफ हॉकिन्स (हॉकिन्स, 2011) की वकालत की गई पदानुक्रमित लौकिक मेमोरी (HTM) की अवधारणा है। वह और उनके सहयोगी इस तथ्य से आगे बढ़ते हैं कि घटनाओं का अस्थायी परिवर्तन एकमात्र ऐसी चीज है जो अलग-अलग सूचना छवियों को एक साथ जोड़ने की अनुमति देती है। इससे यह निष्कर्ष निकाला गया है कि कॉर्टेक्स के मूल सूचना तत्व को स्थिर छवियों के साथ काम नहीं करना चाहिए, लेकिन एक समय अनुक्रम के साथ। HTM अवधारणा में, एक सूचना भंडारण तत्व संकेतों का समय-विस्तारित अनुक्रम है। मान्यता दो अनुक्रमों के संयोग का निर्धारण है। भविष्यवाणी करने के लिए HTM की क्षमता पर विशेष जोर दिया जाता है। जैसे ही एक न्यूरॉन इसके बारे में परिचित अनुक्रम की शुरुआत को पहचानता है, यह अपने स्वयं के अनुभव से सक्षम हो जाता है कि यह निरंतरता को याद रखता है। एचटीएम में वर्तमान तस्वीर का वर्णन उन न्यूरॉन्स की गतिविधि है जो घटनाओं के वर्तमान परिवर्तन का जवाब देते हैं।
इस दृष्टिकोण की जटिलता काफी स्पष्ट है। सबसे पहले, समय के साथ अनुपालन की आवश्यकता। डेटा की प्राप्ति में थोड़ा त्वरण या देरी मान्यता एल्गोरिथ्म का उल्लंघन कर सकती है। दूसरे, कॉर्टेक्स उन पर संचालित होने से पहले सभी स्थिर छवियों को अस्थायी अनुक्रमों में अनुवाद करने की आवश्यकता है। और पसंद है।
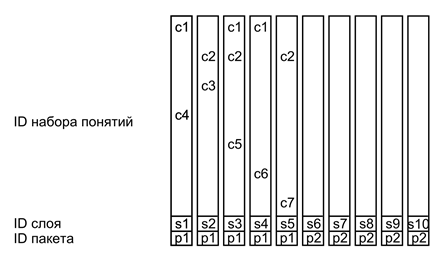
हमारे मॉडल में, पहचानकर्ता प्रणाली हमें एक सार्वभौमिक उपकरण देती है जो सभी प्रकार की स्मृति का वर्णन करने के लिए समान रूप से अनुकूल है। मूल विचार सरल है - प्रत्येक सरल विवरण एक समग्र पहचानकर्ता है जिसमें पूरे सेट, दोनों साहचर्य और लौकिक संबंधों को इंगित करने के लिए आवश्यक सब कुछ शामिल है।
नीचे दिया गया आंकड़ा इस तरह के एक साधारण विवरण की एक सशर्त छवि दिखाता है। एक साधारण विवरण एक लहर है जो विभिन्न प्रकार के पहचानकर्ताओं के कई सेटों को वहन करती है। मुख्य सामग्री अवधारणा पहचानकर्ताओं के एक सेट से एन्कोडेड है जो कि क्या हो रहा है, के सार का वर्णन करता है। परत पहचानकर्ता मुख्य सामग्री को चिह्नित करता है, इसे बाकी के सरल विवरणों से अलग करता है। एक पैकेज पहचानकर्ता कई परतों को जोड़ता है जो एक जटिल विवरण से संबंधित हैं। स्थान, समय और अनुक्रम के पहचानकर्ता जटिल विवरणों के बीच संबंधित संबंधों की एक प्रणाली बनाते हैं।
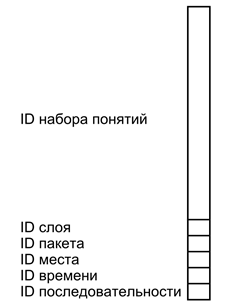 सरल विवरण प्रारूप
सरल विवरण प्रारूपपिछले उदाहरण को लें और C1 ... C7 (नीचे चित्र) के रूप में उपयोग की जाने वाली अवधारणाओं के अनुरूप पहचानकर्ताओं की तरंगों को निरूपित करें।
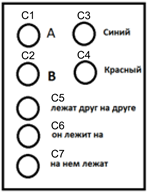 वर्णन करने के लिए प्रयुक्त अवधारणाओं
वर्णन करने के लिए प्रयुक्त अवधारणाओंफिर "लाल वस्तु A, नीली वस्तु B पर निहित है" का वर्णन नीचे दी गई तस्वीर जैसा दिखेगा।
 जटिल विवरण उदाहरण
जटिल विवरण उदाहरणइस उदाहरण में, पैकेज की प्रत्येक परत अपनी परत पहचानकर्ता के साथ एक सरल विवरण है। सभी पैकेज परतों में एक आम पैकेज पहचानकर्ता p1 है। जब एक जटिल विवरण समाप्त होता है, तो इसके बाद के पैकेज पैकेज के लिए एक अलग पहचानकर्ता होता है (दूसरे विवरण की अवधारणाएं आंकड़े में नहीं दिखाई जाती हैं)।
इस तरह के डिज़ाइन को काम करने योग्य बनाने के लिए, मस्तिष्क को एक काफी जटिल प्रणाली की आवश्यकता होती है जो पैकेज बनाने वाले पहचानकर्ता बनाता है। इसके अलावा, प्रांतस्था के प्रत्येक क्षेत्र के लिए, इस तरह के पहचानकर्ताओं का अपना सेट होना आवश्यक हो सकता है, जो इसके लिए उपयुक्त है।
उदाहरण के लिए, दृश्य धारणाओं का एक क्रम लें। आंखों के स्पस्मोडिक माइक्रोक्रोमेशन, जिसे माइक्रोकैड्स कहा जाता है, आंख को रेटिना के केंद्र में स्थित छवि के एक छोटे हिस्से को स्कैन करने का कारण बनता है। ऐसी स्कैन की प्रक्रिया में प्राप्त की जाने वाली सभी छवियां संभवतः एक सामान्य पहचानकर्ता द्वारा एकजुट हो सकती हैं। आंखों की सूक्ष्मता को चौगुनी के ऊपरी ट्यूबरकल द्वारा नियंत्रित किया जाता है। यह माना जा सकता है कि यह वह है जो इस तरह के पहचानकर्ता को एनकोड करता है। कई microsaccades के बाद, एक मजबूत छलांग होती है, जिसे एक सेकेड कहा जाता है (ऊपर की तरफ नेफर्टिटी के सिर के साथ आंकड़ा में दिखाया गया है)। प्रत्येक सैकेड माइक्रो सैकडे आइडेंटिफायर में बदलाव का कारण बनता है।
यह माना जा सकता है कि प्राथमिक दृश्य प्रांतस्था के लिए माइक्रोकैड्स मौलिक रूप से महत्वपूर्ण हैं। एक आम पहचानकर्ता कॉर्टेक्स को बताता है कि लगातार छवियों की एक श्रृंखला एक ही वस्तु का वर्णन करती है, लेकिन रेटिना पर विभिन्न पदों में, जो उन्हें एक एकल विवरण में संयोजित करने और मान्यता प्राप्त करने की अनुमति देता है जो रेटिना पर स्थिति के लिए अपरिवर्तनीय है।
एक लंबी घटना एक श्रृंखला है। चूंकि श्रृंखला एक एकल तस्वीर को देखने के लिए संदर्भित करती है, परिणामी विवरणों को एक अन्य सामान्य पहचानकर्ता - सैकेड पहचानकर्ताओं द्वारा एक साथ जोड़ा जा सकता है। लेकिन यह पहचानकर्ता प्राथमिक के लिए आवश्यक नहीं है, बल्कि दृश्य प्रांतस्था के द्वितीयक और गहरे स्तरों के लिए, जहां बाद में सूचना का प्रसंस्करण होता है। एक पहचानकर्ता जो कॉर्टेक्स को बताता है कि हम जो कुछ भी saccades की एक श्रृंखला के दौरान देखते हैं वह एक और एक ही तस्वीर है, जो हमें रेटिना में अलग-अलग स्थानों पर दिखाई देने वाली समान छवियों को सहसंबंधित करने की अनुमति देता है।
जब तस्वीर की जांच की जा रही है तो महत्वपूर्ण पहचानकर्ता को बदलना चाहिए। उदाहरण के लिए, सिर के एक मजबूत मोड़ के साथ, ध्यान स्विच करना, फिल्म में योजना या दृश्य बदलना। स्विचिंग ध्यान मस्तिष्क के लिम्बिक सिस्टम के तत्वों द्वारा एन्कोड किया जा सकता है और इस से बंधे कई कॉर्टिकल जोन तक विस्तारित हो सकता है। इसी समय, हिप्पोकैम्पस पहचानकर्ता घटनाओं के अनुपात-लौकिक विवरण को एन्कोडिंग करते हैं जो विवरण प्रणाली में मौजूद हैं। संक्षेप में, पैकेज को परिभाषित करने वाले पहचानकर्ताओं की प्रणाली काफी जटिल हो सकती है, और जानकारी की विशेषताओं द्वारा निर्धारित की जाती है जो क्रस्ट के प्रत्येक विशेष क्षेत्र से संबंधित है।
पहचानकर्ताओं का उपयोग करना, घटनाओं के अनुक्रम के निर्धारण को व्यवस्थित करना आसान है। उदाहरण के लिए, यदि आप दो टुकड़ों से मिलकर एक पहचानकर्ता लेते हैं, तो वैकल्पिक रूप से उनमें से एक को बदलकर, आप पड़ोसी विवरण (नीचे आंकड़ा) की सहयोगी कनेक्टिविटी प्राप्त कर सकते हैं।
 अनुक्रम कोडिंग
अनुक्रम कोडिंगप्रत्येक ऐसे पहचानकर्ता में पिछले और बाद के पहचानकर्ता से एक तत्व होगा। इस तरह के पहचानकर्ताओं के साथ छवियों के समय अनुक्रम को याद करते हुए, प्रत्येक छवि के लिए हम समयरेखा में इसके दो पड़ोसियों को पा सकते हैं। पहचानकर्ता को आसानी से जटिल करने के बाद, न केवल सामान्य कनेक्टिविटी को सांकेतिक शब्दों में बदलना संभव है, बल्कि समय के प्रवाह की दिशा भी संभव है।
यह ध्यान दिया जाना चाहिए कि हमारे मॉडल में, प्रत्येक मेमोरी में पहचानकर्ताओं की एक समृद्ध प्रणाली है। यह कई पूरी तरह से अलग संघों के माध्यम से मेमोरी तक पहुंच की अनुमति देता है। विवरणों के अर्थ के संयोग के आधार पर कोई कुछ याद कर सकता है। आप सूचना चित्रों को वर्णित घटनाओं के स्थान या समय से जोड़ सकते हैं। आप किसी एकल ईवेंट से संबंधित छवियों के अनुक्रम को पुन: उत्पन्न कर सकते हैं। यह देखना आसान है कि पारंपरिक रिलेशनल डेटाबेस बनाने के लिए उपयोग किए जाने वाले दृष्टिकोणों के साथ यादों तक ऐसी पहुंच बहुत आम है।
साहित्य का इस्तेमाल कियाविस्तारपिछले भाग:
भाग 1. न्यूरॉनभाग 2. कारकभाग 3. अवधारणात्मक, दृढ़ नेटवर्कभाग 4. पृष्ठभूमि गतिविधिभाग 5. मस्तिष्क की तरंगेंभाग 6. प्रोजेक्शन सिस्टमभाग 7. मानव कंप्यूटर इंटरफ़ेसभाग 8. तरंग नेटवर्क में कारकों का अलगावभाग 9. न्यूरॉन डिटेक्टरों के पैटर्न। उलटा प्रक्षेपणभाग 10. स्थानिक स्व-संगठनभाग 11. डायनेमिक न्यूरल नेटवर्क। संबद्धताभाग 12. स्मृति के निशानभाग 13. साहचर्य स्मृतिभाग 14. हिप्पोकैम्पसभाग 15. मेमोरी कंसोलिडेशनएलेक्सी रेडोज़ुबोव (2014)