 एवरन मास्को ऑफिस में रिसर्च टीम के प्रमुख यूजीन लिवित्स द्वारा पोस्ट किया गया
एवरन मास्को ऑफिस में रिसर्च टीम के प्रमुख यूजीन लिवित्स द्वारा पोस्ट किया गयाचीनी एवरनोट मान्यता प्रणाली (ENRS, एवरनोट रिकॉग्निशन सिस्टम) के लिए हाल ही में जोड़े गए समर्थन के साथ अब 24 भाषाओं में हस्तलिखित नोटों को अनुक्रमित करता है। हर बार जब हम एक नई भाषा लेते हैं, तो हमें एक विशेष वर्णमाला और लिखने की शैली की बारीकियों से संबंधित नए कार्यों का सामना करना पड़ता है।
चीनी, जापानी और कोरियाई (CJK): जब हमने पूर्व एशियाई भाषाओं को लिया तो अतिरिक्त कठिनाइयाँ पैदा हुईं। इन भाषाओं को अधिक वर्णों के दो आदेशों के लिए समर्थन की आवश्यकता होती है, और उनमें से प्रत्येक हमारे द्वारा पहले से निपटाए गए लोगों की तुलना में बहुत अधिक जटिल है; शब्दों के बीच रिक्त स्थान वैकल्पिक हैं; लेखन की उच्च गति पर, लोग अक्सर घसीट लेखन पर स्विच करते हैं, जो व्याख्या को काफी हद तक संदर्भ पर निर्भर करता है।
CJK समर्थन की बारीकियों में गोता लगाने से पहले, आइए जल्दी से उन कठिनाइयों से गुज़रें जिन्हें हमें यूरोपीय भाषाओं में लिखावट की मान्यता से दूर करना था। हमारा पहचान इंजन टेक्स्ट स्ट्रिंग्स को ढूंढकर एक हस्तलिखित पेज को पार्स करना शुरू कर देता है। यह पहले से ही एक गैर-तुच्छ कार्य हो सकता है। इस उदाहरण पर विचार करें:

लाइनों को दांतेदार किया जा सकता है, विभिन्न लाइनों के पत्र एक दूसरे के साथ प्रतिच्छेद करते हैं, और लाइनों के बीच की दूरी एक विस्तृत श्रृंखला में भिन्न होती है। लाइन विभाजन एल्गोरिथ्म आसन्न लाइनों के प्रक्षेपवक्र के यादृच्छिक चौराहों को खोलना चाहिए।
लाइनों के निर्माण के बाद, हमें निम्न कार्य का सामना करना पड़ता है - उन्हें शब्दों में सही ढंग से कैसे विभाजित किया जाए। एक नियम के रूप में, यह मुद्रित पाठ के लिए मुश्किल नहीं है, जहां अक्षरों और शब्दों के बीच की दूरी में अंतर अपेक्षाकृत स्पष्ट रूप से परिभाषित किया गया है। कई मामलों में हस्तलिखित पाठ के मामले में, अक्षरों के बीच की दूरी से यह निर्धारित करना असंभव है कि क्या हम एक अंतःक्षेत्र या इंट्रावर्ड स्पेस के साथ सामना कर रहे हैं।

पाठ में जो कुछ लिखा गया है उसकी समझ यहां मदद कर सकती है। फिर, शब्दों को समझते हुए, हम यह निर्धारित कर सकते हैं कि उनकी शुरुआत कहां है और अंत कहां है। हालांकि, इसके लिए संपूर्ण स्ट्रिंग को समझने की क्षमता की आवश्यकता होती है, और केवल एक शब्द को दूसरे के बाद नहीं पढ़ना चाहिए - जैसा कि अधिकांश पाठ मान्यता इंजन आमतौर पर करते हैं। यूरोपीय भाषाओं के लिए, हस्तलिपि मान्यता का कार्य अक्सर एशियाई ग्रंथों की तुलना में बहुत आसान नहीं है। उदाहरण के लिए, यहाँ कोरियाई में हस्तलिखित पाठ का एक नमूना है:

इसी तरह, आपको संभावित चौराहों को खोलना, पाठ की पंक्तियों का चयन करना होगा। इसके अलावा, यह स्पष्ट है कि शब्द विभाजन में लगे एक अलग ब्लॉक का निर्माण अवास्तविक है। जैसा कि यूरोपीय हस्तलिखित पाठ के मामले में, समाधान मान्यता प्राप्त शब्दों को समझकर और उनकी सीमाओं का निर्धारण करके एक एल्गोरिथ्म के भीतर मान्यता और विभाजन था।
अब चरित्र पहचान की प्रक्रिया पर एक नज़र डालें। सबसे पहले, हमें पात्रों की सीमाओं को खोजने की आवश्यकता है। वे स्ट्रोक के बीच या तेज लेखन की विशेषता वाली लाइनों को जोड़ने के बीच छोटे स्थानों से गुजर सकते हैं। हमारे पास वर्णों के बीच सीमा बिंदुओं को निर्धारित करने के लिए एक विश्वसनीय तरीका नहीं है, इसलिए हम कुछ अंतर के साथ संभावित प्रतिच्छेदन विभाजन बिंदुओं को उजागर करने के लिए मजबूर हैं (हम ओवरसिलेशन करते हैं)। इसी समय, इस स्तर पर, हमें इस बात की स्पष्ट समझ नहीं है कि क्या यह या वह संभावित विभाजन बिंदु सही जगह पर है और प्रतीकों को अलग करता है, या क्या यह उनमें से एक के अंदर आता है। नतीजतन, पूरी लाइन छोटे ब्लॉकों में टूट जाती है।
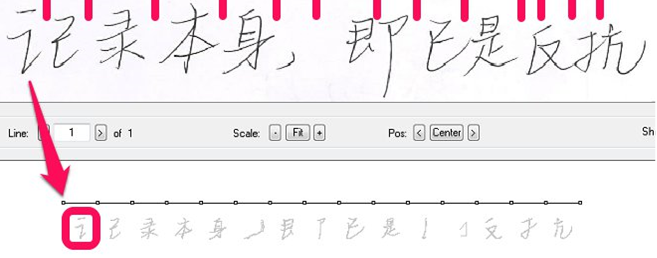
वास्तविक पात्रों को इकट्ठा करने के लिए, हम इन छोटे ब्लॉकों को बड़े ब्लॉकों में संयोजित करने का प्रयास करते हैं, ऐसे प्रत्येक संयोजन का मूल्यांकन करते हैं। नीचे दी गई छवि पहले दो ब्लॉकों के संयोजन को पहचानने का प्रयास दिखाती है।

बेशक, इसका मतलब यह है कि हमें वास्तव में लिखे गए पात्रों की कई और विविधताओं को पहचानना होगा। और सीजेके भाषाओं के लिए, इसका मतलब है कि मान्यता प्रक्रिया यूरोपीय भाषाओं की तुलना में बहुत धीमी होगी, क्योंकि विभिन्न संयोजनों के मूल्यांकन के लिए "उम्मीदवारों" की एक बड़ी संख्या पर विचार करना होगा। हमारे चरित्र पहचान प्रणाली का मूल समर्थन वेक्टर मशीन (एसवीएम) सॉल्वरों का एक सेट है, जिनमें से प्रत्येक इसे सौंपे गए प्रतीक के लिए "सभी के खिलाफ एक" समस्या को हल करता है।
और अगर अंग्रेजी भाषा के लिए हमें लगभग 50 ऐसे सॉल्वर (सभी लैटिन अक्षर + अक्षर) चाहिए, तो सबसे आम चीनी अक्षरों का समर्थन करने के लिए हमें पहले से ही 3,750 की आवश्यकता होगी! इससे प्रक्रिया 75 गुना धीमी हो जाएगी, यदि केवल हमें ही इन सभी सॉल्वरों के प्रत्येक भाग को चलाने का कोई रास्ता नहीं मिलेगा।
ऐसा करने के लिए, हम पहले काफी सरल और तेज़ एसवीएम का एक सेट लॉन्च करते हैं जो वर्णों के एक समूह का चयन करेंगे जो वर्तनी में समान हैं। और मानक एसवीएम केवल पहले चरण में पाए जाने वाले पात्रों पर काम करते हैं। यह दृष्टिकोण आम तौर पर हमें पूरे चरित्र सेट के केवल 5-6% का उपयोग करने की अनुमति देता है, जो मान्यता प्रक्रिया को लगभग 20 गुना बढ़ा देता है।
यह तय करने के लिए कि आपको अंतिम उत्तर के लिए चुने जाने वाले लिखित पात्रों की कई संभावित व्याख्याओं में से, हमें अलग-अलग भाषा के मॉडल की ओर मुड़ने की जरूरत है - यह वह संदर्भ है जो हमें SVM द्वारा उत्पन्न सभी संभावित विकल्पों की अधिक सार्थक व्याख्या बनाने की अनुमति देगा। व्याख्या सबसे आम दो-चरित्र संयोजनों के एक सरल भार के साथ शुरू होती है, फिर संदर्भ स्तर को लगातार तीन-वर्ण अनुक्रमों और फिर शब्दकोशों और परिचित संरचित मॉडल से शब्दों तक विस्तारित किया जाता है - दिनांक, फोन नंबर, ईमेल पते। सुझाए गए शब्दों और पैटर्न के संभावित संयोजन निम्नलिखित हैं। और सभी संभावनाओं को तोले बिना, हम यह सुनिश्चित करने के लिए नहीं कह सकते कि इस या उस पंक्ति की व्याख्या करना कितना अच्छा है। डीप ब्लू ने कई शतरंज पदों का विश्लेषण कैसे किया, इसके समान, लाखों और संभव संयोजनों के केवल तुलनात्मक मूल्यांकन, कस्पारोव के खिलाफ खेलते हुए, हमें इष्टतम व्याख्या करने की अनुमति देता है।
एक बार स्ट्रिंग के लिए सबसे अच्छी व्याख्या प्रस्तुत करने के बाद, हम अंत में शब्दों की सीमाओं को निर्धारित कर सकते हैं। नीचे दी गई छवि में हरे रंग के फ्रेम उन शब्दों को अलग करने का सबसे अच्छा तरीका दिखाते हैं जिनसे आप जुड़ने में कामयाब रहे।
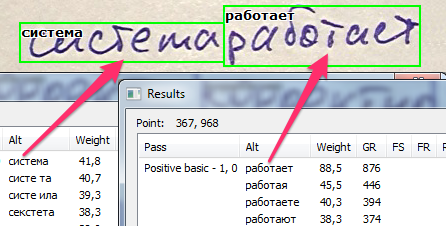
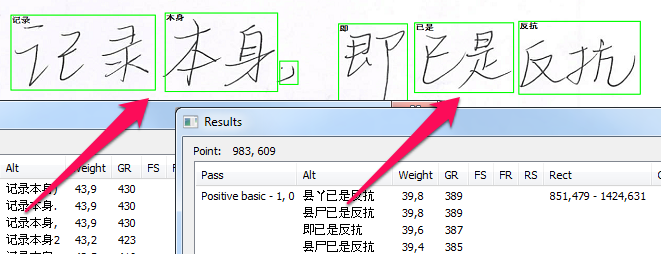
और, जैसा कि आप देखते हैं, प्रक्रिया यूरोपीय हस्तलिखित ग्रंथों और सीजेके दोनों के लिए समान रूप से समान है।