
कंप्यूटर पर प्राकृतिक विकास को अनुकरण करने के लिए पहले प्रयोगों के परिणामस्वरूप 1950 के दशक में जेनेटिक एल्गोरिदम का आविष्कार किया गया था। तब से, उनका उपयोग विभिन्न प्रकार की अनुकूलन समस्याओं को हल करने के लिए किया गया है, जहां किसी कारण से ढाल के तरीके उपयुक्त नहीं हैं। आनुवंशिक एल्गोरिदम के जैविक घटक का एक बहुत ही सरल रूप है और इस मामले में हम इसके पूर्ण विकसित मॉडलिंग की तुलना में विकासवादी चयन के सामान्य विचार का पालन करने के बारे में अधिक बात कर रहे हैं। फिर भी, कभी-कभी जीए के परिणामों की व्याख्या जैविक अर्थ में की जा सकती है। हमारे लेख में, हम किसी व्यक्ति के "महत्व के क्षेत्रों" को प्राप्त करने के लिए चेहरे की पहचान कार्य के लिए आनुवंशिक एल्गोरिदम का उपयोग करने के अनुभव के बारे में बात करते हैं। इस दृष्टिकोण के आवेदन ने हमारे चेहरे की पहचान प्रणाली की मान्यता सटीकता में औसतन 20% की वृद्धि की अनुमति दी।
मौजूदा चेहरा पहचान दृष्टिकोण
ऐतिहासिक रूप से, कंप्यूटर फेस रिकग्निशन के क्षेत्र में लगभग 20 वर्षों के गहन शोध के बाद, 2000 के दशक की शुरुआत में, चेहरे की तुलना के तरीकों के दो बुनियादी समूहों को प्रतिष्ठित किया गया: "समग्र दृष्टिकोण", "समग्र दृष्टिकोण" (या "वैश्विक दृष्टिकोण") और "सुविधा दृष्टिकोण" "," फ़ीचर-आधारित दृष्टिकोण "(या" संरचनात्मक दृष्टिकोण ") [1]। पहले मामले में, चेहरे को पूरी छवियों के रूप में माना जाता है जिनकी आपस में तुलना की जाती है। दूसरे मामले में, स्थानीय संकेतों को चेहरे की छवि से अलग किया जाता है, जैसे कि आंखों, नाक, मुंह, आदि की पूर्ण और सापेक्ष स्थिति के बारे में जानकारी। दोनों समूहों में अपनी कमियां हैं: विशिष्ट दृष्टिकोणों की तुलना में समग्र दृष्टिकोणों ने आम तौर पर आदर्श मान्यता स्थितियों के करीब अधिक विश्वसनीयता दिखाई है, हालांकि, विशेषता दृष्टिकोण उन स्थितियों में खुद को बेहतर साबित कर चुके हैं, जहां चेहरे के कुछ हिस्से किसी कारण से दिखाई नहीं देते हैं (उदाहरण के लिए, वे कपड़ों से ढंके हुए हैं) चश्मा)। विशुद्ध रूप से SIFT जैसी विधियों को उनके शुद्ध रूप में अंकित करने के लिए फेस रिकग्निशन कार्य के लिए लागू करना असंतोषजनक परिणाम देता है, क्योंकि आमतौर पर किसी व्यक्ति के चेहरे पर बहुत कम "कोने" होते हैं जिसके लिए प्रमुख बिंदु निर्धारित होते हैं। मुख्य बिंदुओं के दिए गए जाली का उपयोग करके सुविधाओं की गणना के साथ घने-झारना प्रकार के एल्गोरिदम, हालांकि वे अच्छी पहचान की गुणवत्ता [2] प्रदर्शित करते हैं, फीचर वैक्टर के बड़े आकार और उन्हें गणना करने के लिए लंबे समय के कारण व्यावहारिक उपयोग के लिए हमेशा सुविधाजनक नहीं होते हैं। इन स्थितियों के तहत, हाल के वर्षों में,
स्थानीय बाइनरी पैटर्न की विधि सहित सशर्त रूप से "मॉड्यूलर दृष्टिकोण" [4–9] नामक विधियों के एक समूह ने लोकप्रियता हासिल की है।
चेहरे की तुलना करने के लिए क्लस्टर दृष्टिकोण
चेहरे की तुलना करने के लिए क्लस्टर दृष्टिकोणों का सार चेहरे की छवि को कई वर्गों में विभाजित करना है, जिनमें से प्रत्येक के लिए आप एक समग्र दृष्टिकोण लागू कर सकते हैं और उनकी तुलना जोड़े में कर सकते हैं, अर्थात्। अन्य साइटों की परवाह किए बिना। इस मामले में, यह आशा की जा सकती है कि यदि उपरोक्त छवियों के कुछ जोड़े वर्गों की छाया या ओवरलैप्स जैसे उपरोक्त हस्तक्षेप करने वाले कारकों के कारण मेल नहीं खाते हैं, तो शेष जोड़े अनुभाग आपसी सहसंबंध की आवश्यक डिग्री प्रदान करेंगे, जो मैच / बेमेल के सही अंतिम समाधान के लिए पर्याप्त होगा। ।
मुख्य घटकों की विधि [4], पल इनवेरिएंट्स [5],
स्थानीय बाइनरी पैटर्न (एलबीएस) [6, 7], गैबर वेवलेट्स [8], हैर वेवलेट्स [9], और अन्य तरीकों का उपयोग समग्र दृष्टिकोण के रूप में किया जा सकता है। हमारी परियोजना में, हम संयुक्त LBSh दृष्टिकोण का उपयोग करते हैं [7] और छद्म Zernike क्षण [5]।
चेहरे के क्षेत्रों के महत्व का मैट्रिक्स
हमारे चेहरे की पहचान प्रणाली में, ZZPhoto आवेदन में लागू, हम चेहरे की छवि को विभाजित करके चेहरे की तुलना करने के लिए चेहरे के विभिन्न भागों के असमान महत्व को ध्यान में रखते हैं
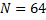
प्लॉट (छवि 1) और उनमें से प्रत्येक को अपने स्वयं के वजन को असाइन करना
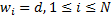
भार के मान चार असतत मानों में से एक लेते हैं,
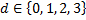
।
चित्र 1. ए) चेहरे का विभाजन 8x8 = 64 तिरस्कार वर्ग भूखंडों में। बी) चेहरे के वर्गों के महत्व के वजन मैट्रिक्स के मान।वजन का मूल्य जितना बड़ा होगा, तुलनात्मक एल्गोरिथम के अंतिम निर्णय पर चेहरे के संबंधित हिस्से के संयोग / बेमेल का प्रभाव उतना ही अधिक होगा। अंजीर में। चेहरे के 6 और महत्वपूर्ण क्षेत्रों को एक लाल रंग की टिंट में हाइलाइट किया गया है।
महत्वपूर्ण वजन के इष्टतम मैट्रिक्स को निर्धारित करने के लिए संपूर्ण खोज का उपयोग करना अभ्यास में मुश्किल है, क्योंकि हमें विचार करना होगा
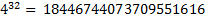
वजन के मैट्रिक्स के वेरिएंट (यहां 32 की शक्ति है, 64 की नहीं, क्योंकि हम वजन के सममित क्षैतिज मैट्रिक्स का उपयोग करते हैं, सामान्य तौर पर, व्यक्ति के चेहरे की सममित प्रकृति)। इसलिए, सर्वश्रेष्ठ मैट्रिक्स की खोज करने के लिए, आपको अधिक बुद्धिमान खोज एल्गोरिथ्म का उपयोग करने की आवश्यकता है। नतीजतन, हम आनुवंशिक एल्गोरिदम (जीए) पर बस गए।
आनुवंशिक एल्गोरिथम
आनुवंशिक एल्गोरिदम ने खुद को वैश्विक अनुकूलन के साधन के रूप में साबित किया है जब ढाल अनुकूलन विधियों को लागू नहीं किया जा सकता है। उनके फायदे हैं कि अनुकूलित ऑब्जेक्ट के एक अलग मॉडल की आवश्यकता नहीं है, साथ ही स्थानीय न्यूनतम में गिरने का कम जोखिम भी है। उनका शून्य ग्रेडिएंट विधियों की तुलना में काफी कम अभिसरण दर है। आनुवांशिक एल्गोरिदम का सार प्राकृतिक चयन की प्रक्रिया को इष्टतम समाधान खोजने के साधन के रूप में अनुकरण करना है, वंशानुगत जानकारी को पीढ़ी से पीढ़ी तक जीन के माध्यम से संचारित करने के तंत्र का उपयोग करना। शरीर के "जीवन" की सफलता के उपाय के रूप में, लक्ष्य अनुकूलन फ़ंक्शन का उपयोग किया जाता है, जिसे GA के संदर्भ में "फिटनेस फ़ंक्शन" कहा जाता है। हमारे मामले के लिए GA एल्गोरिदम के संचालन का वर्णन करने से पहले, हम उन अवधारणाओं की सूची सूचीबद्ध करते हैं जिनके साथ हम काम करते हैं और संक्षेप में उनका अर्थ समझाते हैं।
फिटनेस फ़ंक्शन - एक पीढ़ी (आबादी) में किसी व्यक्ति के "जीवन" की गुणवत्ता निर्धारित करता है। हमारे मामले में फिटनेस फ़ंक्शन की भूमिका चेहरे के चित्रों के दिए गए आधार पर चेहरे की तुलना करने के लिए हमारे एल्गोरिथ्म का उपयोग करके चेहरे की पहचान पर एक कार्यक्रम प्रयोग द्वारा की जाती है। फिटनेस फ़ंक्शन का परिणाम किसी विशेष गुणसूत्र के लिए सही ढंग से पहचाने गए चेहरों का प्रतिशत है।
गुणसूत्र - जनसंख्या में व्यक्ति को निर्धारित करता है, वास्तव में, यह हमारे चेहरे के क्षेत्रों के महत्व का मैट्रिक्स है। प्रत्येक गुणसूत्र लक्ष्य समस्या को हल करने के लिए एक उम्मीदवार है।
फिटनेस एक गुणसूत्र द्वारा एन्कोड किए गए व्यक्ति के जीवन की गुणवत्ता है। यह गुणसूत्र के लिए फिटनेस फ़ंक्शन को लागू करने का परिणाम है। हमारे मामले में, यह चेहरे के क्षेत्रों के महत्व के भार के एक दिए गए मैट्रिक्स के साथ वर्गीकरण की सटीकता है।
जनसंख्या 100 अलग-अलग गुणसूत्रों का एक समूह है, जीन {0,1,2,3} के वैध सेट से मानों के साथ एन्कोड किए जाते हैं। मान या तो पूरी तरह से यादृच्छिक (पहली आबादी) हो सकते हैं या विकासवादी प्रक्रिया (क्रॉस और म्यूटेशन) के उत्पाद हो सकते हैं।
क्रॉसिंग (प्रजनन) एक नया गुणसूत्र प्राप्त करने की प्रक्रिया है। "बच्चे" का नया गुणसूत्र "माता-पिता" के गुणसूत्रों के कुछ हिस्सों से बनता है। माता-पिता की प्रत्येक जोड़ी के लिए हर बार एक यादृच्छिक संख्या जनरेटर का उपयोग करके क्रॉसिंग बिंदु का चयन किया जाता है। चयन द्वारा माता-पिता का चयन किया जाता है।
चयन "माता-पिता" गुणसूत्रों के चयन की प्रक्रिया है जिसमें से एक नई आबादी के लिए गुणसूत्रों का गठन किया जाएगा। चयन कई "माता-पिता" में प्रवेश करने वाले गुणसूत्रों की संभावना को बढ़ाने के लिए डिज़ाइन किया गया है जिन्होंने इस समय बाद की आबादी में बेहतर फिटनेस दिखाया है। हम एक स्टोकेस्टिक दृष्टिकोण, संभावना का उपयोग करते हैं

आई-वें गुणसूत्र की पसंद:
जहां:
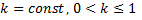
।
उत्परिवर्तन - पार करने के बाद एक गुणसूत्र मूल्य को यादृच्छिक मान से बदलने की प्रक्रिया, उत्परिवर्तन की संभावना पूर्व निर्धारित है।
अभिजात्य एक नई पीढ़ी के गठन की एक विशेषता है, जिसका सार इस तथ्य में निहित है कि सर्वश्रेष्ठ माता-पिता व्यक्तियों को सीधे नई पीढ़ी में शामिल किया गया है। उनकी संख्या 1 या अधिक से हो सकती है।
प्रयोग का विवरण
- 100 गुणसूत्रों की प्रारंभिक आबादी उत्पन्न होती है, जिनमें से मान यादृच्छिक मानों से भरे होते हैं।
- आबादी के प्रत्येक गुणसूत्र पर एक फिटनेस फ़ंक्शन लागू होता है, जो गुणसूत्रों के लिए फिटनेस मूल्य निर्धारित करता है।
- चयन की मदद से, सबसे अनुकूलित गुणसूत्र, जो कई "माता-पिता" बनाते हैं, चुने जाते हैं।
- माता-पिता के सेट से यादृच्छिक जोड़े का चयन किया जाता है, क्रॉस का प्रदर्शन किया जाता है, और "बच्चों" के गुणसूत्र बनते हैं।
- म्यूटेशन प्रक्रिया "बच्चों" के गुणसूत्रों पर लागू होती है।
- परिणामी गुणसूत्र एक नई आबादी बनाते हैं, जिसमें से चरण 2) - 5) का प्रदर्शन किया जाता है।
- यदि सुधार लंबे समय तक नहीं होता है (कहते हैं, 30 आबादी या अधिक), एक पड़ाव होता है। जिस गुणसूत्र ने बेहतर फिटनेस दिखाई है, वह समस्या का समाधान है।
प्रयोगों
हमारे प्रयोगों के लिए निम्नलिखित जैविक व्याख्या दी जा सकती है: जैविक व्यक्ति जो चेहरे के "गलत" क्षेत्रों पर ध्यान देते हैं; जिन व्यक्तियों की अच्छी पहचान क्षमता होती है, वे जीवित रहते हैं और अधिक संतान देते हैं।
पहला प्रयोग चेहरे की छवियों के प्रसिद्ध आधार रंग FERET [11] पर किया गया था। कई सत्रों के दौरान फोटो खिंचवाने वाले 100 लोगों के चेहरों का चित्र इस डेटाबेस से चुना गया, प्रति व्यक्ति 5 उदाहरण। Color FERET फेस डेटाबेस से छवियों के उदाहरण अंजीर में दिखाए गए हैं। 2. इस डेटाबेस में विभिन्न प्रकाश स्थितियों में और विभिन्न चेहरे के भावों के साथ कई फोटो सत्रों में प्राप्त चेहरों की छवियां हैं। वास्तविक चेहरे के खंडों को वियोला-जोन्स फेस डिटेक्टर पर आधारित फेस डिटेक्शन मॉड्यूल द्वारा स्वचालित रूप से चुना गया था, जो ओपनसीवी का हिस्सा है। इसके अलावा इसमें ललाट तल में घूर्णन के आकार, स्थिति और कोण में छवि का सामान्यीकरण शामिल है (जिसके लिए चेहरा, नाक और मुंह अतिरिक्त रूप से खोजा जाता है)।
अंजीर। 2. रंग फ़ेरेट फेस डेटाबेस से चेहरे के उदाहरण।प्रयोग का सार "एकल चेहरा प्रति व्यक्ति" मोड में व्यक्तियों को वर्गीकृत करना है। मान्यता एल्गोरिथ्म डेटाबेस से इनपुट के रूप में प्रत्येक व्यक्ति के चेहरे की एक तस्वीर प्राप्त करता है, जिसके बाद यह डेटाबेस में अपने सभी अन्य और अन्य लोगों के चेहरे की छवियों के साथ चयनित चेहरे की तुलना करता है और प्रमाणीकरण कई गुना पर 1 और 2 तरह के प्रमाणीकरण त्रुटियों की निर्भरता बनाता है, अर्थात्। । झूठी स्वीकृति दर (एफएआर) और झूठी अस्वीकार दर (एफआरआर) निर्भरता घटता है। एफएआर त्रुटि "झूठी पहुंच" की स्थिति से मेल खाती है, जब सिस्टम गलत तरीके से "अपने स्वयं के रूप में अजनबी को पहचानता है"; FRR त्रुटि एक "मिस्ड टारगेट" है जब सिस्टम गलत तरीके से "अपने स्वयं के पहचान नहीं करता है"। लागू की गई समस्या की शर्तों के अनुसार हम हल कर रहे हैं, एफआरआर मूल्य 20% से अधिक नहीं होना चाहिए। प्रयोगों के परिणामों के अनुसार, सभी चेहरों पर कुल मान्यता त्रुटि बनाई जाती है, जिसकी भूमिका में HTER (हाफ टोटल एरर रेट) त्रुटि का उपयोग किया जाता है, अर्थात। औसत FAR और FRR के बराबर पहुँच त्रुटि।
कलर फेरेट फेस डेटाबेस के लिए, यूनिट वेट के साथ एफएआर मान्यता त्रुटि 21% थी (यानी सही उत्तरों का 79%), जो कि चेहरे की पहचान के तरीकों के आधुनिक अत्याधुनिक स्तर के करीब है। चेहरे के क्षेत्रों (छवि 3) के महत्व के वजन मैट्रिक्स का अनुकूलन करने के लिए आनुवंशिक एल्गोरिदम लागू करने के बाद, एफएआर मान्यता त्रुटि को 12% तक घटा दिया गया था, अर्थात। मूल की तुलना में लगभग 2 गुना कम करें।
अंजीर। 3. रंग FERET के आधार पर चेहरे के क्षेत्रों के महत्व के वजन मैट्रिक्स का अनुकूलन करने के लिए आनुवंशिक एल्गोरिदम को लागू करने का परिणाम है।अलग-अलग दौड़ के साथ-साथ वास्तविक स्थितियों के करीब एक प्रयोग का आयोजन करने के लिए, हमने अपना फेस डेटाबेस ZZWolf ABC फेस डेटाबेस एकत्र किया है, जिसमें विभिन्न रेस (एबीसी = एशियन, ब्लैक, कोकेशियान) के लोगों के चेहरे शामिल हैं। लोगों के आधार में तीन मुख्य दौड़ के लिए लोगों के नमूने हैं, प्रत्येक दौड़ के 10 लोगों (5 पुरुषों और 5 महिलाओं) के लिए 10 लोग, इंटरनेट पर लोगों की तस्वीरें एकत्र की गईं, कुल 300 लोग। ये मुख्य रूप से प्रसिद्ध लोगों (अभिनेताओं और राजनेताओं) के चेहरे हैं, अलग-अलग समय (अलग-अलग शूटिंग में अंतर हो सकता है) और अलग-अलग प्रकाश की स्थिति में चित्रों को विभिन्न कैमरों के साथ लिया गया था।
अंजीर। 4. ZZWolf ABC फेस डेटाबेस से चेहरे के उदाहरण। व्यक्तियों के अलगाव, सामान्यीकरण और पूर्वप्रकरण को स्वचालित रूप से किया गया था।नतीजतन, नए आधार पर चेहरे की पहचान की त्रुटि औसत 37.2% थी। आनुवंशिक एल्गोरिदम को लागू करने के बाद, त्रुटि 32% तक कम हो गई थी।
अंजीर। 5. विभिन्न दौड़ के लिए ZZWolf ABC फेस डेटाबेस के आधार पर चेहरे के क्षेत्रों के महत्व के वजन मैट्रिक्स का अनुकूलन करने के लिए आनुवंशिक एल्गोरिदम को लागू करने का परिणाम है।तालिका 1. ZZWolf एबीसी चेहरे के आधार पर मान्यता परिणाम | एशियाई के लिए
| अश्वेतों के लिए
| गोरों के लिए
| औसत
|
महत्व का इकाई भार
(चेहरे के सभी हिस्से बराबर हैं)
| 38,0%
| 35,3%
| 38,3%
| 37,2%
|
आनुवांशिक एल्गोरिदम द्वारा अनुकूलित महत्व वज़न
| 34,3%
| 29,0%
| 32,8%
| 32,0%
|
चेहरे के क्षेत्रों के महत्व के परिणामस्वरूप अनुकूलित मैट्रिसेस को अंजीर में दिखाया गया है। 6, विभिन्न जातियों के लिए वे भिन्न हैं। हमारे चेहरे "ZZWolf एबीसी फेस डेटाबेस" का नमूना मात्रा में छोटा है, इसलिए हम यह दिखावा नहीं करते हैं कि अलग-अलग दौड़ के लिए चेहरे के क्षेत्रों के महत्व के प्रायोगिक रूप से प्राप्त मेट्रिक्स किसी भी परिस्थिति में इष्टतम हैं और वास्तविक लोगों में जैविक चेहरे की पहचान प्रणालियों के लिए पूरी तरह से अनुरूप हैं।
अंजीर। 6. विभिन्न जातियों के लिए चेहरे के वर्गों के महत्व के मैट्रीस। रंग जितना अधिक लाल होगा, उतना ही महत्वपूर्ण है।फिर भी, यदि हम इस परिकल्पना को स्वीकार करते हैं कि विभिन्न जातियों के लोग, एक-दूसरे के चेहरे को पहचानते समय, चेहरे के उन क्षेत्रों पर अधिक ध्यान देते हैं जो उनकी जाति के लिए विशिष्ट हैं, और इस वजह से विभिन्न जातियों के प्रतिनिधियों (उदाहरण के लिए, यूरोपीय और एशियाई) एक-दूसरे को पहचानना मुश्किल है , फिर परिणामों की व्याख्या निम्नानुसार की जा सकती है: गोरों के लिए, आँखों का क्षेत्र नाक के क्षेत्र को काला करने के लिए, और एशियाई लोगों के लिए, कानों का क्षेत्र और मेहराब के ऊपर माथे का क्षेत्र है।
निष्कर्ष
लेख चेहरे की पहचान एल्गोरिथ्म की सटीकता में सुधार के लिए एक विधि प्रस्तुत करता है, जिसका उपयोग आनुवंशिक एल्गोरिदम के उपयोग के आधार पर ZZPhoto कार्यक्रम में किया जाता है। विभिन्न चेहरे के आधारों पर प्रयोग 20% से 2 बार मान्यता की गुणवत्ता में सुधार दिखाते हैं। विधि काफी सामान्य है और इसे विभिन्न क्लस्टर फेस रिकग्निशन एल्गोरिदम पर लागू किया जा सकता है। विभिन्न जातियों के प्रतिनिधियों के चेहरों के नमूने पर प्रयोगों के परिणाम दिलचस्प परिणाम देते हैं, संभवतः लोगों में चेहरे की पहचान के कुछ प्राकृतिक तंत्रों की व्याख्या करते हैं।
संदर्भ
- डब्ल्यू। झाओ, आर। चेलप्पा, पीजे फिलिप्स, ए। रोसेनफेल्ड। चेहरा पहचान: एक साहित्य सर्वेक्षण, एसीएम कम्प्यूटिंग सर्वेक्षण के जर्नल (CSUR), 2003, खंड 35, अंक 4, पीपी। 399 - 458।
- पी। ड्रुव, पी। स्टिंग्रूब, एच। हंसेलमैन, एच। नेय। सर्फ़-फेस: फेस व्यू रिकॉग्निशन अंडर व्यू पॉइंट कंसिस्टेंसी कंस्ट्रक्शंस // प्रोसीडिंग्स ब्रिटिश मशीन विजन कॉन्फ्रेंस, 2009
- आर। गोटुमुक्कल, वीके असारी। मॉड्यूलर पीसीए दृष्टिकोण // पैटर्न मान्यता पत्र, 2004, वॉल्यूम 25, अंक 4, पीपी पर आधारित एक बेहतर चेहरा पहचान तकनीक। 429 - 436।
- एचवी गुयेन, एल। बाई, एल। शेन। स्थानीय गैबर बाइनरी पैटर्न व्हाइट्ड पीसीए: बायोमेट्रिक में एकल छवि प्रति व्यक्ति // अग्रिमों से चेहरे की पहचान के लिए एक उपन्यास दृष्टिकोण। कंप्यूटर विज्ञान में व्याख्यान नोट्स 5558, 2009, पीपी। 269 - 278।
- एचआर कानाणा, के। फेज, वाई। गाब। प्रति व्यक्ति एकांतर छवि से प्रतिमान भारित पैच PZM सरणी का उपयोग करके चेहरा पहचान // पैटर्न मान्यता, 2008, वॉल्यूम 41, अंक 12, पीपी। 3799 - 3812।
- एस निकान, एम। अहमदी। LBP और एन्ट्रापी वेटेड वोटिंग का उपयोग करके रोड़ा के तहत मानव चेहरे की पहचान // पैटर्न मान्यता (ICPR), 11-15 नवंबर को 21 वीं अंतर्राष्ट्रीय सम्मेलन। 2012, पीपी। 1699 - 1702।
- टी। अहोनेन, ए। हदीद, एम। पीटरकैनन। स्थानीय बाइनरी पैटर्न के साथ चेहरा विवरण: फेस रिकॉग्निशन के लिए आवेदन // पैटर्न विश्लेषण और मशीन, 2006, वॉल्यूम 28, अंक, 12, पीपी। 2037 - 2041।
- बी। केपेनेस्की, एफबी टेक, जी। बोजदागी अकार, गाबोर तरंगों के आधार पर अंकित चेहरा पहचान, ICIP 2002, सितंबर 2002, रोचेस्टर, NY, MP-P3.10।
- H.-S. Le, H. Li, प्रति व्यक्ति एक प्रशिक्षण छवि के साथ छिपे हुए मार्कोव मॉडल का उपयोग करते हुए ललाट चेहरे की छवियों को पहचानते हुए, पैटर्न मान्यता (ICPR04), वॉल्यूम पर 17 वें अंतर्राष्ट्रीय सम्मेलन की कार्यवाही। 1, 2004, पीपी। 318-321।
- डी। रुतकोवस्काया, एम। पिलिंस्की, एल। रुतकोवस्की। तंत्रिका नेटवर्क, आनुवंशिक एल्गोरिदम और फ़ज़ी सिस्टम // ट्रांसलेशन। पोलिश एम। से: हॉटलाइन-टेलीकॉम, 2004 - 452 पी।
- www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
- www.nist.gov/itl/iad/ig/colorferet.cfm
अद्यतन: दौड़ के नाम अंग्रेजी भाषा विकिपीडिया के साथ संरेखित हैं।