नमस्ते! मेरा नाम इल्या कटसेव है, और मैं यांडेक्स में परीक्षण विभाग में एक छोटी अनुसंधान इकाई का प्रतिनिधित्व करता हूं। आप पहले से ही हमारे प्रायोगिक
प्रोजेक्ट रोबोटस्टर के बारे में पढ़ सकते हैं - एक रोबोट जो परीक्षक के लिए नियमित काम का एक महत्वपूर्ण हिस्सा कर सकता है।
हमारा मुख्य लक्ष्य यैंडेक्स में त्रुटियों को खोजने के लिए मौलिक रूप से नए दृष्टिकोणों का आविष्कार करना है। मैं वास्तव में यह अनुमान लगाना पसंद करता हूं कि भविष्य में कितना काम रोबोटों के कंधों पर पड़ेगा। वे पहले से ही महान
खेल रिपोर्ट लिखते हैं और
सैनिकों के लिए भार उठाते हैं । सामान्य तौर पर, मुझे ऐसा लगता है कि मानव प्रगति सीधे काम की मात्रा पर निर्भर करती है जिसे हम रोबोट को स्थानांतरित कर सकते हैं - इस मामले में लोगों के पास खाली समय है और वे शांत नई चीजों के साथ आते हैं।

एक ऐसी थीसिस है, जिसे मैं व्यक्तिगत रूप से - किसी भी रोबोट का समर्थक हूं, जो कि एक अप्रस्तुत उपयोगकर्ता को एक रोबोट द्वारा पता लगाया जा सकता है। यही हमने सत्यापित करने का प्रयास किया। लेकिन यहां यह सवाल उठता है: वास्तव में एक व्यक्ति क्या गलती मानता है?
किसी ने अभी तक कृत्रिम बुद्धि का आविष्कार नहीं किया है (हालांकि हॉकिंग, उदाहरण के लिए,
मानते हैं कि यह बेहतर के लिए है), लेकिन हम अपनी सफलताओं को प्राप्त करने में कामयाब रहे। इस पोस्ट में मैं इस बारे में बात करूंगा कि कैसे हमने उस अनुभव को तैयार किया जो मानव परीक्षकों के पास है और उसे हमारे रोबोट को सिखाने की कोशिश की, और इसके बारे में क्या आया।
Robotester। पहला दृष्टिकोण
जब हमने रोबोटस्टर बनाया, तो हमें रूटीन काम को स्वचालित करने के काम से सामना करना पड़ा, जिसमें परीक्षक का समय लगता है। हमने एक वेब पेज खोलने के लिए एल्गोरिदम सिखाया, यह समझें कि तत्वों के साथ क्या क्रियाएं की जा सकती हैं, टेक्स्ट फ़ील्ड भरें, बटन दबाएं और त्रुटि होने पर अनुमान लगाने का प्रयास करें। लेकिन हमें एक समस्या थी - यह पता चला कि उच्च विश्वसनीयता के साथ रोबोट केवल सबसे तुच्छ त्रुटियों का पता लगा सकता है।
तथ्य यह है कि ऑपरेशन के रोबोट के सिद्धांत - संभव के रूप में कई पृष्ठों की जांच - बड़ी संख्या में परीक्षण किए गए, जिसका मतलब था कि त्रुटि का निर्धारण करने की सटीकता एक महत्वपूर्ण कारक बन गई। हमने गणना की कि Yandex.Market की जांच करने के लिए, हमारे रोबोट ने प्रति दिन 800,000 अलग-अलग चेक किए। तदनुसार, यदि चेक की झूठी सकारात्मक दर औसतन 0.001 (जो कि एक छोटी संख्या लगती है) है, तो हर दिन कथित तौर पर मिली 800 त्रुटियों के बारे में एक रिपोर्ट प्राप्त की जाएगी, जो वास्तव में नहीं हैं। स्वाभाविक रूप से, यह किसी के अनुरूप नहीं है।
यह ध्यान दिया जाना चाहिए कि "नकली" त्रुटि संदेश हमेशा होते हैं। विशेष रूप से जब यह वेब परीक्षणों की बात आती है, क्योंकि वे सहायक उपकरणों का उपयोग करते हैं - ब्राउज़र के साथ समस्याएं हो सकती हैं जो रोबोट का उपयोग करती हैं, इंटरनेट के साथ समस्याएं, और इसी तरह।
बहुत "साफ" चेक हैं। उदाहरण के लिए, 404 लिंक प्रतिक्रिया कोड से संकेत मिलता है कि समस्या है। कम सटीकता के साथ एक चेक का उदाहरण पत्र संयोजन की उपस्थिति है, "पाठ में" (अंतरिक्ष और अल्पविराम)। दरअसल, जब अंतरिक्ष और अल्पविराम के बीच कुछ डेटा लोड नहीं होता है, तो ऐसा अक्षर संयोजन त्रुटियों को इंगित करता है। लेकिन कभी-कभी यह सिर्फ टाइपो के बारे में है। खासकर तब जब बाहरी स्रोतों से उपयोगकर्ता टिप्पणियों या सामग्री का पाठ सत्यापन क्षेत्र में आता है। इसलिए, इन त्रुटियों को खोजने के लिए, आपको "झूठे" लोगों से "वास्तविक" समस्याओं को अलग करते हुए, मैन्युअल रूप से कार्य करना होगा।
नतीजतन, रोबोट ने वास्तव में पूरी तरह से परीक्षकों के काम का हिस्सा ले लिया (उदाहरण के लिए, सभी टूटे हुए लिंक पाए गए), लेकिन सभी नहीं। और हमने सोचा कि "रोबोट में खुफिया कैसे जोड़ें"।
कैसे रोबोट त्रुटि के बारे में अनुमान लगाता है?
परंपरागत रूप से, परीक्षण में, परीक्षण के तहत कार्यक्रम कुछ दिए गए इनपुट डेटा के साथ चलाया जाता है और परिणामों की तुलना कुछ प्रकार के पहले सेट "सही" परिणाम के साथ की जाती है। इसे मैन्युअल रूप से सेट किया जा सकता है, या, प्रोग्राम के पिछले संस्करण को लॉन्च करने पर सहेजा गया है (तब हम इस संस्करण और पिछले एक के बीच सभी अंतरों को पा सकते हैं), लेकिन सामान्य सिद्धांत अभी भी वही है। वास्तव में, एक पूरे के रूप में दृष्टिकोण दशकों से नहीं बदला है, केवल इन परीक्षणों को लागू करने के उपकरण बदल रहे हैं।
हालांकि, यह पता चला है कि एक गलती का गठन करने के लिए मौलिक रूप से अलग-अलग दृष्टिकोण संभव हैं।
हमने शुरू में इस तथ्य के बारे में बात की थी कि रोबोट को उन त्रुटियों की पहचान करना सीखना होगा जो कोई भी व्यक्ति कर सकता है, जरूरी नहीं कि वह इस सेवा का एक पेशेवर परीक्षक हो।
तो इस पृष्ठ पर त्रुटि कहां है?

बेशक, सही उत्तर यह है कि नीचे दिए गए पाँच वाक्यों में से डुप्लिकेट वाले हैं। यह समझने के लिए कि यह एक गलती है, आपको मार्केट में एक विशेषज्ञ होने की आवश्यकता नहीं है - आपको केवल न्यूनतम सामान्य ज्ञान की आवश्यकता है।
एक और उदाहरण।
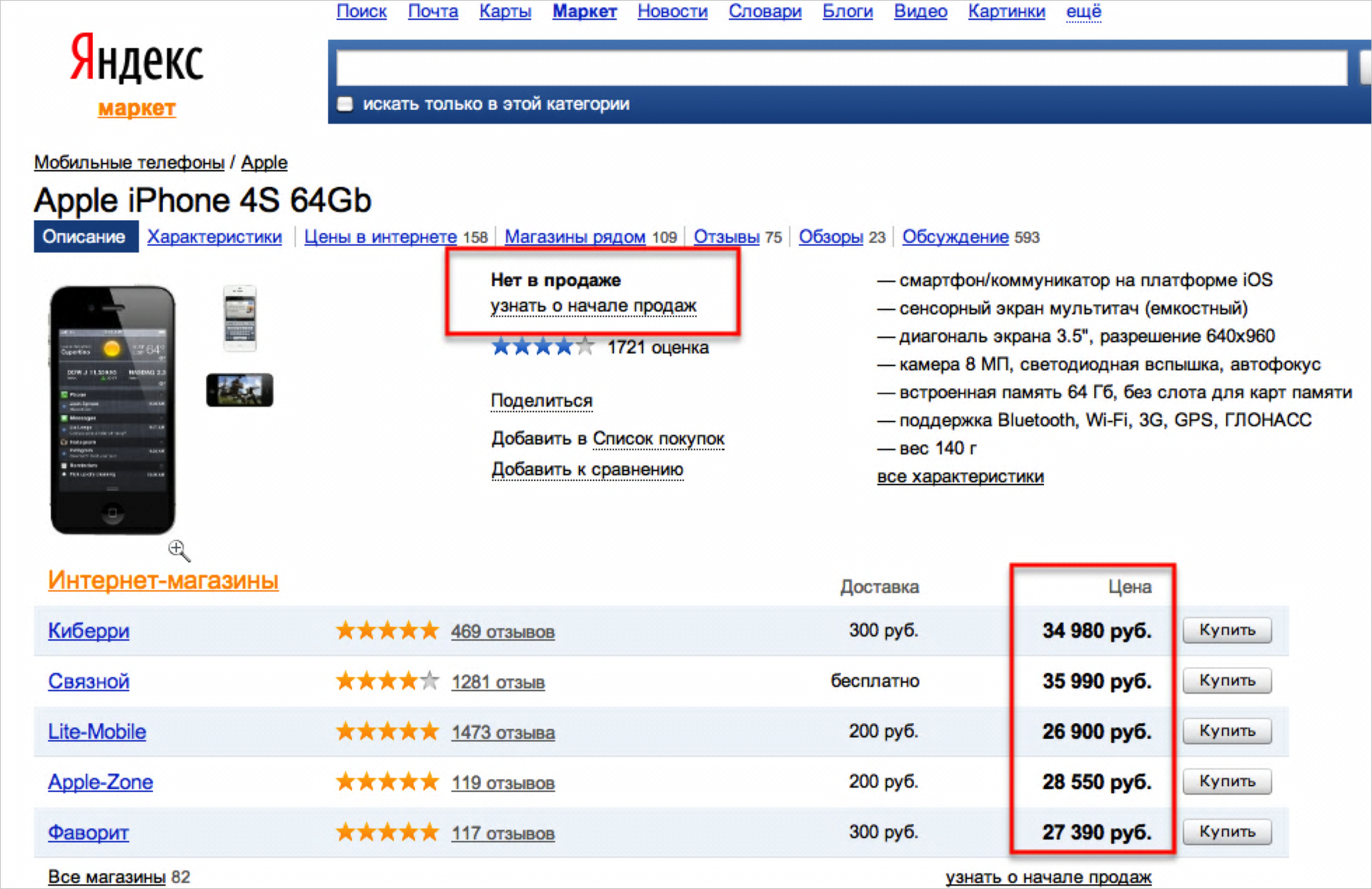
यहां एक जगह यह कहता है कि "बिक्री के लिए नहीं", और दूसरे में - कीमतों का संकेत दिया जाता है। फिर, बिल्कुल कोई भी समझता है कि यह एक गलत स्थिति है।
एक और उदाहरण।
यह सिर्फ एक कोरा पृष्ठ है। यही है, वह मानक "हैडर" और "पाद" है, लेकिन बीच में कोई सामग्री नहीं है।
यहां मुख्य प्रश्न यह उठता है - एक व्यक्ति कैसे समझता है कि यह एक गलती है? यह किस तंत्र पर आधारित है?
हमने लंबे समय तक सोचा, और ऐसा लगता है कि यहां महत्वपूर्ण शब्द अनुभव है। यही है, एक व्यक्ति पहले से ही अपने जीवन में कई वेब पेज देख चुका है, जिनमें से कुछ बिल्कुल उसी प्रकार के थे। और यह उनसे था कि उन्होंने एक निश्चित पैटर्न का गठन किया। यह टेम्पलेट या तो बहुत सामान्य हो सकता है ("पृष्ठ खाली नहीं होना चाहिए", "सभी खोज परिणाम अलग-अलग होने चाहिए"), या, इसके विपरीत, इन पृष्ठों से बंधा हुआ है ("दो चयनित ब्लॉकों में एक ही समय में नंबर शामिल नहीं होते हैं")। यही है, इन नियमों को उसके सिर में पहले से ही बनाया गया है और, जैसा कि हम इन उदाहरणों से देखते हैं, वे पूरी तरह से सीधी दिखती हैं।
इस प्रकार, यहां आगे का कार्य स्पष्ट हो गया - हमें यह जानने की आवश्यकता है कि इन नियमों को स्वचालित रूप से कैसे निकाला जाए या बहुत से इसी तरह के वेब पेजों का विश्लेषण न किया जाए।
यह देखा जा सकता है कि तैयार किए गए नियम काफी सरल हैं, और अगर हमने सीखा कि स्वचालित रूप से उन्हें कैसे निकालना है, तो मानव हस्तक्षेप के बिना ऑटोटेस्ट्स बनाना संभव होगा। उदाहरण के लिए, रोबोट को यैंडेक्स सेवाओं के कई पृष्ठों का विश्लेषण करने के लिए दिया गया है, और यह समझता है कि नीचे उन सभी पर "कंपनी के बारे में" एक लिंक है। तदनुसार, इस तथ्य को एक नियम के रूप में तैयार किया गया है, और रोबोट सेवा के नए संस्करण या किसी अन्य सेवा के लिए भी इसके कार्यान्वयन की जांच करेगा।
इस विचार का सबसे सरल अनुप्रयोग यह है: हम उत्पादन में सेवा के सभी पृष्ठों का विश्लेषण करते हैं, ऐसे "नियमों" को अलग करते हैं, और फिर जाँचते हैं कि क्या वे एक ही सेवा के नए संस्करण के लिए निष्पादित किए गए हैं।
यह दृष्टिकोण लंबे समय से सभी को ज्ञात है। इसे बैक-टू-बैक परीक्षण कहा जाता है और ऐसे लोग हैं जो इसका उपयोग करते हैं। हालांकि, यह विधि केवल तभी लागू होती है जब सेवा को संस्करण से विशेष रूप से नहीं बदलना चाहिए।
आइए कल और आज खोज परिणामों को देखें - खोज परिणाम और विज्ञापन अगले बदल रहे हैं। वे उपयोगकर्ता के क्षेत्र, उनकी प्राथमिकताओं, दिन के समय, अंत में निर्भर करते हैं। तदनुसार, प्रत्यक्ष तुलना में बहुत अधिक "कचरा" होगा (ध्यान दें कि कुछ स्थितियों में ऐसी प्रत्यक्ष विधि स्वीकार्य है)।
यहां हम अपने विचार को विकसित करते हैं और कचरे की "साफ" की तुलना करते हैं - हम खुद पृष्ठों की तुलना नहीं करते हैं, लेकिन पृष्ठों के कुछ "मॉडल" हैं।
ब्लॉक
सामान्य विचार तैयार करने के बाद, हमें इसे लागू करने के तरीके पर आगे बढ़ना चाहिए। हमारा काम स्वचालित रूप से नियमों को निकालना है। मानव समझ के लिए, वे बहुत सरल हैं। हम उन्हें "ब्लॉक" की भाषा में तैयार करते हैं - हम इस बारे में बात कर रहे हैं कि पृष्ठ के एक निश्चित हिस्से में एक तत्व है या नहीं, क्या एक निश्चित ब्लॉक पृष्ठ पर मौजूद है, और इसी तरह। किसी व्यक्ति के लिए, पृष्ठ को प्राकृतिक तरीके से उनमें विभाजित किया गया है - यहां प्राधिकरण फ़ॉर्म है, यहां खोज फ़ॉर्म है (और इसमें उप-ब्लॉक खोज बार हैं, "खोज" बटन)। हालांकि, रोबोट "HTML" कोड को उसके सामने देखता है, और यह उसके लिए पूरी तरह से अस्पष्ट है कि इस कोड का कौन सा हिस्सा ब्लॉक बनाता है।
हमने एक ब्लॉक की अवधारणा को स्पष्ट रूप से स्पष्ट करने का निर्णय लिया। यही है, सबसे पहले हमने अपने लिए यह समझने का फैसला किया कि हम इंसानों को ब्लॉक क्यों कहते हैं। देखते हैं कि ब्लॉक क्या हैं।
1. स्थायी। पूरा ब्लॉक हर पेज पर मौजूद है)।
2. बदल रहा है। हर पेज पर एक टैग मौजूद होता है, लेकिन इसके अंदर हर बार सब कुछ बदल जाता है।
3. एक पृष्ठ पर एक समान ब्लॉक।
4. एक ही प्रकार, लेकिन एक ही पृष्ठ पर अनिवार्य रूप से अलग-अलग ब्लॉक।

इसके अलावा, विभिन्न पृष्ठों पर एक ही ब्लॉक अलग-अलग स्थानों पर खड़े हो सकते हैं।



यही है, हमारे लिए, "ब्लॉक" पृष्ठ का एक निश्चित हिस्सा है, जो जब बदला जाता है, कम या ज्यादा स्थिर रहता है। उदाहरण के लिए, एक व्यक्ति आसानी से समझता है कि पैराग्राफ 2 (ऊपर देखें) से रूपों "समान नारंगी आकार" के विशेष मामले हैं, लेकिन प्रपत्र की सामग्री बदल जाती है।
एक अलग समस्या को एक पंक्ति में जाने वाले कई समान ब्लॉकों द्वारा दर्शाया गया है। कभी-कभी यह "एक ही प्रकार के कई ब्लॉक" होता है, और कभी-कभी यह विभिन्न प्रकार की वस्तुओं का एक सेट होता है, और फिर मैं यह समझना चाहता हूं कि सामान्य रूप से किस प्रकार की वस्तुएं हैं।
सबसे पहले, हमें प्रत्येक पृष्ठ पर पहले से चयनित ब्लॉक को चिह्नित करने के लिए किसी तरह की आवश्यकता है। एक पारंपरिक xpath (उदाहरण के लिए,
/html/body/div[1]/table[2]/tbody/tr/td[2]/div[2]/ul/li[3]/span/a ) उपयुक्त नहीं है क्योंकि इसमें संख्याएँ बदल सकती हैं - एक ही ब्लॉक लगातार तीसरी या पाँचवीं हो सकती है। इस बात पर निर्भर करता है कि अन्य ब्लॉक क्या हैं (अंतिम दो उदाहरण देखें)।
इसलिए, हम पहले xpath (नंबर
/html/body/div/table/tbody/tr/td/div/ul/li/span/a बजाय
/html/body/div[1]/table[2]/tbody/tr/td[2]/div[2]/ul/li[3]/span/a से नंबर निकालते हैं
/html/body/div[1]/table[2]/tbody/tr/td[2]/div[2]/ul/li[3]/span/a ) और हमें बहुत अधिक स्थिर मिलान विकल्प मिलता है (अर्थात, यह ब्लॉक किसी भी पेज पर xpath के अंतर्गत आएगा), लेकिन कम सटीक - अर्थात्, कई तत्व अब एक ही xpath के अनुरूप हो सकते हैं। इस अशुद्धि को कम करने के लिए, हम प्रत्येक टैग के विवरण में इसकी कुछ विशेषताओं के मूल्यों को जोड़ते हैं। हमने केवल अपने हाथों से विशेषताओं को कम या ज्यादा स्थिर लोगों में विभाजित किया है। उदाहरण के लिए, आईडी विशेषता अक्सर नए सिरे से उत्पन्न होती है जब पेज लोड होता है, अर्थात यह हमारे लिए पूरी तरह से अनइंफॉर्मेटिव होता है। उदाहरण के लिए, ऊपर दिए गए ब्लॉक के लिए, निम्नलिखित विवरण प्राप्त किया गया है: एक और ipath
<body> <div class="b-max-width"> <table class="l-head"> <tbody> <tr> <td class="l-headc"> <div class="b-head-search" onclick="return {name:'b-head-search'}"> <div class="b-head-searchwrap b-head-searcharrow"> <form class="b-search"> <table class="b-searchtable"> <tbody> <tr> <td class="b-searchinput"> <span class="b-form-input b-form-input_is-bem_yes b-form-input_size_16 i-bem" onclick="return {'b-form-input':{name:'b-form-input'}}"> <span class="b-form-inputbox"> <text src=" Turion II">
अब चलो ब्लॉकों की तलाश करते हैं। यदि हम एक
पेड़ के रूप में HTML कोड का प्रतिनिधित्व करते हैं, तो हमारा काम रूट वर्टेक्स से स्थिर रास्तों की तलाश करना है (यहाँ स्थिरता का अर्थ है कि पृष्ठ बदलने पर पथ थोड़ा बदल जाता है)। ऐसे कई स्थिर पथों के निर्माण के लिए एल्गोरिथ्म हमारे टूल का मुख्य हिस्सा है। हमने इसे "परीक्षण और त्रुटि के द्वारा" बनाया है। यही है, हमने एल्गोरिदम को संशोधित किया और परिणाम को देखा। मैं नीचे दिए गए एल्गोरिदम का वर्णन करूंगा, लेकिन अब मैं आपको एक पूरी तरह से अप्रत्याशित समस्या के बारे में बताऊंगा - हमें अचानक पता चला कि हम यह नहीं जानते हैं कि पृष्ठ पर कौन से ब्लॉक खड़े थे, कैसे चित्रित करें।
वास्तव में - ब्लॉक विभिन्न पृष्ठों पर अलग दिखता है। हम कुछ के रूप में एक रिपोर्ट प्राप्त करना चाहते थे जो ब्लॉक में टूटे हुए पृष्ठ की तरह दिखे। लेकिन कौन सा ब्लॉक विकल्प लेना है? बार-बार, हम ऐसे मामलों में सामने आए जब एक खाली या बिना सूचना वाला संस्करण हमारी रिपोर्ट में आया। किसी भी तरह से सभी विकल्पों को एक ही पृष्ठ पर दिखाना आवश्यक था। डेवलपर्स में से एक एक अच्छा विचार के साथ आया था - उदाहरण के लिए,
Coub सेवा में
पोर्न साइट्स पर किया
गया : जब आप वीडियो पर माउस ले जाते हैं, तो वहां से फ्रेम बदलते हैं। हमने ठीक यही काम किया है - यदि आप ब्लॉक पर मंडराते हैं, तो यह ब्लॉक "ब्लिंक" करने लगता है, यह दर्शाता है कि यह विभिन्न पृष्ठों पर कैसा दिखता है। यह बहुत सुविधाजनक निकला।
नतीजतन, "पेज मॉडल" कुछ इस तरह दिखता है (नीचे देखें)। आप इसे देख सकते हैं और तुरंत समझ सकते हैं कि कौन से ब्लॉक बाहर खड़े हैं।
ब्लॉक आवंटन एल्गोरिथ्म
अब एल्गोरिथ्म के बारे में। मूल एल्गोरिथ्म इस प्रकार है:
- सेट से एक पृष्ठ का चयन करें।
- हम पहले पृष्ठ से रूट वर्टेक्स से दूसरों तक सभी अधिकतम पथ एकत्र करते हैं।
- फिर प्रत्येक चयनित पथ के लिए हम इसे सभी पृष्ठों पर रखने का प्रयास करते हैं।
यदि पथ का एक हिस्सा रखना संभव था, तो लंबाई में कम से कम 4 से भिन्न होना, हम इस भाग को कई रास्तों से जोड़ते हैं।
यदि यह लगभग सभी रास्ते पर जाता है (वे 1-3 टैग तक नहीं पहुंचते हैं), तो हम इस कट ऑफ संस्करण के साथ सेट में पथ को बदलते हैं। - नतीजतन, परिणामस्वरूप पथ ब्लॉक के अनुरूप हैं। आगे उनसे उन सभी पृष्ठों को चुनना आसान है, या कहें, 95% पृष्ठ।
एल्गोरिथ्म का महान लाभ यह है कि यह रैखिक रूप से पहले पृष्ठ पर तत्वों की संख्या और पृष्ठों की संख्या पर निर्भर करता है।
हालांकि, जैसा कि हमने जल्द ही पता लगाया, ऐसे स्थान हैं जहां एल्गोरिथ्म अच्छी तरह से काम नहीं करता है। उदाहरण के लिए, इन ब्लॉकों के लिए (isbn, लेखक, और इसी तरह):

HTML तत्वों के रूप में वे बिल्कुल समान हैं, वे केवल सीरियल नंबर में भिन्न होते हैं। लेकिन यह तुरंत स्पष्ट है कि इस संख्या का कोई मतलब नहीं है - ऊपर के उदाहरण में, आईएसबीएन या तो दूसरा या पहला है। इसलिए, यह हमारे लिए स्पष्ट हो गया कि इस तरह के तत्वों को अलग करने का एकमात्र तरीका अंदर के पाठ के माध्यम से है। इसलिए, हमने एल्गोरिथ्म को निम्नानुसार बदल दिया: बहुत शुरुआत में हम उन स्थानों की तलाश कर रहे हैं जहां तत्व में कई वंशज हैं जो केवल पाठ में भिन्न हैं। फिर हम सभी पृष्ठों से समान वंशज तत्वों को इकट्ठा करते हैं, और फिर उन्हें पूरे पाठ में क्लस्टर करते हैं ताकि प्रत्येक पृष्ठ में प्रत्येक क्लस्टर के एक से अधिक प्रतिनिधि न हों।
एल्गोरिथ्म में अन्य सुधार थे, लेकिन वे आपके लिए इतने दिलचस्प नहीं हो सकते हैं, क्योंकि वे यांडेक्स बारीकियों से संबंधित हैं। यहां तक कि अब वर्णित एल्गोरिथ्म पृष्ठों के अधिकांश सेट पर काफी अच्छी तरह से काम करेगा।
नियम पीढ़ी
इसलिए, प्रशिक्षण सेट से पृष्ठों की संरचना का विश्लेषण करके, ब्लॉकों का चयन करना और यह समझना कि कौन से ब्लॉक कितने पृष्ठों पर मौजूद हैं, कोई निम्न प्रकार के नियम बना सकता है:
- ब्लॉक ए पृष्ठ पर मौजूद होना चाहिए।
- ब्लॉक ए और बी को एक ही समय में उपस्थित होना चाहिए।
- ब्लॉक ए और बी एक ही समय में मौजूद नहीं हो सकते।
यह संभव है, सिद्धांत रूप में, अधिक जटिल पैटर्न निकालने के लिए, लेकिन हमने अभी तक इससे निपटा नहीं है।
किस प्रकार के लिए हम पहले प्रकार की स्थिति बनाते हैं? उन लोगों के लिए जो पृष्ठों के काफी बड़े अनुपात पर पाए जाते हैं। यह अंश एक विशेष पैरामीटर द्वारा निर्धारित किया जाता है, जिसे हम विश्वास स्तर कहते हैं। इस पैरामीटर को एकता में सेट करना गलत है - जिस तरह से हम शुरू में दो कारणों से करना चाहते थे:
- प्रशिक्षण के नमूने के 100 पृष्ठों में से एक खुल नहीं सकता है (उदाहरण के लिए, टाइमआउट द्वारा), और परिणामस्वरूप, किसी ब्लॉक की अनिवार्य उपस्थिति के बारे में कोई भी स्थिति उजागर नहीं की जाएगी।
- प्रशिक्षण सेट के पन्नों के बीच, गलती से त्रुटियों वाले पृष्ठों का सामना करना पड़ा।
हम पर्यावरण के स्थायित्व के आधार पर इस स्तर के महत्व को बदलते हैं जिसमें हम अपने साधन को प्रशिक्षित करते हैं। पैरामीटर मान को कम करके, आप पर्यावरण की अस्थिरता के प्रभाव को "हटा" सकते हैं। हालांकि, यदि यह पैरामीटर बहुत कम है, तो उपकरण अतिरिक्त अनियमित पैटर्न को उजागर करना शुरू कर देगा। उदाहरण के लिए, यदि 96% माल की कीमत है, और 4% "बिक्री के लिए नहीं" कहते हैं, तो जब पैरामीटर 0.95 पर सेट होता है, तो "बिक्री के लिए नहीं" वाले पृष्ठों को गलत के रूप में चिह्नित किया जाएगा। डिफ़ॉल्ट रूप से, आत्मविश्वास का स्तर 0.997 है।
ब्लॉक की उपस्थिति / अनुपस्थिति के लिए शर्तों के अलावा, हम प्रत्येक ब्लॉक के अंदर पाठ के लिए स्वचालित रूप से स्थितियां उत्पन्न करते हैं। परिस्थितियाँ नियमित अभिव्यक्तियों के रूप में बनती हैं। उदाहरण के लिए, ऐसे पृष्ठ पर प्रकाशन के वर्ष के साथ ब्लॉक पर
निम्नलिखित नियमित मौसम होगा:
प्रकाशन का वर्ष: [0-9] {४}
या यहां तक कि:
प्रकाशन का वर्ष: (19 | 20) [0-9] {2}
इसी समय, यह ब्लॉक स्वयं वैकल्पिक के रूप में चिह्नित है। यही है, निम्नलिखित की जांच की जाती है: यदि ऐसा कोई ब्लॉक है, तो "प्रकाशन के वर्ष" शब्दों के बाद इसे 4 अंक लिखा जाता है या यहां तक कि 4 अंक लिखे जाते हैं, जिनमें से पहले दो 19 या 20 हैं। एक व्यक्ति इस तरह के परीक्षण के बारे में लिखेगा।
व्यवहार में जादू
संक्षेप में, हमारा उपकरण निम्नलिखित कार्य कर सकता है: पृष्ठों के एक सेट के लिए, हम एक निश्चित प्रकार के नियमों को निकालते हैं जो इन पृष्ठों के दिए गए प्रतिशत के लिए निष्पादित होते हैं। बग्स देखने के लिए इसका उपयोग कैसे करें? इसके दो तरीके हैं।
- यह व्यवहार पर विचार करने के लिए एक गलती है जो काफी दुर्लभ है। यह एक विवादास्पद थीसिस है, लेकिन कई बार इस तरह से कार्यात्मक कीड़े ढूंढना संभव था। फिर यह सेवा पर बड़ी संख्या में पृष्ठों का विश्लेषण करने और उन लोगों को चिह्नित करने के लिए पर्याप्त है जो दूसरों के समान नहीं हैं। किसी भी मामले में, यह पथ काम नहीं करेगा यदि, अपेक्षाकृत बोल, "सब कुछ टूट गया है।" इसलिए, हम आमतौर पर एक अलग दृष्टिकोण का उपयोग करते हैं।
- सेवा के संस्करण एन से पृष्ठ एकत्र करें (आमतौर पर सिर्फ उत्पादन से), उन पर नियम बनाएं। फिर सेवा के एन + 1 संस्करण से बहुत सारे पृष्ठ लें (आमतौर पर यह सिर्फ परीक्षण है) और इन नियमों के अनुपालन के लिए जांच करें। संस्करणों एन और एन + 1 के बीच सभी अंतरों की एक समझ में आने वाली सूची प्राप्त की जाती है।
वास्तव में, दूसरे मामले में, हमें वही बात मिलती है जैसे प्रतिगमन ऑटोटिस्ट की उपस्थिति में। हालांकि, हमारे मामले में, एक महान, यहां तक कि भारी लाभ है - इन परीक्षणों के कोड को लिखने और बनाए रखने की आवश्यकता नहीं है! जैसे ही सेवा का एक नया संस्करण पोस्ट किया गया है, मैं "सब कुछ पुनर्निर्माण" बटन पर क्लिक करता हूं और कुछ मिनट बाद "ऑटोटेस्ट्स" का एक नया संस्करण तैयार होता है।
कार्यान्वयन प्रयोग के रूप में, हमने
बाजार के
तुर्की संस्करण को लॉन्च करते समय इस दृष्टिकोण का उपयोग किया। परीक्षण विशेषज्ञों ने आवश्यक मामलों की सूची लिखी और किस पृष्ठों पर क्या करना है, इसकी जाँच की। हमने सेवा के कई पृष्ठों को क्रॉल किया और उन्हें समूहों में विभाजित किया - खोज परिणाम पृष्ठ, श्रेणी पृष्ठ, और इसी तरह। इसके अलावा, पृष्ठों के प्रत्येक समूह के लिए, उपरोक्त नियम स्वचालित रूप से बनाए गए थे और मैन्युअल रूप से जांचे गए थे कि कौन से संकेतित चेक वास्तव में किए गए हैं। यह पता चला है कि लगभग 90% चेक स्वचालित रूप से उत्पन्न हुए थे। उसी समय, ऑटोटेस्ट लिखने के लिए अपेक्षित श्रम लागत लगभग तीन मानव-सप्ताह थे, और हमारा उपकरण एक दिन में सब कुछ करने और कॉन्फ़िगर करने में कामयाब रहा।
बेशक, इसका मतलब यह नहीं है कि अब कोई भी परीक्षण कई बार तेजी से बन सकता है। उदाहरण के लिए, अब तक का हमारा टूल स्वचालित रूप से केवल स्थैतिक परीक्षण (पृष्ठ तत्वों के साथ गतिशील संचालन के बिना) बनाने में सक्षम है।
अब हम विभिन्न यैंडेक्स सेवाओं पर एमटी को लागू करने में व्यस्त हैं ताकि इस सवाल का सटीक जवाब मिल सके कि यह उपकरण किस काम का है। लेकिन यह पहले से ही स्पष्ट है कि काफी
जैसा कि मैंने कहा, रोबोटस्टर और मैजिक टेस्टर परियोजनाएं प्रयोगात्मक हैं और परीक्षण विभाग की अनुसंधान इकाई में की जा रही हैं। यदि आप एक स्नातक हैं और आप अपने कार्यों में खुद को आजमाने में रुचि रखते हैं, तो हमारे लिए इंटर्नशिप के लिए
आएं ।