
शुभ दिन प्रिय Kravravchians। 3 साल से मैं एक ऐसे प्रोजेक्ट पर काम कर रहा हूं जिसमें हम स्प्रिंग का इस्तेमाल करते हैं। मुझे हमेशा यह समझने में दिलचस्पी थी कि यह अंदर कैसे व्यवस्थित होता है। मैंने स्प्रिंग की आंतरिक संरचना के बारे में लेख खोजे, लेकिन दुर्भाग्य से मुझे कुछ नहीं मिला।
जो कोई भी वसंत की आंतरिक संरचना में रुचि रखता है, मैं बिल्ली के लिए पूछता हूं।
आरेख ApplicationContext को बढ़ाने के मुख्य चरणों को दर्शाता है। इस पोस्ट में, हम इन चरणों में से प्रत्येक पर ध्यान केंद्रित करेंगे। कुछ चरण को विस्तार से माना जाएगा, और कुछ को सामान्य शब्दों में वर्णित किया जाएगा।
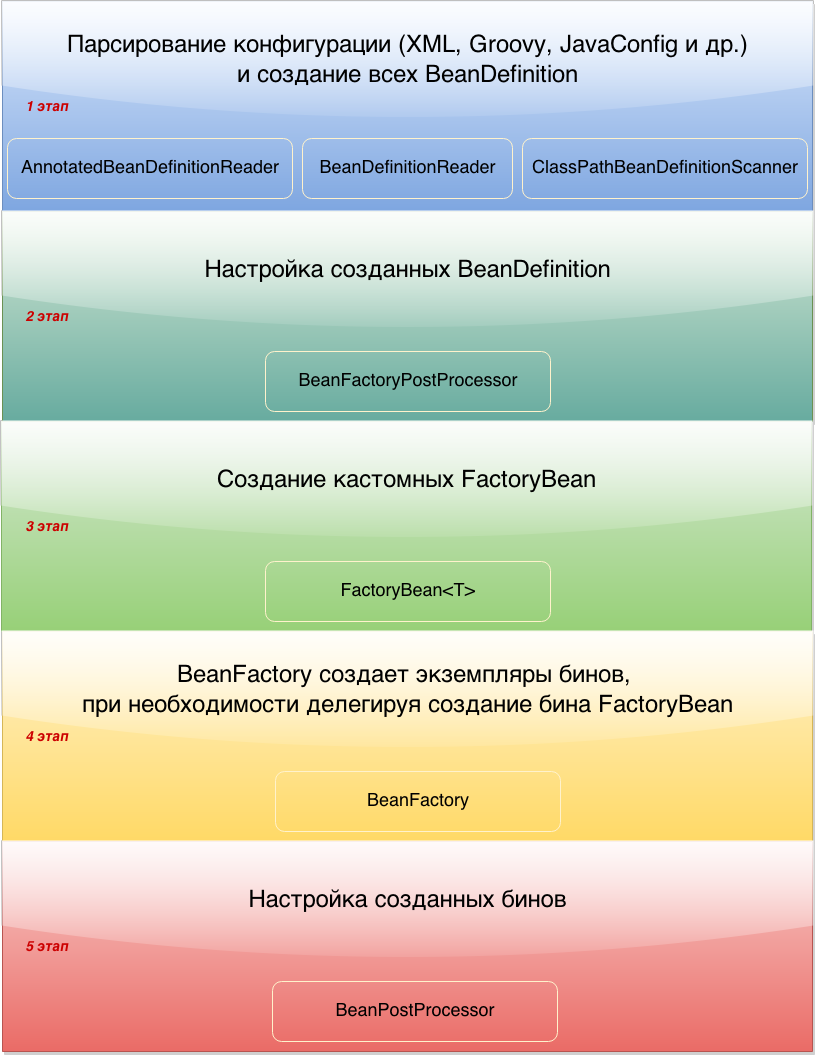
1. पार्सिंग कॉन्फ़िगरेशन और बीनडिफिनिशन बनाना
वसंत के चौथे संस्करण की रिहाई के बाद, हमारे पास संदर्भ को कॉन्फ़िगर करने के चार तरीके हैं:
- Xml कॉन्फ़िगरेशन - ClassPathXmlApplicationContext ("reference.xml")
- एनोटेशन के माध्यम से कॉन्फ़िगरेशन स्कैन करने के लिए पैकेज को इंगित करता है - एनोटेशन कॉनफिग एपिलेशन कॉन्टेक्स्ट ("पैकेजनाम")
- एनोटेशन @Configuration -AnnotationConfigApplicationContext (JavaConfig.class) के साथ चिह्नित वर्ग (या वर्गों का सरणी) को इंगित करने वाले एनोटेशन के माध्यम से कॉन्फ़िगरेशन। इस कॉन्फ़िगरेशन विधि को JavaConfig कहा जाता है।
- Groovy कॉन्फ़िगरेशन - GenericGroovyApplicationContext ("reference.groovy")
चारों विधियाँ बहुत अच्छी तरह से
यहाँ लिखी गई
हैं ।
पहले चरण का लक्ष्य सभी
बीनडिफिनिशन बनाना है।
बीनडेफिनिशन एक विशेष इंटरफ़ेस है जिसके माध्यम से आप भविष्य के बीन के मेटाडेटा तक पहुंच सकते हैं। आपके पास कौन सा कॉन्फ़िगरेशन है, इसके आधार पर, एक या अन्य कॉन्फ़िगरेशन पार्सिंग तंत्र का उपयोग किया जाएगा।
Xml कॉन्फ़िगरेशन
Xml कॉन्फ़िगरेशन के लिए, एक वर्ग का उपयोग किया जाता है -
XmlBeanDefinitionReader , जो
BeanDefinitionReader इंटरफ़ेस को लागू करता है। यहां सब कुछ काफी पारदर्शी है।
XmlBeanDefinitionReader एक
InputStream प्राप्त करता है और
DefaultDocumentLoader के माध्यम से एक
दस्तावेज़ लोड करता है। इसके बाद, दस्तावेज़ के प्रत्येक तत्व को संसाधित किया जाता है और यदि यह एक बिन है, तो एक
बीनडिफाइनमेंट को भरे गए डेटा (आईडी, नाम, वर्ग, उपनाम,
init- विधि, नष्ट-विधि, आदि) के आधार पर बनाया जाता है। प्रत्येक
बीनडिफाइनमेंट को एक मानचित्र में रखा गया है। मानचित्र
DefaultListableBeanFactory वर्ग में संग्रहीत किया जाता है। कोड में, मैप इस तरह दिखता है।
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<String, BeanDefinition>(64);
स्कैन या JavaConfig के लिए संकेत पैकेज के माध्यम से कॉन्फ़िगरेशन
स्कैनिंग या JavaConfig के लिए पैकेज को इंगित करने वाले एनोटेशन के माध्यम से कॉन्फ़िगरेशन मूल रूप से xml के माध्यम से कॉन्फ़िगरेशन से अलग है। दोनों स्थितियों में,
AnnotationConfigApplicationContext वर्ग का उपयोग किया जाता है।
new AnnotationConfigApplicationContext(JavaConfig.class);
या
new AnnotationConfigApplicationContext(“package.name”);
यदि आप AnnotationConfigApplicationContext के अंदर देखते हैं, तो आप दो फ़ील्ड देख सकते हैं।
private final AnnotatedBeanDefinitionReader reader; private final ClassPathBeanDefinitionScanner scanner;
ClassPathBeanDefinitionScanner @Component एनोटेशन (या किसी अन्य एनोटेशन जिसमें
@Component शामिल हैं) के साथ चिह्नित कक्षाओं के लिए निर्दिष्ट पैकेज स्कैन करता है। मिली कक्षाएं पार्स की जाती हैं और उनके लिए बीनडिफाइनमेंट बनाया जाता है।
चलाने के लिए स्कैनिंग के लिए, स्कैनिंग के लिए पैकेज को कॉन्फ़िगरेशन में निर्दिष्ट किया जाना चाहिए।
@ComponentScan({"package.name"})
या
<context:component-scan base-package="package.name"/>
AnnotatedBeanDefinitionReader कई चरणों में काम करता है।
- पहला कदम आगे पार्सिंग के लिए सभी @Configuration को पंजीकृत करना है। यदि कॉन्फ़िगरेशन में सशर्त का उपयोग किया जाता है, तो केवल वे कॉन्फ़िगरेशन जिनके लिए शर्त सही होगी, पंजीकृत हो जाएंगे। वसंत के चौथे संस्करण में सशर्त एनोटेशन दिखाई दिया। इसका उपयोग तब किया जाता है, जब संदर्भ को बढ़ाते समय, आपको यह तय करने की आवश्यकता होती है कि बिन / कॉन्फ़िगरेशन बनाना है या नहीं। और निर्णय एक विशेष वर्ग द्वारा किया जाता है, जिसे शर्त इंटरफ़ेस को लागू करना होगा।
- दूसरा चरण एक विशेष बीनफैक्टरीपोस्टप्रोसेसर को दर्ज करना है , जिसका नाम है बीनडिफिनेशनरेजिस्ट्रीपोस्टप्रोसेसर , जो कि कॉन्फ़िगरेशनक्लासपैसर क्लास का उपयोग करके, जावाकोनफिग को पार्स करता है और बीनफैफिनेशन बनाता है।
ग्रूवी विन्यास
यह कॉन्फ़िगरेशन Xml के माध्यम से कॉन्फ़िगरेशन के समान है, सिवाय इसके कि फ़ाइल एक्सएमएल नहीं है, लेकिन ग्रूवी है। GroovyBeanDefinitionReader वर्ग ग्रूवी कॉन्फ़िगरेशन को पढ़ना और पार्स करना
संभालता है।
2. कॉन्फ़िगर किए गए बीनडिफिनिशन को कॉन्फ़िगर करें
पहले चरण के बाद, हमारे पास एक मैप है, जो
बीनडिफिनिशन को संग्रहीत
करता है । वसंत वास्तुकला को इस तरह से बनाया गया है कि हमारे पास वास्तव में निर्मित होने से पहले हमारी फलियों को प्रभावित करने का अवसर होगा, दूसरे शब्दों में, हमारे पास वर्ग मेटाडेटा तक पहुंच है। ऐसा करने के लिए, एक विशेष इंटरफ़ेस
बीनफैक्टरीपोस्टप्रोसेसर है , जिसे लागू करते हुए, हम निर्मित
बीनडिफाइनमेंट तक पहुंच प्राप्त
करते हैं और उन्हें बदल सकते हैं। इस इंटरफ़ेस में केवल एक विधि है।
public interface BeanFactoryPostProcessor { void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException; }
PostProcessBeanFactory विधि
configurableListableBeanFactory पैरामीटर को स्वीकार करता है। इस कारखाने में कई उपयोगी विधियाँ शामिल हैं, जिनमें
getBeanDefinitionNames शामिल है , जिसके द्वारा हम सभी BeanDefinitionNames प्राप्त कर सकते हैं, और उसके बाद ही किसी विशिष्ट नाम के लिए एक विशिष्ट मेटाडेटा के लिए
BeanDefinition प्राप्त करें।
आइए एक नजर
डालते हैं बीनफैक्ट्रीपोस्टप्रोसेसर इंटरफेस के मूल कार्यान्वयन में
से एक
पर । आमतौर पर, डेटाबेस से कनेक्ट करने के लिए सेटिंग्स को एक अलग संपत्ति फ़ाइल में स्थानांतरित किया जाता है, फिर उन्हें
संपत्ति स्रोत का उपयोग करके लोड किया जाता है। चूंकि इंजेक्शन कुंजी द्वारा किया जाता है, बीन का एक उदाहरण बनाने से पहले, आपको इस कुंजी को संपत्ति फ़ाइल से स्वयं मूल्य के साथ बदलना होगा। यह प्रतिस्थापन एक ऐसे वर्ग में होता है जो
बीनफैक्टरीपोस्टप्रोसेसर इंटरफेस को लागू करता है। इस वर्ग का नाम
प्रॉपर्टीजप्लसहोल्डरकॉन्फिगर है । पूरी प्रक्रिया नीचे दिए गए आंकड़े में देखी जा सकती है।
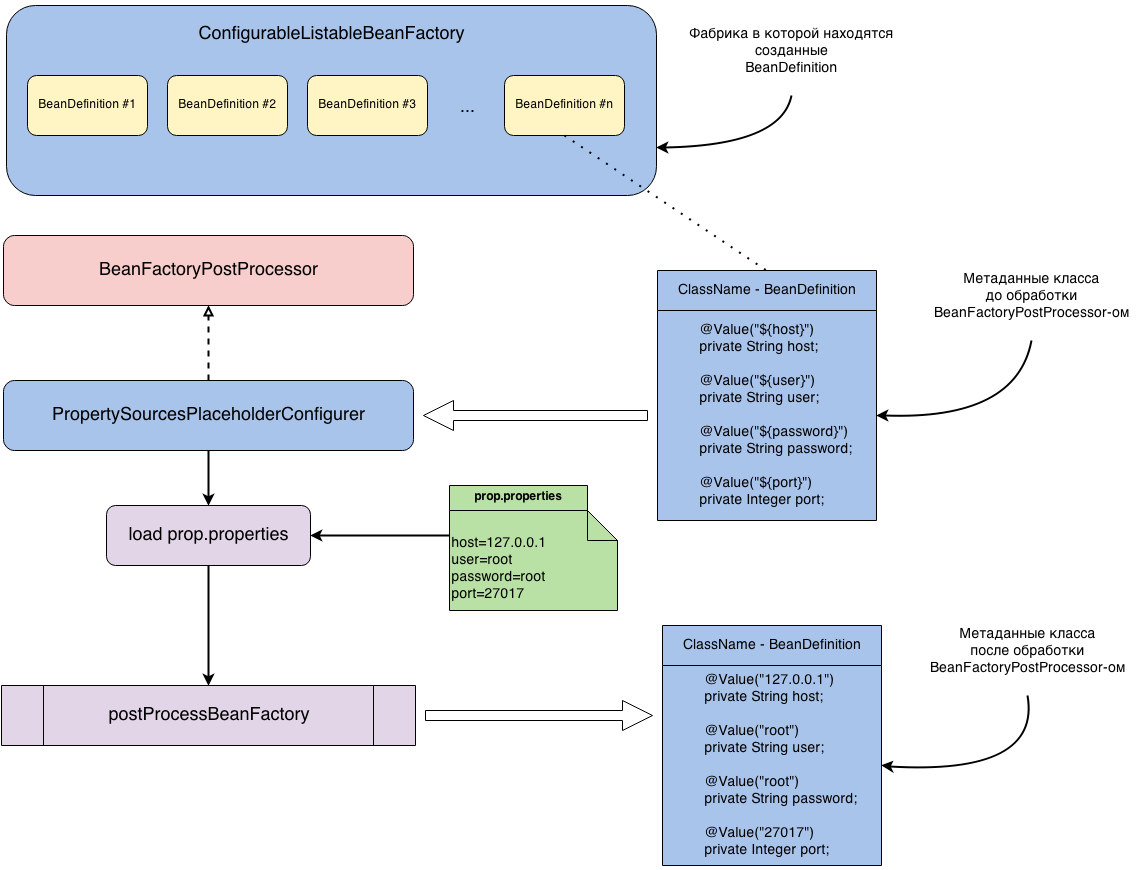
आइए फिर से देखें कि यहां क्या हो रहा है। ClassName क्लास के लिए हमारे पास एक
बीनडेफिनेशन है । वर्ग कोड नीचे दिया गया है।
@Component public class ClassName { @Value("${host}") private String host; @Value("${user}") private String user; @Value("${password}") private String password; @Value("${port}") private Integer port; }
यदि
PropertySourcesPlaceholderConfigurer इस
बीनडिफाइन को संसाधित नहीं करता है, तो ClassName का एक उदाहरण बनाने के बाद, मान "$ {host}" को होस्ट फ़ील्ड में इंजेक्ट किया जाएगा (संबंधित मान शेष क्षेत्रों में इंजेक्ट किया जाएगा)। यदि
PropertySourcesPlaceholderConfigurer अभी भी इस
BeanDefinition को संसाधित
करता है , तो प्रसंस्करण के बाद, इस वर्ग का मेटाडाटा इस तरह दिखेगा।
@Component public class ClassName { @Value("127.0.0.1") private String host; @Value("root") private String user; @Value("root") private String password; @Value("27017") private Integer port; }
तदनुसार, सही मानों को इन क्षेत्रों में इंजेक्ट किया जाएगा।
प्रॉपर्टीजपॉल्सहोल्डरकॉन्फिगर के लिए बनाए गए
बीनडिफिनिशन के सेटिंग लूप में जोड़े जाने के लिए, आपको निम्न में से एक करने की आवश्यकता है:
XML कॉन्फ़िगरेशन के लिए।
<context:property-placeholder location="property.properties" />
JavaConfig के लिए।
@Configuration @PropertySource("classpath:property.properties") public class DevConfig { @Bean public static PropertySourcesPlaceholderConfigurer configurer() { return new PropertySourcesPlaceholderConfigurer(); } }
प्रॉपर्टीजप्लसहोल्डरकॉन्फिगर को स्थैतिक घोषित किया जाना चाहिए। स्थैतिक के बिना, सब कुछ आपके लिए तब तक काम करेगा जब तक आप
@ मान को
@Configuration क्लास के अंदर उपयोग करने का प्रयास नहीं करते।
3. कस्टम FactoryBean बनाना
FactoryBean एक सामान्य इंटरफ़ेस है जिसमें आप टाइप बीन्स बनाने की प्रक्रिया को सौंप सकते हैं। उन दिनों में जब कॉन्फ़िगरेशन एक्सएमएल में विशेष रूप से था, डेवलपर्स को एक तंत्र की आवश्यकता थी, जिसके द्वारा वे सेम बनाने की प्रक्रिया को नियंत्रित कर सकते थे। यह वही है जो इस इंटरफ़ेस के लिए बनाया गया था। समस्या को बेहतर ढंग से समझने के लिए, मैं एक उदाहरण xml कॉन्फ़िगरेशन दूंगा।
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <bean id="redColor" scope="prototype" class="java.awt.Color"> <constructor-arg name="r" value="255" /> <constructor-arg name="g" value="0" /> <constructor-arg name="b" value="0" /> </bean> </beans>
पहली नज़र में, सब कुछ ठीक है और कोई समस्या नहीं है। लेकिन क्या होगा अगर आपको एक अलग रंग की आवश्यकता है? एक और बीन बनाएँ? कोई सवाल नहीं।
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <bean id="redColor" scope="prototype" class="java.awt.Color"> <constructor-arg name="r" value="255" /> <constructor-arg name="g" value="0" /> <constructor-arg name="b" value="0" /> </bean> <bean id="green" scope="prototype" class="java.awt.Color"> <constructor-arg name="r" value="0" /> <constructor-arg name="g" value="255" /> <constructor-arg name="b" value="0" /> </bean> </beans>
लेकिन क्या होगा अगर मुझे हर बार एक यादृच्छिक रंग चाहिए? यह वह जगह है जहां
FactoryBean इंटरफ़ेस बचाव के लिए आता है।
आइए एक कारखाना बनाएं जो सभी प्रकार की फलियां बनाने के लिए जिम्मेदार होगा -
रंग ।
package com.malahov.factorybean; import org.springframework.beans.factory.FactoryBean; import org.springframework.stereotype.Component; import java.awt.*; import java.util.Random; public class ColorFactory implements FactoryBean<Color> { @Override public Color getObject() throws Exception { Random random = new Random(); Color color = new Color(random.nextInt(255), random.nextInt(255), random.nextInt(255)); return color; } @Override public Class<?> getObjectType() { return Color.class; } @Override public boolean isSingleton() { return false; } }
इसे xml में जोड़ें और पहले से घोषित प्रकार के बीन्स को हटा दें -
रंग ।
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <bean id="colorFactory" class="com.malahov.temp.ColorFactory"></bean> </beans>
अब
Color.class प्रकार की एक बीन बनाते हुए ColorFactory द्वारा प्रत्यायोजित किया जाएगा, जो कि प्रत्येक बार एक नई बीन बनाने के लिए
getObject विधि का उपयोग करेगा।
JavaConfig का उपयोग करने वालों के लिए, यह इंटरफ़ेस बिल्कुल बेकार होगा।
4. बीन इंस्टेंस बनाना
बीन्सफैक्टरी सेम के उदाहरण को बनाने के लिए
जिम्मेदार है , और यदि आवश्यक हो, तो यह कस्टम
FactoryBean को दर्शाता है । बीन उदाहरण पहले बनाए गए
बीनडिफिनिशन के आधार पर बनाए
जाते हैं ।

5. निर्मित फलियों की स्थापना
बीनपोस्टप्रोसेसर इंटरफ़ेस
आपको कंटेनर में आने से पहले अपनी फलियों को सेट करने की प्रक्रिया में
जागने की अनुमति देता है। इंटरफ़ेस कई तरीकों को वहन करता है।
public interface BeanPostProcessor { Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException; Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException; }
दोनों तरीकों को प्रत्येक बिन के लिए बुलाया जाता है। दोनों विधियों में बिल्कुल समान पैरामीटर हैं। एकमात्र अंतर वह क्रम है जिसमें उन्हें बुलाया जाता है। पहले को इनिट विधि से पहले कहा जाता है, उसके बाद दूसरा। यह समझना महत्वपूर्ण है कि इस स्तर पर सेम का उदाहरण पहले से ही बनाया गया है और इसे फिर से जोड़ा जा रहा है। दो महत्वपूर्ण बिंदु हैं:
- दोनों विधियों को अंततः बीन वापस करना चाहिए। यदि आप विधि में अशक्त लौटते हैं, तो जब आप संदर्भ से इस बिन को प्राप्त करते हैं, तो आप अशक्त हो जाएंगे, और चूंकि सभी डिब्बे बिनपोस्टप्रोसेसर के माध्यम से गुजरते हैं, संदर्भ को बढ़ाने के बाद, जब आप किसी भी बिन का अनुरोध करते हैं, तो आप शून्य के अर्थ में अंजीर प्राप्त करेंगे।
- यदि आप अपने ऑब्जेक्ट पर एक प्रॉक्सी बनाना चाहते हैं, तो ध्यान रखें कि यह init पद्धति को कॉल करने के बाद ऐसा करने के लिए प्रथागत है, दूसरे शब्दों में, आपको यह करने की आवश्यकता है postProcessAfterInitialization पद्धति में।
ट्यूनिंग प्रक्रिया को नीचे दिए गए आंकड़े में दिखाया गया है।
बीनपोस्टप्रोसेसर को किस क्रम में बुलाया जाएगा, यह ज्ञात नहीं है, लेकिन हम यह सुनिश्चित करते हैं कि उन्हें क्रमिक रूप से निष्पादित किया जाएगा।

यह समझने के लिए कि यह किस लिए है, आइए एक उदाहरण देखें।
एक नियम के रूप में, बड़ी परियोजनाओं को विकसित करते समय, एक टीम को कई समूहों में विभाजित किया जाता है। उदाहरण के लिए, डेवलपर्स का पहला समूह परियोजना के बुनियादी ढांचे को लिख रहा है, और दूसरे समूह को, पहले समूह की उपलब्धियों का उपयोग करते हुए, व्यापार तर्क कहा जाता है। मान लीजिए कि दूसरे समूह को एक कार्यात्मक की आवश्यकता है जो कुछ मानों को उनके डिब्बे में इंजेक्ट करने की अनुमति देगा, उदाहरण के लिए यादृच्छिक संख्या।
पहले चरण में, एक एनोटेशन बनाया जाएगा, जो उस वर्ग के क्षेत्रों को चिह्नित करेगा जिसमें मूल्य को इंजेक्ट करने की आवश्यकता है।
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.FIELD) public @interface InjectRandomInt { int min() default 0; int max() default 10; }
डिफ़ॉल्ट रूप से, यादृच्छिक संख्याओं की सीमा 0 से 10 तक होगी।
फिर, आपको इस एनोटेशन के लिए हैंडलर बनाने की आवश्यकता है, अर्थात्
InjectRandomInt एनोटेशन को संसाधित करने के लिए
बीनपोस्टप्रोसेसर कार्यान्वयन।
@Component public class InjectRandomIntBeanPostProcessor implements BeanPostProcessor { private static final Logger LOGGER = LoggerFactory.getLogger(InjectRandomIntBeanPostProcessor.class); @Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { LOGGER.info("postProcessBeforeInitialization::beanName = {}, beanClass = {}", beanName, bean.getClass().getSimpleName()); Field[] fields = bean.getClass().getDeclaredFields(); for (Field field : fields) { if (field.isAnnotationPresent(InjectRandomInt.class)) { field.setAccessible(true); InjectRandomInt annotation = field.getAnnotation(InjectRandomInt.class); ReflectionUtils.setField(field, bean, getRandomIntInRange(annotation.min(), annotation.max())); } } return bean; } @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { return bean; } private int getRandomIntInRange(int min, int max) { return min + (int)(Math.random() * ((max - min) + 1)); } }
इस
बीनपोस्टप्रोसेसर का कोड काफी पारदर्शी है, इसलिए हम इस पर ध्यान नहीं देंगे, लेकिन एक महत्वपूर्ण बिंदु है।
बीनपोस्टप्रोसेसर एक बीन होना चाहिए, इसलिए हम या तो
@Component एनोटेशन के साथ इसे चिह्नित करते हैं, या इसे नियमित कॉन्फ़िगरेशन के रूप में xml कॉन्फ़िगरेशन में पंजीकृत करते हैं।
डेवलपर्स के पहले समूह ने अपना कार्य पूरा किया। अब दूसरा समूह इन विकासों का उपयोग कर सकता है।
@Component @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) public class MyBean { @InjectRandomInt private int value1; @InjectRandomInt(min = 100, max = 200) private int value2; private int value3; @Override public String toString() { return "MyBean{" + "value1=" + value1 + ", value2=" + value2 + ", value3=" + value3 + '}'; } }
नतीजतन, संदर्भ से प्राप्त प्रकार
MyBean के सभी डिब्बे पहले से ही आरंभिक फ़ील्ड मान 1 और मान 2 के साथ बनाए जाएंगे। यह भी ध्यान देने योग्य है कि जिस चरण में इन क्षेत्रों में मूल्यों का इंजेक्शन है, वह इस बात पर निर्भर करेगा कि आपके बिन में किस तरह का
स्कोप है।
SCOPE_SINGLETON - आरंभ एक बार संदर्भ बढ़ाने के चरण में होगा।
SCOPE_PROTOTYPE - अनुरोध पर हर बार आरंभीकरण किया जाएगा। और दूसरे मामले में, आपका बीन सभी बीनपोस्टप्रोसेसर के माध्यम से जाएगा, जो प्रदर्शन को काफी प्रभावित कर सकता है।
पूर्ण कार्यक्रम कोड
यहां पाया जा सकता
है ।
मैं
एवगेनीबोरिसोव के लिए विशेष धन्यवाद कहना चाहता
हूं । उनके
पाठ्यक्रम के लिए धन्यवाद, मैंने इस पोस्ट को लिखने का फैसला किया।
मैं आपको JPoint 2014 से उनकी
रिपोर्ट देखने की भी सलाह देता हूं।