अभिवादन हरजितेली!
इस पोस्ट में, हम भू-स्थानिक अनुक्रमण के बारे में बात करेंगे, जैसे कि
R * -tree के रूप में एक डेटा संरचना और मैंने अपना पहला प्रोजेक्ट कैसे लागू किया।
तो चलिए शुरू करते हैं। स्नातक होने के तुरंत बाद, मुझे शिक्षकों के कार्यालय से एक प्रस्ताव मिला, जो कारों के लिए जीपीएस-निगरानी सेवाएं प्रदान करता है, जिसे मैंने स्वीकार किया। यहाँ यह है! अंत में, असली दिलचस्प परियोजनाएं! मेरा आनंद और उत्साह कोई सीमा नहीं जानता था। पहला काम जो मुझे दिया गया था, उसमें निम्नलिखित शब्द थे:
एक डेस्कटॉप एप्लिकेशन है, जिसमें माइलेज पर किसी भी रिपोर्ट, कारों के खर्च किए गए ईंधन इत्यादि के अलावा, वेक्टर नक्शे प्रदर्शित किए जाते हैं, जो वास्तविक समय में इन कारों की स्थिति के साथ, कार आंदोलनों के इतिहास और अन्य प्रकार के अन्य सामानों को ट्रैक करते हैं। अब यह सब गलत और अक्षम रूप से काम कर रहा है। कोई नहीं जानता कि इसे सही तरीके से कैसे लागू किया जाए। फिर से लिखने की जरूरत है
...
मेरे हाथ में 160,000 लाइनों के लिए आवेदन का स्रोत कोड दिया गया था और वह यह है। कोई दस्तावेज नहीं, कुछ भी नहीं। जानकारी का एकमात्र स्रोत ये बहुत ही शिक्षक और योजना के स्रोत कोड में दुर्लभ टिप्पणियां "मैंने वास के अनुरोध पर n * x हटा दिया"। यह परियोजना 10 साल से अधिक पुरानी है, कार्यालय ग्राहकों के अनुरोधों को जल्द से जल्द पूरा करने के लिए बहुत ही वफादार और लचीला है। सभी तरह की इच्छाएं और सीटी लगभग अपने घुटनों पर पूरी कर ली हैं जो कि दस्तावेज नहीं थे। राक्षसी लापरवाही! लेकिन ऐसी परियोजनाएं किसी और के कोड को पार्स करने में कौशल को पंप करने में मदद करती हैं।
खैर, कार्य निर्धारित किया गया था, काम के लिए सामग्री थी। कोड के माध्यम से अफवाह फैलाना, सवाल पूछना, मैंने उस समय अपने आप को मामलों की वर्तमान स्थिति के लिए थोड़ा स्पष्ट किया:
- मानचित्र इन बिंदुओं के लिंक के साथ बिंदुओं और वस्तुओं की एक सरणी हैं
- स्क्रीन क्षेत्र को हिट करने वाली वस्तुओं को संपूर्ण खोज द्वारा निर्धारित किया जाता है।
- स्क्रीन पर ऑब्जेक्ट के आकार की गणना करके "मक्खी पर" ऑब्जेक्ट निर्धारित किया गया था या नहीं (यह 1-पिक्सेल घर प्रदर्शित करने पर सिस्टम संसाधनों को खर्च करने का कोई मतलब नहीं है)
छोटे आकार के नक्शे (शहर, जिला) का चित्रण सहनीय था। जब लोड हो रहा हो, तो क्षेत्र के देश के नक्शे को लोड करना, जिसमें सैकड़ों वेक्टर वस्तुएं हों, जिसमें कुल लाखों बिंदु हों, आप कल्पना कर सकते हैं। Googling और विषय पर बहुत सारी सामग्री पढ़ना, मैंने अपने आप के लिए 2 विकल्पों की पहचान की कि कैसे "इसे सही करें" सब कुछ:
- मानचित्र के पूरे क्षेत्र को एक निश्चित आकार के वर्गों में तोड़ें, जोड़ों पर गिरने वाली वस्तुओं को विभाजित करें, प्रत्येक ऑब्जेक्ट को एक वर्ग सूचकांक असाइन करें, डेटा को सॉर्ट करें और चलते-फिरते आवश्यक वस्तुओं की गणना करें;
- आर-ट्री का उपयोग करें।
थोड़ा सोचने के बाद, मैंने पहला विकल्प वापस फेंक दिया क्योंकि स्केल के स्तरों की एक निश्चित संख्या में संलग्न होना और प्रत्येक के लिए एक ग्रिड का निर्माण करना आवश्यक होगा। दूसरे विकल्प ने असीमित स्केलिंग का लाभ दिया, और सामान्य रूप से अधिक सार्वभौमिक लग रहा था। पहिया को सुदृढ़ नहीं करने के लिए, मैंने डेल्फी के तहत मौजूदा पुस्तकालयों की खोज करने का फैसला किया, क्योंकि इस पर प्रोजेक्ट लिखा गया था। पुस्तकालयों को कभी नहीं मिला और मैंने खुद को अनुक्रमित करने का निर्णय लिया।
आर-ट्री क्या है? इस संरचना को स्थानिक डेटा अनुक्रमण के लिए एंटोनिन गुटमैन द्वारा प्रस्तावित किया गया था, यह एक संतुलित पेड़ है और अनुभवजन्य टिप्पणियों के आधार पर विकसित किया गया था। एक पेड़ कई नेस्टेड आयतों में जगह तोड़ देता है। प्रत्येक ट्री नोड में न्यूनतम (न्यूनतम) और अधिकतम (अधिकतम) ऑब्जेक्ट्स की संख्या होती है। ट्री बिल्डिंग एल्गोरिदम के सही संचालन के लिए, यह आवश्यक है कि
2 <=
minCount <=
maxCount / 2 । प्रत्येक ऑब्जेक्ट की अपनी बाउंडिंग आयत है -
MBR (न्यूनतम बाउंडिंग आयत)। एक एमबीआर नोड एक आयत है जो बच्चे के नोड्स के ऑब्जेक्ट के आयतों का वर्णन करता है।
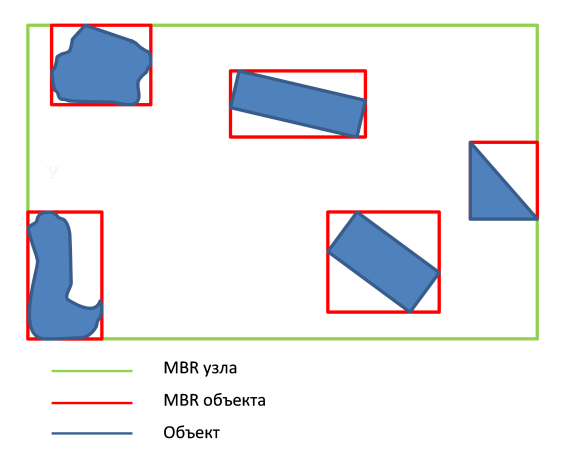
एक पेड़ वैकल्पिक रूप से वस्तुओं को सम्मिलित करके बनाया गया है। जब नोड ओवरफ्लो होता है, तो इसे विभाजित किया जाता है, यदि आवश्यक हो, तो सभी मूल नोड्स के विभाजन के बाद। किसी दिए गए डेटा संरचना के लिए खोज प्रश्नों की प्रभावशीलता कई मानदंडों पर निर्भर करती है:
- एमबीआर नोड्स के क्षेत्र को कम करना (वस्तुओं के बीच रिक्त स्थान को कम करना);
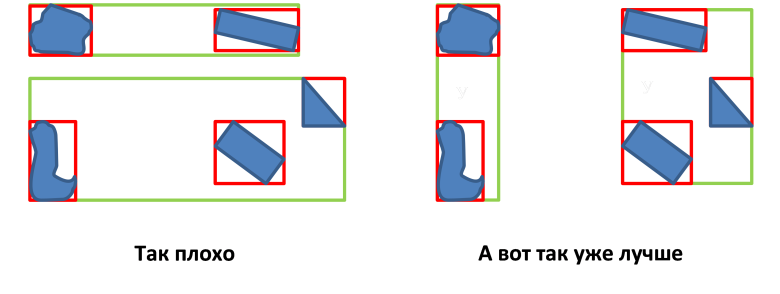
- एमबीआर नोड्स के अतिव्यापी क्षेत्रों के क्षेत्र का न्यूनतमकरण;
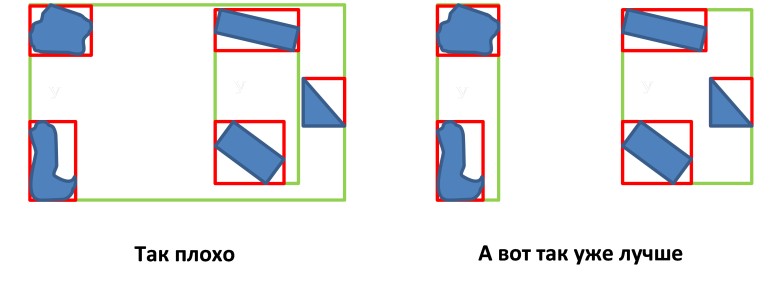
- एमबीआर नोड की परिधि को न्यूनतम करना;
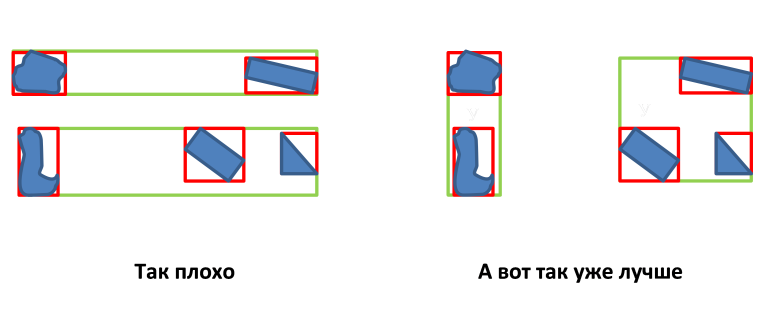
विभिन्न प्रकार के आर-पेड़ हैं, केवल भीड़ नोड के अंतिम और विभाजन की पसंद में भिन्नता है।
मैंने R * -tree क्यों चुना? मेरे व्यक्तिपरक मूल्यांकन में एंटोनिन गुटमैन (आर-ट्रीज़) द्वारा प्रस्तावित शास्त्रीय दृष्टिकोण, वास्तविक परियोजनाओं में उपयोग के लिए पूरी तरह से अनुपयुक्त है। एक उदाहरण के रूप में, मैं
विकिपीडिया , अर्थात् आर-ट्री, जर्मन डाकघरों के लिए निर्मित सामग्री का हवाला दूंगा:
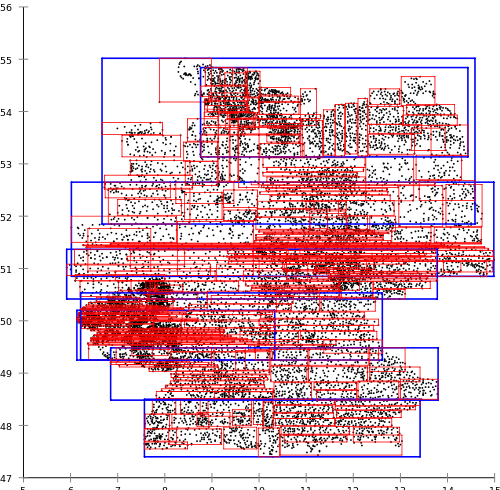
जब एक ही समय में, नोरबर्ट बेकमैन, हंस-पीटर क्रिगेल, राल्फ श्नाइडर और बर्नहार्ड सीजर द्वारा प्रस्तावित आर * ट्री एल्गोरिदम निम्नलिखित परिणाम देते हैं:
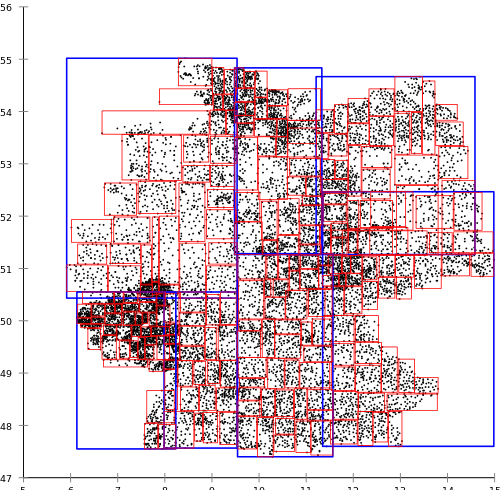
आर * -ट्री बनाने के लिए अधिक संसाधन-गहन है, लेकिन सामान्य आर-ट्री की तुलना में खोज प्रश्नों के लिए बेहतर परिणाम देता है।
इस बात पर विचार करें कि सम्मिलन कैसे होता है: इसमें एक शाखा (सबट्री) / नोड का चयन करने के लिए एल्गोरिदम और एक नोड को पूरा करने के लिए एक एल्गोरिथ्म शामिल है, जब यह भरा हुआ है।
सबट्री चयन एल्गोरिथम (चयन करें)
1. N को रूट नोड के रूप में सेट करें
2. यदि एन एंड नोड है, तो एन वापस करें
3.Inache
4. यदि N का बच्चा नोड्स अंतिम नोड्स (पत्तियां) हैं,
5. एक बच्चे के नोड एन का चयन करें जिसके एमबीआर को सम्मिलन पर ओवरलैप में सबसे छोटी वृद्धि की आवश्यकता होती है
नोड के लिए वस्तु
6. यदि ओवरलैप में सबसे छोटी वृद्धि के साथ कई नोड हैं, तो उनमें से एक का चयन करें
जिसे क्षेत्र में सबसे छोटी वृद्धि की आवश्यकता होती है
7. यदि क्षेत्र में सबसे छोटी वृद्धि के साथ कई नोड हैं, तो उनमें से एक नोड का चयन करें
सबसे छोटे क्षेत्र के साथ
8. नहीं तो
9. एक बच्चे के नोड एन का चयन करें जिसके एमबीआर को क्षेत्र में सबसे छोटी वृद्धि की आवश्यकता होती है
10. यदि क्षेत्र में सबसे छोटी वृद्धि के साथ कई नोड हैं, तो सबसे छोटे क्षेत्र के साथ नोड का चयन करें
11. चयनित नोड पर एन सेट करें।
12. चरण 2 से पीछे हटें।
नोड विभाजन एल्गोरिथ्म (स्प्लिटनोड)
विभाजन विकल्प खोजने के लिए, आर * - ट्री निम्नलिखित विधि का उपयोग करता है: नोड्स को बाईं और दाईं सीमाओं के साथ प्रत्येक समन्वय अक्षों के साथ क्रमबद्ध किया जाता है। प्रत्येक सॉर्ट किए गए संस्करण के लिए, नोड्स को 2 समूहों में विभाजित किया जाता है ताकि
k =
[1 ... (maxCount - 2 * minCount + 2)] , पहले समूह में शामिल हैं
(minCount - 1) + k नोड्स दूसरे में शेष हैं। इस तरह के प्रत्येक वितरण के लिए, निम्नलिखित संकेतकों की गणना की जाती है:
- क्षेत्र: क्षेत्र = क्षेत्र (पहले समूह का एमबीआर) + क्षेत्र (दूसरे समूह का एमबीआर)
- परिधि: मार्जिन = मार्जिन (पहले समूह का एमबीआर) + मार्जिन (दूसरे समूह का एमबीआर)
- ओवरलैप: ओवरलैप = क्षेत्र (पहले समूह का एमबीआर (दूसरे समूह का एमबीआर))
सबसे अच्छा वितरण निम्नलिखित एल्गोरिदम द्वारा निर्धारित किया जाता है:
1. कॉल का चयन करेंSSSSititx अक्ष का निर्धारण करने के लिए जिसके साथ वितरण होगा।
2. चयनित अक्ष पर सर्वोत्तम वितरण निर्धारित करने के लिए selectSplitIndex पर कॉल करें
3. वस्तुओं को 2 नोड्स पर असाइन करें
chooseSplitAxis
1. प्रत्येक अक्ष के लिए
2. बाईं ओर नोड्स को क्रमबद्ध करें, और फिर उनके एमबीआर की दाईं सीमाओं द्वारा।
उपरोक्त वर्णित नोड्स को वितरित करें, एस की गणना करें - प्रत्येक वितरण के सभी परिधि का योग।
3. न्यूनतम एस के साथ एक अक्ष चुनें।
chooseSplitIndex
1. चयनित अक्ष के साथ, न्यूनतम ओवरलैप पैरामीटर के साथ एक वितरण का चयन करें
2. यदि न्यूनतम ओवरलैप पैरामीटर के साथ कई वितरण हैं, तो वितरण का चयन करें
सबसे छोटे क्षेत्र के साथ।
वास्तव में खुद सम्मिलित करें (सम्मिलित करें)
1. कॉल selectSubStree, एन नोड निर्धारित करने के लिए एक तर्क के रूप में रूट नोड से गुजर रहा है,
जिसमें वस्तु E का सम्मिलन होगा
2. यदि N में वस्तुओं की संख्या अधिकतम से कम है,
3. E को N में डालें
4. N और उसके सभी मूल नोड्स के लिए MBR अपडेट करें
5. अन्यथा, एन और ई के लिए स्प्लिटनोड को कॉल करें।
अपने
लेख में R * ट्री के लेखकों का तर्क है कि इस संरचना का सबसे अच्छा प्रदर्शन
minCount =
maxCount *
40% के साथ हासिल किया गया है।
वह सब है। हमारा पेड़ बनाया गया है, और अब किसी दिए गए क्षेत्र में सही वस्तुओं को ढूंढना मुश्किल नहीं है:
किसी दिए गए क्षेत्र में वस्तुओं को खोजने के लिए एल्गोरिदम (FindObjectsInArea)
1. यदि वर्तमान नोड N परिमित है,
2. नोड एन में प्रत्येक बच्चे ऑब्जेक्ट ई के लिए, निर्धारित करें
3. यदि E खोज क्षेत्र को काटता है, तो E को खोज परिणाम R में जोड़ें।
4. नहीं तो
5. नोड एन में प्रत्येक बच्चे के नोड एन के लिए, निर्धारित करें
6. यदि n खोज क्षेत्र को काटता है, तो n के लिए findObjectsInArea पर कॉल करें
इसके बाद, हम बस
findObjectsInArea कॉल
findObjectsInArea , इसे रूट नोड और खोज क्षेत्र पास करते हैं।
बुनियादी एल्गोरिदम के संचालन को अधिक स्पष्ट रूप से प्रदर्शित करने के लिए, आइए कोड को देखें:
कार्यान्वयन के बाद, जो कुछ करना बाकी था, वह वेक्टर मैप ऑब्जेक्ट्स को परतों में विभाजित करना था, इन परतों को अधिकतम पैमाने पर सेट करें जिस पर वे प्रदर्शित होंगे और प्रत्येक परत के लिए R * -tree का निर्माण करेंगे।परिणाम वीडियो पर देखे जा सकते हैं: