नमस्ते, मेरा नाम नताल्या है, मैं तथ्य निष्कर्षण समूह में एक डेवलपर के रूप में यांडेक्स में काम करता हूं। वसंत में, हमने इस बारे में बात की कि टॉमेटा पार्सर क्या है और इसका इस्तेमाल यैंडेक्स में क्या किया जाता है। और पहले से ही यह गिरावट पार्सर के स्रोत कोड को सार्वजनिक डोमेन में पोस्ट किया जाएगा।
पिछली पोस्ट में, हमने पार्सर और इसकी आंतरिक भाषा के सिंटैक्स का उपयोग करने के तरीके के बारे में बात करने का वादा किया था। यह मेरी आज की कहानी है।

इस पोस्ट को पढ़ने के बाद, आप सीखेंगे कि कैसे टॉमिटा के लिए शब्दकोशों और व्याकरणों को संकलित किया गया है, साथ ही साथ प्राकृतिक भाषा में ग्रंथों से तथ्यों को उनकी मदद से कैसे निकाला जाए। एक ही जानकारी एक छोटे वीडियो कोर्स के प्रारूप में उपलब्ध है।
व्याकरण नियमों का एक समूह है जो एक पाठ में शब्दों की एक स्ट्रिंग का वर्णन करता है। उदाहरण के लिए, यदि हमारे पास "मुझे पसंद है कि आप मेरे साथ बीमार नहीं हैं", तो यह निम्नलिखित श्रृंखला [पहला सर्वनाम, एकवचन], [वर्तमान काल और तीसरे व्यक्ति], [अल्पविराम], [संघ] का उपयोग करके वर्णित किया जा सकता है। आदि
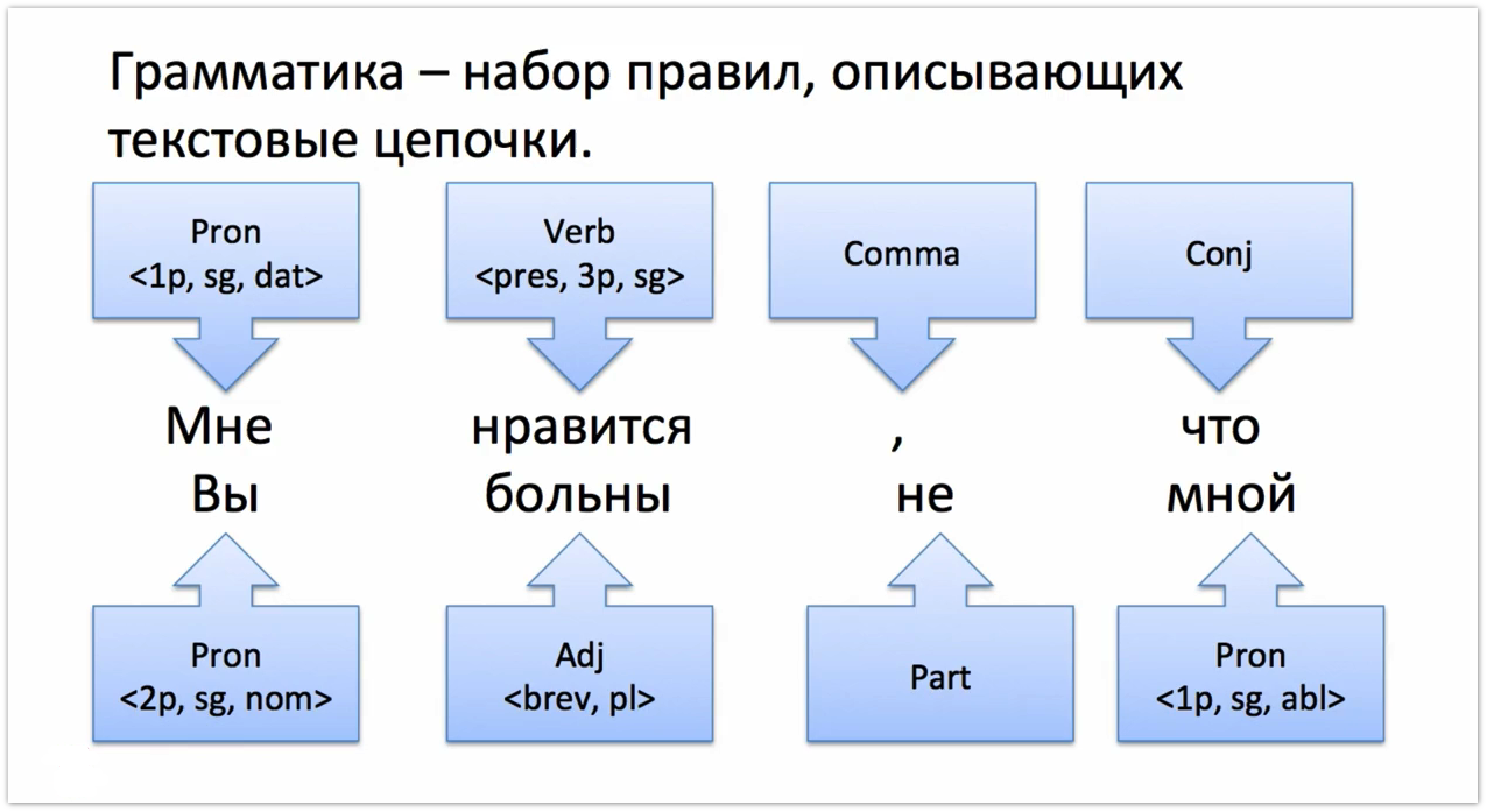
व्याकरण एक विशेष औपचारिक भाषा में लिखा जाता है। संरचनात्मक रूप से, नियम को प्रतीक द्वारा विभाजित किया गया है -> बाएं और दाएं भागों में। बाईं ओर एक गैर-थर्मल है, और दाएं में टर्मिनलों और गैर-टर्मिनलों दोनों शामिल हैं। इस संदर्भ में एक टर्मिनल एक वस्तु है जिसका एक विशिष्ट, अपरिवर्तनीय मूल्य है। कई टर्मिनल टॉमिता भाषा की वर्णमाला हैं, जहाँ से अन्य सभी शब्दों का निर्माण किया जाता है। टोमाइट में शब्द 'लेम्मास' हैं - एकल उद्धरणों में लिखे गए प्रारंभिक शब्द, ( Noun, Verb, Adj ...), विराम चिह्न ( Comma, Punct, Hyphen ...) और कुछ अन्य विशेष वर्ण ( Percent, Dollar ...) के कुछ भाग। टोमाइट में लगभग बीस टर्मिनल हैं, उनकी पूरी सूची हमारे प्रलेखन में प्रस्तुत की गई है। गैर-टर्मिनलों को टर्मिनलों से बना दिया जाता है, और अगर हम प्राकृतिक भाषाओं के साथ एक सादृश्य बनाते हैं, तो वे कुछ इस तरह के शब्द हैं। उदाहरण के लिए, नॉनटर्मिनल नूनप्रेज़, दो टर्मिनलों Adj और Noun मिलकर, दो शब्दों की एक श्रृंखला का अर्थ है: पहले एक विशेषण, फिर एक संज्ञा।
हमारे पहले व्याकरण की रचना करने के लिए, आपको एक्सटेंशन .cxx के साथ एक फ़ाइल बनाने की आवश्यकता है, इसे पहले_ग्राम करें। आप इसे उसी स्थान पर सहेज सकते हैं जहां पार्सर बाइनरी स्वयं निहित है। व्याकरण फ़ाइल की पहली पंक्ति एन्कोडिंग निर्दिष्ट करना चाहिए:
#encoding "utf8"
फिर आप नियम लिख सकते हैं। हमारे पहले व्याकरण में उनमें से दो होंगे:
PP -> Prep Noun; S -> Verb PP;
पहला नियम नॉनटर्मिनल PP वर्णन करता है - एक प्रीपोजल समूह जिसमें एक प्रीपोजिशन और एक संज्ञा ( Prep Noun ) होता है। दूसरा नियम एक क्रिया है जिसमें एक पूर्वपद समूह ( Verb PP ) होता है। इस मामले में, nonterminal S जड़ है क्योंकि यह नियम के दाईं ओर कभी उल्लेख नहीं किया गया है। इस गैर-टर्मिनल को पेड़ का शीर्ष कहा जाता है। यह पूरी श्रृंखला का वर्णन करता है जिसे हम पाठ से निकालना चाहते हैं।
हमारा पहला व्याकरण तैयार है, लेकिन पार्सर शुरू करने से पहले आपको कुछ और जोड़-तोड़ करने की जरूरत है। तथ्य यह है कि व्याकरण सीधे पार्सर के साथ बातचीत नहीं करता है, लेकिन रूट शब्दकोश के माध्यम से - वह इकाई जिसमें सभी निर्मित व्याकरण, शब्दकोश, अतिरिक्त फाइलें, आदि के बारे में जानकारी एकत्र की जाती है। यानी रूट डिक्शनरी एक प्रकार का एग्रीगेटर है जो प्रोजेक्ट के भीतर बनाया गया है। टॉमिट पार्सर के लिए डिक्लेयर Google प्रोटोबॉफ़ के समान सिंटैक्स का उपयोग करते हुए लिखे गए हैं (इनहेरिटेंस के समर्थन के साथ, प्रोटोबॉफ़ कंपाइलर के संशोधित संस्करण का उपयोग करके)। फ़ाइलों को आमतौर पर एक्सटेंशन .gzt दिया जाता है। रूट डिक्शनरी बनाएं dic.gzt और शुरुआत में एन्कोडिंग को भी इंगित करें:
encoding "utf8";
उसके बाद, हम मूल शब्दकोश फ़ाइलों में आयात करते हैं जिसमें शब्दकोशों और व्याकरणों में उपयोग किए जाने वाले मूल प्रकार होते हैं। सुविधा के लिए, इन फ़ाइलों को पार्सर बाइनरी में सीवन किया जाता है, और हम उन्हें पथ निर्दिष्ट किए बिना सीधे आयात कर सकते हैं:
import "base.proto"; import "article_base.proto";
आगे हम एक लेख बनाते हैं। एक शब्दकोश लेख बताता है कि किसी पाठ में शब्दों की एक स्ट्रिंग को कैसे उजागर किया जाए। व्याकरण संभव तरीकों में से एक है। आप पार्सर एल्गोरिथ्म (नाम और तिथियों की श्रृंखला) में निर्मित कीवर्ड की सूची का उपयोग करके एक श्रृंखला का चयन कर सकते हैं। अन्य तरीकों को पार्सर स्रोत कोड (उदाहरण के लिए, सांख्यिकीय नाम पहचानकर्ता) के स्तर पर जोड़ा जा सकता है। लेख में प्रकार, शीर्षक और सामग्री शामिल हैं। किस प्रकार के लेख हैं और उनकी आवश्यकता क्यों है, मैं नीचे बताऊंगा जब हम शब्दकोशों के बारे में अधिक बात करेंगे। अभी के लिए, हम बेस टाइप TAuxDicArticle उपयोग करेंगे। लेख का शीर्षक अद्वितीय होना चाहिए, यह प्रकार के बाद उद्धरण चिह्नों में इंगित किया गया है। फिर, ब्रेसिज़ में, चाबियाँ सूचीबद्ध हैं - लेख की सामग्री। हमारे मामले में, एक एकल कुंजी में हमारे द्वारा लिखे गए व्याकरण की एक कड़ी होती है। सबसे पहले, हम उस फ़ाइल के सिंटैक्स को इंगित करते हैं जिसे हम संदर्भित करते हैं (एक व्याकरण फ़ाइल के मामले में, यह हमेशा tomita ), और इस फ़ाइल का पथ, फिर type फ़ील्ड में - कुंजी का प्रकार (यह निर्दिष्ट किया जाना चाहिए कि कुंजी में व्याकरण का लिंक है)।
TAuxDicArticle "_" { key = {"tomita:first_grammar.cxx" type=CUSTOM} }
पार्सर को यह बताने के लिए कि हमें स्रोत पाठ कहां से प्राप्त होता है, जहां हम परिणाम लिखते हैं, हम कौन से व्याकरण लॉन्च करते हैं, हम कौन से तथ्य निकालते हैं, साथ ही अन्य आवश्यक जानकारी, एक्सटेंशन के साथ एक एकल कॉन्फ़िगरेशन फ़ाइल बनाई जाती है। पार्सर फ़ोल्डर में config.proto फ़ाइल बनाएँ। हमेशा की तरह, शुरुआत में हम एन्कोडिंग को इंगित करते हैं और हमारे कॉन्फ़िगरेशन के विवरण के लिए आगे बढ़ते हैं।
कॉन्फ़िगरेशन फ़ाइल का एकमात्र आवश्यक पैरामीटर रूट डिक्शनरी का मार्ग है, जो शब्दकोश फ़ील्ड में लिखा गया है। अन्य सभी पैरामीटर वैकल्पिक हैं। इनपुट फ़ाइल के बारे में जानकारी Input फ़ील्ड में है। टेक्स्ट फ़ाइलों के अलावा, टोमाइट को इनपुट फ़ोल्डर, आर्काइव या स्टडिन में जमा किया जा सकता है। Output फ़ील्ड रिकॉर्ड करता है कि कहाँ और किस प्रारूप में (पाठ, xml या प्रोटोबॉफ़) निकाले गए तथ्यों को सहेजा जाना चाहिए। हम input.txt फाइल को इनपुट पर भेज देंगे। Articles उन व्याकरणों को सूचीबद्ध करता है जिन्हें हम चलाना चाहते हैं। कृपया ध्यान दें कि यहां हम फ़ाइल को व्याकरण के साथ नहीं, बल्कि उस शब्दकोश के लेख का नाम बताते हैं, जिसमें इस फ़ाइल का लिंक है: जैसा कि हमने पहले ही कहा था, पार्सर अप्रत्यक्ष रूप से रूट शब्दकोश के माध्यम से सभी प्रोजेक्ट फ़ाइलों के साथ इंटरैक्ट करता है।
encoding "utf8"; TTextMinerConfig { Dictionary = "dic.gzt"; Input = {File = "input.txt"} Output = {File = "output.txt" Format = text} Articles = [ { Name = "_" } ] }
अब जब कॉन्फ़िगरेशन फ़ाइल तैयार हो गई है, तो हमें केवल विश्लेषण के लिए पाठ (बाइनरी के बगल में) के साथ एक फ़ाइल डालनी होगी (आप हमारी परीक्षण फ़ाइल का उपयोग कर सकते हैं या अपनी खुद की ले सकते हैं) और आप व्याकरण लॉन्च करने के लिए आगे बढ़ सकते हैं। टर्मिनल में, हम उस फ़ोल्डर में जाते हैं जहाँ हमारा पार्सर निहित है। पार्सर को एक एकल तर्क के साथ लॉन्च किया गया है - कॉन्फ़िगरेशन फ़ाइल का नाम। तदनुसार, * NIX सिस्टम में, शुरू करने का कमांड इस तरह दिखेगा:
./tomitaparser config.proto
परिणाम output.txt फ़ाइल में मिल सकते हैं। हालाँकि, हम वहां कोई भी निकाले गए तथ्य नहीं देखेंगे, क्योंकि अभी तक हमारे व्याकरण में केवल श्रृंखलाओं के चयन के नियम हैं, और चयनित श्रृंखलाओं के लिए संरचित तथ्यों में बदलने के लिए, हमें एक व्याख्या प्रक्रिया जोड़ने की आवश्यकता है। हम इसके बारे में थोड़ी कम बात करेंगे। हालाँकि, हम पहले से ही इस स्तर पर चयनित श्रृंखला देख सकते हैं, इसके लिए हमें कॉन्फ़िगरेशन फ़ाइल में एक और पैरामीटर जोड़ने की आवश्यकता है - डिबग आउटपुट:
PrettyOutput = "pretty.html"
इस पैरामीटर के लिए धन्यवाद, पार्सर के परिणामों को अधिक दृश्य प्रतिनिधित्व के साथ HTML-फ़ाइल में लिखा जाएगा। अब, यदि हम व्याकरण को पुनः आरंभ करते हैं और फोल्डर में दिखाई देने वाली pretty.html फ़ाइल को खोलते हैं, तो हम देखेंगे कि हमने व्याकरण में हमारे द्वारा वर्णित सभी श्रृंखलाओं को पुनः प्राप्त कर लिया है - क्रिया जिसके बाद संज्ञा पूर्वसर्ग के साथ आती है:
परिणाम| दूत की सवारी |
| दुआ के पास रहना |
| रात भर के लिए रुकें |
| उसके पास जाओ |
| Stavropol पर जाएं |
| साथ चलो |
| वोदका ले लो |
| लाइन पर आओ |
| हाइलैंडर्स के खिलाफ रखा |
| तीसरे में रेककन |
| दिन का पालन करें |
| दक्षिण में होना |
| ऊपर जाना |
| घाटी में वापस देखो |
| मांग वोदका |
| मुख्यालय के कप्तान को देखो |
| एक गाय पर ठोकर |
| आग से आश्रय |
| चेचन्या में होना |
| शाफ्ट पर ले जाएँ |
| एक सूटकेस से बाहर खींचो |
| अफसोस |
| सामने से पहले निकल जाओ |
| पर मुकदमा चलाया |
| दूर रहो |
| किले में खड़े हो जाओ |
| एक किले में बसना |
| एक सूअर पर जाने के लिए |
| हंसो |
| इसमें होना है |
| पैसे के लिए हो |
| ताली बजाते हैं |
| इसे देखो |
| मालिक के पीछे दौड़ो |
| सकला बनो |
| बाहर हवा में जाओ |
| पहाड़ों पर जाओ |
| बाड़ के साथ उतारा |
| तेरे पीछे हो |
| abreks के साथ सवारी |
| स्टंप पर कूदो |
| वेकेशन में दौड़ें |
| मोर्चे पर लटकाओ |
| एक खड्ड में उड़ना |
| मार डालना |
| स्टेपनी तक पहुँचें |
| किनारे से दौड़ो |
| खुरों से उड़ना |
| अंधेरे में चमकना |
| चेन मेल करने के लिए चिपटना |
| जंगल की बाड़ को मारो |
| स्थिर हो जाना |
| एक बंदूक ले लो |
| भीड़ के बीच कताई |
| एक अजनबी में होना |
| कुछ और बात करो |
| प्यार से आओ |
| औल में कूदो |
| गढ़ छोड़ दो |
| चेहरा बदलो |
| एक बंदूक पर कूदो |
| एक उत्साही पर सवारी |
| मामले से पकड़ो |
| जमीन पर गिरना |
| किले में आना |
| उस पर सरपट दौड़ना |
| औल जाना |
| उसके पास जाओ |
| एक मृत अंत में हो |
| एक मृत अंत में हो |
| कोने में बैठो |
| कैद में डूबना |
| खिड़की से बाहर देखो |
| एक सोफे पर बैठो |
| उसके पास जाओ |
| हाथ मिलाओ |
| दरार करने में सक्षम हो |
| एक सपने में सपना |
| सड़क से प्रतीक्षा करें |
| शाम को होना |
| झाड़ी से गोता लगाना |
| पहाड़ी से देखें |
| बर्फ में कंपकंपी |
| झोपड़ी से बाहर निकलो |
| के रूप में बाहर जाओ |
| बंद करना |
| अपनी ताकत खो दो |
| स्वर्ग के लिए नेतृत्व |
| बादल में गायब हो जाना |
| शीर्ष पर आराम करो |
| क्रंच अंडरफुट |
| सर में घुस जाना |
| दिल से दूर हो जाना |
| हुड पहाड़ चढ़ो |
| विकिरण से दूर हो जाओ |
| हुड पहाड़ों नीचे जाओ |
| शब्द से आते हैं |
| अपने पैरों के नीचे गिरो |
| बर्फ में बदलो |
| कोहरे में छिप जाना |
| सलाखों पर हराया |
| मौसम में बंद करो |
| वोदका देना |
| गाल पर जंगली चलाते हैं |
| मृत्यु की घोषणा करो |
| जंगली सूअर के लिए धोने के लिए |
| एक सेर से शादी करो |
| कमरे के चारों ओर चलो |
| बिस्तर पर बैठो |
| पहाड़ों पर खींचें |
| बिस्तर पर गिरो |
| सितंबर में हो |
| सर्फ़ के आसपास चलो |
| टर्फ ले लो |
| शाफ़्ट बंद हो |
| कोने पर बैठो |
| स्थिर रहो |
| रकाब पर खड़े हो जाओ |
| शिकार से लौट आओ |
| नदी से बाहर हो |
| शर्त |
| इसमें बदलाव करें |
| शिकार करना |
| देशी के लिए तरस रही |
| में डाल दिया |
| हिरासत से बाहर निकलो |
| अमेरिका जाना |
| सड़क पर मरो |
| राजधानी का दौरा करें |
| पीने से आता है |
| मुखर होना |
| नरकट के चारों ओर सूँघना |
| नरकट में जाना |
| ढेर |
| क्षेत्र में इंगित करें |
| काठी से बाहर चीर |
| Pechorin के साथ पकड़ |
| झपकी लेना |
| अपने घुटनों पर गिरो |
| हाथ पर रखना |
| एक चट्टान पर चढ़ना |
| घोड़ों से उतरना |
| एक घाव से बाहर डालना |
| स्मृति के बिना हो |
| उसे संयंत्र |
| डॉक्टर के लिए भेजें |
| किले से बाहर निकलो |
| एक पत्थर पर बैठो |
| झाड़ियों में खींचें |
| एक घोड़े पर कूदो |
| बिस्तर से बैठो |
| दीवार की ओर मुड़ें |
| पहाड़ों को चाहते हैं |
| आत्मा से मिलो |
| जन्नत में होगा |
| एक विचार के साथ आओ |
| उसी में मरो |
| घुटने टेक दो |
| सर्फ़ के पास जाओ |
| दु: ख के साथ मरो |
| जमीन पर बैठो |
| त्वचा के माध्यम से चलाएं |
| किले के पीछे दफनाना |
| जॉर्जिया जाओ |
| रूस वापस लौटें |
| मैक्सिम के साथ हिस्सा |
पार्सर प्रारंभिक रूप में श्रृंखला के मुख्य शब्द (डिफ़ॉल्ट रूप से पहले) को परिवर्तित करके निकाले गए जंजीरों को सामान्य करने का प्रयास करता है।
अगला चरण एक व्याख्या प्रक्रिया की शुरूआत है, अर्थात्। निकाले गए चेन को तथ्यों में बदलना।
पहले हमें उस तथ्य की संरचना बनाने की आवश्यकता है जिसे हम निकालना चाहते हैं, अर्थात्। वर्णन करें कि इसमें कौन से क्षेत्र शामिल हैं। ऐसा करने के लिए, एक नया fact_types.proto फ़ाइल बनाएं। फिर, हम मूल प्रकारों के साथ फ़ाइलों को आयात करेंगे, और फिर स्वयं तथ्य के विवरण के लिए आगे बढ़ेंगे। शब्द संदेश के बाद तथ्य का नाम, एक बृहदान्त्र और मूल प्रकार का तथ्य लिखा जाता है, जिससे हमारे तथ्य का प्रकार विरासत में मिलता है। अगला, घुंघराले कोष्ठक में, हम अपने तथ्य के क्षेत्रों को सूचीबद्ध करते हैं। हमारे मामले में, फ़ील्ड एक है, यह आवश्यक है (आवश्यक), टेक्स्ट (स्ट्रिंग), जिसे फ़ील्ड 1 कहा जाता है और हम इसे पहचानकर्ता 1 प्रदान करते हैं।
import "base.proto"; import "facttypes_base.proto"; message Fact: NFactType.TFact { required string Field1 = 1; }
अब हमें उस फ़ाइल को रूट डिक्शनरी (dic.gzt) में आयात करने की आवश्यकता है:
import "fact_types.proto";
चलो व्याकरण पर चलते हैं, जिसमें व्याख्या प्रक्रिया होती है। मान लीजिए कि हम पाठ से एक तथ्य निकालना चाहते हैं: क्रिया जो एक पूर्वसर्ग के साथ संज्ञा को नियंत्रित करती है। ऐसा करने के लिए, नियम में, क्रिया मार्कर के बाद, हम interp लिखते हैं, और फिर कोष्ठक में तथ्य का नाम और डॉट के माध्यम से उस क्षेत्र का नाम जिसमें हम निकाले गए चेन डालना चाहते हैं।
S -> Verb interp (Fact.Field1) PP
व्याकरण में कहीं भी व्याख्या हो सकती है, लेकिन तथ्य केवल तभी निकाला जाता है जब व्याख्या किया गया चरित्र जड़हीन में गिरता है।
शुरू करने के लिए आवश्यक अंतिम विवरण कॉन्फ़िगरेशन फ़ाइल में इंगित करना है कि पार्सर शुरू होने पर हम किन तथ्यों को निकालना चाहते हैं। इस मामले में वाक्यविन्यास समान है जब ट्रिगर व्याकरणों को निर्दिष्ट किया जाता है: Facts फ़ील्ड में, वर्ग ब्रैकेट सभी आवश्यक तथ्यों को सूचीबद्ध करते हैं। हमारे मामले में, केवल एक तथ्य है:
Facts = [ { Name = "Fact" } ]
अब आप फिर से पार्सर शुरू कर सकते हैं।
परिणाम| जाने के लिए |
| रोकना |
| रोकना |
| ऊपर आओ |
| जाने के लिए |
| धक्का देना |
| लेने के लिए |
| आने के लिए |
| लगाना |
| माना जाता है |
| पालन करना |
| होना है |
| जाने के लिए |
| पीछे देखो |
| मांग करना |
| देखना |
| ठोकर खाना |
| शरण देना |
| होना है |
| दूर हटो |
| बाहर खींचो |
| पछतावा करना |
| बाहर जाओ |
| देने के लिए |
| होना है |
| खड़ा होना |
| बस जाओ |
| चलना |
| फाड़ना |
| होना है |
| होना है |
| ताली |
| देखना है |
| चलाने के लिए |
| बनने के लिए |
| बाहर जाओ |
| सो जाओ |
| एक रास्ता बनाओ |
| होना है |
| सवारी करना |
| कूदना |
| चलाने के लिए |
| पर लटका |
| उड़ान भरने के लिए |
| मारने के लिए |
| पहुँच जाओ |
| चलाने के लिए |
| उड़ान भरने के लिए |
| चमकने के लिए |
| बजना |
| हिट |
| जल्दी करना |
| पकड़ के लिए आ |
| चारों ओर घूमना |
| लगाना |
| बोलना |
| होना है |
| कूद |
| छोड़ने के लिए |
| परिवर्तनशील |
| कूदना |
| छोड़ |
| छीनना |
| नीचे गिरना |
| आने के लिए |
| सरपट भागना |
| बंद करना |
| जाने के लिए |
| बनने के लिए |
| बनने के लिए |
| बैठने के लिए |
| दूर होना |
| में देखने के लिए |
| बैठने के लिए |
| बंद करो |
| हिट करना |
| सक्षम होना |
| सपने देखना |
| इंतजार करना |
| होना है |
| गोता लगाना |
| देखना |
| ठंडा होने के |
| बाहर जाओ |
| बाहर जाओ |
| बंद करना |
| खटखटाओ |
| नेतृत्व करना |
| गायब हो जाते हैं |
| आराम करने के लिए |
| कुचलना |
| वृद्धि करने के लिए |
| गिर जाना |
| ऊपर चढ़ना |
| उतर जाओ |
| नीचे जाओ |
| घटित होना |
| गिरना |
| में बदल जाते हैं |
| छिपाने |
| हरा देना |
| रोकना |
| देने के लिए |
| जंगली भागो |
| की घोषणा |
| धोना |
| बाहर जाओ |
| चलना |
| बैठने के लिए |
| घसीटना |
| गिरना |
| होना है |
| जैसा होना चाहिए |
| बैठ जाना |
| होना है |
| बैठने के लिए |
| खड़ा होना |
| उठो |
| वापस आ जाओ |
| होना है |
| हरा देना |
| परिवर्तनशील |
| बाहर ले जाना |
| तरसना |
| लगाना |
| बाहर जाओ |
| जाने के लिए |
| मरने के लिए |
| होना है |
| घटित होना |
| होना है |
| poking |
| छोड़ने के लिए |
| एक साथ हो जाओ |
| निर्दिष्ट |
| फाड़ना |
| पकड़ना |
| पालन करना |
| गिरना |
| धारण करना |
| हाथापाई करना |
| उतर जाओ |
| बहना |
| होना है |
| रोपण करने के लिए |
| भेजना |
| बाहर जाओ |
| बैठ जाना |
| खींचना |
| ऊपर कूदो |
| बैठने के लिए |
| दूर हो जाओ |
| चाहने के लिए |
| मिलना |
| होगा |
| आने के लिए |
| मरने के लिए |
| बनने के लिए |
| जाने के लिए |
| मरने के लिए |
| बैठ जाना |
| के माध्यम से चलाएँ |
| दफनाने के लिए |
| छोड़ने के लिए |
| वापस आ जाओ |
| टूट जाना |
अतिरिक्त व्याकरण की विशेषताएं
अब हम खुद को और अधिक कठिन कार्य निर्धारित करते हैं: एक व्याकरण लिखने की कोशिश करें जिसके साथ आप पाठ से सड़क के नाम निकाल सकते हैं। हम पाठ (शब्द सड़क, राजमार्ग, एवेन्यू, आदि) में वर्णनकर्ताओं के लिए खोज करेंगे और उनके बगल में खड़ी श्रृंखलाओं का विश्लेषण करेंगे। जंजीरों को एक बड़े अक्षर से शुरू करना चाहिए और विवरणक के बाईं या दाईं ओर स्थित होना चाहिए। Address.cxx व्याकरण के साथ एक नई फ़ाइल बनाएं और इसे हमारे प्रोजेक्ट के साथ फ़ोल्डर में सहेजें। तुरंत हमारे नए व्याकरण के साथ मूल शब्दकोश में एक लेख जोड़ें:
TAuxDicArticle "" { key = {"tomita:address.cxx" type=CUSTOM} }
अब fact_types.proto में एक नया Street तथ्य जोड़ें जिसे हम पुनः प्राप्त करना चाहते हैं। यह दो क्षेत्रों से मिलकर बनेगा: अनिवार्य (सड़क का नाम) और वैकल्पिक (विवरणक)।
message Street: NFactType.TFact { required string StreetName = 1; optional string Descr = 2; }
व्याकरण लिखने के लिए सीधे जाने के लिए, आपको कई नई अवधारणाओं को पेश करने की आवश्यकता है जिन्हें हमने पहले नहीं छुआ है।
पहली अवधारणा ऑपरेटरों की है। वे आपको व्याकरण नियमों के अधिक सुविधाजनक संक्षिप्त अंकन प्राप्त करने की अनुमति देते हैं:
- * - चरित्र 0 या अधिक बार दोहराया जाता है;
- + - चरित्र को 1 या अधिक बार दोहराया जाता है;
- () - प्रतीक को नियम 0 या 1 समय में शामिल किया गया है;
- | - ऑपरेटर "या"।
व्याकरण लिखने के लिए आगे बढ़ते हैं। हम address.cxx फ़ाइल में दो नियम लिखेंगे - पहले हम StreetW नॉनटर्मिनल का वर्णन करते हैं, जिसमें कुछ स्ट्रीट डिस्क्रिप्टर के नाम होंगे और दूसरे में,
StreetSokr -
StreetSokr संक्षिप्त रूप से।
#encoding "utf8" StreetW -> '' | '' | '' | ''; StreetSokr -> '' | '' | '-' | '' | '';
अगला, हम नॉन-टर्मिनल StreetDescr , जो दो पिछले वाले को जोड़ती है:
StreetDescr -> StreetW | StreetSokr;
अब हमें जंजीरों का वर्णन करने की आवश्यकता है, जो कि यदि वे वर्णनकर्ता के बगल में हैं, तो सड़क के नाम हो सकते हैं। ऐसा करने के लिए, हम दो और अवधारणाओं का परिचय देते हैं: कूड़े के प्रतिबंध और समन्वय।
लिटर्स टर्मिनलों और गैर-टर्मिनलों के गुणों को निर्दिष्ट करते हैं, अर्थात्। टर्मिनल या गैर-टर्मिनल का वर्णन करने वाले जंजीरों के सेट पर प्रतिबंध लागू करें। वे टर्मिनलों / गैर-टर्मिनलों के बाद कोण कोष्ठक में लिखे गए हैं और, गैर-टर्मिनलों के मामले में, समूह वाक्यविन्यास मुख्य शब्द पर लागू होते हैं। संरचना में लाइटर विविध हो सकते हैं। कुछ एकतरफा ऑपरेटर हैं, कुछ के पास एक क्षेत्र है जिसे विभिन्न मूल्यों के साथ आबाद किया जा सकता है। हम कुछ ऐसे लिटर को सूचीबद्ध करते हैं जिनका हम भविष्य में उपयोग करेंगे (पूरी सूची हमारे प्रलेखन में पाई जा सकती है):
- आकृति विज्ञान कूड़े
gram एक ऐसा क्षेत्र है जो शब्दकोष से किसी भी रूपात्मक श्रेणी से भरा जा सकता है: भाषण का हिस्सा, लिंग, संख्या, मामला, समय, मूड, आवाज, व्यक्ति, आदि। <gram = “, , ”> ; - व्याकरणिक लेबल - लेबल का एक समूह जो निकाले गए श्रृंखला के रजिस्टर पर प्रतिबंध लगाता है:
<h-reg1>, <l-reg> ; - विशेष अंक - एक वाक्य में एक शब्द की स्थिति, वर्णमाला, आदि को प्रतिबिंबित कर सकते हैं।: ,,
, , ;
: , : <~fw>, <~lat> .
, , ;
: , : <~fw>, <~lat> .
थोड़ा अलग सिंटैक्टिक कूड़े है . ( ), . . . ( ), . .
कोण मिलान कोष्ठक में लिटर मिलान भी दर्ज किया गया है और इसका अर्थ है कि जिन दो पात्रों को इसे सौंपा गया है, उनमें समान व्याकरणिक श्रेणियां होनी चाहिए। सबसे अधिक बार, निम्नलिखित अनुमोदन लागू होते हैं:
- जीनस, संख्या और मामले द्वारा:
gnc-agr ; - लिंग और संख्या के अनुसार:
gn-agr ; - केस:
c-agr ।
नियम में, एक मिलान पहचानकर्ता लिखना आवश्यक है जो इंगित करता है कि कौन सा चरित्र किसके साथ संगत है। उदाहरण के लिए, निम्नलिखित नियम में, प्रतीक A लिंग, संख्या और मामले में B के अनुरूप है, और C के साथ - संख्या और मामले में:
S -> A<gnc-agr[1], nc-agr[2]> B<gnc-agr[1]> C<nc-agr[2]>;
सड़क नामों के लिए हमारे नियम पर वापस जाएं। आमतौर पर सड़क का नाम या तो विवरणक (Moskovsky Prospekt) के साथ एक विशेषण सहमत है, या नाममात्र या जनन मामले में एक संज्ञा समूह (कुजनेत्स्की सबसे स्ट्रीट या क्रास्नाय कुर्स्कोव स्ट्रीट) के साथ खड़ा है। सबसे पहले, संज्ञा वाक्यांश का वर्णन करें। इस श्रृंखला का मुख्य तत्व एक शब्द होगा जिसे इसके (वैष्णिह वोडी स्ट्रीट) विशेषण से पहले स्वीकार किया जा सकता है, और उसके बाद - आनुवंशिक मामले (मास्को की आठवीं शताब्दी) में एक और शब्द।
StreetNameNoun -> (Adj<gnc-agr[1]>) Word<gnc-agr[1],rt> (Word<gram="">);
विशेषणों द्वारा व्यक्त की गई सड़क के नाम काफी सरल रूप से वर्णित हैं। यह कुछ विशेषणों का क्रम है, जिनमें से पहला एक बड़े अक्षर के साथ आना चाहिए:
StreetNameAdj -> Adj<h-reg1> Adj*;
मूल नियमों में, हम एक साथ वर्णनकर्ता और सड़क के नाम एकत्र करेंगे और व्याख्या जोड़ेंगे। हम मानते हैं कि नाम समूह द्वारा व्यक्त की गई सड़क का नाम सड़क विवरणक के बाद आता है। इसे पूंजीकृत किया जाना चाहिए और नाममात्र या StreetNameNoun मामले में खड़ा होना चाहिए (गैर-टर्मिनल StreetNameNoun को सौंपे गए StreetNameNoun श्रृंखला के मुख्य शब्द पर लागू होंगे)। स्ट्रीट डिस्क्रिप्टर की व्याख्या Descr तथ्य के StreetName क्षेत्र में और StreetName स्ट्रीट नाम में की StreetName ।
Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName); Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName);
विशेषण द्वारा व्यक्त किए गए सड़क के नाम के टेम्पलेट के लिए, हम एक और विशेष मामले पर विचार करते हैं जब नाम में एक अंक (1 Sovetskaya स्ट्रीट) लिखा होता है। , , . . , , : wff , wfl — , wfm — .
S -> A<wff=/[0-9]+.?/>;
, , 0 99, , . , — — NumberW .
NumberW_1 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/>; NumberW_2 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/>; NumberW_3 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/>; NumberW -> NumberW_1 | NumberW_2 | NumberW_3;
, -, . , , , .. , . . outgram , . :
NumberW_1 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/> {outgram=",,"}; NumberW_2 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/> {outgram=",,"}; NumberW_3 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/> {outgram=",,"};
StreetNameAdj : NumberW , , .
StreetNameAdj -> NumberW<gnc-agr[1]> Adj<gnc-agr[1]>;
, StreetNameAdj . , , , . ̈ , .. .
Street -> StreetNameAdj<gnc-agr[1]> interp (Street.StreetName) StreetW<gnc-agr[1]> interp (Street.Descr); Street -> StreetNameAdj interp (Street.StreetName) StreetSokr interp (Street.Descr); Street -> StreetW<gnc-agr[1]> interp (Street.Descr) StreetNameAdj<gnc-agr[1]> interp (Street.StreetName); Street -> StreetSokr interp (Street.Descr) StreetNameAdj interp (Street.StreetName);
. , ( ). , , , , . , . not_norm . , , .
Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName::not_norm); Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName::not_norm);
, , address.cxx Street . , , Input input1.txt
Input = {File = "input1.txt"} Output = {File = "output.txt" Format = text} Articles = [ { Name = "" } ] Facts = [ { Name = "Street" } ]
, :
परिणाम| पता |
| StreetName | descr |
|---|
| 1 डबरोवस्काया | str |
| लोअर मस्लोवका | str |
| दुनिया का | एवेन्यू |
| 1 व्लादिमीरकाया | सड़क |
| बोलश्या सेमेनोवस्काया | str |
| Komsomol | एवेन्यू |
| तैमूर फ्रुंज़े | str |
| |
. dic.gzt, — , , , .. . . .
. , ̈ . — — :
TAuxDicArticle "" { key = "" | "" | ""}
, :
TAuxDicArticle "" { key = {"tomita:address.cxx" type=CUSTOM}}
̈ . , , ̈ — . , , , , , ..
TAuxDicArticle "" { key = { mainword=2 agr=gnc_agr} }
«» — « », , , . , .
, :
TAuxDicArticle "-" { key = "-" key = "" key = "" lemma = "-" }
, , . kwtype . , , (), , .. , kwtype . kwset , . :
Animals -> Word <kwtype="">; Forest -> Word <kwset=["", ""]>;
, ̈ . TAuxDicArticle, , , , . kwtypes.proto. , :
import "base.proto"; import "articles_base.proto"; import "kwtypes_base.proto";
̈ . . message , , . .
message surname : TAuxDicArticle {}
. .gzt- surnames.gzt, , ̈ surname. , kwtypes.proto, , . , , TAuxDicArticle surname :
encoding "utf8"; import "kwtypes.proto"; surname "" { key = "" } surname "" { key = "" } surname "" { key = "" }
, import "surnames.gzt"; । import "kwtypes.proto"; ।
, , , : « -». imeni.cxx. , . . , surname . ̈ , . + “” ( ).
#encoding "utf8" Initial -> Word<wff=/[-]\./>; Initials -> Initial Initial; FIO -> Initials Word<kwtype=surname>; Imeni ->''<gram=", "> FIO;
. :
TAuxDicArticle "" { key = {"tomita:imeni.cxx" type=CUSTOM} }
config.proto ( ) , — . , imeni.cxx input2.txt . . , pretty.html , .
, , . : kwtype , ̈ , , #include . #include — , , . kwtype . imeni.cxx ̈ , . org.cxx. .
#encoding "utf8" OrgDescr -> '' | '' | '';
« -». kwtype , «», imeni.cxx. , , kwtype — . — .
, .
Org_ -> OrgDescr Word<kwtype="">; Org -> Org_ interp (Org.Name);
:
TAuxDicArticle "" { key = {"tomita:org.cxx" type=CUSTOM} }
fact_types.proto:
message Org: NFactType.TFact { required string Name = 1; }
, , ̈ . , “”. , “Org”.
Articles = [ { Name = "" } ] Facts = [ { Name = "Org" } ]
pretty.html. « . . ».
? « .. » imeni.cxx. « _..», .. , org.cxx.
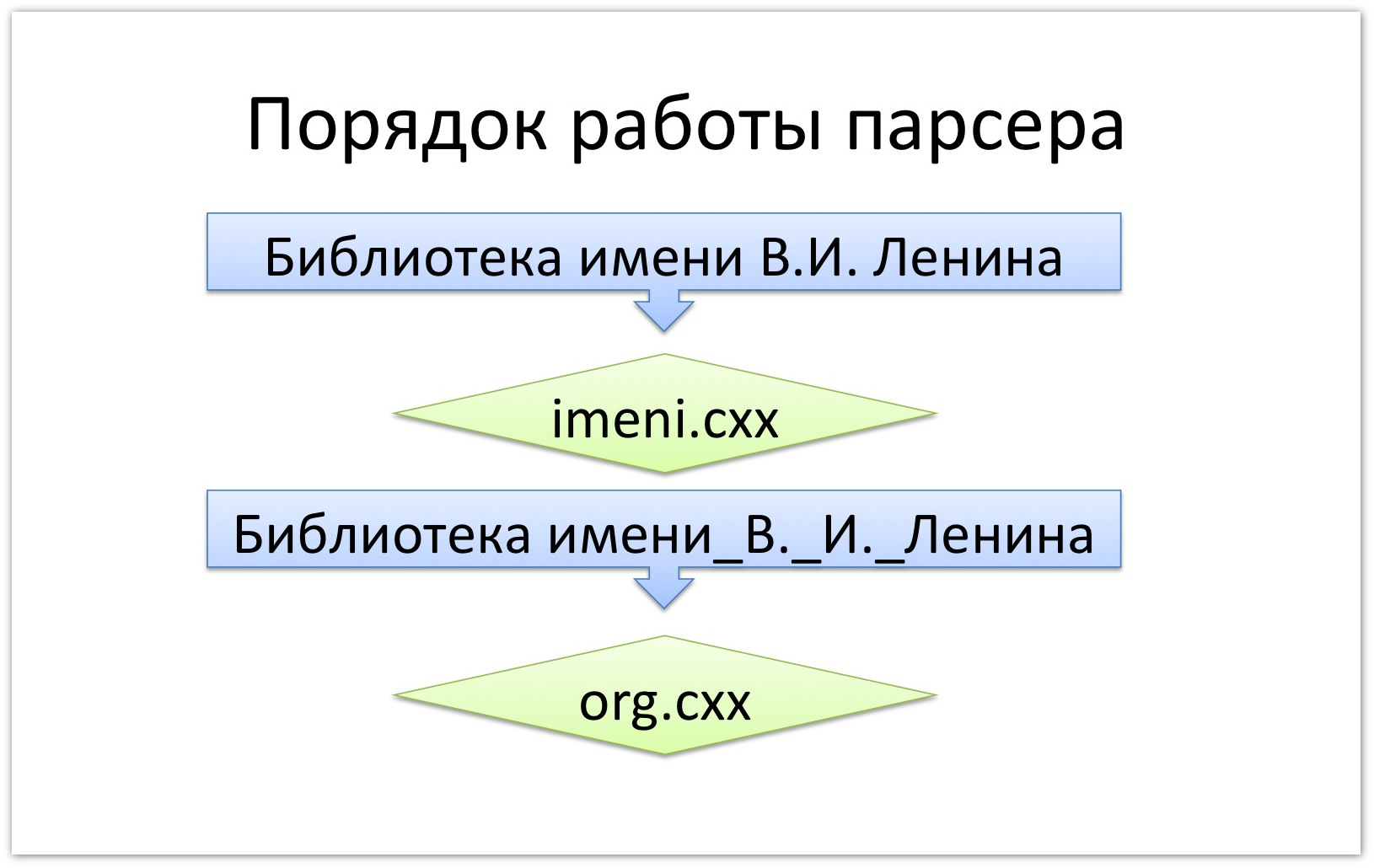
, , (.. kwtype ): , .
. , -, .