VP8の
最初のレビューを書いていた瞬間でさえ、公式のデコーダー
libvpxが非常に遅いことに気付きました。 優れた
H.264デコーダーよりも大幅に高速である必要がある特別な理由はありませんが、それほど遅くなることはありません! だから私はロナルド・ブルジェとデビッド・コンラッドとともに
FFmpegのベストバージョンを書く計画を持っていました。 このデコーダーの実装は、libvpxライブラリーであるプロプライエタリコードのダンプとは対照的に、コミュニティによって開発され、最初から自由であると想定されていました。 数週間前、デコーダーはビデオストリームとlibvpxのバイナリ互換性を確保するために十分に完成し
、VP8デコーダーの最初の独立した無料の実装になりました 。 最適化の最初のサイクルが完了したので、実際の条件で使用する準備ができているはずです。 開発プロセスの詳細については後で説明しますが、次に、この投稿の核心であるコーデックパフォーマンスの比較テストの結果に移りましょう。
2つの1080pクリップでデコーダーをテストしました:
Parkjoy (ライブショット)と
Sintel trailer (コンピューターで作成)。 テストは次のように実行されました。
time ffmpeg -vcodec {libvpx or vp8} -i input -vsync 0 -an -f null -この投稿の時点でSVNからの最新のFFmpegビルドを使用しました。VP8デコーダーの最適化を含む最後のリビジョンはr24471でした。
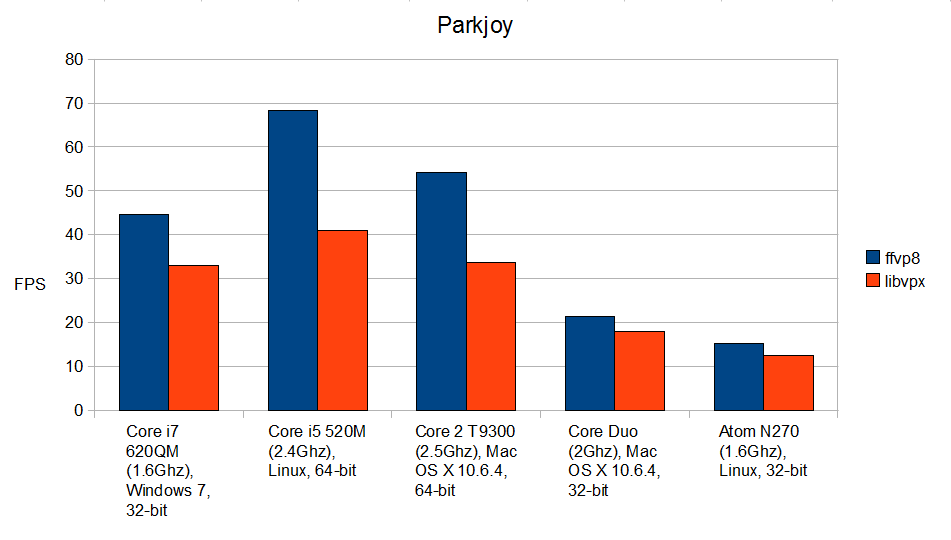

これらのグラフが示すように、特に64ビットプラットフォームでは、ffvp8はlibvpxよりもはるかに高速です。 Atomプロセッサ上でも、Atom専用に最適化すらしていないにもかかわらず、非常に高速に動作します。 多くの場合、このパフォーマンスの違いにより、特にエンジンがプロセッサのリソースのかなりの部分を消費する最新のブラウザで、ビデオが再生されているかどうかが決まります。 VP8ビデオをより速く再生したいですか? FFmpegベースのプレーヤーの新しいバージョン(これはよく知られている
VLCおよび他の多くのバージョンです)には、ffvp8ライブラリが含まれます。 ブラウザでVP8ビデオをより速くデコードしたいですか? 開発者と通信し、libvpxの代わりにffvp8を使用することを主張します。 ビデオ再生サブシステムで既にlibavcodecを使用しているため、Chromeがffvp8を最初に使用すると信じています。
ffvp8の開発はそこで終わりではないことを忘れないでください。改善とスピードアップを続けます。 メインの開発ブランチにはまだ含まれていない最適化のキューがまだあります。
FFVP8開発
DavidとRonaldが始めた最初のタスクは、デコーダーのコアを再作成し、libvpxとストリームのバイナリー互換性を実現することでした。 公式仕様が不完全であるため、これは簡単ではありませんでした。 仕様の多くの部分は一般的に正しくなく、libvpxコードと矛盾していました。 そしてもちろん、公式の互換性テストのセットが公式のエンコーダーが使用するすべての機能をカバーしていないという事実は、私たちの仕事を助けません! この状況で何らかの形でさらに機能するためには、独自のテストの追加を開始する必要がありました。 しかし、私は以前の投稿で品質仕様の欠如についてすでに不満を言っていたので、ニュアンスに移りましょう。
次のステップは、すべての重要な
DSP機能に
SIMDコードを追加することでした。 基本的に、VP8デコーダーのプロセッサーの負荷は、H.264と同じように、動き補償とデブロッキングフィルター(
エンコードアーティファクトの補償、トランス )によって作成されます。 ただし、H.264とは異なり、デブロッキングフィルターは
飽和の内部
演算に依存します。これは、SIMD実装ではコストがかかりませんが、Cの実装のプロセッサーに関しては非常に「食いしん坊」です。もちろん、どちらも深刻な問題はありません、すべての通常のコーデックでは、これらのプロセスはSIMDコードとして実装されているためです。
Ronaldがx86のSIMDを手伝ったほか、ほとんどの動き補償、内部予測、および逆変換の一部を書きました。 ロナルドは、逆変換の残りと動き補償部分を書きました。 彼はまた、最も難しい部分であるデブロッキングフィルターも行いました。 これらのフィルターは、コーデックごとに異なるため、常に難しい部分です。 比較すると、動き補償の実装は、通常、コーデックが異なればそれほど違いはありません。6タップフィルターはいずれの場合も6タップフィルターになり、通常は係数のみが異なります。
SIMDデブロッキングフィルターの最大の難点は、「アンパック」を回避することでした。 8ビットから16への遷移。 このようなフィルターの多くの操作では、最初は8ビット以上の精度が必要と思われます。 x86の簡単な例はabs(ab)で、aとbは8ビットの符号なし整数です。 結果の「ab」には、符号付きの9ビットの精度が必要です(-255〜255の間にある可能性があるため)。したがって、8ビットには収まりません。 しかし、「アンパック」なしでこの問題を解決することは非常に可能です:(satsub(a、b)| satsub(b、a))、ここで、「satsub」は2つの値の間の飽和の差を計算します。 差が正の場合、結果が返され、それ以外の場合はゼロです。したがって、これらの関数の結果の論理ORを実行すると、必要なものが得られます。 これには4つのx86アセンブラー命令が必要です。実際の「アンパック」および「パッキング」ステップを含め、「アンパック」には少なくとも10が必要です。
これに続いて、CコードのSIMD最適化が行われ、その実行は依然としてデコード時間のかなりの部分を占めました。 私の最大の最適化の1つは、キャッシュミスの数を減らすスマートプリフェッチの追加でした。 ffvp8は、現在のフレームで参照されているフレーム(「前」、「ゴールド」、「代替リンク」、前、ゴールド、ALTREF)を事前クエリしますが、このフレームで実際に使用されている場合のみです。 これにより、必要なすべてを事前に照会でき、使用する可能性が低いものを要求することはできません。 原則として、libvpxは、GOLDENまたはALTREFフレームをほとんど使用しない(「まったく使用しない」と理解しない)フレームをエンコードするため、この最適化により、多くの実際のビデオでの事前要求にかかる時間が大幅に削減されます。 さらに、コードのさまざまな場所で多くの最適化を行ったため、たとえばDavidが作成したエントロピーデコーダーの最適化など、すべてをここにリストすることはできません。 また、これらの改善のほとんどのパフォーマンスをテストする際に貴重な助けをしてくれたEli Friedmanにも感謝します。
次は? Altivecアセンブリコード(
PPC )は実質的に存在せず、Davidの動き補償コードにはいくつかの機能しかありません。 NEON(
ARM )のアセンブリコードはまったくなく、モバイルデバイスで迅速に動作するために必要です。 もちろん、これはすべて時間の経過とともに行われ、いつものように、私たちは常にパッチに満足しています!
アプリケーション:裸の数字
以下は、上記のグラフに対応する数値で、1秒あたりのフレーム数と
標準誤差を示しています。
Core i7 620QM(1.6Ghz)、Windows 7、32ビット:
Parkjoy ffvp8:44.58±0.44
Parkjoy libvpx:33.06±0.23
Sintel ffvp8:74.26±1.18
Sintel libvpx:56.11±0.96
Core i5 520M(2.4Ghz)、Linux、64ビット:
Parkjoy ffvp8:68.29±0.06
Parkjoy libvpx:41.06±0.04
シンテルffvp8:112.38±0.37
Sintel libvpx:69.64±0.09
Core 2 T9300(2.5Ghz)、Mac OS X 10.6.4、64ビット:
Parkjoy ffvp8:54.09±0.02
Parkjoy libvpx:33.68±0.01
シンテルffvp8:87.54±0.03
Sintel libvpx:52.74±0.04
Core Duo(2Ghz)、Mac OS X 10.6.4、32ビット:
Parkjoy ffvp8:21.31±0.02
Parkjoy libvpx:17.96±0.00
シンテルffvp8:41.24±0.01
Sintel libvpx:29.65±0.02
Atom N270(1.6Ghz)、Linux、32ビット:
Parkjoy ffvp8:15.29±0.01
Parkjoy libvpx:12.46±0.01
シンテルffvp8:26.87±0.05
Sintel libvpx:20.41±0.02
翻訳者メモ
たとえば、6タップフィルターのロシア語の正しい翻訳を誰かが教えてくれたら、とても感謝しています。
以下では、ノートへのコメントで、著者は読者からのいくつかの質問への回答を示しています。 これは質問と回答を直接翻訳したものではなく、本質を要約したものです。
Q:ffvp8は、libvpxに加えられた改善を使用できますか?
A:実際、興味深いと思われるすべての最適化は、すでにそこから行われています。 ただし、デコーダのアーキテクチャは根本的に異なるため、ソースの単純なマージでは十分ではないことを理解する必要があります。
Q:ffvp8がlibvpx実験開発ブランチとの互換性を維持できなくなる危険性はありますか?
A:現時点では、実験ブランチは実際の条件での使用を目的としていないため、このようなタスクは価値がありません。 実験ブランチと現在のlibvpxとの互換性さえ保証されていません。
Q:FFmpegの開発のスポンサーは誰ですか?
A:プロジェクト全体は誰でもありませんが、特定の顧客が必要とする機能の実装に対してお金を受け取る開発者もいます。 著者が知る限り、ffvp8の開発は完全に非営利でした。
Q:パフォーマンスの向上は、libvpxのグローバルなデメリットの1つによるものですか、それともあちこちで多くの最適化が行われたのですか?
A:一般的には、2番目です。 しかし、主なパフォーマンスの向上は、libvpxがフレームを数回通過し(以前のすべてのOn2コーデックが同じことを行う)、ffvp8がすべての操作を1回のパスで実行するためです。
Q:FFmpegで独自のVP8エンコーダーを開発する予定ですか?
A:これは非常に大きな仕事であり、正直なところ、これが実行されるとは思いません。 実際、FFmpegが持つ唯一の「ネイティブ」エンコーダーはmpegエンコーダーであり、既存のフレームワークに基づいてVP8エンコーダーを作成する方法はほとんどありません。いずれにしても、この方法は単純ではありません。 しかし、もちろん、誰かが試してみたい場合...
Q:しかし、FFmpegのネイティブエンコーダーがmpegのみの場合、このライブラリは、mpegだけでなく、WMV 7/8、H.261 / 3、および他のライブラリを使用しない他の形式でもビデオエンコーディングをサポートしますか
A:これらのエンコーダーはすべて、実際には内部mpegエンコーダーを使用しますが、フォーマットごとにわずかなバリエーションがあります。 エンコーダーは多くの部分で構成される大きく複雑なプログラムであり、リストされている形式のエンコーダー間の唯一の重要な違いはエントロピーエンコーディングアルゴリズムとヘッダーであることに留意してください。 両方とも、残りのコードを変更せずに簡単に置き換えることができます。 FFmpegには、すべてメインmpegエンコーダーに基づく非常に多くの「エンコーダー」が存在する理由です。実際、これらのアルゴリズムの違いはそれほど重要ではありません(それらはすべて、8x8ピクセルブロックの
離散コサイン変換に基づくMPEGに似ています)。ほぼ同じコードが使用されます。
ちなみに、これはFFmpegにWMV9エンコーダーがないことを説明しています-このアルゴリズムは以前のバージョンとはあまりにも異なるため、内容に基づいて簡単に実装できます。
Q:ffvp8はVP4、5、6、7もデコードできますか?
A:たぶんですが、VP4、5、6のみです。VP7をまだリバースエンジニアリングしていないためです。 しかし、VP7とVP8がほぼ同じであると私は疑っているので、VP8のオープンを考慮して、VP7のサポートは近い将来に登場するでしょう。
Q:Media Player Classic HomeCinemaとFFDshowの新しいSVNアセンブリをどこで入手して、新しいWindowsデコーダーで自分で確認できますか?
概要:
xhmikosr.1f0.deメモの作成者に質問がある場合は、翻訳して彼のブログに公開する準備ができています。