複雑なシステムのエミュレートを開始する前に、たとえばChip-8などの単純なものから始める必要があると考えられています。 この記事では、仮想マシンでこの言語の実装を作成する方法のすべての側面を検討します。 どのプログラミング言語でも実行できますが、その単純さから、Delphiを選択します。
待って、すぐにエディターに突入しないでください。最初にペンとノートが必要です。ここで、私たち自身のためにすべての重要な情報を書き留めます。 それはすべて彼女の検索から始まります。 まず、これはもちろんGoogleです。 30分間リンクをたどると、どのシステムに対して既にいくつの実装が作成されているかを確認できます。選択はしたくありませんが、他のソースコードを見るのではなく、独自に作成します。
歴史的背景
CHIP-8は、RCAのTELMAC 1800やCOSMAC VIPなどの一部の小型商用コンピューターや、ETI 660やDREAM 6800のような安価な「自分で作成」コンピューターで70年代後半から80年代前半に使用された言語インタープリターです。 ...
CHIP-8により、ゲームのプログラミングが簡単になりました。 TELMAC 1800およびCOSMAC VIPは、RCA CDP-1802プロセッサに基づいていました。 どちらも1977年の12ゲーム以上のオーディオカセットが付属しています。 インタープリターには、数学、データフローの制御、グラフィックス、サウンドなど、40未満のコマンドがありました。
これらのコンピューターのメモリ制限のため、インタープリターは非常に小さくする必要がありました。COSMACVIPは2Kb(ただし、32Kbに拡張可能)で、TELMACは4Kbでした。 CHIP-8の長さは512バイトのみでした。
言語のシンプルさにより、ビデオゲームの最初の段階でプレイしたPong、Brix、Invaders、Tankを作成できました。 優れたプログラマーは、これらのゲームを256バイト未満で入れることができます。
DREAM-6800ユーザーの1人のCHIP-8についての短いストーリーを次に示します。
「
... DREAMとETI 660は、オーストラリアの電子雑誌にビルドプロジェクトとして登場しました。これらのコンピューターを組み合わせ、信じられないほど低価格(約100ドル)、16進キーボードの使用、非常に限られたグラフィックス64 x 32ピクセル(ETI 660 64 x 48または64 x 64(変更時)をテレビに転送し、約1キロバイトのRAM、およびCHIP-8と呼ばれる高レベルの擬似言語を実行する機能(COSMACグラフィックをデモンストレーションするためにRCAが開発したようです)。
...
ある日、兄がDREAM 6800を組み立てました。なんてコンピューターなのでしょう! DREAM&ETI 660ビルドの記事と一緒に、CHIP-8のゲームリストが山ほどありました。 一部のゲームは200バイト以下であったため、それらを入力することは永遠にかかりません。 そして、これらは素晴らしいゲームでした。 彼らは遅くなかった。 したがって、CHIP-8は古典的なテレビゲーム用に非常にうまく設計されていました。 」
Paul Hyter(AmigaのCHIP-8インタープリターが投稿)
その後、90年代前半にHP48計算機でCHIP-8が使用されました。これは、CHIP-8でゲームをより速く書く方法がなかったためです。 CHIP-8のほとんどすべてのオリジナルゲームもCHIP48インタープリターで動作しましたが、多くの新しいゲームが作成されました。
その後、新しいバージョンの言語-SUPER-CHIPがリリースされました。 彼は標準のすべての機能を備えていましたが、128x64の解像度で既に動作することができました。
建築
CHIP-8のすべてのプログラムは200時間で始まりますが、ETI-660は600時間で始まります。 これは、言語インタープリター自体が000h-1FFhにあるためです。
すべてのメモリは完全にアドレス可能でアクセス可能です。 命令は16ビットを占有するため、通常は偶数アドレスを持ち、8ビットがコード内に挿入されると、アドレスは奇数になります。
メモリアドレスに使用される12ビットに基づいて、トリックなしの最大メモリ量は4096バイト(000h-FFFh)であると計算できます。 ただし、アドレスF00h-FFFhはビデオメモリによって占有され、EA0h-EFFhはCHIP-8のスタックおよび内部変数を格納するために使用されます。
インタープリターは、8ビットのボリュームを持つ16個の汎用レジスターを使用します。 V0..VFとして利用可能です。 さらに、VFは、転送の場合は算術演算のフラグとして、スプライトを描画するときは衝突検出器として使用されます。
サイズが16ビットのアドレスレジスタ(I)も1つあります。 メモリは4キロバイトしかないため、インタープリターは下位12ビットのみを使用しました。 ただし、フォントが8110にあるため、上位4ビットはフォントのダウンロード機能に使用できます。
レジスタに加えて、2つのタイマーがありました。 1つは遅延タイマー、もう1つはオーディオタイマーです。 両方とも8ビットの長さであり、その時点でゼロでない場合、1秒あたり60回コンテンツを削減しました。 つまり、周波数は60ヘルツでした。 サウンドタイマーの値がゼロ以外の場合、サウンドが再生されました。
スタックの次元は不明のままでしたが、16レベル(2x16バイト)で行うのが一般的です。
グラフィックは、バイト単位でエンコードされた1..15ピクセルの8つのスプライトでレンダリングされます。 原点は左上隅にあり、ポイント0から始まります。すべての座標は正であり、それぞれ64または32による除算の残りと見なされます。 画面への出力はXORモードです。 1つ以上のピクセルがクリアされると(色を1から0に変更する)、VFレジスタは01hと00hに設定されます。 Chip-8には、文字0-9およびAFを含む4x5ピクセルのフォントがあります。
明確にするために、スプライトとそのコーディングの例を考えてみましょう。 8x5のスプライトを取ります。
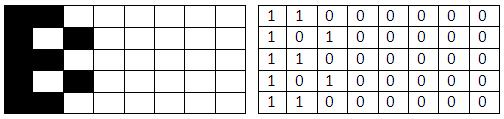
次のバイトセットを取得します
0 A0 0 A0 0完全にクリアするには、別の1スプライト8x8を使用します。

スプライトは8バイトを占有し、次の構造を持ちます
0 60 30 18 0 06 03CHIP-8のキーボードは16番目で、次の外観があります。
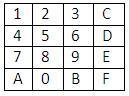
そのようなキーボードの利便性と便宜性は、議論と議論しかできません。 しかし、すべてがそのようなキーボードのために特別に開発されたので、我々はオリジナルから出発しません。
コマンドシステム
アドレスをNNN、KK-8ビット定数、XおよびY-4ビット定数として指定することをすぐに言う必要があります。
次に、コマンドのリストを検討します。
0NNN Syscall nnnコードNNNでプロセッサ1802の機械命令命令を呼び出します。
00CN * scdown n画面をN行下にスクロールします。
00FB *画面を右に4ピクセルスクロールするScright
00FC *画面を左に4ピクセルスクロールするScleft
00FD *エミュレーターを終了する
00FE *低グラフィックモードをCHIP-8(64x32)に設定します
00FF *高グラフィックモードをスーパーチップ(128x64)に設定します
00E0 Clsクリアスクリーン
00EE Rtsルーチンからの戻り
1NNN jmp nnnプログラム実行をNNNに転送
2NNN jsr nnn NNNでの関数呼び出し。 前のアドレスがスタックにプッシュされます。
3XKK skeq vx、kk VX = KKの場合、次の命令(2バイト)をスキップします
4XKK skne vx、kk VX <> KKの場合、次の命令(2バイト)をスキップします
5XY0 skeq vx、vy VX = VYの場合、次の命令をスキップします
6XKK mov vx、kk VXレジスタにKKを書き込みます
7XKKはvx、kkを追加しますVXレジスタにVX + KKを書き込みます(ウィキペディアおよびその他のソースからの情報によると、フラグには影響しません)
8XY0 mov vx、vy VXでレジスタVYの値を書き込む
8XY1またはvx、vy VX = VXまたはVY。
8XY2およびvx、vy VX = VX AND VY
8XY3 xor vx、vy VX = VX XOR VY(元の文書には文書化されていません)
8XY4は、vx、vy VX = VX + VYを追加します。 VF =キャリー。
8XY5サブvx、vy VX = VX-VY。 (*)VF =借用しない。
8X06 shr vx VX = VX SHR 1(VX = VX / 2)、VF =キャリー
8XY7 sub vy、vx VX = VY-VX、VF =借用しない(*)(元の文書には記載されていません)
8XYE shl vx VX = VX SHL 1(VX = VX * 2)、VF =キャリー
9XY0 skne vx、vy VX <> VYの場合、次のステートメントをスキップします
ANNN mov I、nnn I = NNN
BNNN Jmi NNN NNN + V0へのプログラム実行の転送
CXKKランドvx、kk VX =(乱数0..255)およびKK
DXYN vx、vy、nを描画します。レジスタIに含まれるアドレスのメモリで始まる座標(VX、VY)で、高さN(N = 0カウントN = 16)で幅8のスプライトを描画します。VF=衝突。
EX9E Skpr vx VXキーが押された場合、以下の指示をスキップします。
EXA1 Skup vx VXで数字キーが押されていない場合、以下の指示をスキップします。
FX07 Gdelay vx VX =遅延タイマー
FX0A Key vxボタンが押されるのを待って、VXに追加します。
FX15 Sdelay vx遅延タイマー= VX
FX18 Ssound vxサウンドタイマー= VX
FX1E Add I、vx I = I + VX
FX29 Font vx VXに含まれるフォントスプライト4 x 5の16進文字のIアドレスに入力
FX33 Bcd vx BCD VX表現をメモリのI..I + 2アドレスに配置します。 たとえば、VXに4Fhが含まれる場合、00h 07h 09hがメモリに書き込まれます。つまり、4Fhの10進表現です。
FX55 Save vx Saves V0 ... VXレジスターはアドレスIから始まるメモリーに保存されます。
FX65 Load vxアドレスIから始まるメモリからレジスタV0 ... VXをロードします
FX75 * Ssave vxはV0 ... VX(X <8)をHP48フラグに保存します
FX85 * Sload vx HP48フラグからV0 ... VX(X <8)をロード
*-コマンドがSUPER CHIPインタープリターにのみ関連することを意味します。
(*):VX-VYが発生すると、VFはローンの拒否に設定されます。 つまり、VXがVY以上の場合、ローン= 0であるため、VFは01に設定されます。VXがVYより小さい場合、ローン= 1であるため、VFは00に設定されます。
基本的なスプライトの準備
紙とペンを使用して、フォントスプライトの輪郭を描きます。 このセットのようなものが得られます:

それを使用して、各スプライトの値のバイトを書き込みます。
エミュレーションの原則
すべてのエミュレーションは、ほぼこのタイプのサイクルで行われると考えられています。
繰り返す
//エミュレーションを行います
quit_pr まで
ここで、quit_prはエミュレーションを停止する兆候と見なされ、外部からだけでなく、エミュレーションの内部からも変更できます。
遵守すべき最も重要なポイントの1つは、機器の動作周波数と最適化の遵守です。 CHIP-8のような単純な言語のエミュレーションを記述するのが間違っている場合、非常に低いパフォーマンスと非常に高いプロセッサ時間を得ることができますが、正しいエミュレーションは最低コストで十分なパフォーマンスを提供します。
Delphiを使用して、システムエミュレーションをクラスとして開発することにし、このシステム内で使用されるプロセッサのモデルに基づいて、「TCpu1802」という名前を付けました。 メインの実行手順を検討してください。
プロシージャ tcpu1802 走る
始める
delaytimer 。 有効 : = true ;
サウンドタイマー。 有効 : = true ;
drawtimer 。 有効 : = true ;
work : = true ;
繰り返す
useopcode ;
cpumulty <> 0の 場合
if ( round ( cycle ) mod ( 2 ) ) = 0 then sleep ( cpumulty ) ;
アプリケーション。 ProcessMessages ;
work = false まで 。
delaytimer 。 有効 : = false ;
サウンドタイマー。 有効 : = false ;
drawtimer 。 有効 : = false ;
終わり ;
まず、起動時に、CHIP-8タイマーの2つの標準と、画面を再描画するために個別に入力された1つの標準をアクティブにします。 サイクル-コマンドの現在のサイクルを含む変数。各コマンドの呼び出しにより、サイクルが1つ増加します。 2番目のアクションごとに、cpumultyミリ秒間インタープリターを一時停止しようとします。 これは、高速化が発生しないようにするために必要です。
SoundtimerタイマーとDrawtimerタイマーの間隔は17ミリ秒です。つまり、58.82ヘルツの周波数で動作します。これは、オリジナルに可能な限り近いものです。
ドロータイマーの遅延は10ミリ秒に設定されています。 つまり、平均して、レンダリングは3〜4個のインタープリターコマンドごとに実行されます。 インタープリターの実行プロセスを詰まらせないためにタイマーへの割り当てが行われ、プロセスの並列化を実行するための通常の手段を使用することができます。
エミュレーション自体を完了するために必要な変数のリストを見てみましょう。
キーコード: バイト ; //押されたキーのコード
メモリ: バイトの 配列 [ 0 .. 8191 ] 。 //フォントの場所のために割り当てられた8キロバイトのRAM
スタック: 単語の 配列 [ 0..255 ] 。 //スタック
stacksize : byte ; //現在のスタックスイープ
videoarray : ブール値の 配列 [ 0..2047 ] 。 //ビデオ配列
マスク: ブール値の 配列 [ 0..2047 ] 。 //ビデオ配列のマスク
Vreg : バイトの 配列 [ 0 .. 15 ] 。 //-V0..VFを登録します
Ireg : 言葉 。 // 2バイトのアドレスレジスタ
CodeSender : ワード 。 //メモリ内の次のオペコードの場所
音: ブール値 ; //サウンドは現在再生中ですか?
アーキテクチャによれば、ビデオメモリは他のすべてと同じ量のRAMに配置されますが、そこへの一定の読み取りと書き込み、バイトの検査と分析は多くのプロセッサリソースを消費し、プログラムが何かを読み取ることができると仮定すると非現実的ですそこから直接、そのメモリ領域からの読み取りが発生した場合、mirrorvideomemという追加のプロシージャを呼び出すだけで、そこにビデオメモリの現在の内容を書き込むことができます。 このようなソリューションは効果的ですが、RAMの使用量がわずかに増えます。 ミラースタックの手順は似ています。
プロシージャ tcpu1802 mirrorvideomem ;
var
i 、 j : 整数 。
tmp : バイト ;
始める
if ( Ireg> = $ F00 ) and ( Ireg < = $ FFF ) then
始める
for i : = 0 から 255 まで
始める
tmp : = 0 ;
for j : = 0 から 7 do
始める
videoarray [ i * j ] if tmp : = tmp + 1 ;
tmp : = tmp shl 1 ;
終わり ;
メモリ[ $ F00 + i ] : = tmp ;
終わり ;
終わり ;
終わり ;
プロシージャ tcpu1802 mirrorstack ;
var
n 、 i : 整数 ;
始める
if ( Ireg> = $ EA0 ) and ( Ireg < = $ EFF ) then
始める
stacksize> 12 then n : = 11 else n : = stacksize - 1 ;
for i : = 0 から n
始める
メモリ[ $ EFF - i * 2 ] : = stack [ i ] div 256 ;
メモリ[ $ EFF - i * 2 + 1 ] : = stack [ i ] mod 256 ;
終わり ;
終わり ;
終わり ;
プロセッサを作成する前に、各コマンドが条件付きで4ビットの4つのセクションに分割されていることがわかります。 それらを使用するために、opcodeデータ型が導入されました(type opcode = array [0..3] of byte;)。
メモリから次のデータを変換して読み取ることはしませんが、エミュレーションを実行する実行手順の構造に注意を払います。 最適化のために、「if then else」ではなく「case」を使用し、さらに多くのコマンドを使用してアセンブラで使用できるため、エミュレーションがさらに高速化されます。 そのようなコマンドの例を次に示します。
op [ 3 ] = 1の 場合
始める
tmp : = Vreg [ op [ 1 ] ] ;
tmp2 : = Vreg [ op [ 2 ] ] ;
asm
mov ah 、 [ tmp ]
またはああ、 [ tmp2 ] ;
mov [ tmp ] 、 ah ;
終わり ;
Vreg [ op [ 1 ] ] : = tmp ;
使用: = true ;
コード送信者: =コード送信者+ 2 ;
終わり ;
これで、エミュレーションのすべての瞬間を考慮して、独自のCHIP-8エミュレーションを作成できます。 私の記事を楽しんでいただき、それが役に立てば幸いです。 読んでくれてありがとう。
中古品:
CHIP-8 / SCHIPエミュレーター
デイヴィッド・ウィンター(HPMANIAC)ウィキペディアモジュールソース:
ソースコードユーザー
nsinrealから招待状を受け取ったのは彼女のため
でした。
送信できないため、この
記事の公開の1時間前に表示された
記事を「コピーアンドペースト」と見なさないようにという要求。 モジュールの内容やエミュレーションへのアプローチが異なるため、お互いの記事が表示されなかったことを事前に感謝してください。