現在、ホームサーバーを含む1つに複数のインターネット接続が存在することは珍しくありません。 City lokalka、ADSL、3Gモデム...このネットワークにローカルローカルおよび外部仮想(VPN)を追加し、トラフィックのルーティング、インターネット上の異なるチャネル間のトラフィックのバランス(必要な場合)、非稼働からの切り替えを行う必要のあるインターフェイスの活発な混合を取得します労働者のためのチャネル(彼らが落ちるとき)。
インターネット上の投稿から判断すると、この状況に遭遇したほとんどの人は、これがどのように設定されているかについて非常に悪い考えを持っています。 linuhでは、実際にルーティングを管理することは非常に複雑でわかりにくいことに注意してください-進化的な開発と(部分的な)互換性のサポートの結果です。 特定のかなり複雑な例で
マルチホームサーバーのルーティングを構成する原理を説明します。サーバーには、3つの物理ネットワークインターフェイス(1つはホームLAN、2つはADSLモデム)、2つのADSL接続(ブリッジモードのADSLモデム、したがってpppd同じサーバーを別のプロバイダー(1つは静的IP、もう1つは動的IP)に追加し、さらに会社のサーバーにVPNを追加します(合計6つのインターフェース)。
トピックは非常に複雑であるため、資料を理解するには、少なくともルーティング(デフォルトのルートとゲートウェイ)、ファイアウォール(パケットのラベル付け、接続追跡、異なるテーブルとファイアウォールチェーンとルーティング間の通信)、pppd(ip-up /スクリプトip-down)およびIPおよびTCPプロトコル。
一般的な構成と問題の説明
したがって、3つのネットワークインターフェイスがあります。
- eth0 (192.168.0.2)、最初のADSLモデム(192.168.0.1)に接続
- eth1 (192.168.1.2)、2番目のADSLモデム(192.168.1.1)に接続
- eth2 (192.168.2.1)、ホームLAN(192.168.2.x)に接続され、このLANのインターネットゲートウェイです
ADSLを介してインターネット接続が確立されると、さらに2つのインターフェイスが表示されます。
- ppp0 (ssss)、最初のADSLモデムから最初のプロバイダーへの静的IP(8Mbps)
- ppp1 (dddd)、2番目のプロバイダーへの2番目のADSLモデムを介した動的IP(2Mbps)
そして、少なくとも1つのインターネット接続がある場合、もう1つのインターフェイスが追加されます。
- tun0 (vvvv)、VPN経由の会社のサーバーへの静的IP
以下を実装する必要があります。
- ADSL接続の存在下でのサーバーおよびホームLANからインターネットへのアクセス
- チャネル幅に応じて、両方が利用可能な場合、ADSL接続間のトラフィックのバランスをとる
- VPNは、ADSL接続を介して発生する必要があり、両方が利用可能な場合は、最初のプロバイダーを介して(チャネルが広い)
- メールは最初のプロバイダー経由で送信する必要があります(私のドメインにバインドされた静的IPがあります)
- 統計情報を含むWebサイトへのアクセスと2番目のプロバイダーのコントロールパネルは、2番目のADSLを通過する必要があります(プロバイダーは外部からWebサイトへのアクセスを閉じています)
したがって、これらの接続はすべて設定済みであり、一度に1つを上げ下げすることができます。ADSL接続が1つだけ上げられれば、すべてが正常に機能します。マルチホーミングのみを設定します。
理論のビット
以前のルーティングを構成するために(そして今-単純な場合)、routeコマンドが使用されました。 あなたはそれを忘れることができます-そのような設定はipコマンド(iproute2パッケージから)によってのみ行われ、ipとrouteの両方を同時に使用しても問題はありません。 routeコマンドの時点では、
ルーティングテーブルは1つでした。 現在、いくつかのルーティングテーブルがあります(そのうちの1つ、
メインはrouteコマンドが機能するものと同じです)。 これらのテーブルは、/ etc / iproute2 / rt_tablesにリストされています。
それらの内容は、
ip route list table <table name>コマンドで表示できます。
ローカルテーブルには興味深いものは何もありません-利用可能なインターフェイスを介したリンクローカルルーティングルールがあります。 表
mainで、ルーティング
の基本ルール。
デフォルトのテーブルは
デフォルトでは空です。
unspecテーブル(
allとしてもアクセス可能)には、既存のすべてのテーブルからのすべてのルーティングルールが表示されます。
新しいテーブルを作成するには、このファイルに名前を追加する必要があります(より正確には、名前でテーブルにアクセスする場合にのみ必要です。番号で参照することもできます)。
複数のルーティングテーブルがあるとすぐに、使用するルーティングテーブルを選択できるメカニズムも必要になりました。これは
ルーティングルール(RPDB、ルーティングポリシーデータベース)と呼ばれ
ます 。 このメカニズムの主な利点は、(
routeコマンドと
ip route ...のように )宛先アドレスだけでなく、他の基準(ソースアドレス、インターフェイス、tos、fwmark、...フィールド)に基づいてルーティングを選択できることです。 これは次のように機能します:「
ip rule ...コマンドを使用して」「criteria-> routing table」の形式で任意の数のルールを指定します。 特定のパケットに対してルーティングルールの条件が一致し、指定されたルーティングテーブルに(宛先アドレスに基づいて)このパケットのルートが存在する場合、そのパケットが実行されます。 そうでない場合は、ルーティングルールに戻り、他のオプションを確認します。 デフォルトのルーティングルールは次のようになります。
最初の列は優先順位です。 優先度が高い順にルールがスキャンされます。 これらのルールは、最初に
ローカルテーブル(link-localはルーティングルール)、次に
メインテーブル(通常は
routeコマンドで制御)、およびデフォルトルートが通常指定されている場所(つまり、 これにより、ルーティングルールの実行が停止し、(デフォルトルートが
mainで指定されなかった
場合 )
デフォルトテーブル(デフォルトでは空)になり
ます 。
以下は、このエコノミーをすべて使用して、ホームLANアドレス192.168.2.100からのパケットがデフォルトルーティングとは異なるルーティングルールを使用して処理される方法の簡単な例です(最初のADSLモデムと最初のプロバイダーを介してインターネットにのみアクセスを許可します) ):
ファイアウォールについて少し説明します。 これにより、ルーティングに影響を与えることもできます。
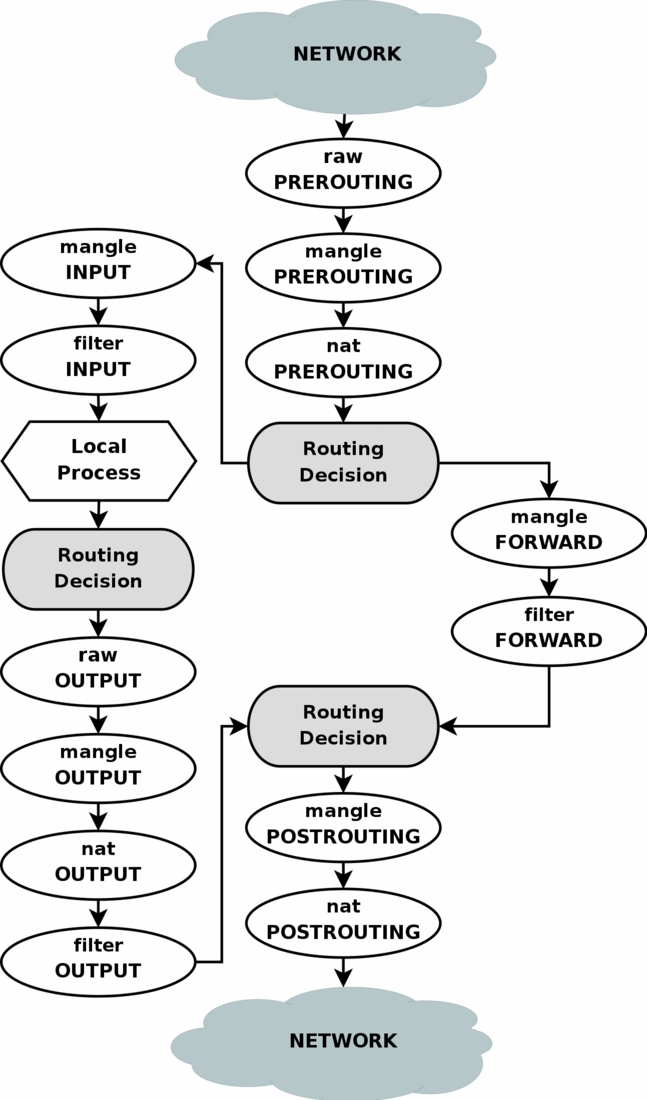
図からわかるように、たとえばローカルアプリケーションからのパケットは、「ルーティング決定」ステージを2回通過します。 私が理解しているように、これはパッケージの作成時に初めて発生し、発信インターフェイスとその発信IP(ファイアウォールルールを確認できるので、パケットがファイアウォールに到達したときに既知である必要があります)を決定するために、さらに再ルーティングしますファイアウォールのMANGLEチェーンを実行した後にこのパケットのが計算されます。これにより、パケットのフィールドが変更され、このパケットのルーティングに影響する可能性があります。
私たちの場合、ファイアウォールを介したルーティングに影響を与える最も簡単な方法は、MANGLEチェーンのパケットfwmarkフィールドを変更し、ルーティングルールを使用してパケットfwmarkフィールドの値に基づいてルーティングテーブルを選択することです(このため、異なるルールで複数のルーティングテーブルを作成する必要があります-たとえば、 1つのプロバイダーを介して1つのテーブルにデフォルトルートを登録し、別のプロバイダーを介して別のテーブルにデフォルトルートを登録します。
ルーティングのセットアップ:最終結果
この最終結果へのパスは、一部の場所では厄介です(pppdおよびopenvpn機能の
バグではリラックスできないため)。以下に説明します。 それまでの間、取得する必要があるものを見てみましょう。
2つのプロバイダー間のバランス
まず、両方のプロバイダーの同時使用を構成し、負荷分散を8対2(それぞれ、チャネル幅)の比率で行います。 この方法は、個々の宛先アドレスごとにルーティングを選択します。 接続が最初に最初のプロバイダーを通過した場合、そのパケットはすべて最初のプロバイダーのみを通過し、
しばらくの間このアドレスへのすべての接続はこのプロバイダーのみを通過します。 接続ではなくパッケージによる分散の方法は異なり、1つのプロバイダーへの接続が複数ある場合にのみ機能します。
なぜなら カーネルは、宛先アドレスとそれらに選択されたデフォルトルーティングとの間の接続に関する情報をキャッシュするため、このキャッシュをリセットする必要がある場合があります(カーネルが再び8から2の確率で、この宛先アドレスのデフォルトルーティングを選択するように):
特定の接続の手動チャンネル選択
なぜなら 場合によっては、どの外部チャネルを介してパケットを送信するかを制御する必要があります。デフォルトルートを使用して、チャネルごとに個別のルーティングテーブルを作成します。
次に、ファイアウォールを使用して目的のfwmark値を設定し、目的のルーティングテーブルを選択できるように、ルーティングルールを追加します。
値0x4 / 0x4(値/マスク)は、0wマスクのビット(つまり、3番目のビットのみ)がfwmarkフィールドから取得されることを意味し、値0x4と一致する必要があります。 つまり fwmarkでは、vpnテーブルのルールが機能するために3番目のビットを設定する必要があり、残りのビットは関係ありません。 このアプローチにより、ファイアウォールのfwmarkにいくつかのビットを設定できるため、このパッケージにいくつかの「適切な」チャネルが示されます。 これらのチャネルの優先度(すべて使用可能な場合)は、ルーティングルールの優先度によって決まります。 チャネルが利用できない場合、対応するルーティングテーブルは引き続き表示されますが、デフォルトルートがないため、次のルーティングルールに戻り、次の適切なチャネルが見つかります。
これらのコマンドはすべて、まだ何にも影響していません-fwmarkファイアウォールは公開しないため、テーブル
isp1 、
isp2および
vpnのルーティングルールは機能しません。デフォルトでは、ルーティングは以前のように
メインテーブルによって決定されます。
これで、統計情報と2番目のプロバイダーのコントロールパネルを使用してWebサイトへのアクセスが2番目のADSLを通過することを示すことができます。
これらのルールがサーバーからの送信パケットだけでなく、ホームLANからのパケットでも機能する必要がある場合、これらのすべてのルールをOUTPUTチェーンだけでなくFORWARDチェーンでもファイアウォールに追加する必要があります。
同じインターフェースからの返信
発信接続についてのみ話している限り、これはすべて正常に機能します。 しかし、サーバーがあります...そしてサーバーへの着信接続があります。 静的IP ssss(最初のプロバイダーのチャネル)で作成されたWebサイトがあるとします。 サーバー<ip_site_isp2>の2番目のプロバイダーの管理者が(lynxを介して)Webサイトを検索したい場合、何も機能しません! 実際、彼は最初のプロバイダーのチャネルを介して(Webサイトの)IP ssssに要求を送信し、サーバーは2番目のプロバイダーのチャネルを介して(したがって、ddddアドレスから)この要求に対する応答を送信します。もちろん、SNAT / MASQUERADEは
ppp0 、
ppp1 、および
tun0インターフェースを通過するパケット用に構成され
ます )-作成したファイアウォール設定に従って:2番目のプロバイダーのチャネルを介して<ip_site_isp2>のアドレスにパケットを送信します。 要求をssssアドレスに送信した管理Webブラウザーは、ddddアドレスから応答を受信することを想定していないため、これは機能しません。
この問題を解決するには、パケットが最初に受信されたインターフェイスからの着信接続への応答を保証する必要があります。 残念ながら、これを行うには、ファイアウォール(conntrack)で接続追跡を使用してfwmark(connmark)を設定する必要があります。 残念ながら-conntrackは大きく複雑でバグの多いゴミですが、選択の余地はありません。 これは次のように行われます(上記のルールを設定する前に、これらのルールを最初にファイアウォールに追加する必要があります)。
ここで、着信パケット(より正確には、それらが属する接続)を、それらが送信されたインターフェースに従ってマークします。 さらに、fwmark値(より正確には、connmark)は、これらのパケットへの応答を送信する必要があるルーティングテーブルに対応するように選択されます(1,2,4-isp1、isp2、vpnの場合、8-これはfwmarkルーティングルールでは使用されません、t .e。このfwmarkを持つパケットは、
メインテーブルの通常のルーティングに従って送信されます-これはローカルネットワークからのパケットに非常に適しています)。
このラベル付けは、着信パケットのルーティングには影響しませんが、これにより、このラベル付けを実際にこの接続のすべてのパケットに関連付けることができます。 発信パケット。 さらに、同じ接続の発信パケット(着信パケットへの応答)については、fwmark値を着信パケットと同じ値に設定し、この接続に関連付けられています(より正確には、connmark値をfwmarkにコピーします)。 結果として、発信パケットにfwmark値が設定されている場合(0ではない)、次のすべてのfwmarkインストールルールを使用して発信チャネルを選択することはできません-このパケットは、着信パケットが到着したのと同じインターフェイスを介して送信する必要があるため、停止します(-j ACCEPT )
合計すると、問題のステートメントに応じた正しいファイアウォール構成オプションは次のようになります。
ルールとルーティングテーブルの設定とともに、必要なものを正確に取得します。 これらの設定をダイナミクスでどのように設定するかは、チャネルが上下する可能性があるという事実を考慮に入れたままです。
最終結果への厄介な道
正直なところ、この記事はかなり大きなものであることが判明したので、私がやろうとしていたip-up / downスクリプトで混乱することはありません。 誰かがコメントを求めたら-後で記事に追加してください。 次に、上記の設定の実装中に発生した主なタスクと問題について簡単に説明します。
- pppd自体は複数のデフォルトルートを上げる方法を認識していないため、nodefaultrouteオプションを使用して実行し、/ etc / ppp / ip- {up、down}スクリプト(またはこれらのスクリプトから自動的に呼び出されるユーザースクリプト-異なるディストリビューション)でハンドルを使用してデフォルトルートを設定する必要があります構成が異なります)。
- チャネルは一度に1つずつ上昇するため、ip-upスクリプトが呼び出された時点で、デフォルトルートが存在しない場合があり(このチャネルが最初に上昇した)、このチャネルを介して通常の単一デフォルトルートを設定する必要があります。 または、デフォルトルートが別のチャネルを介してすでに存在し(このチャネルは2番目に上がった)、単一のデフォルトルートを(ネクストホップとウェイトを含む)ダブルルートに置き換える必要があります-これはメインルーティングテーブルで行われます。
- また、このチャネルを介して、対応するルーティングテーブル( isp1またはisp2 )に単一のデフォルトルートを追加する必要があります。
- ip-downスクリプトでは、論理的に、逆の操作を行う必要があります(2つのチャネルの1つが切断された場合、残りのチャネルを介して二重デフォルトルートを通常のものに置き換える必要があり、最後のチャネルが切断された場合、デフォルトルートを完全に削除する必要があります)...しかし、実際にはpppd自体デフォルトルートを削除します 。たとえそれが二重だったとしても、またpppdがnodefaultrouteオプションで起動されたとしても(これはおそらくpppdのバグです)。 したがって、ip-downのタスクは逆です。それが唯一のチャネルではなかった場合、残りのチャネルを通る通常のデフォルトルートを上げます。 残念ながら、これも簡単ではありません。pppdは、デフォルトのルートをip-downスクリプトと並行して削除します。 競合状態が発生します ! そのため、ip-downでは、まずpppdがデフォルトルートを削除するまで待機してから、再度ルートを上げる必要があります。
- ルーティングを変更した後(ip-upとip-downの両方)、 ip route flush cacheを作成しても問題はありません。
- もう1つ:両方のチャネルが同時に上昇/下降することができ、それらのip-up / downスクリプトも同時に機能します。 ほとんどの場合、これにより競合状態が発生し、デフォルトルートが破損します。 :)したがって、 これらのスクリプトの開始時にロックを提供し、一度に1つだけが動作するようにする必要があります。これを行う最も簡単な方法は、runitパッケージのchpstユーティリティまたはdaemontoolsパッケージのsetlockユーティリティを使用することです。
- openvpnは、カスタムアップ/ダウンスクリプトを呼び出すこともできます...
- アップでは、このチャネルを介して単一のデフォルトルートを対応するルーティングテーブル( vpn )に追加する必要があります。
- ルーティング(上下両方)を変更した後、 ip route flush cacheを作成しても問題はありません。
- ダウンでは、この構成では何も必要ありません(vpnテーブルからのデフォルトルートは、このチャンネルが落ちたときにカーネルによって自動的に削除されます)が、何かを行う必要がある場合、upスクリプトはrootとして実行され、ユーザーopenvpnからダウンすることに注意してください(またはopenvpn設定で指定したもの)(これもおそらくバグです)、そしてopenvpnユーザーは通常、ルーティングを管理するのに十分な権限を持っていません(sudoを使用する必要があります)。