
あなたにとってCouchDBとは何ですか? おそらく、人気のあるNoSQLテーマに少しでも興味がある人ならだれでも一般的な詳細を知っているでしょう。これは、JavaScriptで記述されたmap / reduceリクエストを備えたとてもいいおもちゃです。あなたはそれがフォールトトレラントだと聞いた、あなたはまったく壊れません。 通常、これはこれを超えることはありません。その結果、CouchDBはあらゆる種類のMongoDB、Cassandra、Hadoopなどとともにdeliciousに送信されます。
最近まで、現在のプロジェクトのアーキテクチャを再考し(リレーショナルデータベースに額を置いて)、マップ/縮小できるドキュメントデータベースに移行する緊急の必要が生じるまで、ほぼ同じ意見でした。 CouchDBを詳しく調べてみたところ、このクラスで他に類を見ないものであり、言及された製品と同等にすべきではないことに気付きました。 CouchDBに組み込まれているアイデアは非常に概念的であるため、Webアプリケーション開発のアイデアを根本的に変えることができます。
私はカットの下で私がとても感銘を受けたものについて話そうとします。
すぐにCouchDBを使用した経験がある場合は、自分が「口ひげを生やしている」可能性が高く、この記事はあなたには向いていないと思います。 しかし、残りについては、読んだ後、Couchの開発者が推奨するように、そのような赤いソファに横たわってリラックスする欲求と機会が表示される場合があります。
CouchDBの周りの誇大広告は最近までやや落ち着いていると言わなければなりませんが、このデータベースの言及はハブ上でめったにスリップしませんが、TwitterはCouchDB 1.0のリリースとCloudantがクローズドベータテストフェーズを離れるというニュースで文字通り爆発しました(これについてはお話します)詳細は以下をご覧ください)。 検索では、このイベントは実際にはハブでカバーされていなかったが、MongoDB 1.6の出力は別の投稿として注目されたと述べています。 この不正を修正する必要があります。CouchDBの挿入が遅く、メモリとプロセッサの消費が非常に多い生のアルファとして記憶している場合、これはすべて過去のものであることを忘れるからです。 今日では、手頃な価格の商用サポートと、たとえばBBCなどの企業による生産での実際の使用を備えた生産準備の整ったシステムです。
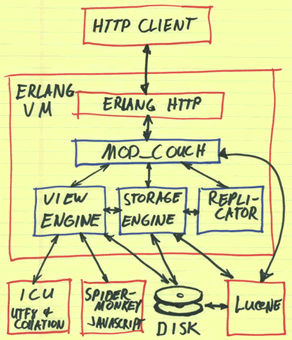
必要に応じ
てプロジェクトのWebサイトで参照できる主な機能については詳しく説明しません。 この製品を詳しく調べることに決めたまで、私には明らかではなかったことについて話そうとします。その結果、この製品に十分な注意を払わなかった一方で、多くの時間と神経細胞を節約できました。
マップ/削減
誰かに何かを驚かせることは難しいようです。 多くのNoSQLデータベースは、厳密に定義されたスキームを持たないデータへのアクセスのこの特定のパラダイムを使用します。 加えて、JavaScriptを使用してmap / reduce関数を記述することも驚くべきことです。 最初の印象は、データベース内の
各ドキュメントに対して少なくとも
map()実行する必要があるため、ゆっくりと怖がるべきだということです。 さらに、SpiderMonkeyエンジンの速度はV8とはかけ離れています。 キャッチは何ですか?
鋭い目で見ると、実際には、CouchDBはその純粋な形式でmap / reduceではなく、いわゆる 増分マップ/削減。 全体的な考え方は、CouchDBはそのビュー(いわゆるビュー
map()や
reduce()などの関数を実行した結果)を毎回計算しないということです。 これは、新しいビューに最初にアクセスしたときにのみ行われます。その後、結果は穏やかにインデックス付けされ、ドキュメントIDはノードの追加情報(および中間更新の結果)で必要なキーのB +ツリーに落ち着きます。 その後、すべてが簡単です。新しいドキュメントがデータベースに追加されると(または古いドキュメントが変更されると)、
map()が1回呼び出され、その後インデックスツリーに配置されます。 つまり インデックス全体を再計算する必要はありません。ツリーは単純に増分的に完成します。
結果が必要な場合、Couchは事前に計算済みのものを提供するだけで、
map()実行してドキュメントを再クロールする必要はありません。 ほとんどのデータベースが行うように、検索を高速化するために複数の個別の列にインデックスを付けるのとは対照的に、すべてのクエリ結果を一気にインデックス付けしました。 クエリを「実行」する必要がないMySQLを想像してください。単一のインデックスからすべての結果をすぐに取得できます。
頭に浮かぶ唯一の類似物は、Oracleのような「大規模な」RDBMSからのマテリアライズドビューですが、はるかに軽量です。 結果のインデックスのみが保存され、必要な値のみが保存されることを忘れないでください-マップ/リデュース結果のみがインデックス化されるため、冗長性は多くのインデックスを持つ通常のデータベースと比べてそれほど大きくありません-このクエリのコンテキストで必要なデータは、すべての列。 はい、現在、この方法が約束する可能性に比べて、ネジは安価です。
もっと力が必要©
map()が基本的に新規/変更された各ノードに対して一度だけ実行されるという事実は非常に興味深いです。 これにより、一度行ったとにかく、新しいドキュメントに対して非常に重い操作を実行できます。 また、組み込みのJavaScriptインターフェースでオーバークロックされていないように見える場合、CouchDBの別の興味深い機能がポップアップします。実際、特定の言語に関連付けられておらず、Viewサーバーの形式で抽象化を使用しています。 つまり 好みのプログラミング言語のビューサーバーを接続し、Pythonで
map()および
reduce()を書き込むだけで、たとえばその豊富な標準ライブラリを使用します。
概して、外部サービス(Google Maps APIなど)を使用してデータベースに追加されたクライアントのアドレスをジオコーディングし、別の外部ライブラリとしてジオインデックスを計算するために、
map()から新しいドキュメントを直接追加する際に煩わされることはありません。 または、Sphinxでドキュメントを取得してインデックスを作成し、データベースの超高速フルテキストインデックスを取得します(Apache Luceneとの統合が十分でない場合)。 一般的に、創造性の範囲は想像力によってのみ制限されます。
さらに速度が必要な場合は、ビューサーバーインターフェイスがシャベルのように単純であり、CouchDBのビューがまったく同じドキュメントであるか、特別なIDを持つデザインドキュメントであるという事実を利用して、すべてのビュー関数をCで書き換えることができます。 したがって、関数コードを直接含める必要はありません。ビューサーバーが理解できる識別子を含めて、そこに置くことができます。 一般に、データとこのデータをまったく同じデータの形で処理するための命令のこのイデオロギー的統一は、Lispのイデオロギーに似ていることは注目に値します。
map / reduceパラダイムはSQLクエリなどの機能を提供しませんが、実際には、カテゴリーでそれを考える方法を学ぶ必要があると彼らに言わせてください。 したがって、たとえば、SQLなしではJOINを実行できないというエラーは、 結合はスケーリングされません。 これはすべて意味がありませんが、文は一般的すぎます。 まず、ドキュメントにはキーと値のペアだけでなく、コレクション、その他のオブジェクト、およびJSONを使用して記述できるすべてのものを含めることができます。次に、基本的なパターンを知って、さらに複雑な結合を実装できます。 CouchDBは非常に強力であると同時に、理解可能で論理的です。
そのままのウェブ
ほとんどの選択肢とは異なり、CouchDBは主にWebアプリケーションのニーズに対応するデータベースとして設計されました。 したがって、RESTインターフェースを介したデータベースへのアクセスなど、重要なソリューションのルーツです。 はい、最も純粋な形式のHTTPにはオーバーヘッドがありますが、このソリューションがいかにエレガントであるかによって完全に相殺されます。 まず、お好みのプログラミング言語のドライバーを探す必要はありません-どのHTTPクライアントでもそれを処理できます(すべての例は、ほとんどの場合、コマンドラインから直接カールします)。 さらに、そのようなクライアントはWebブラウザである場合があります。 サーバー上のミドルウェアを使用せずにWebアプリケーションを作成できます
。Ajaxを介してJavaScriptを使用してデータベースを操作できます(たとえば、
CouchAppはCouchDBの作成者によるjQueryベースのフレームワークです)。
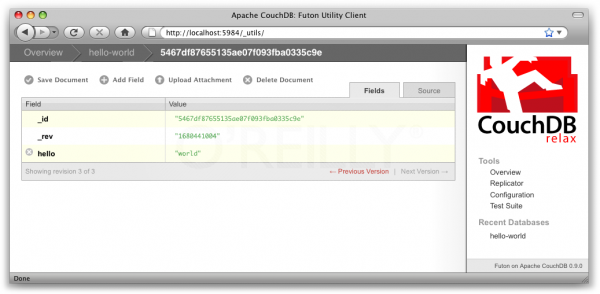
開始後、Couchは通常のHTTPサーバーのように動作します。ブラウザーを使用してCouchにアクセスし、ブラウザーのアドレスバーを使用して単純にGETリクエストを実行し、結果としてJSONを受け取ります。 CouchDBインスタンスの管理インターフェースであるFutonもすぐに利用可能になります。 ちなみに、サーバーミドルウェアなしでJavaScriptで完全に実装されており、拡張性があり、そのシンプルさにもかかわらず多くの興味深いことができます。
HTTPプロトコルが正しく実装され、キャッシュがサポートされ、Couchが304を提供するタイミングを知っていると言うことはほとんど意味がありません。同様に、ドキュメントにはバイナリ添付ファイル(attachments-(B)LOBに相当)を含めることができます。 。 デザインドキュメントには
show()および
list()含めることもできます。これにより、返された結果を必要に応じて、たとえばHTMLページに変換し、ブラウザに直接渡すことができます。 また、以前に、オンラインストアの商品からのユーザーアバターと写真を直接[リレーショナル]データベースに保存するのが悪いという意見があった場合、CouchDBではすべてが異なります-場合によっては、厳格なスキームのないデータでもより構造化されることがありますそして全体。
ご存知のように、すべての独創的なことは簡単です。 CouchDBには、なんらかの方法で処理する必要がある抽象的なデータではなく、Webアプリケーション専用に行われたこのような単純なことがたくさんあります。 最終的には、すべてが一貫しているように見えるため、どのように異なる方法で実行できるかさえ明確ではありません。
スケーリング
CouchDBは、スケールしないと言われていました。 確かに、それほど前ではありませんでしたが、半分だけでした。 まず最初に。
CouchDBの重要で最も興味深い機能の1つは、その複製です。 読者は、レプリケーションが原則としてどのように興味深いものになるのか疑問に思うかもしれません。 Kauchではすべてが間違っています;その複製はもともとデータベースの作成時に設計されました。 まず、マスターツーマスターを使用できます。これにより、インスタンスをマスター/スレーブに分割するのではなく、すべてのインスタンスを同等に機能させることができます。 「通常の」データベースでのこのようなレプリケーションの問題は、潜在的な競合です。 したがって、Couch(MVCC機能を使用)は、競合が発生すると、競合するすべてのバージョンを保存し、構成されたルールに従ってこれらの競合を解決する方法を認識します(またはこの問題をアプリケーションに委ねます-使用方法は想像力に依存します)。 レプリケーション自体は、CouchDB REST APIからURLをプルすることになります(またはFutonを使用すると、別のデータベースのURLを入力してボタンをクリックするだけです)。これはすべて複雑です。
輸送中に食べて、Nexus OneでTwitterに何かを書いて(CouchDBはAndroidの携帯電話でもMaemo / MeeGoでも完全に機能するとは言いませんでした)、トンネルに入ります-接続失われます。 アプリケーションを安全に使用し続けることができます。これにより、接続が戻ったときに、自転車を発明することなく、新しいメッセージをマージして、1つのAPI呼び出しで記述した内容を入力できます。 たとえば、Ubuntu Oneを使用する場合、すでにこの方法でCouchDBを使用しています。

しかし、トピックから気を散らさないようにしましょう。 このようなレプリケーションは確かに優れています(特にCouchDB HTTPの性質を考慮すると、通常のバランサーをKauchyクラスターの前に置くことができ、心配する必要はありません)が、これは「実際の」スケーリングではありません。 レプリケーションとリレーショナルデータベースは(それほどエレガントではありませんが)拡張できますが、シャーディングはどうですか? 結局、誰もがクラスター上のデータを汚し、ノードを追加するだけで、速度を落とすことなく、使用可能なディスク容量、最大負荷、ピークユーザー数などを増やすだけです。 CouchDBは、すぐにこれを行う方法を知りません。 またね しかし、これは時間の問題です。
しかし、
Cloudantはできます。 Cloudantは、数日前にベータテストを完了した新しいサービスであり、現在ではすべての人が利用できます。 これは、CouchDBがデータベースだけでなくミドルウェアにも対応できることを考えると、CouchDBデータベース(Amazonのクラウド上)、さらにはアプリケーション全体のホスティングです。 みんなはCouchDBに用意された可能性を利用し、フォーク(すぐにトランクの一部になるチャンスがあります)を開発しました。ノードの1つが脱落した場合の異なるノード。 さらに、標準APIの完全なサポートに加えて、Cloudantでは、別のmap / reduceの結果に応じてmap / reduceを実装でき、さらに多くの興味深い機能があります。
すべてのコードが開いているため、プライベートクラウドでCloudantを選択して使用できます。 また、
無料のアカウント(ドキュメントの古いリビジョンを考慮せずに最大250メガバイトのディスク領域)を登録し、CouchDBをライブで試すことができます。 布団。
きょう
7月のCouchDBはバージョン1.0に成長しました。開発者は、CouchDBがその安定性と本番用の準備を強調しています。 Cloudantは、CouchDBコミュニティ全体にとって画期的なリリースでもあります。 Couchを試していない場合は、時間を30分費やしてください。最終的にはより多くの時間を節約できますが、これはもちろん特定のプロジェクトの詳細に依存します。 製品は作成されたとおりに機能しますが、それ以上は機能しません。 したがって、奇跡を期待しないでください。しかし、読んだ後、開発者が推奨するように、誰かがリラックスすることを願っています(特に赤いソファがある場合)。