はじめに
今回は、神経生理学とサイバネティックス自体の両方の開発における最も重要なマイルストーンの1つについてお話したいと思います。 今、私は一方で人工ニューラルネットワークを訓練するための最初の作業ルールの定式化について、他方で生物の学習の秘密に近づこうとすることについて話している。
今日は、Hebb仮説の初期形式からその直接適用に進み、人工知能システムでの学習のモデリングに使用する可能性についても議論します。
以前のトピックに対するコメントはこの記事を書くきっかけとなり、シナプス接続の強さを変えることで学習に対する姿勢を表現する必要がありました。 そのため、私は自分自身も含めてすべてを詳細に分析することに決めました。

歴史と元の文言
カナダの神経心理学者ドナルド・ヘブは、「神経生理学的仮説」の最終定式化に長い間取り組み、以前の記事でさまざまなバージョンを発表しました。 しかし、1949年にヘブの最も重要な研究である
「行動の組織:神経心理学の理論」 [1]で最終形態を獲得しました。
この本では、ヘブの仮定は次のとおりです。
「細胞Aの軸索が細胞Bを興奮させるのに十分近く、繰り返しまたは持続的にそれを発火させると、一方または両方の細胞で何らかの成長プロセスまたは代謝変化が起こり、A Bを発するセルの1つとしての効率が向上します。
」 (2002年版の62ページ)。 多くの点で不注意な解釈が考えられないほど多くの異なる種類の規則をもたらしたため、この声明は慎重に翻訳されなければなりません。 さらに、ロシア語の文献のどこにも、まさにこの定式化の翻訳が見つかりませんでした。これは元の定式化です。 上記の引用を翻訳すると、次の仮定が得られます:「セルAの軸索がセルBを興奮させるのに十分近く、繰り返しまたは絶えず興奮に関与している場合、一方または両方の細胞で成長または代謝変化のプロセスがありますエキサイティングなBのセルの1つとしてのAの効率の向上につながります。
この声明を分析し、提示された言葉遣いから推測できる主な結果を強調します。
- 因果関係 。 ヘッブの仮説の主な意味は、シナプス前ニューロンとシナプス後ニューロンの活性化の因果関係が最初に観察される場合、この接続が強化される傾向があることです(ヘブは反対の法則については何も言わない)。
- 変更の場所 。 ヘブは、この増加した接続性は、シナプスの伝導率の変化(成長プロセス)、または細胞自体の代謝特性の変化が原因で発生することを指摘しています。
- 累積的な興奮 。 ヘブが2回(定式化の開始時と終了時)に、問題のシナプス前ニューロンがシナプス後ニューロンの興奮に関与するニューロンの1つに過ぎないという事実に注意を向けているのは偶然ではありません。 神経生理学者にとって非常に理解しやすいこの声明は、数学者にとって非常に難しい。 この定式化により、彼はシナプス後ニューロンの興奮がシナプス前ニューロン1つを犠牲にしてのみ実現できないことを指摘しています(スパイクはニューロン膜の脱分極であり、シナプス前ニューロン1つが放電するとシナプス後ニューロンの脱分極につながることはありません)。 人工ニューラルネットワークのモデルでは、この事実はほとんど常に違反されます。この不一致がもたらすものについては、以下で説明します。
確かに、多くの結果がヘブの仮定から推測されますが、さらなる分析がそれらに基づいて構築されるので、上記のものは偶然に選ばれませんでした。
ANNのさまざまな解釈と応用
インターネットおよびニューラルネットワークの理論に関するさまざまな(かなり尊敬され、人気のある)教科書/書籍でも、Hebb規則の最も多様な定式化を見つけることができます。 たとえば、ウィキペディアでは、2つのヘブルール(1949年の同じ作品を参照)も提供しています。
- 最初のヘブ規則 -パーセプトロン信号が正しくなく、ゼロに等しい場合、ユニットが適用された入力の重みを増やす必要があります。
- 2番目のヘブの規則 -パーセプトロン信号が正しくなく、ユニティに等しい場合、ユニットが適用された入力の重みを減らす必要があります。
この解釈には3つの興味深い点がありますが、それらのうちの2つの存在は完全には説明できません。 これらの最初のものは、規則の分岐点です(将来、数学文学でそのような伝統の考えられる原因を示します)。 2つ目は、パーセプトロンの概念の規則の定式化における存在です。パーセプトロンの導入は、60年代のローゼンブラットの先駆的な仕事にのみ関連しています(より具体的には[2]にあります)。 3番目の機能は、2番目の機能に続く可能性が最も高いルールのかなり特殊な定式化であり、実際にそのタイプを教師による指導に変更します。 当初、ヘブの規則は自己学習の可能性を述べていましたが、この設定では出力の「正しい」値を知る必要があります。
この言葉遣いがウィキペディアでどこに登場したかという質問は、鶏肉と卵の問題に帰着します。なぜなら、今ではインターネット上の多くの場所で見つけることができ、したがって、終わりを追跡することができません。
ニューラルネットワークのほとんどの教科書では、Hebb規則はわずかに異なるが非常によく似た形式で入力されました。 彼の伝統的な記録は次のとおりです(たとえば、有名な本[3])。
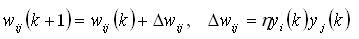
当初、このようなルールは、出力がそれぞれ0または1であるMcCallock-Pitsしきい値ニューロンに適用されました。正式なモデルでしきい値ニューロンを適用すると、Hebbルールの解釈は元の定式化に最も近くなります。
ただし、通常のしきい値ニューロンは、データ処理用のANNを構築するという観点からは非常に不便なので(
生物学的な観点からはおそらく最も現実的ですが、これはまったく異なるトピックです )、さまざまな修正がすぐに登場しました。
最初は、同じしきい値ニューロンを作成することが最も論理的でしたが、他の可能な出力:-1および1を使用しました。かなり長い間、このようなニューロンモデルが最も一般的でした。 ただし、このモデルの条件で上記のヘブ規則の定式化を適用するとどのような結果になるかを見てみましょう。 これが元のルールの分岐につながることは理解できます。 これは、シナプス前ニューロンとシナプス後ニューロンの出力が異なる場合、重み調整式の2番目の項が負の値を取るため、シナプス係数の初期値が減少することを意味します(この効果は
アンチヘブルールと呼ばれることもあります)。 前に見ることができたように、ヘブの元の仮定にはそのようなメカニズムはありません。
数学者に対するそのような仮定が受け入れられるように見えるかもしれない理由は2つあります。 第一に、元のヘブのルールを適用すると、シナプス係数が無制限に増加し、それに応じてネットワーク全体が全体的に不安定になります。 第二に、以前の多くの研究[4]では、Hebb自身が、2つのニューロンのスパイクが一致しない場合に2つのニューロン間のシナプス伝導率が低下する同様のメカニズムを示しました。 しかし、最終的な仮説を策定する際、ヘブはそのようなメカニズムを意図的に除外しました。
将来、シグモイド型の活性化特性を持つニューロンモデルの人気により、状況は悪化し始めました(図1)。 前に見たように、数学文献は、教師と教える場合のヘブ則の適用について説明しています。 教師とのトレーニングの条件下でS字型AXを導入するために、Hebbルールは修正され、生物学的妥当性から遠すぎる
デルタルールに変更されました(この記事では説明しません)。
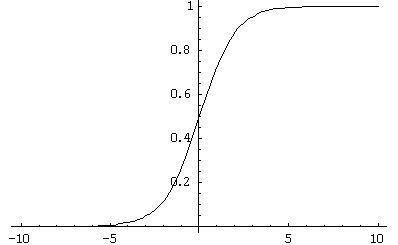 図 1.シグモイド活性化関数の例
図 1.シグモイド活性化関数の例ただし、自己学習の場合、Hebbルールの変更は行われず、出力{-1; 1}を持つしきい値ニューロンへの適用はかなり深刻な結果につながります。 実際、シグモイド関数は連続的であるため、ほとんどの場合、ニューロンの出力はゼロに等しくありません。 したがって、最初に、従来のヘブ規則を使用したトレーニングがほとんど常に発生し、次に、学習ダイナミクスがニューロンの出力値に直接比例するようになりました(0から1までモジュロ連続であるため)。 後者はかなり強い仮定であり、神経生理学的な観点から、私が知る限り、誰もテストしたことがありません。 それにもかかわらず、技術的な問題では、この手法は結果をもたらすため、誰もがこれに目をつぶった。 ただし、シグモイドニューロンの元の定式化でヘブルールを定式化すると、次のようになります。
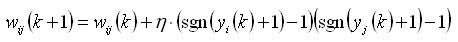
もちろん、将来、スパイクニューロンの出現と一般化されたSTDPルールにより、状況はわずかに改善されましたが、現時点でもスパイクニューロンモデルを使用する専門家はほとんどいません。 したがって、位置の根本的な変化について話す必要はありません。
ヘブのルールとトレーニング
おそらくあなたの多くは、ヘブの規則が訓練されているので、名前のパラドックスについて考えるでしょう。しかし、タイトルのタイトルは偶然に選ばれませんでした。 前のセクションでは、ヘブの仮定の歴史と起源、およびこの規則の誤った解釈につながるいくつかの異なる誤解を調べました。 ここで、バイオニックAIシステムへの適用可能性の観点から、初期の神経生理学的仮説自体を見ていきます(したがって、動物/人間の学習プロセスにおける主要な役割の可能性)。
さらに、私は
3つの考慮事項を策定します。少なくともその本質は、ヘッブのルールに基づいて自己学習システムを構築する可能性(または信じられないほどの量のその修正のいずれか)を構築する可能性についての私の大きな疑問にまで削減されます。 すべての考慮事項は仮想的な状況の分析に基づいており、3番目は形式化が最も少なく、2番目は最も重要です。
考慮事項1. 因果関係の強化数学者の観点からヘッブのルールを見ると、そのアクションは実際には1つの操作に帰着します。因果関係の強化です。 最初は、この因果関係はすでに観察されているはずです。 まず、ニューロンをシナプス的に接続し、次にニューロンを同期させる必要があります(つまり、シーケンスを観察する必要があります-
シナプス前ニューロンのスパイク->シナプス後ニューロンのスパイク )。
ある種の外部環境にいるエージェント/動物が、適応型の結果につながる問題を解決するために、ヘブのルールを使用して訓練された仮想的な状況を想像してください。 これは、原因ニューロン間の興奮伝播経路のシナプス伝導性が改善されたことを意味します(脚がどこから成長するかを示すため、定式化自体が震えに陥ります)。 ヘッブのルールのみを使用した学習の可能性の最初の証明を脇に置き、実際に反対に進んでいるので、この状況を出発点として取り上げます。
ここで、環境が多少変化し(実際の生活で最も一般的な状況)、エージェント/動物が以前に学習した方法で適応的な結果を達成できないと仮定します。 これは、エージェントが何らかの再トレーニングまたは再トレーニングを必要とすることを意味します。 同時に、シナプス伝導は、学習した動作を簡単に実装できるように調整されます。 そのような状況での再トレーニングはかなり困難です。状況が変化したにもかかわらず、訓練されたニューロンがチェーンに沿って活性化され、すべてにもかかわらず、以前の動作が実行され、結果の達成に至らないためです。
考慮事項2. 習得した知識の喪失シナプス伝導の変化によるトレーニングがまだ発生していると仮定します。 しかし、そのようなトレーニングは、必然的に情報(以前に取得した環境に関する情報)の損失につながり、それはネットワーク全体に分散されます。 これは、重み係数の空間がネットワークのすべての「知識」が格納されているフィールドであると想像すると理解しやすいため、このフィールドを変更すると、新しい「知識」は追加されず、蓄積されたすべての知識が上書きされます。
これは最も重要な考慮事項であるため、ここでより詳細な例が必要です。 そのため、私はジェラルド・エーデルマンの研究室で、いわゆる
モリス迷路で開発されたDARWINロボット[5]の挙動を検討し
ます 。
モリスの迷路におけるマウスまたはラットの行動の研究は、以下からなる標準的な生物学的実験の1つです。 不透明な液体が入ったプールがあり(たとえば、水でミルクを染めることができます)、プールの側面には、マウスが見たり方向付けに使用できる図面があります。 プールの特定の場所には、マウスが見つけて逃げることができる隠されたプラットフォームがあります-ownれることはありません。 マウスはプールに投げ込まれ、しばらく泳ぎ、プラットフォームを見つけて脱出するか、沈み始めます(実験者が救助します)。 一連の実験の後、マウスはプールの側面にあるランドマークを使用し始め、かなり短時間でプラットフォームを見つけます。 このような迷路の模式図を図に示します。 2。
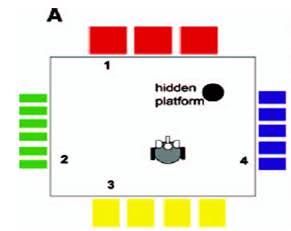
図 2.モリスの迷路の概略図
DARWINロボット自体の構造は非常に複雑です。いくつかの元の構造(制御ニューラルネットワークは合計90,000ニューロン)に加えて、いくつかの実際の脳領域とその接続をシミュレートします。 ロボットのトレーニングは、特別な方法で修正されたヘブの規則のために発生することを知ることが重要です。
ロボットはモリッサのラビリンスに配置され、側面の図面に案内されてプラットフォームを見つけることを学習します。 さらに、その結果、DARWINはプラットフォームを見つけることをすばやく効果的に学習します。 さらなる議論のために、そのような実験の連鎖を提示する必要があります。
ロボットがプラットフォームを効率的に見つける方法を学習したとしましょう。 この学習プロセスを
実験1と呼びます。 プラットフォームを別の場所に移動し、再びロボットをモリスの迷路に配置します(これは
実験2になります)。 ある時点で、ロボットはプラットフォームが移動したことを「理解」し、再び検索を開始します。 この考察の議論の始めに、我々は一時的にヘッブ則による再訓練が基本的に可能であると仮定したことを想起し、
実験2のロボットがうまくやったことを証明し、プラットフォームを効果的に見つけることを再び学んだと仮定します。
最も興味深い部分は、プラットフォームを別の場所に移動して
実験3を試すときに始まります。 この場合、状況は
実験2と同様になります。ロボットはプラットフォームが移動したことを再び認識し、新しい位置を見つけます。 すべてがうまくいくように見えますが、この場合に最も重要なのは決定プロセスです。 DARWINの場合、
実験2と
実験3の解決プロセスはまったく同じです。 ロボットは、
実験1で知識を取得したことすら覚えていません。これは、それらが実際にはもう存在しないためです。
実験2のプロセスで上書きされたためです。
実際の動物の場合、
実験3の決定プロセスの状況
は完全に異なります。 最初は、動物が
実験2で学習した場所でプラットフォームの検索を開始することは明らかです。 ただし、そこに彼女が見つからない場合、まずプラットフォームが
実験中にあった場所を確認します
1 。 この最も重要な機能は、非常に多くの状況で非常に適応性が高いため、動物はその生活の過程で遭遇します。 ちなみに、DARWINシステムに関するこのようなチェックは、私ではなく、スーパーバイザーによって考案されました。
習得した知識の喪失は、ヘブの規則の修正の必然的な結果です。
考慮事項3. ヘブ規則の反射性本質的に、Hebbルールは事後の仮説です。 その応用は、ニューロンの連鎖の連続的な活性化の簡素化をもたらします。 これは、反射アークとトレーニングの概念に非常に似ており、このアークのトレーニングとそれに沿った信号の通過の促進に基づいています。 同時に、カントは、人間の心の学習能力に直接関係するメモで、彼の時代にそのような結論に達しました。
私の観点からは、Hebbルールの適用(Hebbルールのみが適用されている場合は明確にしたい)が集中トレーニングにつながり、最終的に適応結果を達成できるかどうかは非常に疑わしいです。 ルールだけでなく、私が見たどの分析でも、目的の概念そのものが欠落しています。
脳(およびすべてのニューロン)が反応的な実体ではなく活動的な実体であるという事実を明確に理解していることを考えると、動物および人間の訓練におけるヘブの仮説の役割の修正は避けられません。
どうする
この状況から抜け出す方法は何ですか?
私の答えは、学習のモデリングに対するまったく新しいアプローチを開発する必要があるということです。 現時点では、Hebbルールとその多くの修正が、本質的にトレーニング/自己学習の生物学的に適切な唯一のモデルです。 もちろん、これは偶発的なものではありません。Hebbが提唱した神経生理学的仮説には強固な生物学的基盤があるからです。
ヘブの仮説に対する私の批判すべてについて、動物の脳でそれを観察しないと言うつもりはありませんでした。 もちろん私たちは観察し、多くの有名な作品がこれに捧げられています。 学習におけるこの仮説の役割について批判的な見方をしたかっただけです。
私は、シナプス伝導の変化が確かに効果的な学習を提供する主な要因の1つであると考えています。 ただし、このプロセスとヘブの仮説自体は、はるかに複雑な要因、つまり
脳組織の全身レベルによって制御されます。 さらに、仮定自体は、システムレベルのメカニズムの全体性の限られた結果にすぎません。
おわりに
このレビューでは、ヘブの仮説の歴史から、トレーニングの実施における彼の能力と展望の評価に進みました。 ヘブの規則メカニズムを学習の最前線に置いた場合に生じる問題のいくつかに注意を向けようとしました。
繰り返しますが、今までにないほど、完全に異なる、より複雑な適応(目的)トレーニングのメカニズムを策定する緊急の必要性に直面しています。 今日、条件付きで体系的と呼ばれるこのレベルがどのように機能するかはわかりません。仮説のみが存在します。 シナプス伝導率の変化とニューロン自体の変化によってシステムレベルがどのように保証されるかは、さらに複雑な問題であり、すぐには答えが得られない可能性があります。 そのため、現時点では、バイオニックAIの分野の専門家は、より抽象的なルールを導入する必要があります(とにかくニューロンとシナプスを直接操作しながら)。これは、学習、記憶、意思決定の全身メカニズムをモデル化します。
参照資料
[1] 。 ヘブ、DO
行動の組織化:神経心理学理論 。 ニューヨーク(2002)(
オリジナル版-1949 )
[2] 。 Rosenblatt F.神経力学の原理:パーセプトロンと脳メカニズムの理論。 ワシントンDC:スパルタンブックス(1962年)。
[3] 。 Osovsky S.
情報処理用ニューラルネットワーク (2002)
[4] 。 ヘブ、DO条件付けられ、
無条件の反射と抑制 。 非公開MA論文、マギル大学、モントリオール、ケベック、(1932)
[5] 。 Krichmar JL、Seth AK、Nitz DA、Fleischer JG、Edelman GM「空間ナビゲーションと
皮質と海馬の相互作用をモデル化した脳ベースのデバイスの原因分析。」
ニューロインフォマティクス 、2005年
。V。3 . No. 3. PP。 197-221。