先週、OCR SDKの次のバージョンをリリースしました。これは、さまざまなアプリケーションにテキスト認識テクノロジーを組み込むための製品です。 何年もの間、SDK-FineReader Engine(簡潔にするためにFREと呼びます)の形で適切なテクノロジーをリリースすること
により 、カスタムボックス付きFineReader'aの生産に
マグカップとTシャツの流通を追加しました。
カットの下で、以前のバージョンと比較した新しいFREの改善点について説明します。
新しいバージョンを開発するとき、私たちはほぼ正確に、より速く、より機能的なオリンピックの目標を設定しました。 FineReader Engineの第9バージョンでは、精度と機能に積極的に取り組んでおり、この点で大幅な改善を行っています。
10番目のバージョンでは、速度が前面に出ました。 リリースまでに、ほとんどのヨーロッパ言語でFast Mode(特別な高速認識モード)を1.5〜2倍高速化しました。 同時に、速度を上げることは品質を犠牲にして行われず、高速モードでの認識精度は平均して同じレベルのままでした。 ロシア語の場合、速度は平均44%増加しました。 これらの数値は、主な種類のオフィス文書を含むパッケージの内部テストの結果として得られたものです。
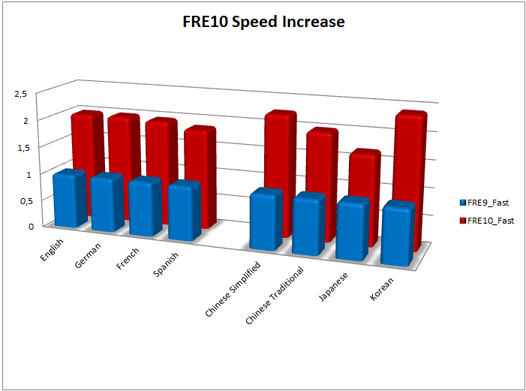 FRE 9.0(2008年10月21日リリース)の結果と比較した各言語の相対的な速度の向上
FRE 9.0(2008年10月21日リリース)の結果と比較した各言語の相対的な速度の向上アジアの主要言語である中国語、日本語、韓国語では、精度が依然として主要な目標でした。 これらの言語で文書を認識する際のエラーの数は、平均で30〜40%減少しました。 さらに、グラフは速度の大幅な増加を示しています。
それほど明らかではない多くの改善が行われました。
新しい二値化 -白黒のカラー画像とグレースケール画像の変換。 これは、文書を認識用に準備するために必要な手順です。指紋でしわのあるシートのスキャンで薄いテキストを認識できるかどうかによって異なります。 二値化ははるかに良くなりました。これは、速度が向上しても品質が低下しなかった理由の1つです。
Camera OCR TM-撮影されたドキュメントのテキスト認識の品質を改善するための特別な変換のセット。 それらの中には:
-角度を付けて撮影したときに現れる台形歪みの補正、
-写真のグリースの除去-三脚なしで撮影する場合の特徴的な欠陥、
-ISOノイズの平滑化-暗い場所でカメラの高感度で表示される写真の多くのカラフルなドット。
ADRT TMの新機能が
登場しました -見出し(ドキュメントマップ)と目次(TOC)の構造を見出し、スタイルの自動作成、写真のキャプションの認識、写真とキャプションをキャプチャして単一のオブジェクトに結合するための特別なスタイルを設定します。
非常に重要な改善点は、製品の理解可能性、アクセシビリティを改善し、製品との連携を促進することです。 OCR SDKは、多数のパラメーターを構成できる巨大なAPIを備えた多機能ツールです。
ユーザーはさまざまなタスクを解決します。 誰かが図書館から書籍をPDFにスキャンするシステムを開発し、コンテキスト検索の可能性、誰かがバーコード認識に基づいてEDMSに文書を自動的に登録し、誰かが認識機能を使用して独自のデータ抽出技術を開発していますテキスト検証。
明らかに、さまざまなタスク-SDKの機能と技術の品質に対するさまざまな要件。 ある場合には、そもそも結果として生成されるPDFファイルの品質とサイズであり、別の場合では、テキストまたは
バーコードの認識の精度です。 したがって、さまざまなタスクを解決するには、さまざまな設定が必要です。
製品のセットアップを簡素化するために、特定の問題を解決するための最適なパラメーター値を含む多くの
プロファイルを作成しました。 この考え方は、製品の主要な「視覚」に反映されています。

適切なプロファイルを選択するだけで、作業を開始できます。
さらに、製品証明書が大幅に改善され、より構造化され、完全になりました。
これらすべてがFineReader Engineをより速く簡単にアプリケーションに統合し、さらに良い認識結果を得るのに役立つことを願っています。
Linux用のFRE10バージョンを約1年後にリリースする予定です。
セミョン・セルグニン
テクノロジー製品部門