Tanimoto係数を使用して、同じ好みを持つ人々を検索する
「集合的な心のプログラミング」という本の演習を解き、この本で言及されているアルゴリズムの1つの実装を共有することにしました(第2章-演習1)。
初期条件は次のとおりです。重要な評価を持つ辞書があるとします。
評論家= { 「リサローズ」 : { 「スーパーマンリターンズ」 : 3.5 、 「あなた、私とデュプリー」 : 2.5 、 「ナイトリスナー」 : 3.0 } 、
「ジーンシーモア」 : { 「スーパーマンリターンズ」 : 5.0 、 「ナイトリスナー」 : 3.5 、 「あなた、私、デュプリー」 : 3.5 } }
スコアが高いほど、映画が好きになります。
たとえば、一方の評価に基づいて他方の映画を推薦できるようにするために、批評家の関心はどれだけ似ているかを計算する必要があります。
係数谷本-2つのセットの類似度を記述します。 インターネット上で、計算式のいくつかのオプションを見つけました。 そして、私は次のことに専念することにしました。
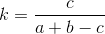
ここで、kはタニモト係数(0から1までの数)であり、1に近いほどセットは類似しています。
aは、最初のセットの要素の数です。
bは、2番目のセットの要素の数です。
cは、2セットの共通要素の数です。
次に、2人の批評家の評価を比較する必要があります。
1つのポイントを明確にしたいだけです。 2つのセットで共通の要素と見なすべきものは何ですか? 現在の形式で評価を提示しても、同様の関心を持つ人々を正確に特定できないことは明らかです。 実際、本質的に、このアルゴリズムの3.5と4.0の同じ評価は完全に異なる数値です。 そのため、評価オプションの数が2〜3以下の場合、Tanimoto係数を使用する必要があります(たとえば、「気に入った、気に入らなかった」、「お勧め、見なかった、お勧めしません」)。評価に次の変換を適用しました。評価が3未満の場合、映画は高評価されませんでした(評価は-0になります)。それ以外の場合は評価されました(評価は-1になります)。 この形式のデータは、実験に適しています。
def prepare_for_tanimoto ( critics_arr ) :
arr = critics_arr。 コピー ( )
arrの評論家向け :
arr [ critic ]の映画の場合:
arr [批評家] [映画] < 3の場合 :
arr [評論家] [映画] = 0
その他 :
arr [評論家] [映画] = 1
返却
出力では、次の辞書を取得します。
評論家= { 「リサローズ」 : { 「スーパーマンリターンズ」 : 1 、 「あなた、私とデュプリー」 : 0 、 「ナイトリスナー」 : 1 } 、
'Gene Seymour' : { 「スーパーマンリターンズ」 : 1 、 「ナイトリスナー」 : 1 、 「あなた、私とデュプリー」 : 1 } }
次に、2人の評論家の評価の類似度係数を計算する関数を作成します。
def tanimoto ( critics_arr、critic1、critic2 ) :
arr = prepare_for_tanimoto ( critics_arr )
a = len ( arr [ critic1 ] )
b = len ( arr [ critic2 ] )
c = 0.0
arr [ critic1 ]の映画の場合:
if arr [ critic1 ] [ film ] == arr [ critic2 ] [ film ] :
c = c + 1
koef = c / ( a + b-c )
戻りケーフ
tanimoto関数の機能を確認してください。
>>>プリントタニモト(評論家、「ジーンシーモア」、「リサローズ」)>>> 0.5私の意見では、結果は正しいです。 各評論家の評価数が増えると、類似度係数の計算の精度が向上することに注意してください。
評価のデータベースがあれば、人々の興味の類似性の係数を計算し、タニモト法に関する推奨事項を提示し始めることができます。
サンプルテキストは
こちらからダウンロードできます。
著者のウェブサイトの本からすべての例の全文をダウンロードできます。 そこには、重要な評価を持つより完全な配列があります。
Source: https://habr.com/ru/post/J104901/
All Articles