Habrを含む多くの記事で、ネットワークサービス(デーモン)のアーキテクチャを構築するさまざまな方法が言及され、説明されています。 ただし、数万の同時接続やギガビットトラフィックで動作するデーモンを作成および最適化した経験のある著者はほとんどいません。
ほとんどの著者はドキュメントに煩わされることさえないので、通常、そのような記事では、すべての情報は特定の噂と噂の再語に基づいています。 これらのうわさはWebをうろつき、Wikipedia、Habrahabrおよびその他の評判のよいリソースをヒットします。 結果は「
あなたはおそらく冗談だろう、Dahl、またはNode.jsなのか」のような反対派
です (著者の句読点は保持されます):それは基本的に本質的に真実ですが、不正確さでいっぱいで、いくつかの事実上の誤りを含み、いくつかのあいまいなオブジェクトを描写します短縮。
「現在、有効なポーリングの実装は* nix-systemsでのみ利用可能」などのフレーズが豊富な記事をバイパスすることは困難でした(poll()は* nixを除くどこかにあるように)。 この投稿は、彼の記事で尊敬されている
イニクリンの誤りを説明する解説として始まりました。 執筆の過程で、最初から主題を説明する方が簡単であることがわかりました。これは実際には別の投稿として行います。
私のエッセイでは、カバーの内訳やいくつかの未知のトリックはありません。異なるオペレーティングシステムで実際にこれがどのように機能するかをチェックした人による、異なるアプローチの長所と短所を単に説明しています。
啓発したい人のために、猫へようこそ。
ネットワークデーモンのTK
まず、ネットワークサービスが正確に何をすべきか、そして一般的には何が問題なのかを理解する必要があります。
すべてのデーモンは、ネットワーク接続を受け入れて処理する必要があります。 TCP / IPプロトコルスタックはUNIXから発展し、このOSは「すべてはファイル」という教義を公言しているため、ネットワーク接続は、ファイルを操作するための標準OS機能によって開かれ、閉じられ、読み書きされる特別なタイプのファイルです。 モーダル動詞「can」に注意してください。「理論的に」という言葉と組み合わせて、現実を非常に正確に表します。
したがって、まず、デーモンはシステム関数socket()を呼び出し、次にbind()、listen()を呼び出し、その結果、特殊なタイプの「listening socket」のファイルを受け取ります。 これらの機能のパラメータとデーモンのさらなるアクションは、使用されるトランスポートプロトコル(TCP、UDP、ICMP、RPDなど)に大きく依存しますが、ほとんどのオペレーティングシステムでは、最初の2つのみをバインドできます。 この記事では、最も人気のあるTCPプロトコルを例として見ていきます。
リスニングソケットはファイルですが、発生する可能性があるのは、「着信接続要求」などの定期的に発生するイベントです。 デーモンはaccept()関数を使用してこの接続を受け入れることができます。この関数は新しいファイルを作成しますが、今回は「TCP / IPネットワークソケットを開く」タイプです。 おそらく、デーモンはこの接続から要求を読み取り、それを処理して結果を送り返す必要があります。
同時に、ネットワークソケットは既にほぼ通常のファイルです。最も標準的な方法では作成されていませんが、少なくともそこからデータの読み取りと書き込みを試みることができます。 ただし、ファイルシステムにある通常のファイルとは大きく異なります。
*すべてのイベントは、実際には非同期に発生し、期間は不明です。 最悪の場合の操作には数十分かかる場合があります。 一般的には。
*ファイルとは異なり、接続は、最も予期せぬ瞬間に「自分で」閉じることができます。
* OSは常に閉じた接続を報告するわけではありません。「デッド」ソケットは30分ハングすることがあります。
*クライアントとサーバーの接続は異なる時間に閉じられます。 クライアントが新しい接続を作成してデータを「送信」しようとすると、データの複製が可能になり、クライアントが誤って書き込まれた場合、失われる可能性があります。 サーバーが1つのクライアントから複数の接続を開いている可能性もあります。
*データはバイトのストリームと見なされ、文字通り1バイトの部分で受信できます。 したがって、たとえばUTF-8文字列と見なすことはできません。
*ネットワーク上のデーモンによって提供されるもの以外のバッファはありません。 したがって、1バイトでもソケットに書き込むと、デーモンが数十分ブロックされる可能性があります(上記を参照)。 さらに、サーバー上のメモリは「非ゴム」であり、デーモンは結果の生成速度を制限できる必要があります。
*エラーはどこでも発生する可能性があり、デーモンはそれらをすべて正しく処理する必要があります。
開いているすべての接続「額」でループを作成すると、最初の「ハング」接続は他のすべての接続をブロックします。 はい、数十分です。 そして、デーモンのさまざまなモジュールの相互作用を整理するためのさまざまなオプションがあります。 写真を参照してください:
 免責事項
免責事項 :図は、現実に対応しない擬似言語コードを示しています。 多くの重要なシステムコールとすべてのエラー処理コードは、明確にするために省略されています。
2.マルチプロセスアーキテクチャ
接続が相互に影響しないようにする最も簡単な方法は、接続ごとに個別のプロセス(つまり、プログラムの個別のコピー)を開始することです。 この方法の欠点は明らかです-別のプロセスを開始すると、非常にリソースを消費する操作になります。 しかし、ほとんどの記事では、このメソッドが同じApacheで使用されている理由を説明していません。
そして、すべてのOSでのプロセスは、システムリソース(メモリ、オープンファイル、アクセス権、クォータなど)のアカウンティングの単位であるということです。 シェルやFTPなどのオペレーティングシステム用のリモートアクセスデーモンを作成する場合、ファイルのアクセス許可を正しく考慮するために、ログインしている各ユーザーに代わって個別のプロセスを開始するだけです。 同様に、異なるユーザーの数百のサイトが1つの「物理」ポートで同時に共有ホスティングサーバー上でスピンしています。また、一部のホスティングユーザーのサイトが他のユーザーのデータにアクセスできないように、プロセスにApacheが必要です。 プロセスを使用しても、実際にはApacheのパフォーマンスには影響しません。
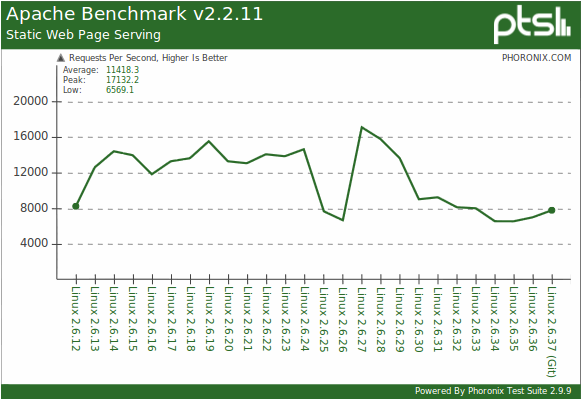
グラフ上-Linuxカーネルのバージョンに応じた、1秒あたりの静的ファイルへの処理済みリクエストの数。 多いほど良い。
テストベンチ:Core i7 970、3Gb DDR3、Nvidia GTX 460、64GB OCZ Vertex SSD。
出典:Phoronix。あなたの悪魔が毎秒17000ファイルを与えることを望みます。
デーモンのユーザーがオペレーティングシステムに登録されていなくても、サービスのセキュリティ要件が高くなっている場合でも、ユーザーごとに個別のプロセスを割り当てることは非常に合理的なアーキテクチャソリューションです。 これにより、悪意のあるユーザーが他のユーザーのデータの読み取りやデーモンプロセスの破壊を許可するバグをデーモンに見つけたとしても、他のユーザーのデータへのアクセスを取得またはブロックすることはできません。
最後に、各プロセスには独自のアドレス空間があり、異なるプロセスが相互のメモリ使用を妨げることはありません。 この利点が一部説明されている理由
3.マルチスレッドアーキテクチャ
ストリームは、共有メモリ、システムリソース、アクセス権を持ち、スタックが異なる最も簡単な「プロセス」です。 つまり、スレッドには共通の動的変数、グローバル変数、静的変数がありますが、ローカル変数は異なります。 マルチプロセッサおよび/またはマルチコアシステムでは、同じプロセスの異なるスレッドを物理的に同時に実行できます。
マルチスレッドアーキテクチャは、パフォーマンスとメモリ消費のためにセキュリティと安定性が犠牲になるマルチプロセスアーキテクチャに似ています。
パフォーマンス後のマルチスレッドアーキテクチャの主な利点は、オープン接続処理アルゴリズムのシーケンスと同期です。 つまり、アルゴリズムは、最初の部分の図に示されているとおりに表示および実行されます。 最初に、必要な時間だけデータがソケットから読み取られ、次に処理されます。この場合も、この処理に必要な時間だけ結果がクライアントに送信されます。 同時に、結果の送信を速すぎると、ストリームはwrite()関数によって自動的にブロックされます。 処理アルゴリズムは単純で、少なくとも最高レベルでは簡単です。 これは非常に大きなプラスです。
同時接続数が比較的少ない場合、マルチスレッドアーキテクチャが最適です。 しかし、実際に多数の接続(1万など)がある場合、スレッド間の切り替えには時間がかかりすぎます。 しかし、これでもマルチスレッドアーキテクチャの主な欠点ではありません。
そして主なことは、スレッドが独立しておらず、お互いをブロックできる(そしてブロックする)ことです。 これがどのように発生するかを理解するには、例を考えてください。
式の値を計算する必要があるとしましょう
a = b + c;、ここで、a、b、およびcはグローバル変数です。
通常のシングルスレッドの状況では、コンパイラは次のマシンコードのようなものを生成します。
a = b; // MOV A, B
a += c; // ADD A, C
マルチスレッドバージョンでは、このコードは使用できません。 別のスレッドは、最初の命令と2番目の命令の間でbの値を変更できます。その結果、誤ったaの値を取得します。 aが常にb + cに等しいと見なされる場合、「フローティング」エラーを再現するのは非常に困難です。
したがって、マルチスレッドバージョンでは、コードは次のように使用されます。
lock a;
lock b;
lock c;
a = b;
a += c;
unlock c;
unlock b;
unlock a;
ここで、lockおよびunlockは、変数へのアクセスをロックおよびロック解除する
アトミック操作です。 これらは、変数が別のスレッドによって既にロックされている場合、lock()操作がその変数の解放を待機するように配置されます。
したがって、2つのスレッドが同時に操作a = b + cおよびb = c + aの実行を開始すると、それらは互いに永遠にブロックされます。 この状況はクリンチと呼ばれ、クリンチの検索と解決は、並列プログラミングの別の「痛い主題」です。 しかし、クリンチがなくても、スレッドは、ロックを迅速に解除しないと、非常に長い期間互いに停止する可能性があります。
さらに、アトミック操作は、RAMバスとRAM自体の排他制御によって物理的に実装されます。 キャッシュではなくメモリを直接操作すること自体が非常に遅く、この場合、他のすべてのサーバープロセッサのすべてのコアの対応するキャッシュラインが無効化(リセット)されます。 つまり、最良の場合でも、ロックがない場合、各アトミック操作は十分に長い時間実行され、他のスレッドのパフォーマンスが低下します。
しかし、悪魔のつながりはほとんど独立しているため、どこから共通変数を取得できるのでしょうか?
しかし、どこから:
*新しい化合物の一般的なキュー。
*データベースまたは同様のリソースにアクセスするための一般的なキュー。
*メモリ割り当てのリクエストの一般的なキュー(yes、malloc()およびnew()はブロッキングを引き起こす可能性があります);
*一般ログ(ログファイル)および統計計算の一般オブジェクト。
これらは最も明白なものです。
場合によっては、共有変数を省く方法があります。 たとえば、ストリームの1つに「ディスパッチャー」の機能を付与すると、新しい接続のキューのブロックを拒否できます。これにより、巧妙な方法でタスクが配られます。 特別な「非ブロッキング」データ構造を適用できる場合があります。 しかし、一般的に、マルチスレッドアーキテクチャのデッドロックの問題は解決されていません。
4.ノンブロッキングアーキテクチャ
理想的には、アプリケーション内のスレッドの数は、プロセッサコアの数とほぼ同数である必要があります。 これを実現する1つのメカニズムは、非ブロッキングI / Oです。
ノンブロッキングI / Oは、ほとんどの最新のオペレーティングシステムにインストールできる単なるファイルアクセスモードです。 通常の「ブロッキング」モードで読み取り関数がプログラマーが注文した数だけファイルからバイトを読み取り、この読み取りが進行中にそれを引き起こしたスレッドを「無効」にすると、非ブロッキングモードでは同じ読み取り関数はファイルから読み取りませんが、キャッシュ、このキャッシュ内のバイト数と同じ数になり、その後、トラフィックをストリーミングしたりブロックしたりすることなく、すぐに戻ります。 キャッシュが空の場合、非ブロッキング読み取り()は0バイトを読み取り、システムエラーコードをEWOULDBLOCKに設定し、すぐに戻ります。 それでも、これは通常の同期関数への通常の同期呼び出しです。
特に英語版ウィキペディアでは、非ブロッキング同期入出力が「非同期」と呼ばれる混乱が、明らかに、Linux OSのあまり好奇心のない謝罪者によって引き起こされています。 このオペレーティングシステムでは、カーネル2.6.22-2.6.29まで長い間、非同期I / O関数がまったくありませんでした(そして、現在でも必要なすべてのセットがなく、特に非同期fnctlはありません)。このOSでのみ、彼らは誤ってノンブロッキング同期関数を「非同期」と呼んでいました。これは多くの古いLinuxマニュアルで追跡できます。
非同期I / Oについては次のパートで詳しく説明しますが、ここでは非ブロッキング読み取りおよび書き込み関数の使用に焦点を当てます。
実際の条件では、ノンブロッキングread()コールの95%がそれぞれ0バイトを読み取ります。 OSカーネルのこれらの「アイドル」呼び出しを回避するために、すでに読み取りおよび/または書き込み可能な接続のリストから選択するようオペレーティングシステムに要求できるselect()関数があります。 一部の* nixオペレーティングシステムには、poll()と呼ばれるこの関数のバリアントがあります。
poll()の詳細:この機能は、POSIX標準の次のバージョンの要件として登場しました。 Linuxの場合、poll()は最初に標準C言語ライブラリ(libc> = 5.4.28)の関数として、通常のselect()のラッパーとして実装され、しばらくしてからカーネルに「移動」されました。 たとえば、Windowsでは、通常のpoll()関数はまだありませんが、Vistaからは、 アプリケーションの移行を簡素化するための特定の緩和策があり、Cのselect()のラッパーとしても実装されています。
これらすべての革新がもたらすものを示すグラフを共有せざるを得ません。 グラフ上-カーネルのバージョンに応じて、ループインターフェイスを介して10 GBのデータをポンピングする時間。 少ないほど良い。 ソースは同じで、テストベンチは同じです。
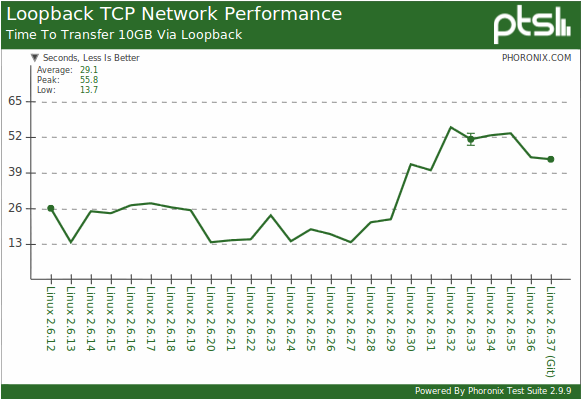
いずれにせよ、select()には一定の制限がありますが(特に、1つのリクエストのファイル数)、この関数とノンブロッキングI / Oモードを使用すると、すべての作業を30行のコードでオペレーティングシステムに転送し、単純に処理することができますあなたのデータ。 ほとんどの場合、非ブロッキングI / Oを担当するスレッドは、1つのコアの処理能力の数パーセントしか消費しません。 すべての計算を実行すると、オペレーティングシステムのカーネルの内部スレッドは10倍以上「消費」されます。
スレッド数の削減に戻りましょう。
そのため、デーモンには「接続」クラスのオブジェクトが多数あり、各接続オブジェクトに正しい順序で適用する必要がある一連の操作があります。
マルチスレッドアーキテクチャでは、接続オブジェクトごとに個別のスレッドが作成され、操作は目的の順序でブロックモードで自然に実行されます。
ノンブロッキングI / Oアーキテクチャでは、操作ごとにストリームが作成され、異なるオブジェクトに順次適用されます。 これは、MMXやSSEなどのSIMD命令に少し似ています。1つの命令が複数のオブジェクトに同時に適用されます。 必要な一連の操作に耐えるため(つまり、最初に結果を計算してから送信する)、スレッド間のジョブキューがプロセスの共有メモリに作成されます。 通常、キューはリングバッファに基づいて作成されます。この場合、「非ブロッキング」方式で実装できます。
実際のネットワークサービスでは、要求の読み取りと結果の送信の間に、アプリケーションサーバー、DBMS、またはその他の「重い」操作の呼び出しを含む、かなり複雑な分岐処理アルゴリズムと、すべての分岐、ループ、すべてのステップでのエラー処理などがあります。 同時に実行されているスレッドの以前の未知数に従ってそれをすべて分解し、さらにプロセッサコアの負荷がほぼ同じになるように-これは、システムプログラミングのすべての側面をマスターする必要がある最高レベルの開発者スキルです。 ほとんどの場合、それははるかに単純にします。read()とwrite()の間のすべてを別のストリームに囲み、開始N =このストリームのコピーのコアの数です。 そして、リソースを奪い合ったり、DBMSを殺したりするクリンチメンバーのために松葉杖が発明されました。 並列スレッド。
5.非同期I / O
非同期関数と同期関数の違いを理解していない場合、簡単にするために、非同期関数は、たとえば隣接するカーネルで呼び出したプログラムと並行して同時に実行されると想定できます。 一方では、呼び出し側プログラムは計算の終了を待つ必要がなく、何か役に立つことができます。 一方、非同期関数の結果の準備ができたら、何らかの方法でこれについて顧客プログラムに通知する必要があります。 このメッセージが発生する方法は、さまざまなOSで非常に異なる方法で実装されます。
歴史的に、Windows 2000は非同期I / Oをサポートする最初のOSの1つでした。
典型的なユースケースは次のとおりです。たとえば、数十秒以内に大きなファイルをロードするシングルスレッドアプリケーション(マルチコアプロセッサはありませんでした)。 read()の同期呼び出しで見られたインターフェースと「クロック」をフリーズする代わりに、非同期バージョンではメインプログラムフローが「ハング」せず、ロードプロセスと「キャンセル」ボタンを表示する美しいプログレスバーを作成することができます。
「プログレスバー」を実装するために、特別なOVERLAPPED構造が非同期Windows I / O関数に渡され、そこでOSは現在の転送バイト数を記録します。 プログラマーは、この構造体の内容を自分にとって都合の良いときにいつでも読むことができます-メインのメッセージ処理サイクル、タイマーなどで。 同じ構造で、操作の最後に、その最終結果が記録されます(転送されたバイトの合計数、エラーコード(ある場合)など)。
この構造に加えて、独自のコールバック関数を、操作の終了時にオペレーティングシステムによって呼び出されるOVERLAPPEDへのポインターを取る非同期I / O関数に転送できます。
どこにいてもプログラムを中断することによるコールバック関数の真の正直な非同期起動は、同じカーネル上でプログラム実行の2番目のスレッドを開始することと区別できません。 したがって、コールバック関数を非常に慎重に記述するか、アクセスロックに関するすべての「マルチスレッド」ルールを共有データに適用する必要があります。これは、シングルスレッドアプリケーションでは非常に奇妙です。 シングルスレッドアプリケーションでの潜在的なエラーを回避するために、Windowsは生のコールバックをキューに入れます。プログラマーは、これらのコールバックを実行するために中断できるプログラム内の場所を明示的に指定する必要があります(WaitFor *オブジェクトファミリー関数)。
上記の非同期I / Oスキームは、WindowsNTカーネルの「ネイティブ」です。つまり、他のすべての操作は何らかの方法で実装されます。 氏名-IOCP(入力/出力完了ポート)。 このスキームは、鉄から理論的に最大の性能を達成できると考えられています。 Windowsでの本格的な作業用に設計されたデーモンは、IOCPに基づいて開発する必要があります。 詳細については、
MSDNのIOCPの概要を参照してください。
Linuxでは、通常のOVERLAPPED構造の代わりに、aiocbとの弱い類似性があります。これにより、操作の完了の事実のみを判断でき、現在の進行状況は判断できません。 カーネルは、ユーザー定義のコールバックの代わりに、UNIXシグナル(はい、殺すシグナル)を使用します。 シグナルは完全に非同期で到着し、すべての結果が生じますが、リエントラント関数の作成に慣れていない場合は、特殊なタイプのファイル(signalfd)を作成し、非ブロッキングを含む通常の同期I / O関数を使用して着信信号に関する情報を読み取ることができます。 詳細については、
man aio.hを参照してください。
非同期I / Oを使用しても、デーモンのアーキテクチャに制限は課せられません。理論的には任意です。 ただし、原則として、いくつかのワークフローが(プロセッサコアの数に応じて)使用され、その間にサービス接続が均等に分散されます。 接続ごとに、有限状態マシン(FSM)が構築およびプログラムされ、イベント(コールバック関数および/またはエラーの呼び出し)の出現により、このマシンが1つの状態から別の状態に移行します。
まとめ
ご覧のとおり、それぞれの方法には長所、短所、用途があります。 セキュリティが必要な場合-プロセスを使用し、高負荷下で速度が重要な場合-ノンブロッキングI / Oで、開発の速度とコードのわかりやすさが重要な場合は、マルチスレッドアーキテクチャが適しています。 非同期I / Oは、Windowsの主な方法です。 いずれにせよ、自分でI / Oを操作するコードを書かないでください。 このネットワークには、すべてのアーキテクチャとオペレーティングシステム用の無料の既製のライブラリがあり、何十年もの間、ほとんど輝きを放っています。 ほとんど-あなたの場合、あなたはまだあなたの条件にねじれ、ファイルし、調整する必要があるためです。 インターネットは複雑なものであり、万能な解決策はありません。
デーモンは1つのI / Oで十分ではなく、要求処理中により複雑な「ギャグ」が発生する可能性があります。 しかし、誰かが興味を持っている場合、これは別の記事のトピックです。
参照資料
1.
C10Kの問題 、ヒント
o_O_Tyncに感謝2.
libevライブラリのヘルプ 。大量の入出力(eng)のさまざまなメカニズムの説明が付いたおいしい部分です
。tipsaterenkoに感謝します
。3.
よくある質問echo ru.unix.prog4. UNIXライブラリ
libaioの概要5.
2.6.12から2.6.37までのコアパフォーマンステスト 。