皆さんの多くは、DC Oversan-Mercuryシステムのアーキテクチャについて多くのことを語ったHabréのブログの記事でOverseanに精通しています。
Skalaxiクラウドのアーキテクチャについても話しましたが、主に
専門の会議で、レポートやプレゼンテーションの多くはすでに時代遅れであり、無関係になっています。
Skalaxiのサブシステムとアーキテクチャソリューションの多くはあなたにとって興味深いものになると思い、それらについて話すことにしました。 コンピューティングリソースの保証量の問題は常にバケツにあるため、CPUリソース割り当てのトピックから始めることにしました。興味のあるお客様、批評家、ブロガーから定期的に聞いています。
リソースの分布を理解するには、少なくとも一般的な観点から仮想化システムのアーキテクチャを検討し、詳細を検討する必要があります。 この記事では、クライアント仮想マシン間のCPU処理能力の分配がどのように機能するか、各CPUが各VMに対してどれだけの時間を取得し、どのように達成されるかについて説明します。
定義
Skalaxiチームの私たちは、このテキストでいっぱいになるいくつかの用語と定義に慣れているため、ここにリストします。
- VRTホストまたは単にVRT-1つの仮想化ホスト、ユーザー仮想マシンをホストする物理サーバー。
- VMはユーザーの仮想マシンであり、仮想サーバーです。 クラシックホスティングの世界では、このことの非常に単純なバージョンはVPSと呼ばれます。
他の多くの定義と用語は、資料を提出する際に以下に開示されます。
一般的なXenアーキテクチャ
XenのCPUスケジューラについて話し始める最も簡単な方法は、Xenハイパーバイザーの基本的な動作原理についての短い紹介です。 Xenは、Xenを使用して物理リソースにアクセスする1つの物理マシン(ホスト)で複数のゲスト仮想マシンを実行できる準仮想化システムです。 この場合、ゲストVMを起動するための2つのオプションがあります。準仮想化(PV)モード。仮想マシンが変更されたカーネルで起動し、Xenで実行されていること、またはマシンが変更されていないOSから起動し、実際の動作をエミュレートする特別なプロセスがエミュレートされる場合鉄(qemu-dm)、このモードはHVMと呼ばれます。
Xenでは、ゲスト仮想マシンはドメインとも呼ばれます。 ハイパーバイザーを管理する特権ドメイン(Dom0)が1つあり、他のゲストマシンがI / Oで動作し、他の仮想マシンが管理されます。 ゲスト仮想マシン(DomUs)は、Dom0のロード後にのみ起動できます。

一般に、Xenハイパーバイザーのアーキテクチャについては、すでにハブで多くのことが議論されています。
CPUプランニングと配電
したがって、ハイパーバイザーが実行されているハードウェアレベルがあり、その上で複数のゲスト仮想マシンが実行されていることがわかります(Dom0およびDomU)。 これらの各仮想マシンはCPUにアクセスできます。 どのように構成されていますか?
各仮想マシンは、いわゆる仮想CPU(vCPU)で動作します。これは1つのコアの仮想化表現です。 vCPUの数は、構成内またはxm vcpu-setコマンドを使用して、各仮想マシンに個別に割り当てられます。 さらに、各仮想マシン上のvCPUの数は、少なくとも1つで、ホストコアの数以下にすることができます。
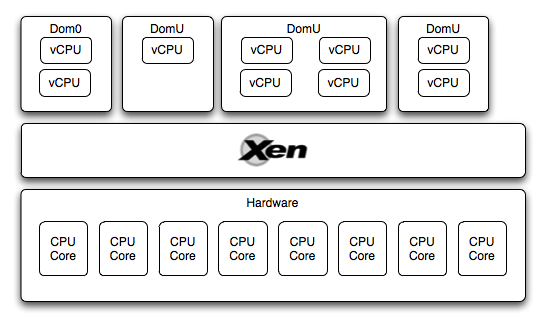
ハイパーバイザーのタスクは、vCPU間で物理CPU時間を正しく分配することであり、CPUスケジューラと呼ばれるコンポーネントがこのタスクに関与しています。 この記事の執筆中に、3つの既存のスケジューラーに関する情報と、Xenで現在デフォルトで使用されているものを置き換える特定のスケジューラーの説明を見つけました。 しかし、この記事の目的は、これがクラウドでどのように機能するかを伝えることです。そのため、クレジットスケジューラーについて説明します。
検索する場合、Habr
でこのテーマに関する記事を見つけることができます。 したがって、ここではスケジューラの基本原則を簡単に要約し、その作業のアルゴリズムをもう一度理解します。
- スケジューラは、キュー内のオブジェクトとしてvCPUを使用します。 XenはVM内のタスクを計画せず、vCPUランタイムのみを制御し、ゲストOSがVM内のプロセスを処理します。
- 仮想マシンは、vCPUの数を1からコアの合計数に制限できます。
- 仮想マシンには、vCPUのCPU割り当ての優先度を制御する重みが割り当てられます。
- キャップ-1つの物理コアの割合としてのCPU時間の最大割り当て量の人為的制限。 1つのコアの20から20%、400から4コアがすべて、0から無制限。
- Dom0はこれらのパラメーター(およびvCPU)も使用し、その重量と上限パラメーターに従ってプロセッサー時間を受け取ります。
アルゴリズムの詳細:
- Xenの各CPUには、vCPUが入る独自のキューがあります。 キュー内のvCPUにはクレジットレベル(数値)とステータス(オーバー/アンダー)があり、仮想コアがこの配信期間にCPUの一部を受信したか、まだ受信していないかを示します。
- 請求期間-特定の期間。外部スレッドがすべてのvCPUのクレジット数を再カウントし、クレジット数(ポイント)に応じてステータスを変更します。
- CPUタイムスライス-CPUが1つのvCPUに提供する期間(デフォルトでは30ミリ秒)。

1つのタイムスライスを解決すると(vCPUがブロックされ、アイドル状態になり、逆に目覚めた)、CPUはキュー内の次のvCPUに移動します。 同時に、CPUタイムスライスを消費して、ポイントがvCPUアカウントから差し引かれます。ポイントの数が負になると、vCPUはステータスを受信し、キューに置き換わります。 キューのステータスがvCPUを使い果たした場合、CPUは他のコアのキューでそのようなvCPUを探します。 彼がそこにいない場合、彼は次のvCPUを探します。自分自身とステータスがオーバー状態になっている他のvCPUを探します。これにより、vCPUをもう少し発行できます。 このアプローチにより、システムおよび他の仮想マシンのCPUがアイドル状態の場合、かなり低いウェイトのvCPUでさえもプロセッサー時間を受け取ることができ、VMがプロセッサー時間を受け取ることも保証されます。
Skalaxiでの構成
Skalaxiでは、Xenハイパーバイザーを使用し、ユーザー仮想マシンはVRTホストで実行されます。 独自の開発であるCloudEngineは、マシンを実行するVRTホストを選択します。 適切なホストを選択するためのアルゴリズムはアロケーターと呼ばれますが、VMスロットの数に基づいて簡単な方法で説明すると、クラウドが「正しく」パッケージ化されるように適切な場所を選択します。マシンはより多くのリソースを取得しました(上記の段落で、物理ホストが100%満杯でない場合、CPUは保証された最小値よりも多く割り当てられると言いました)。
SLESは、cap = 0およびweight = 16384でdom0で起動されます。次に、CloudEngineによって送信されたクライアントVMがdomUで起動され、RAMの1メガバイトあたり1つの重み単位に基づいて重みが割り当てられます。 したがって、VRTホストが完全にロードされたときのdomU-machinesの総重量は32768です。つまり、ホストが眼球にロードされても、dom0は突然必要な場合に十分なコンピューティングリソースを取得し、ホストはdomU-machinesの重量で「チョーク」しません。
実際、dom0はほとんど常にアイドル状態であるため、dom0で若干の損失が発生しても、CPUはクライアント仮想マシン間で分散されていると想定できます。 Frank Kohlerのプレゼンテーションでは、通常モードで起動した後、dom0はCPUの最大0.5%を「消費」すると主張しています。
また、非常に重要なポイント:CloudEngineは、1つのホストでリソースの最大50%が占有されるようにマシンをクラウドに配置します。 これは非常に簡単に実現されます:クラウドが予約されていることを定期的に保証します。つまり、ホストの最大50%が低下すると、VMが他のホストに移行されて動作し続けることになります。つまり、クラウドの最大半分が占有される可能性があります。 そしてこれは、理想的には、各ホストで使用されるリソースの50%を超えないことを意味します。これにより、VMのスケーリングが容易になり(スケーリング時の移行が少なくなり)、各マシンに送られるCPUの割合が増加します。
次は何ですか
この記事では、クラウド内のVM間でCPUがどのように分散されるかについて説明しました。 以下では、これが実際にどのように機能するかを示したいと思います。 来週のパフォーマンステストを待ってください:)独立したテストを実施したい場合-書き込み、これのためのリソースを無料で提供します。
関連資料
XenでのCPUリソースの割り当てに関する資料を読みたい場合は、以下に情報を使用した情報源を示します。 他の興味深い記事を見つけたら、コメントでこれについて書いてください。
twitterを購読すると、仮想化とクラウドコンピューティングに関する興味深い資料を見つけることができます。 そして、
私たちに来て
テストしてください /
必要な機能についてのアイデアを教えてください :)