 データ重複排除
データ重複排除は、ディスクストレージ内の冗長データを検出して排除する技術です。 その結果、同じ量のデータを保存するための物理メディアのボリュームが削減されます。
データ重複排除は、過去2〜3年のデータストレージシステムの分野で最もホットなトピックの1つです。 現在のストレージシステムが保存しなければならない膨大な量のデータでは、ストレージボリュームを大幅に削減できるため、重複および同一のデータが必然的に発生することは明らかです。
おそらく最も成功したのは、ディスクバックアップシステムの分野での重複排除テクノロジーの実装(たとえば、EMC Avamar、Data Domain)ですが、NetAppは、いわゆる「プライマリストレージ」、つまりメインの「戦闘」アクティブデータストレージに重複排除を使用する可能性を最初に発表しました。彼女は実際に作業のパフォーマンスを低下させない重複排除技術を提供できたからです。
今日、私はそれがどのようにそして何のために可能であったか、そしてなぜこれまで他の人が成功しなかったかをお話ししたいと思います。
そのため、重複排除とは、ストレージディスクに保存されている重複データを排除することです。 どうやって?
「重複排除」という一般名で、一連の異なる実現はすぐに隠すことができます。 最も簡単なのは、「ファイル」レベルでの重複排除の実装です。 これは、「リンク」メカニズムを使用して「UNIXライクな」ファイルシステムに長い間実装されてきたものです。 同じ物理ブロックチェーンは、ファイルシステムの異なるポイントからアドレス指定できます。 たとえば、多くの異なるプログラムで変更せずに同じ標準ライブラリを使用する場合、同じファイルをディスク上の数十の場所にコピーする代わりに、1つのコピーを保存し、残りをリンクに置き換えます。 OSまたはアプリケーションがこのファイルのファイルシステムにアクセスすると、ファイルシステムはリンクを透過的にその単一インスタンスにリダイレクトします。
しかし、ライブラリの新しいバージョンがリリースされた場合はどうでしょうか。これは、数百バイトのコンテンツだけが異なりますが、すでにまったく異なるファイルですか? このようなメカニズムは機能しなくなります。 また、FCまたはiSCSIで動作するSANストレージなどの「非ファイル」データに対しても機能しないため、現在、リンクメカニズムまたは「ファイル重複排除」は比較的限定的に使用されています。 これで、リンク上のコンテンツの一部にリンクすることができた場合!
このようなメカニズムは、サブファイルまたはブロック重複排除と呼ばれ始めました。 標準のUNIXライクなファイルシステムのレベルで実装することはできません。その中のリンクは、ファイルのみ、およびファイル全体にアドレス指定できるためです。
すべてのNetAppストレージシステム、WAFLファイル構造に基づいて私の記事を思い出すと、NetAppが重複排除に非常に興味を持っている理由がわかります。 結局のところ、サブファイル、ブロック重複排除は、WAFLの用語では絶対に自然に実装され、「すべてがストレージユニットへのリンク」を持っています。
重複排除はどこに適用できますか?
すでにバックアップストレージについて説明しましたが、この分野では重複排除が比較的長い間使用され、正常に実行されています(多くの場合、同じ広範なファイル、大きなファイル、異なるフォルダー内のコピーを含むユーザードキュメントがバックアップに含まれ、異なるユーザー)。 しかし、他の有望なアプリケーションがあります。
それらの1つは、VMware ESX、MS Hyper-V、Xen Serverなどのサーバー仮想化環境での仮想マシンデータのストレージです。
ただし、バックアップで適切に機能する重複排除方法を使用すると、ほとんどの場合失敗します。 多くの場合そうであるように、ディスクストレージのパフォーマンスが壊滅的に低下するスペースに対して、誰も支払いを望みません。
バックアップに適したものは、プライマリストレージには適していません。
重複を排除するだけでなく、パフォーマンスに影響を与えないようにする必要もあります。
これらの仮想インフラストラクチャで重複排除を効果的にしているのはなぜですか?
最もひどい例を挙げましょう。 VMware環境にサーバー仮想化システムを展開しており、ESXサーバーデータセンターに多数のWindowsまたはLinuxサーバーがあり、それぞれが独自のタスクを実行しているとします。 もちろん、同じタイプのすべての仮想マシンは、必要なすべてのパッチ、設定、およびサービスパックとともに、参照OSを含む事前に準備された「テンプレート」から展開されます。
新しいサーバーを作成するには、このテンプレートをコピーして、個別の設定ファイル、および「ゲストOS」とそのアプリケーションのすべてのファイルを含む大きな「仮想ディスク」ファイルで構成される、既に構成および更新された新しい仮想マシンを取得するだけです。
しかし、同時に、これらの仮想マシンの数十に対して、フォルダー/ Windows / System32(または/ usr)が内部にあり、レジストリおよび構成ファイルの個々の設定が数十キロバイトだけ異なる、ほぼ完全に同一の仮想ディスクが数十個あります。
内容が形式的にほぼ同一であるという事実にもかかわらず、「C:ドライブ」を持つ各仮想マシンは、ストレージシステム上で独自の10ギガバイトを占有します。 10個の仮想マシンを乗算すると、これはすでにかなり重要な数字になります。
VDI(Virtual Desktop Infrasructure)の場合、さらに深刻な状況が発生する可能性があり、「仮想デスクトップ」の数は数百になり、それらのすべてが原則として同じOSを使用します。
仮想ディスクファイルのデータで重複排除を使用する方法は、スペース節約の結果が、「重複排除なし」で元の使用ボリュームの75〜90%に達することが多いことを示しています。
これは非常に魅力的で、多くのリスクとオーバーヘッドがなく、パフォーマンスを犠牲にすることなく、仮想マシンのイメージで以前占有されていた750から900ギガバイトのストレージを解放します。
重複排除は「サブファイル」、ブロックレベル、異なるファイルシステムで実行されるという事実により、ファイルシステムの同じ4KBブロック内に同一のコンテンツのフラグメントが含まれている場合、同一のファイルだけが重複排除できます。
重複排除は、データをディスクに書き込むときに直接実行できます。これは「オンライン重複排除」と呼ばれ、「ポストプロセス」、オフラインで実装できます。
データを受信するとすぐに発生する「オンライン」重複排除を放棄したため、何かが確実に失われます。
たとえば、1TB(900GBがゼロ)のように強く複製されたデータを書き込む場合、最初にレコード上に1TBのサイズの場所を割り当て、「ゼロで90%ゼロ」を埋めてから、重複排除プロセス中に90%このスペースは解放されます。
ただし、「オフライン」重複排除には、多くの非常に重要な利点もあります。
- 重複データを検出するために、より効率的で正確な(読み取り:低速で「プロセッサ集約型」)アルゴリズムを使用できます。 プロセッサに過負荷をかけたり、重複排除によってストレージシステムのパフォーマンスを低下させたりしないように妥協する必要はありません。
- 「オフライン」の場合、データの現在の直接記録された部分だけでなく、ストレージスペース全体の重複排除を分析および使用できるため、非常に大量のデータを分析および処理できます。
- 最後に、都合のよいときにいつでも重複排除を行うことができます。
したがって、NetAppストレージシステムがシステムの実際のディスクパフォーマンスへの影響を最小限に抑えて重複排除を行えるため、「オフライン」方式を使用することは驚くことではありません。
私の知る限りでは、今日、NetAppは重複排除を使用するストレージシステムの唯一のメーカーです。これは、いわゆるプライマリデータ、つまり、バックアップとアーカイブだけでなく、基本的な作業データへの使用を公式に推奨することを恐れていません。
NetAppで使用される重複排除メカニズムは「物理的に」どのように配置されていますか?
NetApp FCおよびSASハードドライブは512バイトではなく520の「非標準セクターサイズ」を使用しているとよく耳にします。 引用符で「非標準」、これは奇妙なことに聞こえますが、今日では「標準」と見なされるのは520バイトセクター(512bデータ+ 8b CRC)であり、この値は「T10委員会」によって承認されているため、 SCSI標準の開発と採用。 残念ながら、この新しい標準に準拠しているストレージシステムはほとんどありません(NetAppを除き、EMC Clariionだけでなく、EMC SymmetrixやHDS USPなどのハイエンドクラスのシステムも知っています)。このセクターフォーマットを使用すると、多くの適切で便利なボーナスが得られます。記録されたセクターのコンテンツへのRAIDレベルの損傷で
追跡不可能な追加の保護を導入します。 このようなエラーの可能性は非常に低いですが、それでもゼロではありません。
ただし、この保護に加えて、NetAppはセクターごとにこのような追加の8バイトを使用して、データ重複排除メカニズムを編成します。

(写真)
WAFLのデータブロックは4096バイトです。 データブロックは、ファイルシステムで「ディスククラスター」と呼ばれることもあり、単一のアドレスデータであり、「高可用性」コンピュータークラスターと混同しないでください。 このブロックは、ご覧のとおり、それぞれ512バイトの8セクターで構成されています。
前述したように、これらの512バイトのデータはそれぞれ、ディスクのシステムレベルでさらに8バイトのCRCが「与えられ」ます。 合計で、4KBのWAFLブロックには、64バイトのCRCチェックサムがあります。
CRCには1つの大きなプラスがあります-それは非常に高速で計算が簡単です。 ただし、マイナスがあります-いわゆる「ハッシュ衝突」は可能です。異なるコンテンツの2つのブロックが同じハッシュ結果を持つ状況です。 ハッシュの比較結果にのみ焦点を当てる場合、異なるコンテンツの2つのブロックを同一(およびそのうちの1つを完全に削除)にすることができます。 この可能性は小さいですが、存在するため、データで正確に発生することは望ましくないでしょう。
ハッシュ衝突に対処する方法は? 解決策は、ハッシュを拡張し、計算アルゴリズムを複雑にすることです。 ただし、このオプションは、主にストレージシステムのプロセッサに関連して、非常にリソースを消費します。 そのため、CAS-いわゆるContent-Addressable Storageシステム、いわゆる「第1世代の重複排除」、たとえばEMC Centeraは、書き込みが非常に遅く、ほとんど変更のないドキュメントのストレージのみに適しています。
ただし、オンライン重複排除の場合、別のオプションがないことがよくあります。
ただし、「オフラインになる」とすぐに、ディスクにデータを書き込む実際のプロセスに縛られることなく、多くの新機能が得られます。
バックグラウンドで実行される重複排除プロセスは、ディスクボリュームのすべてのブロックのハッシュのベースを形成し、それをソートして、「重複データの疑いがある」リストを受け取ります。 次に、このリストを受け取り、「容疑者」の輪とさらなる作業の量を大幅に減らして、重複排除プロセスはディスクを通過し、潜在的なすべての重複に対して単純なバイト比較操作を実行します。 そして、考慮されるブロックの内容が完全かつ無条件にファイルシステムレベルで解放されることを確認した後にのみ、以前に現在解放されたブロックを指していたiノードポインターがもう一方にシフトします。 このメカニズムは、UNIXファイルシステムのリンクメカニズムに似ており、ファイルだけでなく、ファイルシステムのデータブロックに直接適用されます。
「そのようなメカニズムが通常のファイルシステムで使用されるのを妨げるものは何ですか?」 以前に公開された
WAFLデバイスに関する投稿を読んでいただければ、簡単に質問に答えることができます。 これらのファイルシステムでは、データブロックを後で変更、上書きできるためです。 2つの異なるファイルAとBがあり、それぞれが3つのデータブロック(それぞれ4096Kb)で構成されているとします。したがって、これら3つのブロックの中央は両方のファイルで同じです(他の2つは異なります)。 これを見つけ、そのような「リンク」を使用し、ファイルBの中央ブロックにリンクする代わりに、ファイルAの2番目のブロックにリンクを設定します。
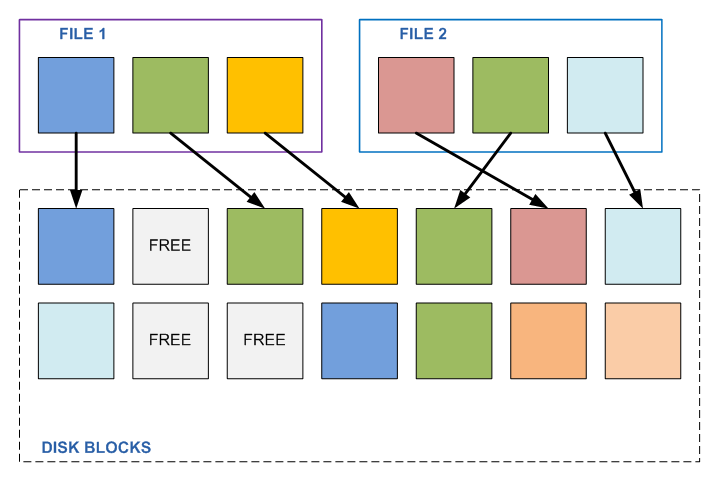
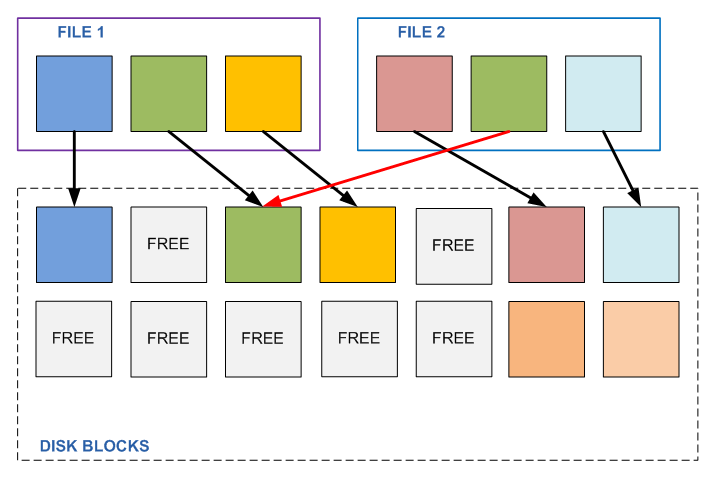
何らかのプログラムがこれらのファイルのいずれかのこの2番目のブロックを変更する必要があるまで、すべては問題ありません。 1つのファイルの内容を変更することにより、2番目のファイルの内容を自動的に変更します。 一般的に言えば、変更される予定はなく、独自のコンテンツを持ち、完全に異なるタスクに属します。 このファイルが変更されるまで、真ん中に別のファイルと同じ部分(たとえば、些細なゼロのシーケンス)があることが判明しました。
そして、ブロックが変更されるとどうなりますか? 良いものはありません。 プログラムは、知らずに、完全に無関係なファイルの内容を変更したことがわかりました。 さて、これらのファイルがさまざまな場所に100あると想像してみましょう。
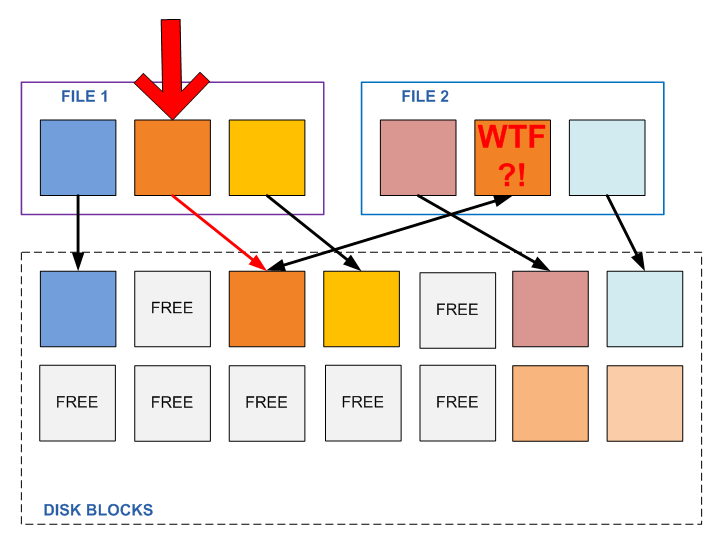
これは、通常1回だけ書き込まれ、もはや変更されないバックアップに対して機能する可能性がありますが、任意に変更できるアクティブな「プライマリデータ」には絶対に適していません。
WAFLデバイスに関する記事から覚えているように、記録されたブロックは、ファイルが存在するまで上書きまたは変更されなくなり、アクティブなファイルシステムまたは任意のスナップショットからこのブロックへのリンクが少なくとも1つ存在するように配置されます。 また、ファイルデータに変更を書き込む必要がある場合、記録が行われる場所は空きブロックのプールから割り当てられ、アクティブなファイルシステムのポインターはこのブロックに移動されます(スナップショットポインターは前のブロックに残るため、新しいファイルコンテンツに同時にアクセスできます)。 「アクティブファイルシステム」、および古いコンテンツへのスナップショット(実行された場合)。
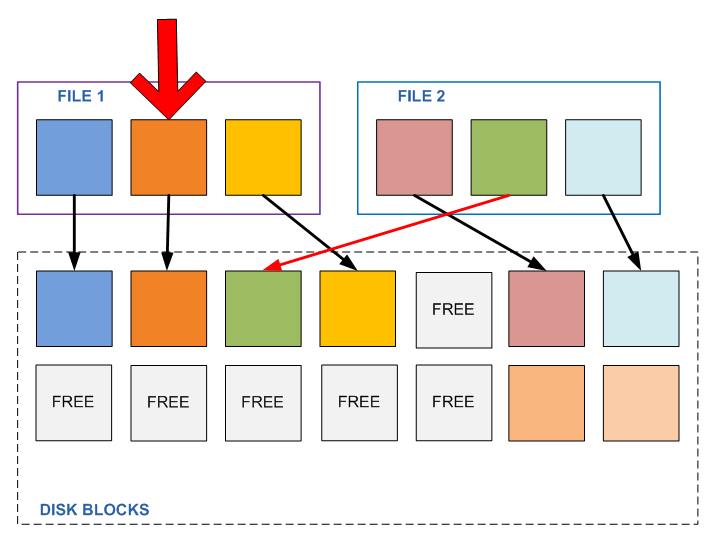
ストレージデバイスのこのようなスキームは、ファイル内のコンテンツの望ましくない変更の状況が発生しないことを保証します。
記録されたブロックの変更は保証されず、必要な操作を実行できます。たとえば、この「コンテンツ」の単一コピーを持つブロックへのリンクを持つ重複コンテンツでブロックを置き換えるなど、継続的な不変性を保証します。
おそらく、重複排除に関して最もよく寄せられる質問は次のとおりです。重複排除はストレージシステムのパフォーマンスにどのように影響しますか。
まず、前述のように、プロセスが「オフライン」で発生するときの重複排除、重複データブロックの検索、検出、および削除は、ワークロードプロセスよりも低いバックグラウンド、優先度の低いプロセスであることを考慮する必要があります。 したがって、重複排除が機能していても(負荷が最小の時間に割り当てることができます)、コントローラーのプロセッサーリソースはワークロードを犠牲にして関与しません。
第二に、重複排除されたデータには関連するメタデータがいくらか多く含まれていますが、理論的には大量の入出力を伴うシステムの負荷を増加させる可能性がありますが、ほとんどのユーザーは重複排除されたデータのパフォーマンスを低下させる効果にまったく気付きません。 また、場合によっては、読み取りボリュームの減少とキャッシュへのより適切なロード(およびNetAppキャッシュは重複排除されたデータを正しく使用する方法を知っており、知っている)により、たとえば、いわゆる「ブートストーム」の瞬間、数十、さらにはディスクから読み取られたデータの大部分が、多くの異なるマシンのメモリにロードされた同じOSファイルである場合、数百の仮想マシン。
ただし、それでも、NetAppは、保存されたデータの負荷の性質の最悪の組み合わせで5〜10%以内のパフォーマンスの低下、重複排除のサイズ決定とテストを行ってから「本番への出力」を決定するよう
に、ドキュメントで 「保守的な」推奨
を行っています 。 管理者は、不要な影響が検出された場合、いつでもデータを元の状態に簡単に「重複排除」および「ロールバック」できることを知っていると便利です。
それでも、私は繰り返しますが、実際のインストールに関する多数のレビューは、パフォーマンスに顕著な悪影響がまったくないことを示しています。
仮想マシンディスクのコンテンツなど、簡単に重複排除できるタスクのスペースを節約すると
、50% (ディスク上の以前占有されていたボリュームの半分が解放されます)
から75% (以前占有されたボリュームの4分の3が解放されます)のスペース節約が示されます。
ちなみに、NetAppは2年前に業界で前例のない
50%省スペースプロモーションを発表できるように、シンプロビジョニングですでに説明したRAID-DPなどの他のNetAppテクノロジーやWAFL記事で簡単に説明したスナップショットとともに重複排除を行いました
保証 」:NetAppは、同じ量の仮想マシンデータが別のメーカーのストレージシステムに保存されていることを保証するため、NetAppはディスクの半分の容量に収まります。 そして、この約束が満たされない場合-足りない車輪を無料で置いてください。 しかし、私が知っているように、誰もディスクを要求しませんでした。
最後に、データ重複排除機能はすべてのNetAppストレージシステムで無料で利用可能であり、通常、そのアクティベーションのライセンスはストレージシステムにデフォルトで付属しているため、突然それなしでシステムを販売した場合、販売者から無料で入手できます。