算術式をどのように計算するかという疑問が生じるとき、おそらく、多くは逆ポーランド記法から考えます。 したがって、このトピックでは、算術式の文法を構成し、ANTLRを使用してそれから字句解析プログラムを作成する方法について説明します。
まず、必要なツールを検討してください。 以下が必要です。
- ANTLRWorks-文法開発およびデバッグ環境
- ANTLR v3-ANTLR自体(執筆時点では、最新バージョンは3.2です)
- C#ランタイム配布(Antlr3.Runtime.dll)-ジェネレーターを使用するための.NETライブラリ
- Visual Studio-C#コードをコンパイルおよびデバッグするためのその他のツール
- Javaランタイム-ANTLRおよびANTLRWorksはJavaで記述されているため
ANTLRに関連するすべて、つまり最初の3つのポイントは、公式Webサイト
http://www.antlr.org/download.htmlから無料で、つまり無料でダウンロードできます。
ANTLRについて実際にいくつかの言葉を紹介します(Wikipediaを参照)。
ANTLR (言語認識のための別のツール)は、ターゲットプログラミング言語(C ++、Java、C#、Python、Ruby)のいずれかでパーサープログラム(字句解析プログラムなど)を自動的に作成できるパーサージェネレーターです。 LL(*)の記述によると-RBNFに近い言語の文法。 このプロジェクトの著者は、サンフランシスコ大学のテレンス・パー教授です。 このプロジェクトはオープンソースであり、BSDライセンスの下で配布されていると言わなければなりません。
1.問題の声明
このトピックのフレームワーク内で、C#でプログラムを作成します。プログラムはコンソールから、改行で区切られた算術式を読み取り、計算結果を出力します。 加算、減算、乗算、除算などの算術演算がサポートされます。 簡単にするために、すべての操作は整数で実行されます。 ボーナスとして、計算機(プロジェクトと呼びましょう)は変数の操作をサポートし、それに応じて割り当て操作をサポートします。
2.文法開発
ANTLRWorksを起動し、文法を使用してプロジェクトを作成します。 起動すると、ANTLRWorksは作成するドキュメントの種類を尋ねます。 「ANTLR 3 Grammar(* .g)」を選択します。 表示されるウィンドウで、文法の名前を入力し(「Calc」と呼びましょう)、デフォルトでタイプをそのままにします(「結合文法」)。 これは、1つのファイルに、字句解析と構文解析の両方の文法規則があることを意味します。 さらなる不一致を避けるために、字句解析器をレクサー、構文をパーサーと呼びましょう。 ドロップダウンリストの他のオプションを見ると、入力した表記が理解できます。 レクサーが文字のストリームからトークン(トークン)を選択することを思い出させてください:整数、識別子、文字列など、パーサーはトークンストリーム内のトークンが正しい順序であるかどうかをチェックします。 また、識別子と整数をチェックすることをお勧めします。そうすることで、文法に識別子と整数のルールが既に設定されています。 結果は次のようになります。

「OK」ボタンを押して、自動的に追加された2つのレクサールールを含む文法を取得します。 INTルールの例を使用して、レクサーのルールがどのように記述されるかを見てみましょう。 ルールは名前(この場合はINT)で始まります。 レクサー規則の名前は大文字で始める必要があります。 名前の後に記号「:」があり、その後にいわゆる
alternativesが続きます。 代替はsivol "|"で区切られます 記号「;」で終わる必要があります。
ここで、INTルールの唯一の代替案を見てみましょう。 ANTLRのエントリ '0' .. '9' +は、INTが少なくとも1桁の数字のシーケンスであることを意味します。 記号「+」の代わりに、たとえば、sivol「*」がある場合、これは数字のシーケンスが空であることを意味します。 IDルールはやや複雑で、IDは小文字と大文字のラテン文字、数字、下線で構成され、文字または下線で始まる文字のシーケンスであることを意味します。
さて、パーサーの最初のルールまたは科学的
公理 、つまり、パーサーがトークンのストリームのチェックを開始するルールを独自に記述します。 など:
calc
:ステートメント+
;
ご覧のとおり、名前が小文字で始まる必要があることを除いて、パーサーの規則の構造はレクサーの規則と異なりません。 この場合、入力トークンストリームが空ではない一連のステートメントであることをパーサーに伝えます。 パーサーは千里眼ではないため、ステートメントが何であるかを知る必要があります。 彼に言う:
声明
:expr NEWLINE
| ID '=' expr NEWLINE
| 改行
;
このルールでは、選択肢が何であるかを忘れた人は、それがどんな動物であるかを覚えることができ
ます 。 代替手段は、可能なトークン順序オプションの1つにすぎません。 つまり、ステートメントは、改行(NEWLINE)で終わる任意の式(expr)、または改行で終わる割り当て操作、または単に改行です。 はい、ところで、NEWLINEルールをレクサールールに追加することを忘れないでください。文法ファイルの最後に配置することをお勧めします。
改行: '\ r'? '\ n'
;
記号「?」 は、文字「\ r」が文に1回存在するか、まったく存在しないことを意味します。
次に、2つの選択肢を1つに結合するルールを考えます。
expr
:multExpression( '+' multExpression | '-' multExpression)*
;
ANTLR言語では、これは、exprが任意の符号を持つ用語の任意のシーケンスであることを意味します。 たとえば、multExpression-multExpression + multExpression-multExpression-multExpression + multExpressionです。
残りのルールは考慮しませんが(残りのルールは2つしかありません)、そのままそのまま使用します。
multExpression
:a1 = atom( '*' a2 = atom | '/' a2 = atom)*
;
原子
:ID
| INT
| '(' expr ')'
;
読んでいるときに文法ファイルにルールを書くと、おそらく各ルールに対してANTLRWorksがグラフを描くことにすでに気づいているでしょう。 気づいた? いいね! ここで、各ルールについてコメントする必要はありません。
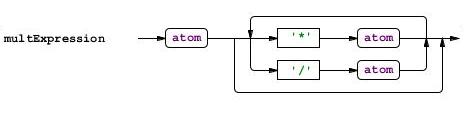
これが文法の終わりです。 本当に簡単ですか?
3.パーサーとレクサーの生成と起動
さて、文法を開発しました。 C#でパーサーとレクサーを生成するときです。 ANTLRWorksはよりJava指向であるため、視覚環境を使用するよりも(個人的には)手動でコードを生成する方が簡単です。 しかし、それについては後で。 最初に、文法ファイルに数行を追加します。 文法名の最初の行の直後に、次を追加する必要があります。
オプション
{
言語= CSharp2;
}
@parser ::名前空間{生成}
@lexer ::名前空間{生成}
これらの行は、C#コードを取得することと、ParserおよびlexerクラスをGenerated名前空間に含めることをANTLRに伝えます。 すべて、コードを生成できます。 これを行うには、次の内容を追加する.batファイルを作成します。
java -jar antlr-3.2.jar -o Generated Calc.g
一時停止
私の場合、.batファイルはantlr-3.2.jarおよびCalc.gファイルと同じディレクトリにあることに
注意して
ください 。
「-o」スイッチは、生成されたファイルが置かれるフォルダーへのパスを指定します。 一時停止は利便性のためだけに行われたため、エラーが発生した場合にそれを確認できます。
.batファイルを起動し、生成されたフォルダーを調べます。 そこには3つのファイルがあります。
- CalcLexer.cs-レクサーコード
- CalcParser.cs-パーサーコード
- Calc.tokens-トークンのリストを含むユーティリティファイル
パーサーを開始するには、Visual Studioでコンソールアプリケーションを作成し、受信した2つの.csファイルを追加しました。 便宜上、名前空間はGeneratedと呼ばれ、using'iを記述しません。 C#ランタイムディストリビューションへの参照をプロジェクトに追加することを忘れない
ことが重要です(ANTLRプロジェクトサイトからダウンロードしたDOT-NET-runtime-3.1.1.zipアーカイブ内のAntlr3.Runtime.dllファイル)。 次のコードをMain()関数に追加します。
試してみる
{
//文字の入力ストリームをコンソール入力に設定します
ANTLRReaderStream input = new ANTLRReaderStream(Console.In);
//このスレッドでレクサーを設定します
CalcLexer lexer =新しいCalcLexer(入力);
//レクサーベースのトークンストリームを作成します
CommonTokenStreamトークン=新しいCommonTokenStream(レクサー);
//パーサーを作成します
CalcParser parser = new CalcParser(トークン);
//そして最初の文法ルールを実行します!!!
parser.calc();
}
catch(例外e)
{
Console.WriteLine(e.Message);
}
Console.ReadKey();
できた!!! コンパイルして実行します。

ファイルの終わり(EOF)文字が検出されると、入力が終了することに
注意して
ください 。 この文字をWindowsに配置するには、CTRL + Zを押します。
すべてがほとんど素晴らしい。 おそらく画面に結果が表示されないことに気づいたでしょう。 混乱! 迷惑な欠陥を修正するには、文法をもう一度思い起こす必要があります。 まだANTLRWorksを閉じていませんか?
4.電卓機能を文法に追加する
楽しい部分が来ました。 始めるために、次のスニペットをファイルの先頭に追加して、ANTLRをもう少し構成します。
文法:
@header {
システムを使用して;
System.Collectionsを使用します。
}
@members {
ハッシュテーブルメモリ=新しいハッシュテーブル();
}
説明します。 @membersは、(変数値を保存するために)パーサークラスにプライベートメモリメンバを追加する必要があることをANTLRに伝えます。したがって、
ヘッダーは、Hashtableを使用するために接続する必要があるネームスペースを示します。 これで、C#コードを文法に追加できます。 ステートメントルールから始めましょう。
声明
:expr NEWLINE {Console.WriteLine($ expr.value); }
| ID '=' expr NEWLINE {memory.Add($ ID.text、$ expr.value); }
| 改行
;
コードは中括弧{}で記述されています。 ステートメントが最初の選択肢である場合、算術式の値を画面に出力し、2番目の場合-変数名とその値をメモリに保存して、後で取得できるようにします。 ここではすべてが非常に簡単ですが、疑問が生じます。式$ expr.valueの値はどこから来るのでしょうか? そして、それはここから取られます:
exprは[int value]を返します:me1 = multExpression {$ value = me1;}( '+' me2 = multExpression {$ value + = $ me2.value;} | '-' me2 = multExpression {$ value-= $ me2値;})*; ここでも複雑なことはありません。 exprルールがint型の値と呼ばれる値を返すことをANTLRに伝えます。 両方のエントリに「$ expr.value」と「returns [int value]」の値が偶然表示されないことに
注意して
ください 。 私たちが書く場合:
exprは[int tratata]を返します
...
;
そして、$ expr.valueに変更すると、ANTLRはエラーをスローします。
「ルールは意味を返す」と言って、ある程度の発言を許可しましたが、意味を失うことなく別の言い方をすることは、私の意見では十分に難しいです。
別の微妙。 ステートメントルール、たとえば最初の選択肢を検討してください。 この代替に対応するコードでは、exprルールを直接参照します($ expr.value)。 ただし、ステートメントルールでは、2つのmultExpressionルールが同時に含まれるため、これは機能しません。つまり、それらを区別するために、名前を付ける必要があります。 この場合、これらはme1とme2です。 すべての微妙さのようです
議論され、今ではポイントにより近い。
exprルールでは、2つの選択肢が文字「|」を介して1つに書き込まれます。 これは、このトピックのパート2で明確に見られます。 exprはmultExpression-multExpression + multExpression-multExpression-multExpression + multExpressionという形式の文であることを思い出させてください。 ここで中括弧内のコードを見て、最初の用語の値が戻り値の値に割り当てられ、次に操作に応じて後続の用語の値が加算または減算されることを確認します。 ルールは似ています
multExpression:
multExpressionは[int value]を返します
:a1 = atom {$ value = $ a1.value;}
( '*' a2 = atom {$ value * = $ a2.value;}
| '/' a2 = atom {$ value / = $ a2.value;})*
;
アトムパーサーの最後のルールは残ります。 問題はないはずです:
アトムは[int value]を返します
:ID {$ value =(int)memory [$ ID.text];}
| INT {$ value = int.Parse($ INT.text);}
| '(' expr ')' {$ value = $ expr.value;}
;
atomが識別子(ID)である場合、メモリから取得した値を返します。 atomが整数の場合、単純に文字列表現から取得した数値を返します。 最後に、atomが括弧で囲まれた式である場合、式の値を返すだけです。
.batファイルを使用してパーサーとレクサーを生成します。 Main()関数のコードでさえ変更する必要はありません。 電卓を起動してプレイします。
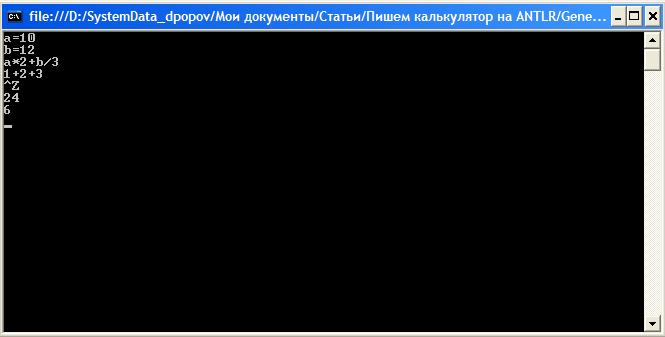
興味深いことに、生成されたパーサーは構文エラーを報告し、さらにそれらから回復できます。 これを確認するには、たとえばスペースを含む式を入力してみてください(スペース、タブなどの処理は行いませんでした)。

パーサーはエラーを検出しましたが、それでも結果を正しく計算しました。 「2 ++ 3」のように記述して5を取得することもできます。
5.結論
要約する時が来ました。 私たちが得た解決策は、私には思えますが、タスクと完全に一致しています。 式プログラムは読み取りますか? はい 結果は計算されますか? はい これは、おそらく、終了することができます。 皆さん、このトピックが好きで、ANTLR文法を使用して構文解析ツリーを構築し、同じANTLRを使用してそれらを回避する方法を学びたいと心から願っています。 独自のプログラミング言語を作成するという夢がある場合、ANTLRを使用すると実装にはるかに近づきました!
6.推奨読書
- 確定ANTLRリファレンス、Terence Parr、2007年。
ISBN-10:0-9787392-5-6、ISBN-13:978-09787392-4-9 - 言語実装パターン、テレンスパー、2010年。
ISBN-10:1-934356-45-X、ISBN-13:978-1-934356-45-6