テキストを文章に正しく分割するように検索エンジンに教える方法は? 彼女が文の終わりではない点を認識できることを確認してください。
機械学習に関する記事では、テキストを文章に正確に分解する必要がある場合に検索エンジンで使用される手法の1つについて説明します。 この問題の解決策は、たとえば検索エンジンによってスニペットを生成するときや、単語の使用状況のデータベースを構築するときなど、根本的に重要です。 現在、このテクノロジーは検索インデックスMail.Ruに組み込まれています。 観察によると、この方法の精度は99%以上です。
これがどのように機能するかについては、記事をご覧ください。
問題と既存の解決策
自動ワードプロセッシングシステムを開発する場合、多くの場合、テキストを文章に正しく分割するというタスクが発生します。 そのソリューションは、たとえば検索エンジンによってスニペットを生成するとき、または単語使用コンテキストのデータベースを構築するときなど、基本的に重要です。
実際には、最初に記号が文の終わりであるかどうかを確認し、次に誤って文の区切りが省略されたテキスト内の場所を特定する必要があります。 2番目を実現(および計算)することははるかに困難ですが、幸いなことに、文の暗黙の終わりは明示的な終わりよりも一般的ではないため、これは緊急ではありません。
文の終わりは、ドット、疑問符と感嘆符、段落の終わりの文字、楕円、場合によってはコロンで示されます。 主な問題は、ドット文字によって作成されます。これは、略語やリテラル表記(日付、暗号、電子メールアドレス、Webアドレスなど)でも使用されるためです。
このコンテキストのポイントが文の終わりであるかどうかを判断するために、さまざまな方法が適用されますが、その複雑さは結果の要件に依存します。 最も一般的な方法は、正規表現と標準の略語表の使用を伴う方法であり、かなり単純な場合には許容できる結果が得られます。
略語表の主な欠点は、非標準(著作権)の略語の場合に適用できないことです。 さらに、略語は文の最後にある場合があり、たとえば「etc。」、「and other」などの一部は、しばしば提案の明示的な終了を示します(ところで、この提案は例外です)。
記号が文の終わりであるかどうかに関する情報は、コンテキストに保存され、特定の規則に従って表示されます。 特にアルゴリズムの形式で提示する必要があるという事実を考慮すると、私たち自身の経験だけに基づいてそれらを定式化することはそれほど簡単ではありません。
しかし、文の終わりの兆候を99%以上の精度で自動的に区別するルールを導き出すことは可能ですが、可能です。
私たちの方法
Search by Mail.Ruに使用することにした方法は、基本的なルールの小さなセット(約40)を作成し、これらのルールを適用した結果に基づいて分類子を自動的に構築することです。
基本的なルールは、置換と組み合わせの2つのタイプに分けられます。 置換は正規表現によって定義され、たとえば「右側のスペース」や「左側の大文字」などの特定の単純な文脈上の兆候をチェックします。
組み合わせは、順列から構築される代数構造です。たとえば、「左側の大文字」+「右側のタイトル」(タイトル-大文字で始まる単語)。 各基本ルールは、特定のコンテキストに適用されると、付与されたポイントの数、通常は0、-1、または+1を返します。 最終結果は、特別な分類器を使用してポイントベクトルから計算されます。
このアプローチの優れた機能は、決定を下すには、すべてのルールの値ではなく、分類器が必要とするルールの値のみを計算する必要があるという事実です。 さらに、分類子のルールの重要性に基づいて、ルールを最適化して、品質とパフォーマンスを向上させることができます。
学習について:決定木
基本ルールの選択は、特別に開発された宣言型言語を使用して手動で行われました。 分類器を構築するために、「決定木」に基づく機械学習アルゴリズムを使用しました。
トレーニングは、Webページ、フィクション、正式なテキストなど、さまざまなタイプのドキュメントで順次実行されました。 合計で、約1万のエピソードが、オファーのサイン除数とディバイダーではないサインの数の比が2対3のように選択されました。 99%の精度で6段階のトレーニングが必要でした。
トレーニングの最初の段階では、データは手動で準備されました。約1000件のエピソードが考慮されました。 その後の各段階で、エピソードがトレーニングリストに追加され、分類子は「誤解」または「疑い」になりました。
最も重要なルール
すでに述べたように、個々のルールの重要性は学習プロセスで自動的に決定されます。 特定のルールによって取得されたスコアと必要な回答との相関度が高いほど、このルールは調査リスト内で高くなり、その実装が頻繁にチェックされます。
実験の結果、最も重要なルールには以下が含まれることがわかりました。
•「セパレータータイプ」、3つのルール。 ポイント、疑問符、感嘆符がそれぞれ決定されます。
•「左右のスペース」。 セパレータの左右に空白があるかどうかを判断します。
•「句読点記号右/左」。
•「右/左の数字」。
•「左右の大文字/小文字」;
•「右/左の開閉ブラケット」。
•「標準の略語」。
•「一般形式xxx.-xxの不明な略語。 xx。」など
分類アルゴリズム
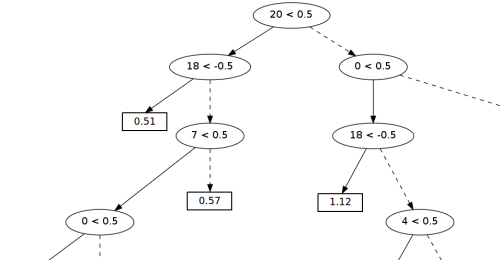
図1.意思決定ツリーのフラグメント。
分類子の基礎として、機械学習で広く使用されている「決定木」を使用しました。 分類器からの実際の「ツリー」の例を図1に示します(「ツリー」全体が大きすぎるため、フラグメントを示します)。
ツリーの「ノード」には、ルールをチェックするための条件があります。 「20 <0.5」という形式のレコードは、ルールNo. 20のスコアが0.5ポイント未満の場合、左側のサブツリーに移動する必要があることを意味し、そうでない場合は右側のサブツリーに移動する必要があります。
除数が文の終わりである確率の推定値は、「ツリーの葉」に格納されます(値が大きいほど、確率が高くなります)。 この例では、ツリーは次のルールに基づいて決定を下します。
•No. 0-区切り記号はポイントです
•No. 4-右側のスペース
•No. 7-左側の大文字
•No. 18-省略記号(最初のポイントが+2、平均が+1、最後が-1)
•No. 20-右側のタイトル(タイトル-大文字で書かれた単語)。
残念ながら、1つの「ツリー」では許容できる分類品質を提供できないため、数百の比較的単純なツリーの組み合わせを分類子として使用します。
各「ツリー」は、分類器の残りの「ツリー」の誤差を最大限に補償するように構築されます(このアプローチは、ブースティングという名前で専門文献で知られています)。 さらに、分類器全体の品質を向上させるために、トレーニングセットのランダムサブセットを使用して各「ツリー」を構築し、「ツリー」から「ツリー」に変更するブートストラップ手法を使用しました。 このようにして得られた複合分類子は、単一の「ツリー」よりも著しく優れた作業品質を示します。
フレーズのランダムなセットに対するマークアッププログラム出力の例
内部のsnタグは文全体です:
< sn > "". </ sn >< sn > There is no silver bullet. </ sn >< sn > . . - . </ sn >< sn > . . . </ sn >< sn > Unix 01. 01. 1970. </ sn >< sn > . . 11.06.1999. </ sn >< sn > v.pupkin@nowhere.ru.com, - nowhere.ru.com/pupkin.html - , . </ sn >
* This source code was highlighted with Source Code Highlighter .
表は、分類子によって行われた評価を示しています。 カットオフしきい値(0.64に等しい)は、トレーニングサンプルから得られた推定値の最小二乗法によって選択されました。 しきい値シフトは、符号がセパレーターである場合とそうでない場合のケース数に関するトレーニングサンプルの非対称性によって説明されます。
| 解決策: | コンテキスト(区切り文字は中央にあります): | 評価: |
| はい | 「あの日は「よかった」。 銀のいじめはありません」 | 1,000 |
| はい | `特効薬はありません。 A. S.プーシキン-偉大なp ' | 0.734 |
| いや | 「これは特効薬ではありません。 A. S.プーシキン-グレートラス | -0.002 |
| いや | `特効薬はありません。 A. S.プーシキン-偉大なロシア人 | 0.003 |
| はい | 「インは偉大なロシアの詩人です。 F. M.ドストエフスキーは、 | 0.972 |
| いや | `-ロシアの偉大な詩人。 F. M.ドストエフスキーは | -0.002 |
| いや | `ロシアの偉大な詩人。 F. M.ドストエフスキーは自分の中に住んでいない | 0.003 |
| はい | `ロシアの単純な時間。 Unix時代のカウントの始まり ' | 1,000 |
| いや | `mのUnix時代は01. 01. 1970と考えられています。Vasily Pupkin ' | 0.460 |
| いや | 「Ohi Unixは01. 01. 1970と考えられています。VasilyPupkinはそうでした」 | 0.489 |
| はい | `ixは01. 01. 1970と見なされます。VasilyPupkinが任命されました ' | 0,500 |
| いや | `李パプキンが任命された。 について。 部長 | 0.184 |
| いや | `パプキンが任命された。 について。 ゼネラルマネージャー1 ' | 0,050 |
| いや | `ゼネラルマネージャー06/11/1999。 彼のメールアドレス ' | -0.001 |
| いや | `1999年6月11日のマネージャー。 彼の住所は | -0.001 |
| はい | `` 1999年6月11日にマネージャー。 彼の住所はv.pupです ' | 0,500 |
| いや | `999。 彼の住所はv.pupkin@nowhere.ru.comです。 | -0.055 |
| いや | `v.pupkin@nowhere.ru.comアドレス、個人ページ ' | 0,000 |
| いや | 「v.pupkin@nowhere.ru.comアドレス、個人ページはこちら」 | 0.001 |
| いや | `ka here-nowhere.ru.com/pupkin.html-now ' | 0,000 |
| いや | 「ここ-nowhere.ru.com/pupkin.html-今」 | -0.001 |
| いや | `p://nowhere.ru.com/pupkin.html-今では誰もが知っている、 ' | -0.001 |
| はい | 「彼に連絡する方法を見つけなさい。」 | 0.972 |
私たちはどうですか?
現在、検索エンジンのインデクサーには、テキストを文章に正しく分割するための機械学習技術が組み込まれています。 この実装により、Search @ mail.Ruのスニペットの品質が向上し、単語が使用されているコンテキストをより正確に判断できるようになり、検索結果の関連性が高まります。
課外リーディング
機械学習アルゴリズムのより深い理解のために、T。Hastie、R. Tibshirani、JHFriedman「統計学習の要素」という本を
オンラインで入手
することをお勧めします。
よろしく
検索チーム。Mail.Ru