ときどきトレントクライアントのウィンドウを開いて、ファイルがどのように配布されるかを見るだけです。これは、自家製のクヴァスを入れた3リットルの瓶に入れたデフラグや間欠泉や火山よりも魅力的です。 結局のところ、私は多くの見知らぬ人が必要なファイルをダウンロードするのを助けます。 私の自宅のコンピューターは小さなサーバーであり、そのリソースをインターネット全体と共有しています。 おそらく、同様の感情は、世界中の何千人ものボランティアが@ homeを折りたたむようなプロジェクトに参加することを奨励しています。
世界中の何百万もの小型コンピューターが提供する大量の配布を、リソースのごく一部を使用して処理できるファイルサーバーはありません。 今、私が好きなサイトと同じくらい簡単にリソースを共有できるなら! 視聴者の増加に伴うホスティングコストが線形ではなく、対数的に増加した場合、訪問者のコンピューターからの「任意のボットネット」が原因です。 表示される広告の量はどのくらい少ないでしょうか? いくつの興味深いスタートアップがスケーリングに関する頭痛の種を取り除きますか? 顧客の好意に依存しなくなる非営利プロジェクトはいくつありますか? そして、このようなサイトをサイバー攻撃や特別なサービスでDDoSするのはどれほど難しいでしょう!
発行価格
現在、世界には15億台以上のコンピューターがインターネットに接続されています。 これらのうち、約5億人がブロードバンド接続を使用しています。 家庭用コンピューターの平均年齢が約2年であると仮定すると、単純なデュアルコアプロセッサ、1〜2ギガバイトのメモリ、および500ギガバイトのネジがあると仮定できます。 明確にするため、ブロードバンド接続の平均速度は10メガビット/秒であると想定しています。
それはたくさんですか、それとも少しですか? この隠された大量のリソースに到達できたらどうなりますか? のぞき穴を覗いてみましょう。 これらのコンピューターを24時間オンのままにすると、リソースの少なくとも4分の3がアイドル状態になると仮定します(これは慎重な見積もりを超えているため、Wikipediaの平均サーバー負荷は18%です!)。 コンピューターを適切にロードすると、エネルギー消費は、たとえばコンピューターあたり70ワット、または月あたり50キロワット時増加します。 世界の平均電力価格はキロワット時あたり約10セントです。これは月額5ドルです。 さらに、摩耗の増加という疑問が生じます。 問題はかなり議論の余地があり、真面目なメーカーのほとんどのコンポーネントは、壊れるよりもはるかに早く絶望的に時代遅れになります。さらに、絶え間ないオンオフと関連する加熱冷却やその他の過渡現象は、24時間作業よりも速くリソースの開発につながるという意見があります。 それにも関わらず、我々は計算に、例えば4年間の運用にまたがる修理のための追加の150ドルを含めます。 これは月に3ドル強です。 合計-月額8ドル、または年間100ドルの追加費用。 一方、コンピューターの購入時に既に支払ったリソースの4分の3が現在アイドル状態になっている場合、平均システム価格が500〜375ドルである場合、それらを埋め立て処分します。 これらの375を一度に使用したことを考慮に入れると、この金額を4年間の運用に分配すると、年間100ドルとまったく同じになります。 おそらく、コンピュータが電力の10%を使用している場合でも、電力を消費するのは10倍ではなく、2倍にすぎないことに注意してください。 しかし、ならず者ではありません。 実際、自宅にコンピューターと高速インターネットを持っている人の99%は「黄金の10億人」に属しているため、月にプラスまたはマイナス数ドルは大きな役割を果たしません。
それで、すべてをまとめましょう。 1ギガバイトのメモリ、1.5-2ギガヘルツの周波数で1.5コア、ネジごとに350ギガバイト、7メガビット/秒のチャネルに5億を掛けます:
- + 500ペタバイトのRAM
- + 7億5,000万コア
- + 175,000ペタバイトのディスク容量
- + 3.5ペタビット/秒の帯域幅
- -300テラワット時の電力(世界の電力消費量の約0.3%)
- -年間1,000億ドル、うち50ドルはコンピューターの購入時に既に支払っています
批判的な読者(そしてそれらのほとんどがここにいることを願っています)は、前の段落のすべての数字の校正を必要とするかもしれません。 これらは過去数年間の信頼性の程度が異なるさまざまな統計情報への数十の参照であり、テキストを大きく詰まらせるため、それらを引用しないリスクを取りました。 記事のトピックを明らかにするには、桁違いに重要であるため、特別な精度は必要ありません。 それにもかかわらず、誰かが同じオペラから既製の信頼できる統計を持ち、それが私の数字とは非常に異なっていたら、私はそれを見てうれしいです。
したがって、この海洋資源の大部分は未使用のままです。 彼女への行き方 ファイル共有ネットワークで発生するように、トラフィックの急激な急増時にサイトのアクセシビリティを低下させるのではなく低下させることは可能ですか? 私のコンピューターの無料リソースの一部を興味深いスタートアップに提供して、立ち上がるのを助けるシステムを作成することは可能ですか? この方向の最初のステップはすでに実行されていますが、すべての最初のステップと同様に、それらをまだ特に成功と呼ぶことはできません。 分散システムは、同等の機能を備えた集中型システムよりもはるかに複雑です。 子供でも、サーバー上のどこかに保存されているファイルへのハイパーリンクが何であるかを説明できます。 しかし、すべての大人がDHTの仕組みを理解できるわけではありません。
モザイク片
無数のクライアントコンピューター上のサイトを「塗り付ける」ときに対処しなければならない最大の問題は、動的コンテンツです。 静的なページの分散ストレージと配布は、他のファイルの配布と大差ありません。 ページの整合性と信頼性の問題は、ハッシュとデジタル署名を使用して解決されます。 残念ながら、純粋なHTMLでの静的サイトの時代は、分散ネットワークとプロトコルが成熟して広く普及する前に終わりました。 他に代替手段がない単純なニッチは、
FreeNetや
GNUnetのような匿名暗号化ネットワークネットワークです。 それらでは、恒久的なアドレスを持つ通常のWebサーバーを作成することは、定義上不可能です。 これらのネットワークの「
サイト 」は、
フォーラムに統合された静的なページまたはメッセージのセットのみで構成されてい
ます 。 さらに、より多くのトラフィックが暗号化および匿名化されると、そのようなネットワークの帯域幅はより速くゼロになり、応答時間は無限になります。 ほとんどの人は、匿名性とプライバシーのためにこのような不便に耐える用意ができていません。 そのようなネットワークは、多くのオタク、政治的反対者、および小児性愛者のようなすべての悪霊のままです。 私がプライバシーについて書き始めたとき、段落は非常に大きくなり、周囲のテキストから非常に大きく突き出したため、別のトピックとしてデザインしました。 だからここで
余談があります。
私たちのトピックに少し近いのは
、オシリスプロジェクトです。 匿名のファイル共有とメッセージではなく、「ポータル」という分散サイトの作成に特に焦点を当てています。 匿名性は十分にありますが。 無責任な匿名者が洪水やスパムでポータルを台無しにするのを防ぐために、レピュテーションアカウンティングシステムが使用されます。これは「一元的」モードで動作できます。ポータルの所有者がレピュテーションを割り当て、「アナキスト」モードではすべての訪問者がレピュテーションの作成に参加します。 このプロジェクトは比較的若く、著者はイタリア人であり、ほとんどのドキュメントはまだ英語に翻訳されていません(ロシア語は言うまでもありません)。したがって、
Wikipediaの記事は公式サイトよりもかなり充実しているでしょう。
さらに興味深いのは、分散キャッシュシステムとCDNです。 多くの人が
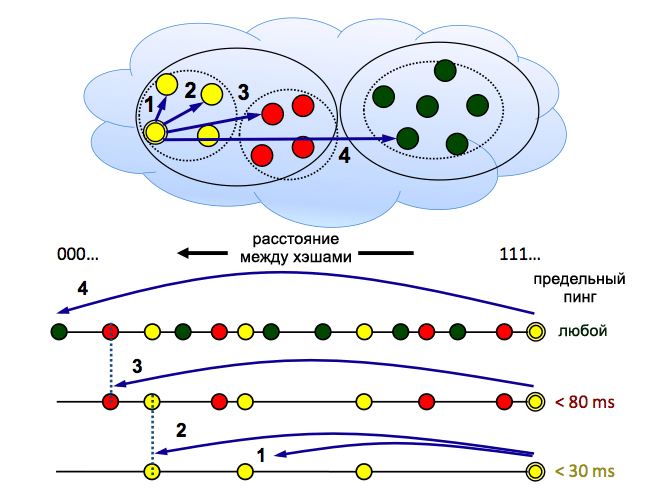
コーラルCDNについて聞いたことがあります。 Coral分散ネットワークは、ユーザーコンピューターではなく
PlanetLabサーバーに基づいて
いますが、そのアーキテクチャは非常に興味深いものです。 ネットワークの主な機能の1つは、ピーク時にスラッシュドットまたはhabraeffectの下で小規模サイトを支援することです。 リソースURLの右側に「マジックワード」.nyud.netを追加するだけで十分です。すべてのトラフィックはCoralを通過します。 リンクにアクセスすると、ネットワークは、DHTの修正バージョン-ずさんなDHTを使用して、要求のハッシュによって目的のリソースを検索します。 「ずさん」という言葉は、ピア情報が同様のハッシュ値を持つ複数のノード間で「ぼやけている」ことを意味し、リソースハッシュに最も近いノードの負荷を軽減します(最後の文で何も理解していない場合、分散ハッシュアーキテクチャの基本原則は理解可能な言語でレイアウトされます表)。 さらに、Coralは、応答時間を短縮するために、ノード間のpingに応じてハッシュテーブルをクラスターに分割します-結局、DHTが十分なピアを見つけている間にムービーのダウンロード中に1分間待つことができる場合、ページの読み込み時に余分な数秒が非常に迷惑です。
詳細な説明は次のとおりです。
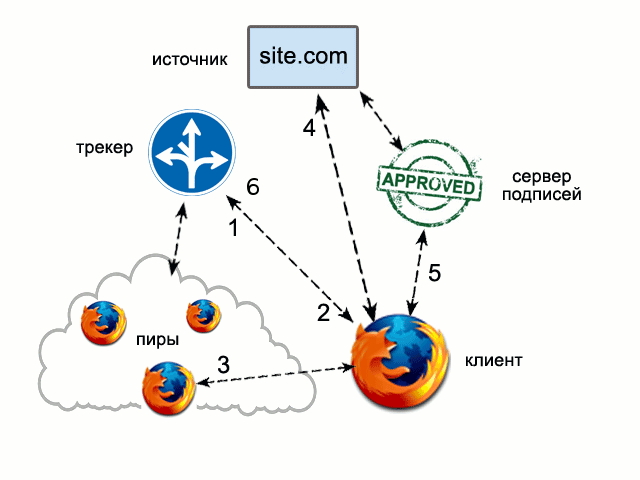
分散型Webサイトに向けた2つの小さなステップ-BitTorrent DNAとFireCoral。
DNAはBitTorrentに基づいており、大量のコンテンツを配信するように設計されています。 クライアントマシンにブートローダーをインストールする必要があり、実際にファイルまたはビデオをダウンロードします。 ブートローダーの原理は、ストリーミングビデオが常に順次ロードされるため、完全なダウンロードを待たずに視聴を開始できることを除いて、通常のトレントダウンロードとそれほど変わりません。 ダウンロードしたファイルはキャッシュされ、他のクライアントに配布されます。 ドライバーをダウンロードしたときに、DNAローダーに何度か出くわしました。 これまでのところ、これはすべてWindowsでのみ機能します。
FireCoralは、PlanetLabサーバーではなく、クライアントコンピューターで実行する必要があるFireFoxアドオンであるCoral CDNの比較的若い
親 isです。 執筆時点では、このアドオンをダウンロードしたのは1404人だけだったため、実際にはドライブできませんでした。 そして、それは最終日に1人もの人を使いました。
FireCoralアーキテクチャの詳細な説明を次に示します。 簡単に言うと、FireCoralはHTTPリクエストをインターセプトし、ブラウザキャッシュに適切なものがない場合、トラッカーを参照します(1)。 トラッカーは、キャッシュに目的のファイルがあるピアのアドレスをクライアントに報告するか(3)、要求をまだキャッシュしていない場合、またはキャッシュ内のバージョンが期限切れになっている場合にソースサーバーに送信します(4)。 FireCoralがピアからダウンロードしたすべての信authentic性は、信頼できる署名サーバーによって提供されるデジタル署名によって検証されます(5)。 リクエスト処理の完了後、FireCoralはトラッカーに、コピーも持っていることを通知します(6)。
既存の分散キャッシュシステムの欠点は明らかであり、非常に重要です。 キャッシュは、サーバーの参加なしで(さらに、知識なしで!)行われます。 これにより、訪問統計の収集が複雑になり、コンテンツの配信を制御し、サーバーとクライアントの両方に潜在的なセキュリティの脅威をもたらします。 サイトの観点から見ると、このようなP2Pネットワークは
オープンプロキシサーバーに非常に似て
います 。 これらの困難に対処することは、サイトが分散キャッシュの存在を認識し、それを制御している場合にのみ可能です。 FireCoralアーキテクチャに関しては、これはソースサーバーがトラッカーと信頼できる署名サーバーの両方として同時に機能することを意味します。 Webサーバーがカスタマーサービスのすべての作業を独立して行う場合、そのようなアーキテクチャでは、すべての汚い作業を行うピアを制御する「オバーサー」の役割のみが維持されます。
WebサーバーがP2Pネットワークと連携するだけでなく、クライアントが特定のサイトを明示的に支援する場合、さらに多くの機会が現れます。 つまり、ダウンロードしたコンテンツを自分で共有するだけでなく、特に使用頻度の低いコンテンツなど、特に必要のない情報をディスクに保存することをサイトに許可します。 または、複雑な計算を支援します。
ストレージが最も簡単です。 暗号化により、データを信頼せずにクラウドまたはサーバーに保存できます。 これが、Dropboxのライバルの1つであるWualaなどの仕組みです。 Wualaを
使用すると 、データセンターだけでなく、ユーザーのディスク領域のために、ファイルを保存するため
の利用可能な領域を増やすことができます 。 つまり、クライアントプログラムはコンピューターをクラウドストレージの一部として使用します。 ファイルをクラウドに保存するための費用はお金ではなく、ディスクとインターネット接続のリソースで支払います。 すべてのファイルは暗号化されているため、ネジに誰が何を保存しているのかわかりません。さらに、ファイルは完全に保存されるわけではありませんが、実際には分散ファイルシステムです。 つまり、誰かが断片をまとめて私のファイルを解読する可能性は、ごくわずかです。
残念ながら、Wualaはこの機能を実際には宣伝していませんが、理解できます。 無料で利用可能なスペースを増やすことをユーザーに大声で明確に提供することは、あなたが座っているブランチを切ることを意味します。 P2Pクラウドで同期およびストレージサービスを促進するには、別のビジネスモデルが必要です。 たとえば、リソース交換は、他のできるだけ多くのオファーに対するテラバイトの需要です。 この式にお金を含める必要があります。たとえば、100ギガバイトの空き領域があり、クラウドに保存するファイルを補うために150が必要です。50ギガバイトが不足する代わりに、お金で支払います。 サービスには少額の手数料がかかります。 そして、十分なユーザーが集められ、需要と供給のバランスが許せば、リソースを側に売ることが可能になります。
分散Webサーバーに戻ると、
Flattrのようなシステムを想像できますが、お金の代わりにギガバイトとメガバイトが分散され、コンテンツ全体ではなくサイト全体が評価されます。
コンピューティングでは事態はさらに悪化します。 マシン上でデータを操作する人をだれにも知らせることはできません。 暗号化により、機密性を恐れることなく情報をどこにでも保存でき、署名および証明書により、誰でも偽造の可能性を除いて情報を配布できる場合、暗号化および署名された形式でこの情報を処理および変更することは不可能です。 分散ネットワークのノードをある程度信頼する必要があります。 また、ノードの偶発的または意図的なデータ破損のチェックにリソースを費やす必要があります。
信頼の問題は、クライアントコンピューターで「正面から」解決することはできません。 クライアントコードの難読化、あらゆる種類のアンチチートモニター-これはかさばる、不便な松葉杖です。 あらゆる種類のMMORPGの作成者は常に
それと戦っています 。 遅かれ早かれ、すべてにパッチを適用できます。 むしろ、ほとんどすべて。
信頼できるコンピューティングがあります。 素晴らしい新しい世界へようこそ! リチャード・ストールマンの悪夢、ビッグブラザーの夢-すべてのコンピューターには、私たちがすべきこと、いつ、どのようにすべきかだけを確実にするチップがあります。 この解決策は、問題自体よりもはるかに悪いです。
別の方法が実際に機能します。 それは長い間、大自然によって成功裏に使用されてきました。 これは免疫です。 あらゆる生物は、敵対的または機能不全の細胞を非常に効果的に検出し、破壊します。 同様のシステムがP2Pネットワーク用に発明されました。
たとえば、「anything @ home」プロジェクトのベースとなっているBOINC分散コンピューティングプラットフォーム。
コンセンサス方式を使用
します。 計算のために同じデータが複数の参加者に与えられ、全員が同じデータを返した場合にのみ結果がデータベースに入力されます。 そうでない場合、誰かが間違いを犯したか、だまされました。 エラーは主に2つの方法で修正できます。信頼できるサーバーが存在する場合、データの紛争部分の計算は彼に委ねられ、別の回答をした人はすべてフォレストに移動します。 ネットワークが完全に分散され、ピアツーピアである場合、参加者の過半数によって与えられた答えは正しいとみなされ、この方法は「定足数コンセンサス」として知られています。 さらに、中間オプションが可能です-各ノードについて、レピュテーションは前の作業の結果に基づいて計算されます。 評判の高いノードの応答は、競合の解決においてより重要です。
これはすべて分散Webサイトにどのように適用されますか? Webサーバーが提供するデータは、4つのグループに分類できます。
- パスワード、クレジットカード番号、プライベートメッセージ、ファイルなど、データの開示と不正な変更は絶対に容認されません。 暗号化された形式でのみ保存および転送できます。
- 誰でも見ることができるデータですが、彼らのarbitrary意的な変更は受け入れられません。 たとえば、ページ上のJavaScript。 そのようなデータは、信頼できるソースによって検証および署名される必要があります。
- 不正な閲覧は望ましくないが、災害ではないデータ。 たとえば、こちらのHabréの非公開ブログのコンテンツ。
- 不正な変更を後で簡単に修正できるデータ。 たとえば、破壊よりも修正がはるかに簡単なウィキペディアの記事。 分散化を促進するために、クォーラムコンセンサス方式を使用して、信頼できるサーバーに参加せずに、そのようなデータの検証と公開を許可できます。
そのため、今日、すでにグローバルネットワークのリソースの「ダークマター」に到達するための基本的な機会があります。 ただし、これまでのところ、ファイル共有のみが本当に大規模になっています。 おそらく、P2Pサイトを完全かつ安全に運用するには、サイト構築の基本を真剣に検討する必要があるということです。アーキテクチャ、アクセス制御のアプローチが大きく変化し、新たなリスクが生じます。 そしてもちろん、鶏と卵の永遠の問題。 インフラストラクチャがないため分散サイトはありません。分散サイトがないためインフラストラクチャはありません。
さて、私の意見では
、インフラストラクチャではなく分散サイトの一部でこの悪循環を打破する最も有望な試みは
、Diasporaプロジェクトです。 開発はまだアルファ段階ですが、彼らはなんとか一般の注目を集め、
kickstarter.comで多くの資金を集めることができました。マーク・ザッカーバーグでさえプロジェクトの資金調達に
貢献しました。 Diasporaの作成者は、一般的に分散ホスティングの問題を解決することを脅かしていませんが、本質的にP2Pアーキテクチャに適合するソーシャルネットワークを作成します。 人を惹きつける主な「ニンジン」は、データを完全に制御することです。 ディアスポラは、この種の唯一のプロジェクトではありません。GNUsocial、Appleseed、Crabgrassもありますが、どれもそんなに人気になることはできませんでした。
DiasporaはRuby on Rails Webアプリケーションです。 Diasporaサーバーを上げるには、LinuxまたはMacOS Xが必要で、その上にthinおよびnginxが必要です(ここでオプションが可能です)。 Windowsまで、著者の手は届きませんでした。 非オタク向けのシンプルなインストーラーの作成-将来の計画。 Diasporaのアーキテクチャは植物の用語を使用しています。サーバーは「ポッド」(ポッド)、ユーザーアカウントは「シード」です。 各ポッドには1つ以上の穀物が含まれている場合があります。 投稿—写真、メッセージなど—は、1つ以上の「アスペクト」に属する場合があります。 アスペクト-ユーザーのグループ。たとえば、「親ative」、「仕事」、「友達」。 ディアスポラは暗号化アクセス制御を使用します。 これは何ですか
ACLや
RBACなどの習慣的なアクセス制御モデルは、信頼できるサーバーに完全に依存して、だれが開始するかを決定します。 番犬のように。 データがどこかに保存されている場合、各サーバーに秘密を慎重に守るかなり邪悪な犬がいるとはもはや予想できません。 彼女はまったくそこにいないか、犬が友人と敵を混乱させるかもしれません。 このような状況では、キーを持っている人だけがアクセスできるように、各情報をロックでロックする必要があります。 これは暗号制御です。 情報へのアクセスを制御し、それを暗号化し、必要と考える情報にキーを配布します。
暗号化制御の最大の問題は、以前にこのアクセス権を持っていた人から確実にアクセス権を奪うことが実際上不可能であることです。 これを行うには、すべての情報を別のキーで再暗号化し、このキーをグループのすべてのメンバーに配布する必要があります。 これをかなり迅速に実行できたとしても、グループから削除されたユーザーが適切なキーを持っているときに復号化された情報を保存しなかったという事実に頼ることはできません。 しかし、インターネットで公開されたすべてのものが永遠にそこに残るという事実にすでに慣れています。
一度公開された情報を100%アクセス不能にすることができないという事実は、私たちが試みることすらしてはならないという意味ではありません。 99%も良いです。 ただし、新しいキーの再暗号化と配布は、リソースを大量に消費する低速なプロセスです。 誰かを除外したいグループのメンバーの数がそれほど多くなく、成功した「通信」の99%の保証に満足している場合、すべてを再暗号化し、新しいキーを提供します。 グループが非常に大きく、多くの情報がある場合、ゲームには問題はありません。キーを置き換えるだけに制限できるため、除外されたユーザーは新しい情報ではなく古い情報にアクセスできます。
暗号化アクセス制御プロセスはどのようなものですか? Nユーザーのグループにアクセスを許可する必要があるとします。 情報はランダムキー対称アルゴリズムで暗号化されます。 次に、このキーはN個の公開キーで暗号化されます。暗号化された情報+ N個の異なる暗号化されたランダムキーのインスタンスがパッケージ化され、署名され、グループメンバーに配布されます。 グループから誰かを除外するには、N-1キーを使用してプロセス全体を繰り返し、暗号化されたファイルの古いインスタンスをすべてのピアで削除するようにマークする必要があります。 または、古い情報が引き続き利用可能であるという事実に納得できる場合、将来的にユーザーキーを使用してランダムキーを新しい情報N-1に暗号化するのは非常に簡単です。 逆に、グループの新しいメンバーにアクセスを許可する場合は、すべての古いファイルのキーを彼に送信するだけで十分です。
これは、暗号制御を実装する最も簡単な方法です。 分散キーの数を減らすために、さまざまな階層派生グループキーを使用できます。 Nの代わりにO(logN)キーを省くことができますが、これはスキームを非常に複雑にします。 制限では、Nが非常に大きい数であり、キーを置き換える可能性が原則として存在しない場合、
AACS (
DRMの基礎)のようなモンスターが判明します。 DRMの法的、社会的、および倫理的な側面は別として
、AACSデバイスは非常に楽しいものです。 サブセット差分木システムは、量子力学にやや似ています-もしあなたがそれを理解すると思うなら、あなたはそれを理解しません。 少なくとも、私は彼女の仕事を理解している間、3つまたは4つのレベルの誤った理解を経験しました(多分もっとあるかもしれませんが、残念ながら、私は深く掘り続ける自由な時間はあまりありません)。 暗号化アクセス制御の詳細については
、こちらを参照してください。ドキュメントの2.3章を参照してください。 。
ファンタジーと憶測
分散Webサイトが一般的になるには何が必要ですか?
まず、インフラストラクチャ。 uTorrentなどのクライアントプログラム、FireCoralなどのブラウザープラグイン、またはOpera UniteなどのWebサーバーのブラウザーサポート。 このインフラストラクチャはどのような機能を提供する必要がありますか?
- 訪問したサイトの暗黙的な自動分散キャッシュ。 (例-FireCoral、BitTorrent DNA)
- サポートするサイトにコンピューターリソースを明示的に提供する。(まだ例はありません。思い浮かぶのは、ウィキリークスに関する最近のイベントです。シンパサイザーが数百のサイトミラーを手動で作成したときです)
- 自分のリソースをP2Pクラウドに公開または保存します。(例-Diaspora、Opera Unite、Wuala)
第二に、Webアプリケーションのアーキテクチャ。- Webサーバーは、独自のP2Pネットワークのトラッカーおよび認証センターになる必要があります。
- . - , . , . - key-value . , , .
- , .
- Push on change Pull on demand.
たとえば、Habrahabrが配布された場合にどのように機能するかを想像してください。インフラストラクチャ全体がすでに存在し、機能していると仮定します。メインページに移動すると、サーバーから、ページ自体とそのハッシュをダウンロードできるピアの現在のリストのみを取得します。ページ自体もあまり一般的ではありません。全体をキャッシュすると、ライブブロードキャストなどの頻繁に変更されるフラグメントや、各トピックの下にあるコメントの数が原因で、ほぼ瞬時に陳腐化してしまいます。したがって、ページの静的フレームが最初に揺れるのは、ヘッダー、フッター、スタイル、およびJavaScriptです。これらは、ロード後に、さらにいくつかのリクエストで動的なピースをプルアップします。さらに、これらのピース自体も更新の速度が大きく異なります。 「ライブ」を1分間に数回更新できる場合、「24時間のベスト」はほとんど変わりません。実際、これはまさにサーバー側のキャッシュが今のように見えるものです。ほぼすべての動的ページは、そのような多少の静的部分で99%構成されています。違いは、完成したページがクライアント側でこれらのピースから組み立てられ、ピース自体がP2Pネットワークにあることです。データ更新はどのように配布されますか?誰かがこのトピックについてコメントを書いたとします。コメント、評価、またはページの更新のいずれを作成する場合でも、クライアントは各リクエストで、自分のサイトおよびアクセスしたノードのピアのリストを更新します。ディスカッションに積極的に参加すればするほど、宴会のリストの関連性が高まり、新鮮な情報が早く得られます。つまり、すべての更新プログラムは主にローカルで配布され、現在話題になっている「群れ」の中にあります。更新はHabrauserによって署名されるため、何かを偽造したり台無しにしたりすることは非常に困難です。極端な場合、たとえば、いくつかのノードが情報を共謀して故意に歪めた場合、不名誉は長くは続きません。中央サーバーは数分ごとに「私たちを見て」、新鮮なコメントと評価を保存し、それらの信and性と妥当性を検証します。技術はこのスキームで完全に書かれていますpubsubhubbub(最も面白いのは、日本人が発音した言葉です)。原則として、中央サーバーがまったくなくても、サイトは一時的または永続的に機能します。これは、ネットワークの成長とコアオーディエンスの形成の初期段階でのみ必要です。将来的には、サーバーは単に作業を高速化および簡素化し、サイト所有者がプロジェクトの開発を管理できるようにします。レピュテーションアカウンティングシステムを使用すると、数十の最も権威のあるサイトがトラッカーや認証機関の役割を果たすことができ、コミュニティの安定性と分散データベースの整合性を維持できます。そのようなネットワークを破壊または制御するには、ほとんどの信頼できるノードを同時に捕捉する必要があります。これは、中央サーバーを切断するよりもはるかに困難です。そのようなサイトを一般的に破壊不可能にするために、思い付くことが残っていますDNSの分散型アナログ。または、DNSを分散検索エンジンに置き換えることができます。たとえば、Wikileaksからドメインが1つずつ削除されると、サイトはGoogleの発行で最初にハングし続け、ドメイン名の代わりに、しばらくの間誇張された裸のIPアドレスになりました。そして、ドメインとは何なのかさえ知らず、単に「VKontakte」という単語を入力し、上から最初のリンクをクリックするだけのティーポット-これは空想ではなく現実です。分散DNSまたは分散Googleの作成と実装がより困難なのは不明です。そして最後に、完全に分散されたアーキテクチャのもう1つの素晴らしい機会は、部門ごとの複製です。十分にまとまりのあるユーザーのサブグループが形成されていれば、分散サイトを「分岐」することは技術的に難しくありません。時間の経過とともに、1つのサイトのサイトでツリー全体が成長する可能性があります。おわりに
このトピックは、一部の人にとってはあまりにも理想的すぎるように見えるかもしれません。技術のほとんどはまだかなり湿気が多く、信頼性が低いようです。しかし!
上部の数字に戻ります。現在アイドル状態になっているこれらのペタバイトのすべてに到達する可能性が少なくともある場合は、試してみてはいかがですか?結局のところ、これは大量のファイル共有とクラウドコンピューティングほど悪くない革命です!変化はすでに起きています。データベースとファイルシステムへのアクセスはブラウザーにクロールし、JavaScriptはサーバーにクロールし、NoSQL DBMSは勢いを増しており、ローカルネットワークとインターネットの速度の差は消えつつあります。彼を信じたい。たぶん時が来た?UPD:すでにこのトピックを読んだ少数の人々は、彼らがhatch化した(そしてすでに気づいている)作者の空想に疑わしいほど類似したプロジェクトを作成するための陰湿な計画を認めました。経験のある人はここで(初心者向け)経験とアイデアを交換することをお勧めします。おそらく何か面白いものが出てくるでしょう!UPD2:それから、私のファンタジーに非常によく似たアイデアが近隣のトピックに登場しました。さらに読むためのリスト
記事の執筆過程で見つかったが、本文にリンクが含まれていない興味深いドキュメント。ほとんどどこでも-PDFへの直接リンク:ネットワークファイルシステムの暗号化アクセス制御リモートプロシージャコールXPeerの 暗号化アクセス制御:自己組織化XML P2Pデータベースシステムピアツーピアデータベースシステムでの柔軟な更新管理プッシュのための柔軟なアーキテクチャデータベースのP2Pネットワークは、ベースのBitTorrentベースのピア・ツー・ピアデータベースサーバA放送の調査暗号化(ハード慎重に、Matanを!)CDNの出版物リストにコーラルプロジェクトピアツーピア・ネットワークスの攻撃システムをゲーミングオンラインチート耐性P2Pネットワークの設計をピアツーピアファイルシステムのコンテンツの保護Building secure systems on & for Social NetworksSecure Peer-to-peer Networks for Trusted Collaboration