XSDは、XMLドキュメントの構造を記述するための言語です。 XMLスキーマとも呼ばれます。 XMLスキーマを使用する場合、XMLパーサーはXMLドキュメントの正しい構文だけでなく、その構造、コンテンツモデル、およびデータ型もチェックできます。 多くの場合、ドキュメントが特定のスキームに準拠しているか、エラーの可能性を報告することを保証する完全な検証手順に何らかの形で遭遇しています。 この記事では、上記に加えて、有効な文書をその場で設計できるようにする部分的な検証に焦点を当てます。 このアプローチが提供する可能性のある機会と、それを実装する方法を理解します。
主な目標
特定のプロパティを使用してドキュメントを作成する必要があるのはなぜですか?また、どのプロパティを制御できますか? 最初の質問に対する答えはほとんど明白です。 ほとんどの文書は単なるテキストではなく、いくつかのセマンティクスを備えています。 XMLは構文表現の問題を解決し、スキーマは意味的な意味の問題を部分的に解決します。 ドキュメントがスキームに準拠しているため、有効なドキュメントのクラス全体に対して有効な一連の事前定義済みアクションを実行できます。別の形式での表示、特定のタスクの重要な情報のエクスポート、グローバルな制限を考慮した新しい情報のインポートです。 この場合に最も一般的に使用されるメカニズムはXSLT変換です。その意味は次の図で説明できます。
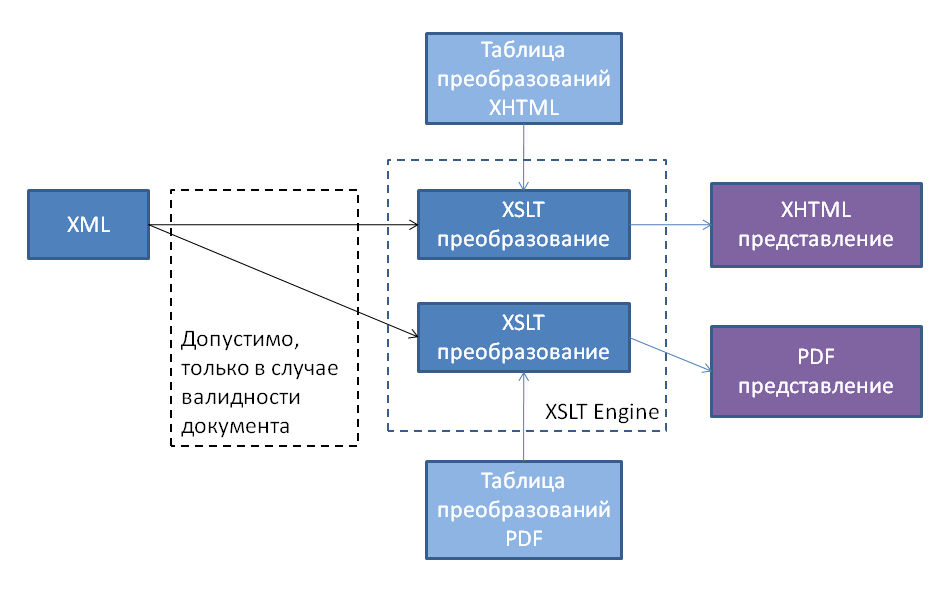 回路
回路の
仕様は 2番目の質問に完全に答えますが、回路の機能を理解するための最も重要な点についてのみ説明します。 そのため、このスキームでは次のことができます。
- データノードと属性の類型化を厳密に制御します。
- ノードのシーケンスを決定し、必要なノードと属性の存在を監視します。
- 特定のコンテキストで要素の一意性を要求します。
- コンテキストに応じて、一部の属性またはその他の属性の存在を必要とするバリアントノードを作成します。
- ノードまたは属性のグループで特定の述語の実行を要求します。
簡単な例として、記事の目次を引用できます-スキームはデータのセマンティクスを設定できます「タイトル-ページ」、ページが昇順であること、同一の名前がないこと、定義済みの要素「紹介」が「参照」に行き、もしあれば必要です結論の要素。 最も複雑で強力な例は
XMLデータベースです
。XMLデータベースでは、類型化とデータの有効性の両方がスキーマのみによって決定されます。
有効性を失わないように、選択されたスキームを既に満たしているドキュメントを変更したいことがよくあります。 ここでは、ドキュメントへの情報のWebエージェント(アグリゲーター)の追加やXMLデータベースのクエリの変更などの自動変更、および視覚的なXMLエディターでの手動変更について説明しています。 大きなドキュメントの完全な検証操作には、数十秒以上のかなりの時間がかかる場合があり、一般に「原子の変更-検証-拒否/解決」アプローチを使用できません。 そして、ビジュアルエディターの場合は、さらに多くのことを望みます。アトミックアクションをチェックできるだけでなく、スキームに従って有効な特定のノードを変更するためのすべてのオプションを提供できるようにします。 ただし、
優れたXMLエディターはこれを実行できます。どのように実行するかを理解しようとします。
必要なXMLスキーマ情報
W3C XMLスキーマは、
XML DTD (ドキュメントタイプ定義)のアイデアを発展させたものです。 両方の標準は、このドキュメントの構文上の制限に関してクラス(またはタイプ)を記述する一連の宣言(パラメーターオブジェクト、要素、および属性)によってドキュメントのレイアウトを記述します。 DTDは、アトミック用語またはタイプディクショナリの要素に対する一連の正規表現を考慮します。 各タイプは、他のタイプ、アトミック用語および代替操作「|」、連結「、」および演算子「?」、「+」、「*」、意味のオプション、1つ以上の存在、またはゼロ以上に基づいて構築されます要素。 XMLスキーマはXML DTD構文とは異なり、DTDの機能を次の3つの方法で拡張します。
- 指定した名前空間に一致する要素を使用できるテンプレート(any、anyType、anyAttribute)。
- 特定のタイプの説明の代わりに使用できるタイプのセットを定義する置換グループ。
- 繰り返しの数。各要素について、タイプ内のオカレンスの最小および最大許容数を決定します(Kleene演算子の一般化:「*」、「+」)。
スキーマのアルゴリズムによる検証は、DTD [1]の対応するタスクよりも複雑なタスクですが、XMLスキーマを記述するための後の標準は、検証を非常に容易にする規則によって補足されます。
Unique Particle Attributionルールでは、ドキュメントの各要素が、親要素のコンテンツモデル内の任意の1つのxsd:elementまたはxsd:任意の粒子に一意に対応している必要があります[2]。
一般的に、Unique Particle Attribution(UPA)ルールはXMLスキーマの構造に対する厳密な要件ではありませんが、非常に望ましい推奨事項と使用されているスキーマの一部のみがこれに準拠していません。 パーティクルの定義に関する一意性の規則への違反を示す最も単純な例を考えてみましょう。
次のようにスキームを定義します。
<xsd:element name="root">
<xsd:complexType>
<xsd:choice>
<xsd:element name="e1"/>
<xsd:any namespace="##any"/>
</xsd:choice>
</xsd:complexType>
</xsd:element>
次に、1つの要素で構成されるXMLドキュメントは、一意性の規則への違反を証明します。 要素は、xsd:elmentおよびxsd:任意のブランチに同時にマッピングできます。
幸いなことに、ほとんどのすぐに使えるスキームはUPAルールに従います。 スキームがUPAルールに準拠している場合にのみ、さらなる考慮事項が当てはまりますが、一般に、推論を少し変更するだけで、速度の低下により互換性のないUPAスキームでも正確性を達成できます。
検証ツールの構築
まず、構造の基本的な変更を定義します。これは、正確性をチェックします。
- 追加:位置nにタイプxのサブアイテムを作成。
- 削除:位置nのサブ要素を削除します。
- MOVE:要素を位置nから位置mに転送します(転送は要素の削除と追加に限定されますが、中間状態はドキュメントの有効性に違反する場合があります)。
次に、複雑なスキーマタイプのコンテンツモデルについて説明します。
- 粒子:
•MinOccurs-用語の繰り返しの最小数(0の場合、用語はオプションになります)。
•MaxOccurs-項の繰り返しの最大数(無限は許可されます-inf)。
•用語:要素の説明、パターン、シーケンス、または選択。
- 要素の説明(typedef):
•ローカル名。
•名前空間の名前(省略できます。その場合、要素は任意の名前空間で有効と見なされます)。
•置換グループ-typedefを含む式で受け入れられるすべての要素のセット。
- テンプレート(任意):
•置換要素に有効な名前空間の名前(存在しない場合があります)。
- シーケンス:
•許容される粒子の順次リスト。
- 選択肢:
•許容される多くの粒子。
検証アルゴリズムに直接アクセスできます。 最初に必要なアクションは、「スキームのタイプ」->「このタイプの要素の子孫の有効性をチェックできるオートマトン」を作成することです。 タスクは、次の2つの再帰アクションになります。
1.与えられた粒子から与えられた最終状態Sを持つ非決定
性有限状態機械 (NFA)の構築:
a。 Sに初期状態nを設定します。
b。 MaxOccursパーティクルが無限大(inf)に等しい場合:
•新しい中間状態tを追加します。 用語のNFAへの変換から取得(ケース2)。 tからnおよびnからSにイプシロンエッジを追加します。
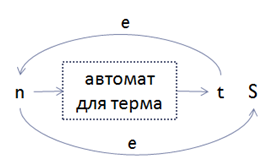
c。 MaxOccursパーティクルの数がmの場合:
•(MaxOccurs-MinOccurs)用語変換のチェーンを構築し、最終状態Sから開始し、各ステップで中間状態から最終状態Sにイプシロンリブを追加します。
たとえば、MaxOccurs = 4およびMinOccurs = 2の場合、次のオートマトンが取得されます。
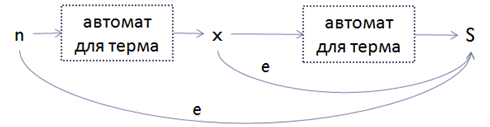
d。 新しい初期状態nから前の手順で取得した初期状態への用語変換のminOccursコピーを作成します。
2.与えられた用語で与えられた受信状態Sを持つ非決定性有限状態マシンの構築:
a。 用語がテンプレート(any)の場合:
•新しい状態bを作成し、用語タイプでマークされたエッジでSに接続し、bを返します。
b。 用語が要素の説明の場合:
•新しい状態bを作成し、置換グループの各要素に対して、要素のタイプでマークされたbからSへのエッジを作成し、bを返します。
c。 用語が選択の場合:
•新しい状態bを作成します。選択した要素ごとにオートマトンを作成し(ケース1)、状態bおよび状態Sのイプシロンエッジに接続します。bを返します。
d。 用語がシーケンスの場合:
•各選択要素について、オートマトンを作成し(ケース1)、取得したオートマトンを状態Sから逆順で接続し、チェーンの最初の状態を返します。
次に、取得したNFA [3]に
トンプソンアルゴリズムを適用して
、決定性オートマトンを構築します。 トンプソンアルゴリズムは、同じラベルの非イプシロンエッジの折り畳みに基づいて、決定オートマトンAhoおよびUlmanを構築するアルゴリズムと同じ場合に適用できます[4]。 ただし、場合によっては、元のオートマトン(手順1〜2で作成)を使用すると、Aho and Ulmanアルゴリズムは決定的なオートマトンを構築できません。
これは、次のような1つの頂点から2つの外向きのエッジがある場合に発生します。
- それらのラベルは、同じローカル名と名前空間名を持つタイプの説明です。
- ラベルは、重複する領域を持つパターンの名前です。
- 一方のエッジのラベルはテンプレートであり、もう一方はタイプの説明であり、両方とも同じネームスペースにあり、タイプの説明はテンプレート領域に含まれています。
各ケースがUPA制限の違反に対応していることを示すのは簡単です(3番目のケースは、パーティクル定義の一意性の規則に違反するスキームの例ですでに検討されています)。 したがって、これらの点は解の正確さを妨げません。アルゴリズムの出力では、対応する型の要素の内容を検証する決定論的な有限状態マシンを常に取得します。
提案されたアルゴリズムを各タイプの回路に適用し、このタイプの要素の子孫をチェックできる対応タイプ->オートマトンを取得します。
最後の問題である、特定のツリー要素で操作を検証するときの目的の有限状態マシンの選択を解決することは残っています。 ほとんどすべて(たとえば、
MSXMLやlibxml)の完全なバリデーターによって生成された検証タイプ(PSVI、
事後検証情報セット)のバインディングの構造が役立ちます。 ツリーの任意の要素について、スキームの説明でそれに対応する型を示します。これは、目的のオートマトンを生成した正確な型です。

この場合、PSVI構造の実装は、ツリーの各要素のスキームのタイプへの参照によって表されます。
MOVEおよびREMOVE操作はオペランドのタイプを変更しないため(したがって、PSVI構造を変更する必要はありません)、x要素の追加に伴うADD操作ではPSVI構造にxタイプを追加する必要があります。 したがって、構造の変更とともに、検証タイプのバインディングの情報セットを変更し、部分検証の問題を解決し、外部検証を呼び出すことなくPSVIツリーをサポートします。
結果の比較
一般的に、直接の比較はありません-結局、特定のケース(UPA準拠)で特定の問題(操作ADD / REMOVE / MOVE)を解決するアドインについて説明しましたが、この場合、完全な検証を使用しようとする場合に比べて、速度が大幅に向上することを示したいと思います。 PSVIを生成する参照バリデーターとしてMSXML6が選択されたため、それを動作時間と比較します。
| 構造要素の数 | ネストレベル | 回路タイプの数 | MSXML6の平均検証時間 | 説明されているアドインを使用した平均検証時間 |
| 32 | 4 | 16 | 10ミリ秒 | <1 ms |
| 32 | 4 | 40 | 16ミリ秒 | <1 ms |
| 120,000 | 4 | 16 | 51ミリ秒 | <2 ms |
| 120,000 | 4 | 40 | 62ミリ秒 | <2 ms |
| 120,000 | 32 | 16 | 2300ミリ秒 | <5ミリ秒 |
| 120,000 | 32 | 40 | 2600ミリ秒 | <6 ms |
したがって、非常に許容可能な平均スキャンタイムアウトが得られ、ビジュアルエディターでその場でドラッグアンドドロップメカニズムを実装でき、可能なXMLデータベースに対して1秒あたりのクエリ数が多くなります。
参照資料
[1] XML Schema Validator。 トンプソン、ヘンリーS.およびR.トービン、W3C、エジンバラ大学、2003年。
[2]
XMLスキーマパート1:構造。 ヘンリー・S・トンプソン、デビッド・ビーチ、マレー・マロニー、ノア・メンデルゾーン、編集者。 W3C勧告、2001年。[3]
正規表現のマッチングは簡単で高速です。 ラスコックス、2007年。[4]コンパイラ構築の原則。 A.アホ。 D.ウルマン。 M。:ミール、1977年。