最近、個々のノードのレベルで視覚化または分析できない数百万のノードからソーシャルネットワーク内のコミュニティを識別するための効果的なアルゴリズムを開発するために、多くの試みが行われました。
ベルギーの開発者は、計算速度において既存のすべての同等物を上回る
新しいアルゴリズムを
導入しました 。 その結果、前例のないサイズのベースで使用できます。200万ノードの典型的なネットワークの分析には2分かかります。 すべての開発者がルーバン(ベルギー)で働いていたときに作成されたため、ルーバンメソッドと呼ばれます。
Luvenskyメソッドは、結果を検証できる既知のコミュニティ構造を持つネットワークでテストするときに、その正確性を証明しました。 階層構造のため、さまざまなスケールでコミュニティを分析するのに適しています。 特に、ベルギーの携帯電話会社のネットワーク(260万人の加入者)のコミュニティと、クローラーのStanford WebBaseによって収集された
Webページ (1億1800万のノードと10億を超えるリンク)に
基づいてテストされました。
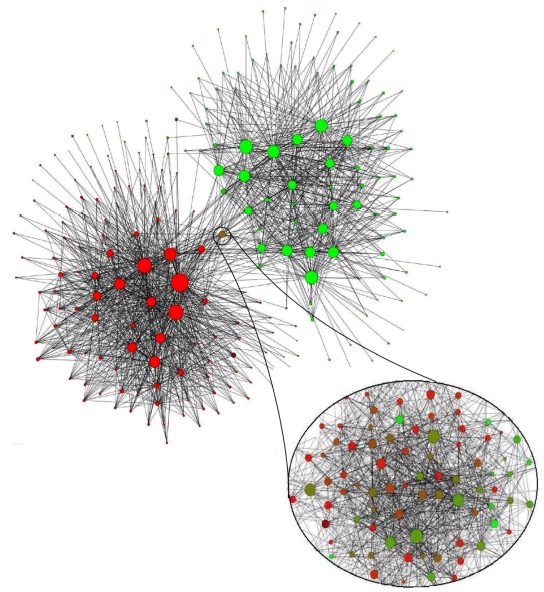 ベルギーの携帯電話会社のネットワークにおける加入者ベースの分析結果。 フランス語を話すコミュニティは赤でマークされ、オランダ語は緑でマークされます。 両方の言語で通信する「中間」コミュニティのセクションが拡大されています。 このスケールでは、100人を超える人々のグループが表示されます。
ベルギーの携帯電話会社のネットワークにおける加入者ベースの分析結果。 フランス語を話すコミュニティは赤でマークされ、オランダ語は緑でマークされます。 両方の言語で通信する「中間」コミュニティのセクションが拡大されています。 このスケールでは、100人を超える人々のグループが表示されます。この方法は2つの段階で構成されています。 1つ目は、ローカルレベルでモジュール性を最適化することによる「小さな」コミュニティの検索です。 2番目の段階では、1つのコミュニティのノードが集約され、より大規模な新しいネットワークが構築されます。その後、これらの段階がモジュール性の最大レベルに達するまで繰り返されます。
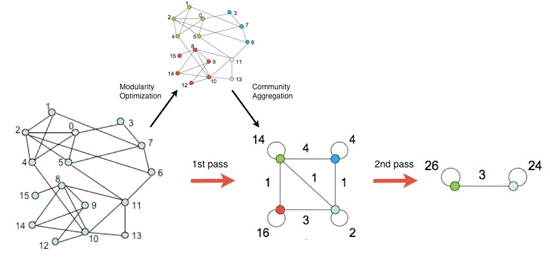
したがって、各段階の後に、プログラムはより大きな規模のコミュニティを表示します。
詳細について
は、大規模ネットワークでのコミュニティの高速展開を参照
してください。 例えば、アルゴリズムClauset / Newman / Moore、Pons / LatapyおよびWakita / Tsurumiと比較したアルゴリズムの品質と速度の表が含まれています。 各タスクについて、24 GBのRAM(24時間を超える場合はダッシュ)を搭載したOpteron 2.2 GHzマシンのモジュール性とランタイムのレベルが示されます。 結果から判断すると、Louvainメソッドには文字通り同等のものはありません。
 C ++
C ++および
matlabのプログラムは無料です。