Xapianという言葉がよく知らない場合は、短い
記事を読むことをお勧めします。
要するに、XapianはC ++で書かれたテキスト情報のインデックス作成ツールであり、インデックス化された情報のデータベースを検索する機能を備えています。 動作するためにインストールされたサーバーを必要としません;そのライブラリは十分です。 何百万ものドキュメントで測定される膨大な量の情報(1.5Tbまで検証済み)を処理できます。 これは、SphinxとApache Luceneの競合製品です。
これらの3つの製品の中から、.Netから使用できる能力が選ばれました。
まず、.Net用のXapian dll 'kiを
ダウンロードする必要があり
ます 。
次に、C ++でコンパイルされたラッピングdllにアクセスしようとすると、別の補助DLL-
Zlib1.dllが例外なしでスローされます。
実際には仕事のために、これが必要なすべてです。 プロジェクトを作成できます。 XapianCSharp.dllがすぐにリファレンスに追加されます。 _XapianSharp.dllおよびzlib1.dllをプロジェクトに(コンテンツとして)追加し、出力ディレクトリにコピーを常にコピーとしてマークします。
作業をテストするために2つの関数を作成します。
.... using Xapian; ....
Write関数を好みに合わせて作成します。
テキストファイルを含むディレクトリを作成するか、既存のディレクトリを使用して、IndexFolder(directory_name)を呼び出し、ファイルのインデックスが作成されるまで待ちます。 また、検索用のキーワードを含む文字列をスペースで区切って渡すSearchを呼び出すことができます。
テスト。
鉄の構成:
Intel Pentium III 996Mhz
ラム256Mb
インデックスファイルの数:641489
インデックスファイル:2,38Gb
ファイルのインデックス作成時間:1週間以上(ハードウェアを思い出してください。4xCoreでは、操作に数時間かかる可能性が高く、それに応じてスワップによりパフォーマンスが低下する場合があります)
インデックス負荷
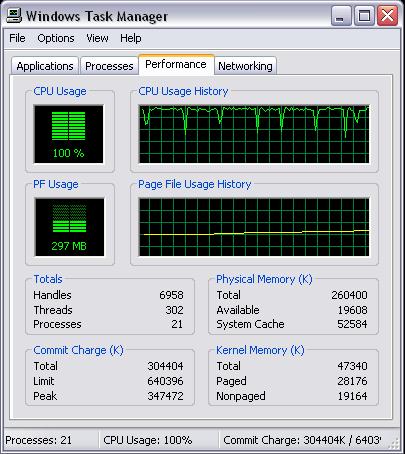
テーブル平均検索時間
| 単語数 | 検索する | 時間 |
| 1 | 1 | 1883ミリ秒 |
| 1 | 2 | 28ミリ秒 |
| 1 | 3 | 31ミリ秒 |
| 2 | 1 | 175ミリ秒 |
| 2 | 2 | 36ミリ秒 |
| 2 | 3 | 41ミリ秒 |
| 3 | 1 | 1074ミリ秒。 |
| 3 | 2 | 35ミリ秒 |
| 3 | 3 | 37ミリ秒 |
指標は非常に楽観的で、特にこのような弱い車にとっては楽観的です。
ソース:
codeprojectに関する記事公式サイト