70年前の1941年に、最初のプログラム可能なコンピューターが作成されました。 それ以来、大量の水が流れ、今ではコンピューターがあらゆる場所を取り囲んでいます。 コンピュータの設計の多くの側面は大きく進化しましたが、多くは本質的にまったく変化していません。 特に、中央
処理装置の動作原理
-アルゴリズムモデル
-は変更されておらず、おそらく変更されません。 このモデルの物理的な制限は十分に理解されており、したがって、速度という意味での中央処理装置の開発の限界がはっきりと見えます。 技術的には、この上限はまだかなり遠いです:数十年の開発と数桁の速度。 しかし、これにより、高速開発の限界に迫るプロセッサの種類を真剣に考えることを妨げてはなりません。
可能な開発経路は、光の速度の有限性、熱力学の法則、
要素の最小サイズの制限などの基本的な物理的制約によって厳密に決定されているという事実です。
パート1.現在および将来のコンピューティングデバイスの原則
その存在の初期の数十年では、コンピューターはコンピューティングのみに使用されていました。 「コンピューター」という言葉の元の意味は、ロシア語では「自動コンピューター」(AVM)と訳されています。 少し後に、コンピューターは他のデバイスの制御要素としても使用されるようになり、「コンピューター」という言葉は「
汎用プログラム実行プログラム」という現代的な意味を獲得しました。 今日、AVMは高度に専門化された(コンピューターセンターで使用される)デバイスであり、制御要素としてのコンピューターは、マイクロ波からロボット生産ライン、携帯電話から宇宙船まで、ほぼすべての自動
デバイスで使用されています。 特に、ラップトップ、デスクトップワークステーション、ゲームコンソール(家庭用コンピューターと呼ばれるデバイス)で制御的な役割を果たします。
いくつかの大きく異なる計算モデルがあるため、将来のAVMはおそらく完全に予想外の方法で配置されるでしょう。 ただし、制御デバイスとしてのコンピューターには、いずれの場合でも実行ユニット(中央処理装置)が含まれている必要があり、このユニットのデバイスはその機能によって厳密に固定されています。
-他のデバイスに一貫した指示を発行し、
-現在の状況に応じて、さらなる行動プログラムを選択します。
これらの2つの要件は、英語の「緩和された順次実行」またはロシア語の伝統の「アルゴリズムモデル」と呼ばれるデバイスモデルを自動的に想定しています。 量子コンピューティングは基本的に可逆であり、選択を行うことは基本的に不可逆であるため、このモデルは他の多くのモデルとは異なり、量子に対応するものがありません。 このモデルについては、記事の次の2つの部分で説明します。
ストーリーを完全にするために、現時点で知られている計算のすべてのスケーラブルなハードウェアモデルのリストを示します。
-アルゴリズムモデル、つまり、(条件付きで)命令の段階的な実行(「条件付き」は、独立した命令の並列実行が許可されることを意味します)。
-ストリームベクトルコンピューティングとその自然な
一般化-量子コンベア。
-セルラー/ネットワークオートマトンとその自然な
一般化-量子オートマトン。
現在、実際には、シーケンシャル実行モデルを除き、ストリーミングベクトル計算のみが使用されています.3次元グラフィックス(GPU)用の専用コプロセッサーの家庭用コンピューター、および数値シミュレーションと大規模なデータ配列の処理のためのコンピューターステーションの高出力アナログ(GPGPU)で使用されています。 中央処理装置は特定のタスクをストリーム処理装置に委任しますが、制御機能を実行するのは自分自身だけです。 量子コンピューティングの開発により、この状況は変わることはほとんどありません。量子パイプラインとマシンは、中央プロセッサへの追加のみであり、その代替ではありません。
パート2.現在および将来のプロセッサの要素ベース
基本レベルでは、プロセッサは2種類の要素で構成されています。スイッチとそれらを接続するトラックです。 トラックのタスクは信号を運ぶことであり、スイッチのタスクはこの信号を変換することです。 スイッチとトラックにはさまざまな実装があります。
私たちの周りのデジタルエレクトロニクスでは、トランジスタはスイッチとして使用され、トラックは導体で作られています。
§2.1。 信号伝送
バイナリデジタルエレクトロニクスでは、電圧を使用して信号をエンコードします。 トラックは、電位
(U 0 ±ε)が適用されると「ゼロ」信号を搬送し、電位
(U 1 ±ε)が適用されると「1」信号を搬送します。 U
0およびU
1の基本レベルは、(U
0 +ε)<(U
1 -ε)となるように選択されます。ここで、
εは技術的な理由で不可避です。 ある状態
から別の状態
への遷移は、導体内の膨大な数の電子の停止または逆の加速です。 これらのプロセスは両方とも非常に時間がかかり、必然的に大きなエネルギー損失に関連付けられます。
この欠点のないデジタルエレクトロニクスに代わるものがあります:トラックに沿って電子(いわゆるスピントロニクス)または光子(いわゆるフォトンロジック)の一定のストリームを送信し、このストリームの偏光を使用して信号をエンコードできます。 1次元の導波路に沿って移動する電子と光子の両方は、正確に2つの直交偏光状態に存在でき、その1つはゼロと宣言され、もう1つは宣言されます。 どちらが良いですか-光子ロジックまたはスピントロニクス、それは明確ではありませんが:
-どちらの場合も、粒子流は避けられない熱損失で流れますが、これらの損失は任意に小さくできます。
-どちらの場合も、流速は光の速度よりも低くなりますが、任意の速度に近づけることができます。
-どちらの場合も、干渉、熱雑音、バックグラウンド放射(ランダムな粒子が飛んでくる)が信号を歪まないように、複雑な技術が必要です。
つまり、両方の技術の既知の物理的制限は同じです。 最も可能性が高いのは、複合技術が最良の結果をもたらすことです。光子輸送は長距離で勝ち、短距離で損失します。 同時に、光子の偏光と電子束の間のアダプター(両方向)の実用プロトタイプがすでに開発されています。 グラフェンは、スピントロントラックに最適な材料です。非常に低い熱損失で優れた速度を提供します。 さらに、次の要素の作業プロトタイプが既に存在します。
-短距離および中距離で現在の分極を確実に維持するトラック。
-分極を保存し、保存された分極のストリームを形成できるメモリセル。
グラフェントラック情報:
2010-06:
グラフェンナノワイヤの大量生産
。 ジョージア工科大学。
2011-01:
研究者はグラフェンでスピン流を生成することに成功しました。 香港市立大学。
2011-02:
グラフェンの純粋なスピン流の作成。 香港市立大学。
2011-02:
可溶性の欠陥のないグラフェンナノリボンの大量生産に対応したボトムアップ合成。 マインツのマックスプランク高分子研究所。
§2.2。 スイッチ
デジタルエレクトロニクスで使用されるトランジスタは、次のように動作する3ピンデバイスです。
-中間の接点に高電位が印加されると、極端な接点が接続され、スイッチは「導体」位置になります。
-低い電位が中央の電位に印加された場合、極端な接点が開き、スイッチは「絶縁体」の位置になります。
現時点では、1つの分子で構成されるトランジスタの作成とテストに成功しています。 それらの速度とコンパクトさは理論上の限界にほぼ達しますが、これまでのところ、大量生産と使用を可能にする技術はありません。 最新のデジタルエレクトロニクスはすべて、金属酸化物電界効果トランジスタ(MOSFET)に基づいて作られています。 数十年間、チップメーカーはこのようなトランジスタの線形寸法と消費電力を削減してきましたが、いくつかのタイプのマルチターミナルおよびトランジショントランジスタ(BDT、JNT)の工業試験はすでに行われています。 このようなトランジスタは、
4〜6倍のパフォーマンスを提供できます。 この移行では、プロセスの大幅な変更は不要であり、今後
5〜10年以内に予定されています。
基本的な熱力学的な理由から、トランジスタ型のスイッチは効率的に機能できません。効果的なスイッチは、論理要素として保守的で可逆的でなければなりません。 フレドキンバルブとも呼ばれる対称スイッチは、これらの条件を満たします。
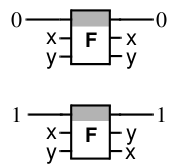
このデバイスには、2つの入力In
1 、In
2、2つの出力Out
1 、Out
2 、および
連続トラック
C(コントロール)があります。 Cが「0」の位置にある場合、入力と出力は直接接続されます。In1はOut
1 、In
2はOut
2です。 Cが「1」の位置にある場合、入力と出力は交差して接続されます。In1とOut
2 、In
2とOut
1です。 最も可能性が高いのは、最大のコンパクトさ、速度、効率を組み合わせた単一分子バージョンでスピン対称スイッチを実装できることです。
トランジスタと対称スイッチの両方を使用して複雑なロジック回路を作成できますが、対称スイッチの方がはるかに経済的です。 たとえば、信号と論理演算のクローンを作成するために、「not」、「and」、「or」、「and not」、「should」の場合、必要な対称スイッチは1つだけで、「exclude」、「not or」、「not and」は2つ必要ですスイッチ。 これらの操作をトランジスタに実装するには、4〜6個のトランジスタが必要です。


高速シングルビット加算器(半加算器)は、4個の対称スイッチ(12個のトランジスタの代わりに)を使用し、理想的にはトランジスタアナログよりも大幅に高速な動作速度を提供します:動作時間はわずか2τです(τは1つのスイッチと1つのトラックの信号通過時間です)。 より複雑な回路では、対称スイッチのコンパクトさと速度向上がさらに顕著になります。 マルチビット加算器(全加算器)のリンクは多数のトランジスタで構成されていますが、対称スイッチの実装には4(最もコンパクトなバージョン)から7(最速オプション)のスイッチが必要です。
対称スイッチのユニークな機能は、プロセッサの非常に一般的な構成要素であるマルチプレクサとデマルチプレクサの最大のコンパクトさと速度を実現するのに役立つことです。 残念ながら、対称スイッチは、スピントロニクスまたはフォトンロジックを使用する場合にのみ魅力的になります。 電子機器は、従来のトランジスタを使用する運命にあります。
*この段落では、
ブルース、ソーントンらによる記事の資料と画像を使用してい
ます。 、
「保守的な可逆論理に基づく効率的な加算回路」 (ミシシッピ州立大学、Proc。IEEE Symposium on VLSI、2002);
Rentergem、de Vos 、
「リバーシブル全加算器の最適設計」 (Universiteit Gent、International Journal of Unconventional Computing、2005)、およびプライベート通信。 単分子トランジスタの画像は、エール大学のウェブサイトの対応するプレスリリースから取得されています。
§2.3。 おわりにそのため、将来の中央処理装置は、おそらく、スレッドが分極した電子流を伝導するグラフェンテープで作られた巨大なウェブであり、ノードにはミニチュア対称スイッチがあります。 長距離にわたって、信号は光にトランスコードされ、光子によって配信され、宛先にトランスコードされます。 多くの特別なタスク(特に検索とソート)が、量子コンベヤーと自動機によって実行されます。
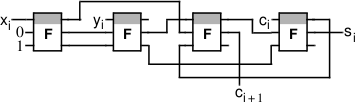
パート3.現在および将来の中央処理装置のアーキテクチャ
今日のすべての一般的な中央処理装置は、フォンノイマンアーキテクチャのレジスタマシンです。
-プロセッサには、特定の数(たとえば16)の番号付きメモリセル(たとえば、それぞれ64ビット)が含まれています。これらは操作レジスタと呼ばれます。
-プロセッサは、プログラムに従ってレジスタの内容を処理します。
-プログラムは一連の命令で、たとえば次のとおりです。
-レジスター2と5から値を取得し、レジスター8にその量を記録します。
-レジスタNo. 4に、レジスタNo. 6のアドレスを持つ外部メモリセルの値を読み込みます。
-レジスタ番号12から外部NNNデバイスに番号を送信します。
-データとプログラム自体はRAMに保存され、プログラムの命令は数字でエンコードされ、シーケンシャルメモリセルに書き込まれます。
-命令が現在実行されているセルの番号は、命令ポインタと呼ばれる特別なレジスタに格納されます。このレジスタは、実行の終了時に次のメモリセルに移動します。
このアーキテクチャの出現から半世紀以上にわたって、シーケンシャル実行を編成するための数十の代替アーキメティックシステムが提案されてきましたが、それらはすべてパフォーマンスの上限が劣っています。 パフォーマンスの上限は、構造の重要な部分の線形寸法によって決定されます(光の速度の有限性のため)。これは、現在提案されているすべての順次実行アーキテクチャから計算の最大局所性を提供する古典的なレジスタアーキテクチャです。 したがって、少なくともこのあと数十年間は、おそらくこのアーキテクチャが、おそらく
将来的に保存されるでしょう。
§3.1。 機能論理ユニット
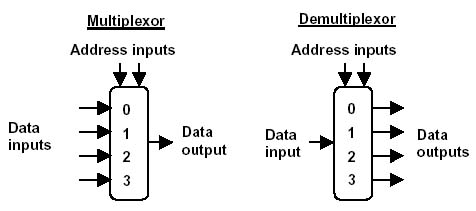
最初の部分で説明したスイッチとトラックは、加算器、乗算器、マルチプレクサー、デマルチプレクサーなどの機能ロジックユニットを製造するための「原材料」です。 マルチプレクサーとデマルチプレクサーは、鉄道のマーシャリングヤードに似たデバイスです(右の図を参照)。 マルチプレクサーの入力は、
n個の数字(
a 1 ..
a n )と制御数
mを受け取ります。 出力は数値
a m 、つまり
n個の 入力数値の
m番目です。 デマルチプレクサは、マルチプレクサのミラーアナログです。入力信号を
n 番目の出力の
m番目に転送します。
加算器のタスクは、供給された数値を追加することです。
nビット加算器の入力は、
nビットの 2つの数値
aおよび
bと、1ビットの数値
c (0または1)を受け取ります。 加算器は入力数値を加算し、結果
( a + b + c )を生成します。 これは
( n + 1)ビット数です。
機能論理ユニットは、引数の変化にすぐに応答しません。信号は、回路の最初から最後まで、スイッチを通過することによる遅延と回路内の可能なサイクルを考慮して、最後まで進む必要があります。 設計中の各機能論理ユニットについて、動作時間が計算されます。 最小限のランタイムで機能論理ユニットを設計する広範な理論が開発されました。 そのため、画像での加算と紙上の列での加算の類似性を実行する最も単純な複数桁の加算器は、ビット深度とともに直線的に成長するために作業する時間が必要です。 60年代には、成長を対数的なものに減らす加速移動スキームが開発されました。 対称スイッチでこれらを使用する加算器は、理論的な速度制限である⌈3+ log
2 (ビット容量)⌉・τの結果を計算することが保証されています。 64ビット加算器の場合、単純な実装と比較して15倍の加速が達成されます。 そして、三角関数の乗算、除算、および計算の巧妙な最適化により、何百回も加速することができます。
§3.2。 操作ブロック操作
ユニットは 、1つの
タイプの命令(たとえば、加算と減算)を実行できるデバイスです。 操作
ユニットの基本要素は、実行される命令が書き込まれるメモリセル(いわゆる命令レジスタ)です。 命令の実行時に、ブロックはこのセルをクリアします。 操作ブロックの残りの部分は、互いに接続され、命令レジスタに接続された機能論理ユニットのセットで構成されています。 たとえば、「レジスタ
No. 2および
No. 5から値を加算し、レジスタ
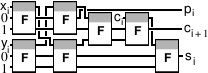
No. 8に金額を書き込む」という形式の命令に従うことができるオペレーティングユニットを考えます。
私たちは、必要があります。
-加算演算のコードとオペランドレジスタの番号を格納する命令レジスタ(上記のコマンドの2、5、8)。
-加算器;
-一方のレジスタブロックと他方の加算器の入力に接続された2つのマルチプレクサ:レジスタ命令(
番号2および
5 )に番号が格納されている2つのレジスタから選択し、内容を加算器の入力に送ります。
-1つのデマルチプレクサ。加算器の出力をレジスタ入力に送り、そこに格納する必要があります。
最新のプロセッサでは、オペレーティングユニットは複数のアクションを実行できます。 たとえば、ブロックには、加算器に加えて乗数が含まれる場合があります。 技術的な実装では、命令レジスタに保存されているオペレーションコードに応じて、加算器または乗算器を介して信号を送ることを選択するデマルチプレクサーとマルチプレクサーによってフレーム化された乗算器を加算器と並列に配置するだけで十分です。
§3.2.1。 運用サイクルの構成:同期、スーパースカラー、パイプラインプロセッサは、次のサイクルの繰り返しであり、その間、情報は「
レジスター→作動
ユニット→レジスター」という円で渡されます。
-実行する命令をオペレーティングユニットにロードします。
-結果を待ちます。
-結果をレジスタに保存します。
プロセッササイクルを編成するには、同期と非同期の2つのアプローチがあります。 同期プロセッサには信号導体があります。 変更されると(「導体が杖を振る」)、操作ユニットによって生成された値がレジスタに保存され、次の命令が操作ユニットに送信されます。 非同期プロセッサーには共通のコンダクター信号はありませんが、操作ユニット自体が結果の準備状況を報告します。 タスクとオペランドの準備が整った瞬間から、ブロックは結果の準備状況の監視を開始します。 計算の最後に、ブロックは結果を保存して次のタスクを要求するためのゴーサインを与えます。
同期プロセッサのクロック
速度は固定です-1秒あたりの「指揮者のバトンの揺れ」の数。 「スイング」間の時間は、最も悲観的なシナリオに基づいて選択する必要があります。 ただし、実際には、ほとんどの場合、操作に必要な時間は数倍短くなります。 3つの要因が実行速度に影響します。
-動作ブロックの初期状態:命令または引数の一部が事前にロードされている場合、ブロックの一部は事前に目的の状態になります。
-オペランドの値:したがって、短い数値の乗算は、長い数値の乗算よりもはるかに短い時間で済みます。
-バックグラウンドノイズレベル:
20°Cのプロセッサ温度では
、すべての操作が
90°Cの温度よりもはるかに速く進行します
。同期化されたアプローチでは、これらすべての要因を考慮することはできません。 さらに、温度に対するノイズレベルの依存性は、結晶
欠陥の濃度によって決まります。この値は、インスタンスごとに異なり、プロセッサが古くなるにつれて増加します。 プロセッサのクロック周波数を計算するときは、最悪から、つまり
85〜90°Cの温度で動作する使い古した平凡なインスタンスから処理を進める必要があります
。 この事実は、プロセッサのいわゆる「オーバークロック」を実行する人々によって使用されます。十分な冷却を備えた成功したインスタンスは、メーカーが設定したクロック速度を大幅に超えても安定して動作し続けます。
非同期プロセッサは、前のプロセッサの結果が準備でき次第、次の操作を開始します。 クロック周波数のようなものはありません。これらの条件では常に最大速度になります。非同期プロセッサにホットコーヒーを入れると速度が低下し、液体
窒素を注ぐと加速します。 ただし、非同期回路は、その複雑さにより、現在、少数の実験的な非同期プロセッサでのみ使用されています(1951年に
ILLIAC Iから2010年にGA144で終了)。 将来、最適化の他の領域が残っていないため、おそらくより多く適用されるでしょう。
10年以上にわたり、プロセッサは各タイプの複数のオペレーティングユニットをインストールしています。 このようなプロセッサはスーパースカラーと呼ばれます。 独立した
アクションを同時に実行できます。たとえば、命令
「c = a + b」と
「d = a・b」を並行して実行します。 広く使用されている別の最適化手法は、いわゆる「パイプライン化」です。オペランドが準備される前にタスク命令が演算ブロックに書き込まれ、マルチプレクサーとデマルチプレクサーが事前に目的の状態に到達し、演算時間が大幅に短縮されます。 ただし、同期プロセッサは各命令に所定数の「バトンの揺れ」を与えて実行するため、パイプラインを使用することの最大の利点は非同期プロセッサでのみ得られ、命令をブロックにプリロードすることによる利得は比較的小さいためです。 さらに、非同期プロセッサで各オペランドの準備状況を個別に監視する場合、命令をプリロードするだけでなく、オペランドの1つが以前に準備できているため、時間を短縮できます。
すべてのオペランドの準備が整う前でも命令が機能する場合があります。たとえば、オペランドの1つがゼロの場合、2番目のオペランドの準備が完了するまで乗算はゼロになります。オペランドの可用性を個別に制御する唯一の効果的な方法はレジスタの1回限りの使用。この用語は、各サブプログラムの動作中に、各レジスタへの書き込みが1回だけ実行されることを意味します(値が上書きされることはありません)。手順の最後に、使用されたすべてのレジスタが空の状態にリセットされます。これにより、オペランドの可用性を簡単に確認できます。オペランドを含むレジスタが空にならない限り、オペランドの準備が整います。個別のレディネス制御を簡単に実装するには膨大な数のレジスタが必要ですが、実際にはこれは必要ありません。実際には、少数のハードウェアレジスタを使用せずに多数の論理レジスタをエミュレートできます。§3.3。制御ブロックと割り込みブロック制御ユニットは、メインメモリに記録されたプログラムに従って、オペレーティングユニット間でタスクを分配します。 RAMからプログラム命令をロードし、それらをデコードし、デコードされた形式で空き動作ブロックの命令レジスタに送信します。さらに、分岐および分岐命令を実行します。つまり、操作レジスタの値に応じてプログラム分岐の1つを選択します。プロセッサには複数のコントロールユニットがあり、複数のプログラムを並行して実行できます。中央処理装置はプログラムを実行するだけでなく、ハードウェアの要求にも応答します。ハードウェアのリクエスト-これは、外部デバイスによって特別に割り当てられたプロセッサ入力に供給される信号です。たとえば、マウスボタンをクリックすると、プロセッサはこのイベントを処理するように要求されます。ハードウェア要求の処理は、割り込みブロックによって処理されます。要求を受信すると、割り込みブロックは空き制御ブロックを検索し、ハンドラープログラムを実行する命令を送信します。空きブロックがない場合、ブロックの1つを選択し、そのブロックで実行中のプログラムを一時的に中断し、ブロックをリダイレクトしてハードウェア要求を処理します。処理の終わりに、中断されたプログラムが再開します。割り込みブロックの名前の由来は、その作業のほとんどが正確にプログラムの実行の中断と再開にあるという事実にあります。§3.3.1。制御命令:ジャンプ、呼び出し、分岐、ループプログラムは、連続したメモリ位置にある命令エンコードされた数字のセットです。何らかの理由で、連続したセルに連続した命令を配置できない場合、通常はジャンプ命令が使用されます。このような命令を読み取ると、制御ユニットは命令で指定されたアドレスを命令ポインタに書き込みます。従来のアーキテクチャでは、残りのレジスタの状態は移行中に変化しません。歴史的に、ジャンプ命令の主な用途はサブルーチンを呼び出すことですが、現在は別個の呼び出し命令とリターン命令がこれに使用されています。呼び出し命令は、呼び出されたサブルーチンが「ゼロから」動作するように、引数が配置されているレジスタの範囲を除き、すべてのレジスタをマスクまたはクリアします(特別に割り当てられたストレージに値をリセットします)。 (マスキングは、値をストレージに移動するよりも高速に動作しますが、動的レジスタの名前変更を使用するプロセッサでのみ実装できます。)サブルーチンの実行結果。特別なケースは、いわゆる末尾呼び出しです。つまり、特定のサブルーチンfが「gを呼び出して実行結果をより高いレベルに戻す」などの命令のペアで終了する状況です。この場合、gを呼び出すときに、現在のレジスタと戻り点を保存またはマスクする必要はありません-代わりに、結果をfに戻してはならないという呼び出されたルーチンgを渡すことができます、すぐにより高いレベルに。テールコールは、移行中に保存するレジスタと破棄するレジスタを明示的に示すという点でのみ、このセクションの冒頭で説明した遷移と異なります。将来的には、「テールコール」遷移は、従来の遷移(動作レジスタの値を変更しない)を置き換えます。これは、従来の遷移が非同期実行とレジスタの1回限りの使用を妨げるが、「テールコール」遷移はそうではないためです。 (実際、returnステートメントは遷移の特別なケースである「テールコール」ですが、この美しい概念の議論はこのテキストの範囲を超えています。)呼び出しと遷移に加えて、制御ユニットは分岐命令を実行します。つまり、操作レジスタの1つの値に応じてプログラム分岐を選択します。分岐は従来、条件付き分岐命令を使用して行われますが、非同期プロセッサでは、従来の分岐操作ではなく、条件付き呼び出しまたは条件付きテール呼び出し命令を使用する方がはるかに優れています。この種の命令は、動作中のレジスタの値に応じて呼び出すサブルーチンが記述されているテーブルを示します。条件付き(末尾)呼び出し命令を使用すると、if-then-else、match-caseの形式の構成を効果的に実装できます、条件付き再帰、それに応じて、可能なすべてのタイプのサイクル。追加の実行制御操作は必要ありません。多くの場合、無料のコンピューティングリソースの分岐点に近づくと、呼び出されたルーチンの引数の大部分が準備できますが、どのルーチンを最終的に呼び出すかを決定する値は準備ができていません。この場合、最も可能性の高い1つ以上の手順の実行を投機的に開始し、「外部世界」に影響する操作のみを回避できます。パブリックRAMへの値の保存、外部デバイスへのアクセス、手順からの戻り。多くの状況でのこの最適化手法により、生産性が2倍以上向上します。分岐の例:match (a <> b) { case 0: { print "a and b are equal" } case 1: { print "a is greater than b" } case -1: { print "b is greater than a" } }
分岐の最も一般的な特定のケース
は 、if-then-elseバイナリ分岐です。
if (condition) { do_this } else { do_that }
≡
match (condition) { case True: { do_this } case False: { do that } }
再帰の例:
def gcd(a, b) = { if (b = 0) return a else return gcd(b, a % b)
§3.4。 おわりにどうやら、中央処理装置のアーキテクチャはフォン・ノイマンのままです。 パフォーマンスの向上は、命令の並列化と非同期回路への移行により改善されます。 可能な限り最高の並列性を確保するには、より高度な
命令セットに切り替える必要があります。特に、レジスタの1回限りの使用に適しています。
最新のプロセッサは、1〜16個のコントロールユニットと4〜64個のオペレーティングユニットを使用します。 非同期回路への移行では、数十個の制御ユニットと数百個の操作ユニットを使用することが正当化されます。 このような移行と、それに対応するブロック数の増加により、ピークパフォーマンスが2桁以上、平均生産性が1桁以上向上します。
パート4。ↁⅠⅩが欲しい!
1962年に、ドナルドクヌースは有名な本シリーズThe Art of Programmingの執筆を開始しました。これは、効果的なアルゴリズムを説明し、その速度を分析します。 低レベルのアルゴリズムを記述し、その実行時間を正確に評価する機能を維持するために、彼は高レベルのプログラミング言語を使用せず、アセンブラーで記述することにしました。 しかし、実際のプロセッサのアーキテクチャとアセンブラは、
本質から逸脱する奇妙な技術的特徴で満たされています
-当時、それらは必要なエンジニアリングの妥協と技術的なトリックの結果でしたが、今日の主なソースは古いモデルとの後方互換性の要件です。 読者に不必要で急速に老化する詳細で過負荷にならず、プレゼンテーションの汎用性を保持しないために、Knutはトレーニング専用に設計された独自のコンピューターアーキテクチャを開発することにしました。 このアーキテクチャはMIXと呼ばれます。
次の30年間で、コンピューターテクノロジーの分野で大きな変化が起こり、MIXはほとんど時代遅れになっています。 「プログラミングの芸術」を引き続き関連するソースとして維持するために、著者は
MMIXプロセッサの主要な産業開発者とともに、1990年代後半に理想化され改善されたコンピューターの類似物で
ある新しい架空のコンピューターを開発することを決定しました。 MMIXは、すぐにハードウェアを実装するのに適した十分に考え抜かれたアーキテクチャであり、現在広く使用されているすべてのプロセッサアーキテクチャよりも著しく発展しています。
1990年代後半のツールを使用して「ハードウェア」で効果的に実装できるマシンを作りたいという願望は、
将来のための十分な準備を妨げました
-残念ながら、MMIX命令セットは非同期スーパースカラープロセッサの可能性を実現するのに実際には不適切です。 実際、MMIXでの呼び出しの編成は、従来の遷移の使用に基づいており、レジスタの書き換えが必要です。 有望なプログラミング手法の実用的な研究のために、上記の中央
処理装置の開発における避けられない傾向に従ってこの命令セットを修正する必要があります。幸いなことに、これはそれほど難しい作業ではありません。